Command Palette
Search for a command to run...
SmolLM3-3B-Modell Mit Einem Klick Bereitstellen
1. Einführung in das Tutorial

SmolLM3-3B wurde im Juli 2025 vom Hugging Face TB (Transformer Big)-Team als Open Source veröffentlicht und als „Leistungsmaximum“ positioniert. Zugehörige Forschungsarbeiten umfassen… SmolLM3: kleiner, mehrsprachiger, kontextbezogener Denker Es handelt sich um ein revolutionäres Open-Source-Sprachmodell mit 3 Milliarden Parametern, das entwickelt wurde, um die Leistungsgrenzen kleiner Modelle in einer kompakten Größe von 3B zu durchbrechen.
Dieses Tutorial verwendet eine einzelne RTX 5090 (32 GB) Grafikkarte und eine PyTorch 2.8 + CUDA 12.8 Installationsumgebung. Die geschätzte Ladezeit der Gradio-Anwendung beträgt 2–3 Minuten.
2. Projektbeispiele
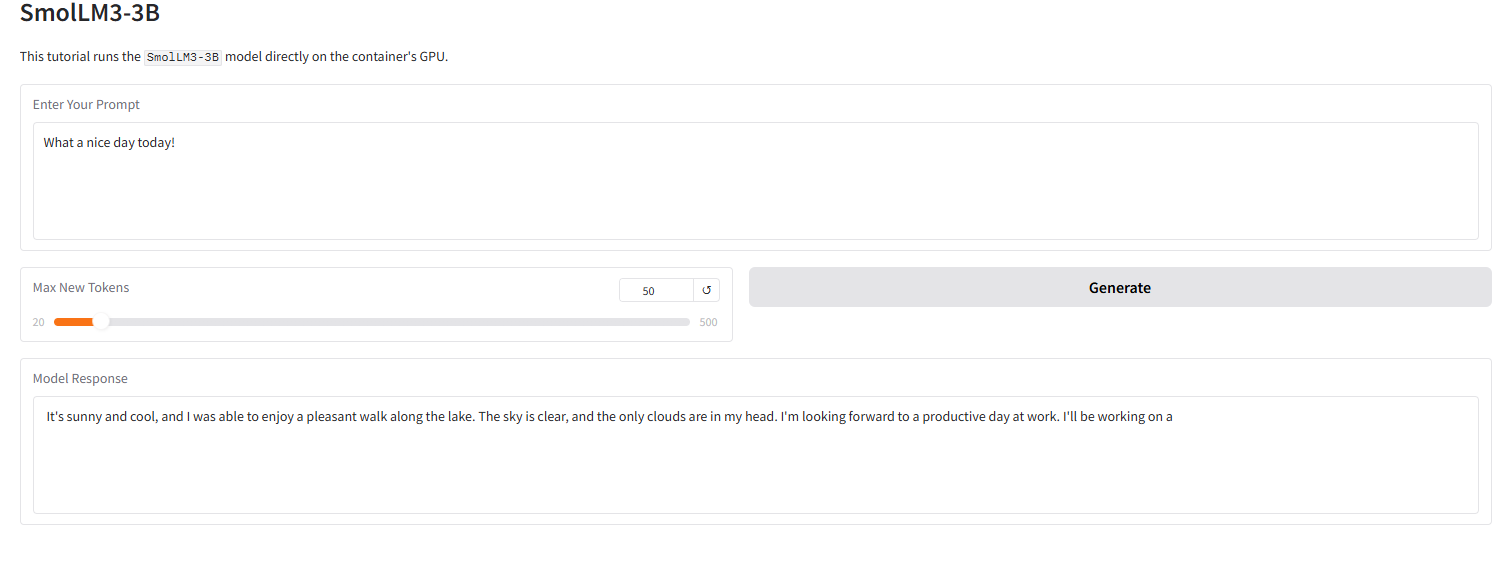
Die Abbildung unten zeigt die Wirkung der Grado-Oberfläche in diesem Tutorial. Wir haben ein Eingabewort eingegeben, und das Modell lieferte erfolgreich eine 4-Bit-quantisierte Antwort.
3. Bedienungsschritte
Dieser Abschnitt enthält Anweisungen für den Ein-Klick-Start, die Code-Verzeichnisstruktur und häufig gestellte Fragen.
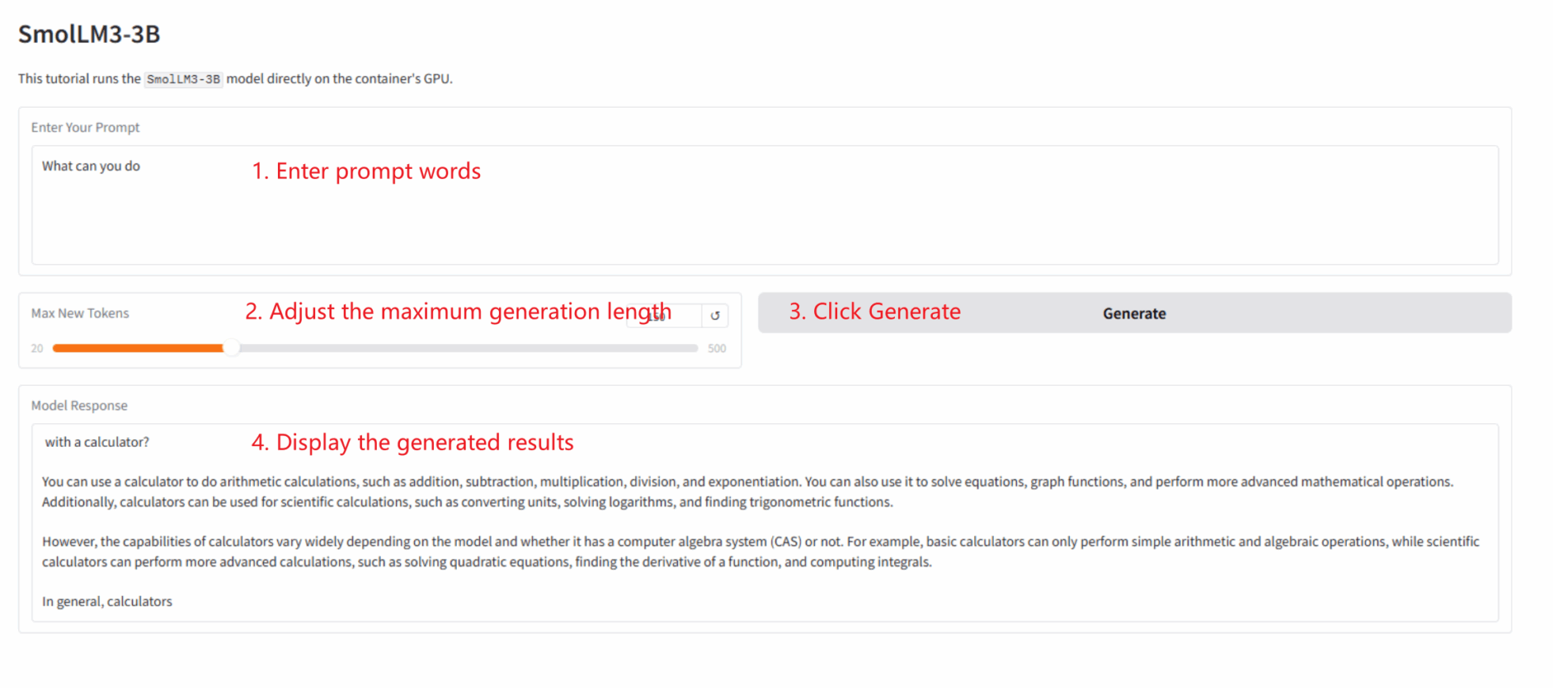
Dieses Tutorial zeigt, wie man eine Gradio-App mit einem einzigen Klick bereitstellt. Benutzer müssen keinen Code ausführen; folgen Sie einfach diesen Schritten:
1. Klon-Anleitung: Klicken Sie in der oberen rechten Ecke dieser Seite auf „Klonen“, um Ihren persönlichen Container zu erstellen.
2. Starten Sie den Container und warten Sie: Das System startet den Container automatisch für Sie (empfohlen). RTX 5090). dependencies.sh Das Skript wird automatisch im Hintergrund ausgeführt und lädt das 4-Bit-Quantisierungsmodell.Dieser Vorgang dauert etwa 2-3 Minuten.
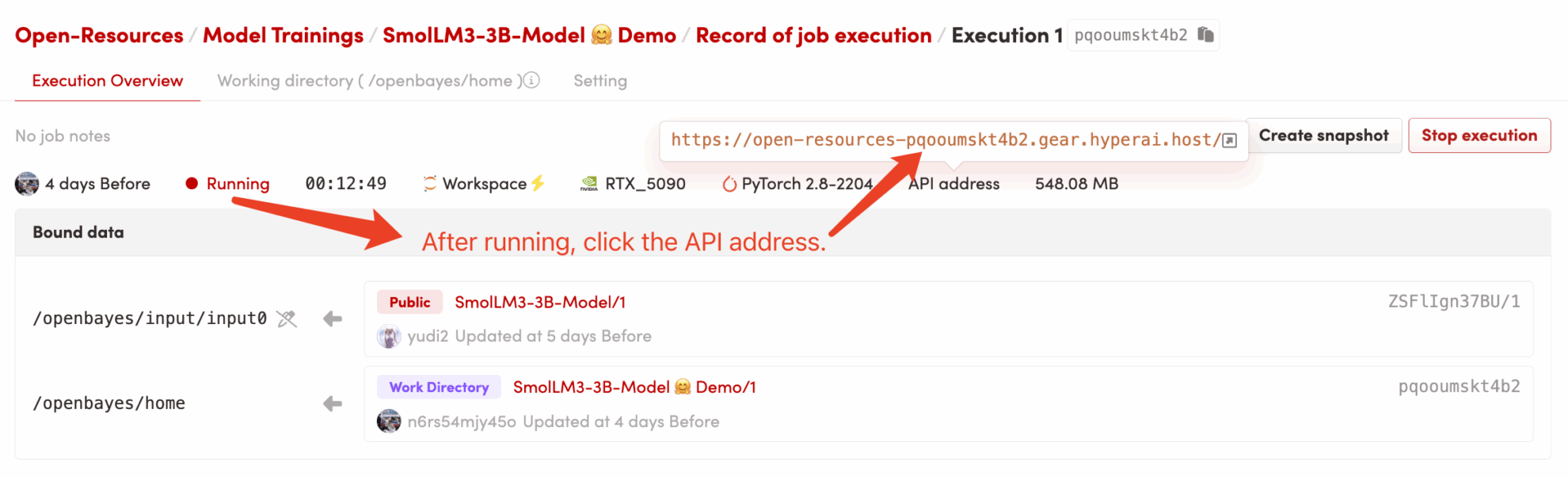
3. Zugriff auf die Anwendung: Sobald sich der Containerstatus auf „Running“ ändert, klicken Sie auf der Containerdetailseite auf „API Address“, um die Grado-Oberfläche zu öffnen.
Code-Verzeichnisstruktur
/openbayes/home |-- app.py \# Gradio 应用的启动脚本 |-- requirements.txt \# 锁定的 Python 依赖包 (已预装) |-- dependencies.sh \# 平台自动化执行脚本 (仅启动 app) |-- README\_cn.md \# 本教程说明文档 (中文) \`-- README\_en.md \# 本教程说明文档 (英文) /openbayes/input/input0 # 只读绑定的 SmolLM3-3B 模型文件
Häufig gestellte Fragen
- F: Nach dem Klicken auf „API-Adresse“ kann die Seite nicht geladen werden oder zeigt die Fehlermeldung „502“ an? A: Das liegt daran, dass das Modell geladen wird.
SmolLM3-3BEs handelt sich um ein großes Modell; selbst die 4-Bit-quantisierte Version benötigt 2–3 Minuten, um vollständig auf die GPU geladen zu werden. Bitte warten Sie einige Minuten, bevor Sie die Seite aktualisieren. - F: Das Protokoll zeigt
OSError: Cannot find empty port 8080? A: Das liegt daran, dass Sie (oder Ihr System) versucht haben, die Anwendung mehrmals zu starten, wodurch Port 8080 von einem „Zombie-Prozess“ belegt ist. Sie müssen die Anwendung nur in einem Container-Terminal ausführen.pkill -f "python /openbayes/home/app.py"Alte Prozesse bereinigen und anschließend erneut ausführen.bash /openbayes/home/dependencies.shDas ist alles.
Zitationsinformationen
@misc{bakouch2025smollm3,
title={{SmolLM3: smol, multilingual, long-context reasoner}},
author={Bakouch, Elie and Ben Allal, Loubna and Lozhkov, Anton and Tazi, Nouamane and Tunstall, Lewis and Patiño, Carlos Miguel and Beeching, Edward and Roucher, Aymeric and Reedi, Aksel Joonas and Gallouédec, Quentin and Rasul, Kashif and Habib, Nathan and Fourrier, Clémentine and Kydlicek, Hynek and Penedo, Guilherme and Larcher, Hugo and Morlon, Mathieu and Srivastav, Vaibhav and Lochner, Joshua and Nguyen, Xuan-Son and Raffel, Colin and von Werra, Leandro and Wolf, Thomas},
year={2025},
howpublished={\url{[https://huggingface.co/blog/smollm3](https://huggingface.co/blog/smollm3)}}
}Notebook-Übersicht
Stufe
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.