Command Palette
Search for a command to run...
Chatterbox TTS: Demo Zur Sprachsynthese
1. Einführung in das Tutorial

Eine der Kernfunktionen von Chatterbox ist das Zero-Sample-Voice-Cloning. Dadurch lassen sich mit nur fünf Sekunden Referenz-Audiomaterial hochrealistische, personalisierte Stimmen erzeugen, ohne dass ein komplexer Trainingsprozess erforderlich ist. Darüber hinaus unterstützt es die Kontrolle emotionaler Übertreibungen, sodass Nutzer die emotionale Intensität, die Sprechgeschwindigkeit und die Intonation der Stimme anpassen können, um ihr mehr Ausdruckskraft zu verleihen. Dank der extrem niedrigen Latenzzeit von weniger als 200 Millisekunden eignet sich Chatterbox für interaktive Anwendungen wie virtuelle Assistenten und Echtzeit-Synchronisation. Um die Sicherheit und Rückverfolgbarkeit der Inhalte zu gewährleisten, ist die neuronale Wasserzeichentechnologie „Perth“ von Resemble AI in das von Chatterbox generierte Audio integriert, um Missbrauch zu verhindern.
Die wichtigsten Neuerungen sind:
- Kontrolle emotionaler Übertreibungen: Durch Anpassen der Parameter (z. B. Übertreibung = 0,7 + cfg = 0,3) können Sie einen Sprechstil von nichtssagend bis dramatisch erreichen.
- Echtzeitsynthesefähigkeit: Inferenzverzögerung < 200 ms, geeignet für interaktive Echtzeitszenarien
Die Rechenressourcen dieses Tutorials nutzen eine einzelne RTX 4090-Karte. Die Eingabeaufforderungen dieses Modells unterstützen nur Englisch.
2. Bedienungsschritte
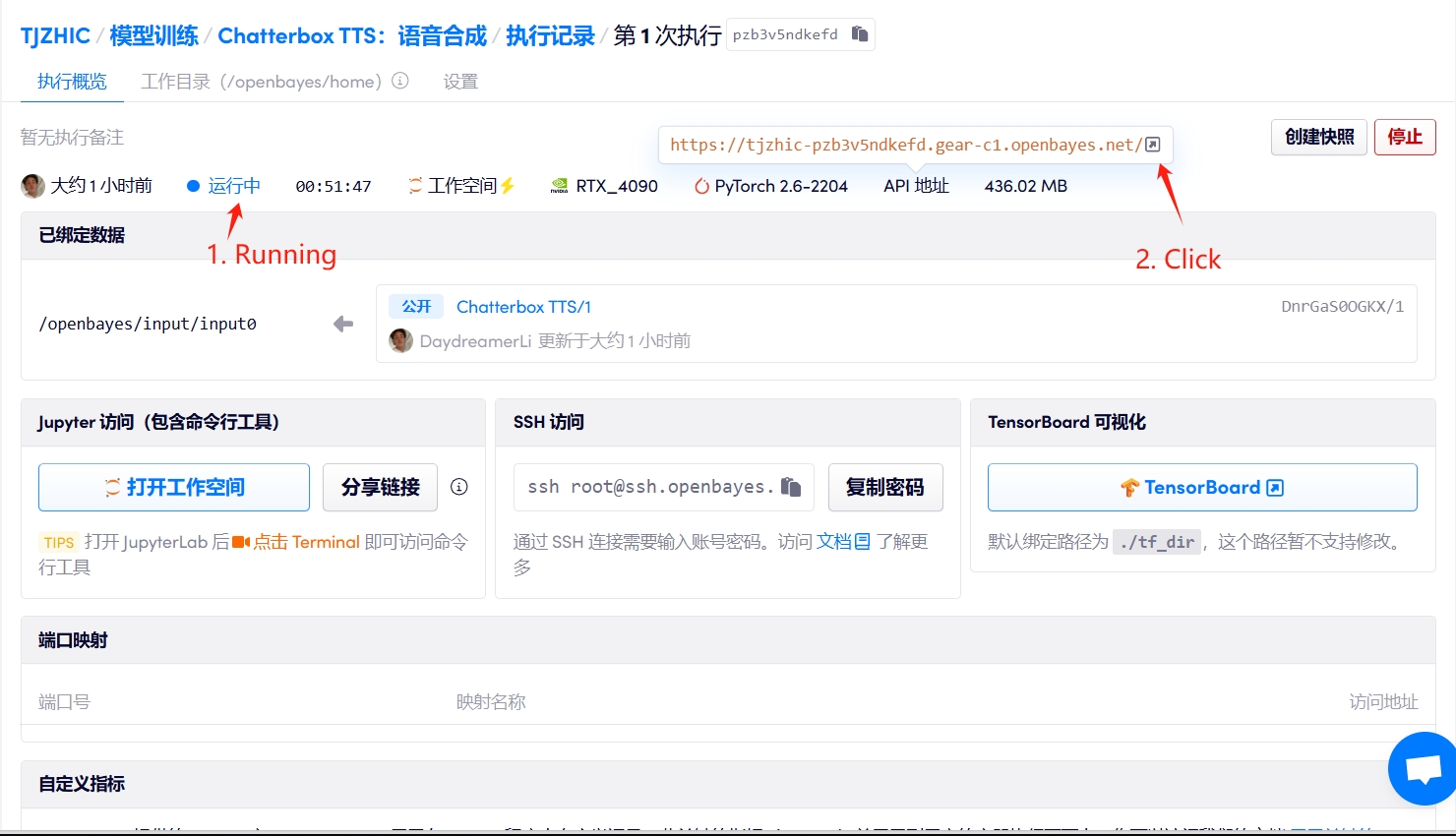
1. Starten Sie den Container
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
2. Anwendungsschritte
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
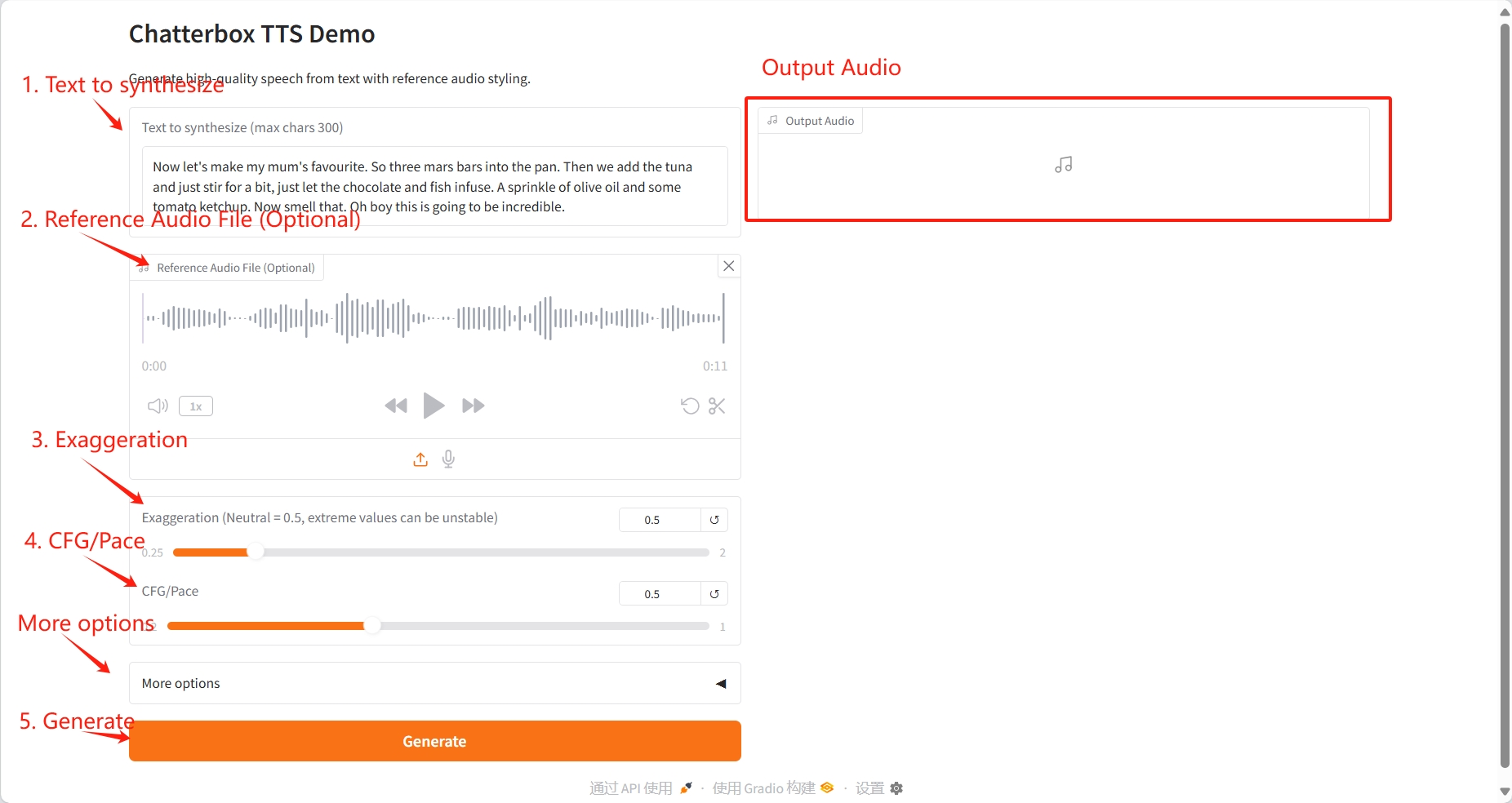
1. Textgenerierung
Spezifische Parameter:
- Zu synthetisierende Texte: Geben Sie den Text ein, der in Sprache umgewandelt werden soll. Die maximale Länge beträgt 300 Zeichen (zu langer Text wird automatisch gekürzt).
- Referenz-Audiodatei (optional): Stellt eine Referenz-Audiodatei bereit, damit das System den Stimmstil, die Intonation und den Rhythmus des Sprechers nachahmen kann.
- Übertreibung (Neutral = 0,5): Steuert die Übertreibung des emotionalen Ausdrucks und des Stimmklangs.
- CFG/Pace: Steuert den Rhythmus und die Geschwindigkeit der Sprache.
- Zufallsstartwert (0 für Zufall): Legen Sie den Zufallsstartwert fest.
- Temperatur: Steuert die Zufälligkeit und Vielfalt sprachlicher Äußerungen.
Ergebnis 
3. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.