Command Palette
Search for a command to run...
PixelReasoner-RL: Visuelles Inferenzmodell Auf Pixelebene
Datum
Paper-URL
Lizenz
MIT
1. Einführung in das Tutorial
PixelReasoner-RL-v1 ist ein bahnbrechendes visuelles Sprachmodell, das im Mai 2025 vom TIGER AI Lab veröffentlicht wurde. Die zugehörige Forschungsarbeit lautet wie folgt: Pixel Reasoner: Anreize für pixelbasiertes Denken durch neugiergetriebenes Reinforcement Learning .
Dieses Projekt, basierend auf der Qwen2.5-VL-Architektur, überwindet die Grenzen traditioneller visueller Sprachmodelle, die ausschließlich auf textbasiertem Schließen beruhen, durch eine innovative, neugiergetriebene Methode des bestärkenden Lernens. PixelReasoner kann direkt im Pixelraum Schlussfolgerungen ziehen und unterstützt visuelle Operationen wie Skalierung und Frame-Auswahl. Dadurch wird die Fähigkeit, Bilddetails, räumliche Beziehungen und Videoinhalte zu verstehen, deutlich verbessert.
Kernfunktionen:
- Inferenz auf Pixelebene: Das Modell kann direkt im Bildpixelraum analysiert und manipuliert werden.
- Die Kombination aus globalem und lokalem Verständnis ermöglicht es, sowohl den Gesamtbildinhalt zu erfassen als auch in bestimmte Bereiche hineinzuzoomen und sich darauf zu konzentrieren.
- Neugiergetriebenes Training: Einführung eines Belohnungsmechanismus für Neugier, um das Modell zu motivieren, aktiv Operationen auf Pixelebene zu erkunden.
- Verbesserte Fähigkeit zum logischen Denken: Hervorragende Leistungen bei komplexen visuellen Aufgaben, einschließlich der Erkennung kleiner Objekte und des Verständnisses subtiler räumlicher Beziehungen.
Dieses Tutorial verwendet Grado, um PixelReasoner-RL-v1 als Demonstrationsprojekt mit den Rechenressourcen einer einzelnen RTX 5090-Karte bereitzustellen.
2. Effektanzeige
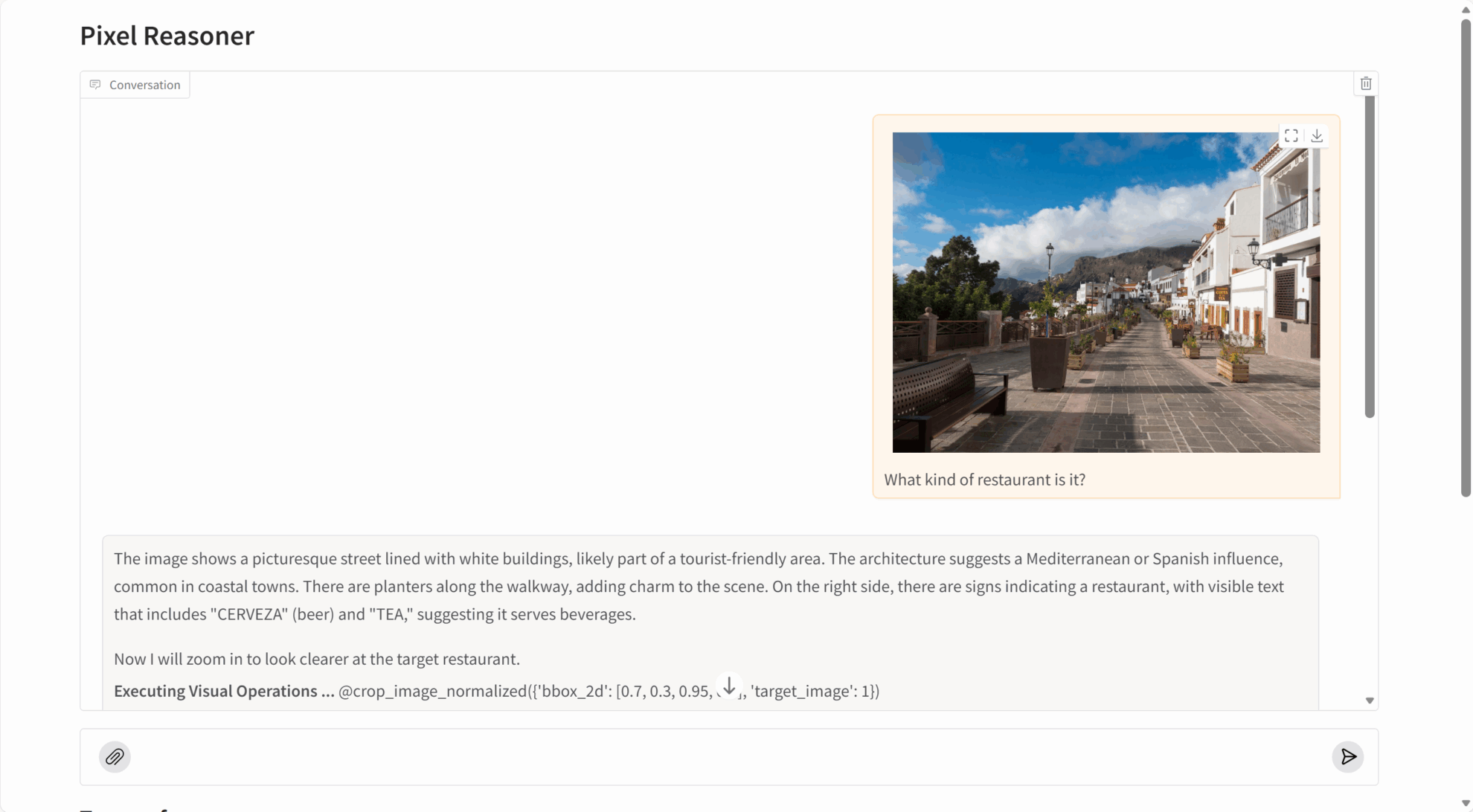
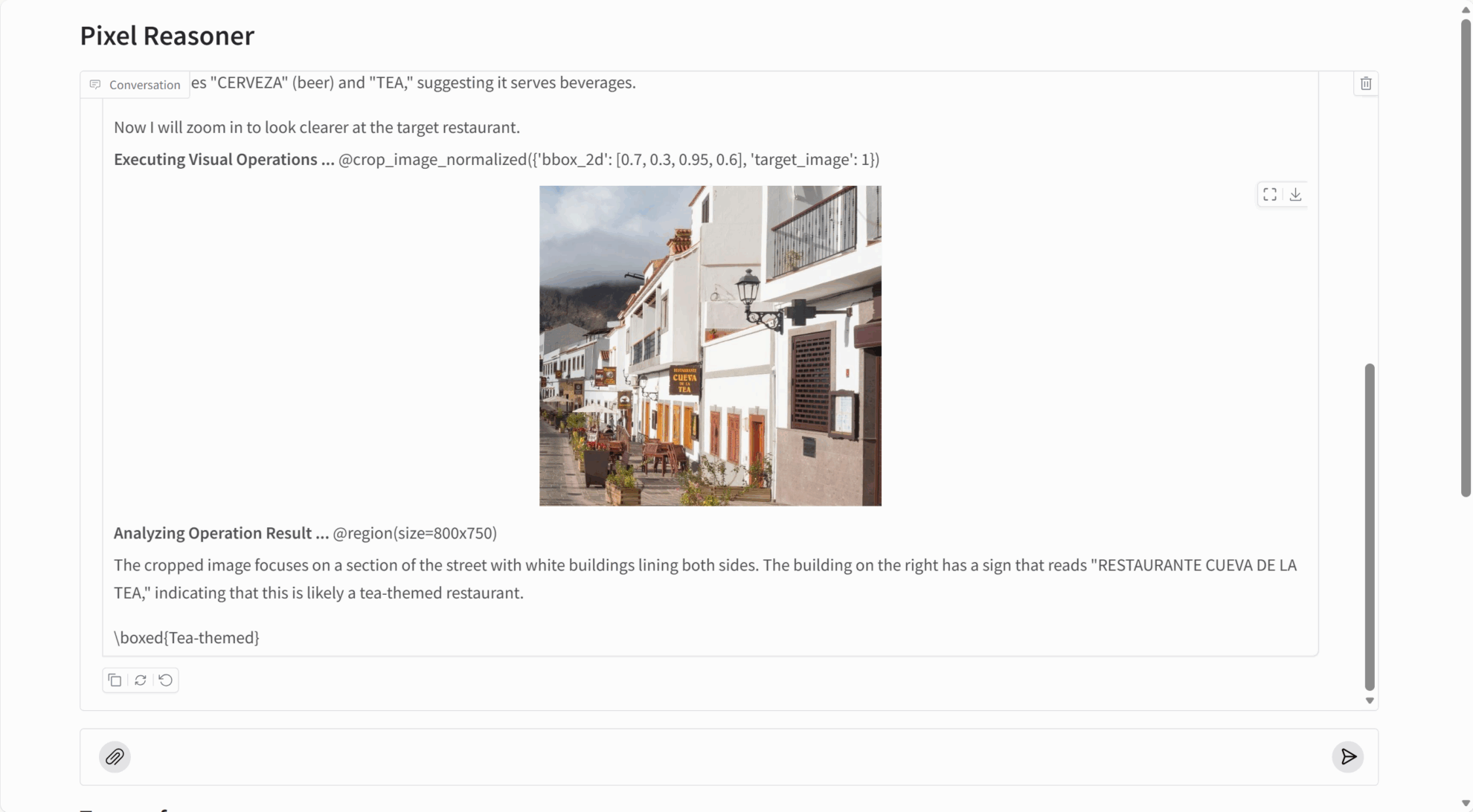
PixelReasoner-RL-v1 erzielt bei mehreren visuellen Denkaufgaben außergewöhnlich gute Ergebnisse:
- Bildverständnis: die genaue Identifizierung von Bildinhalten, Objektbeziehungen und Szenendetails.
- Detailerfassung: Kann kleinste Objekte, eingebetteten Text und andere feine Informationen in Bildern erkennen.
- Videoanalyse: Videoinhalte und Handlungsabläufe durch die Auswahl von Schlüsselbildern verstehen.
- Räumliches Denken: das genaue Verständnis der räumlichen Position und der relativen Beziehungen von Objekten.
3. Bedienungsschritte
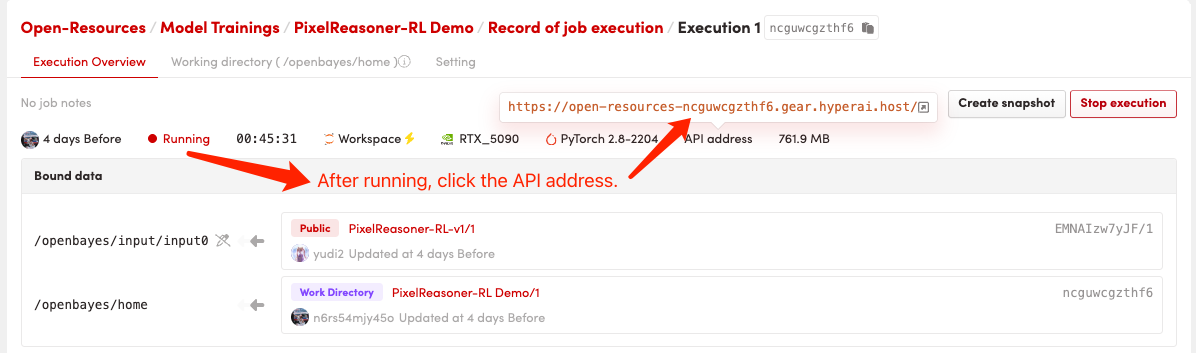
1. Starten Sie den Container
Klicken Sie nach dem Starten des Containers auf die API-Adresse, um zur Weboberfläche zu gelangen
Der erste Startvorgang dauert etwa 2–3 Minuten; bitte haben Sie etwas Geduld. Sobald die Bereitstellung abgeschlossen ist, klicken Sie auf die „API-Adresse“, um direkt auf die Grado-Oberfläche zuzugreifen.
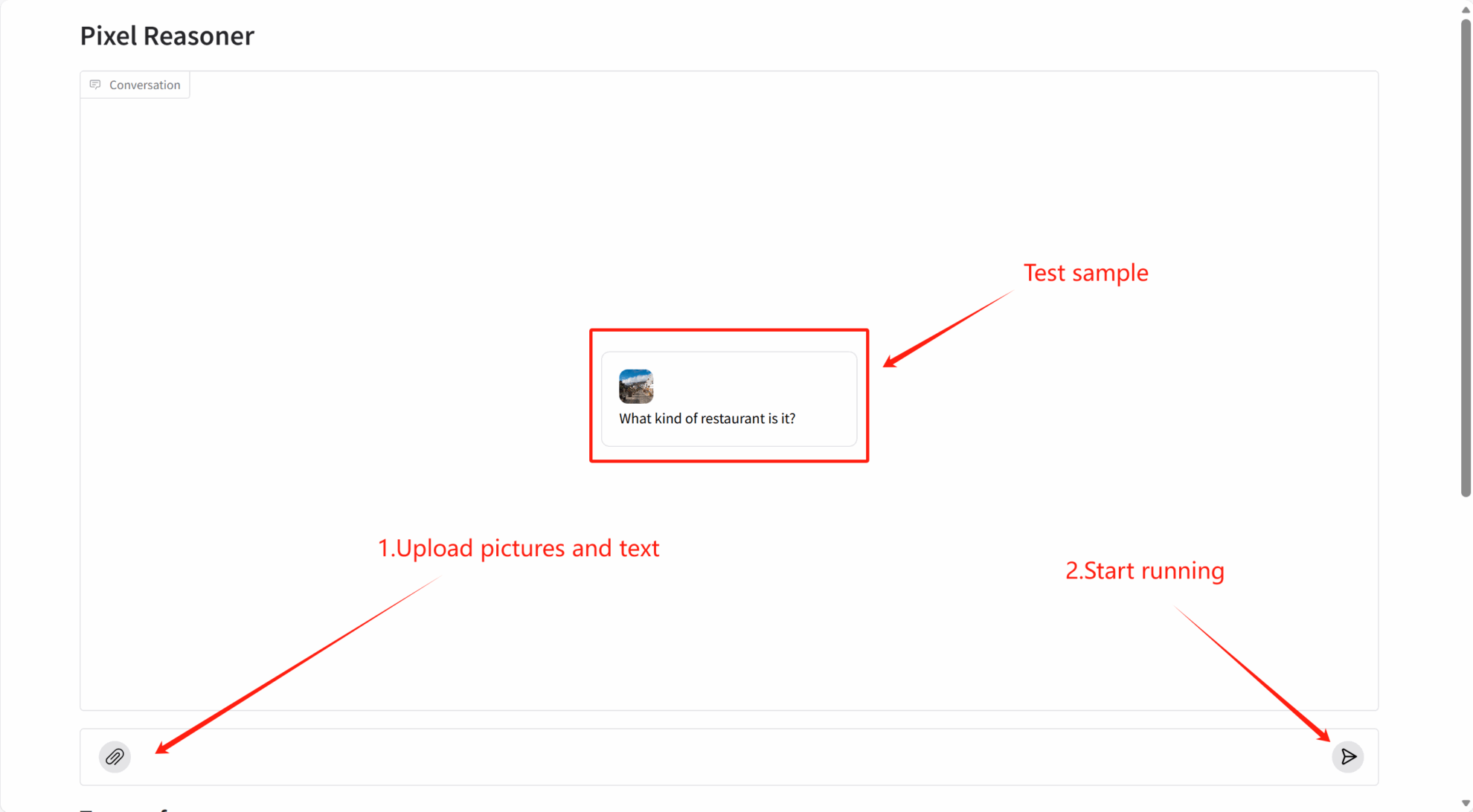
2. Erste Schritte
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{pixelreasoner2025,
title={Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning},
author={Su, Alex and Wang, Haozhe and Ren, Weiming and Lin, Fangzhen and Chen, Wenhu},
journal={arXiv preprint arXiv:2505.15966},
year={2025}
}Notebook-Übersicht
Stufe
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.