Command Palette
Search for a command to run...
YOLOE: Alles in Echtzeit Sehen
Datum
Paper-URL
Lizenz
Apache 2.0
GitHub
1. Einführung in das Tutorial

YOLOE ist ein neuartiges Echtzeit-Bildverarbeitungsmodell, das 2025 von einem Forschungsteam der Tsinghua-Universität entwickelt wurde und das Ziel verfolgt, „alles in Echtzeit zu sehen“. Es übernimmt die Echtzeit- und Effizienzeigenschaften der YOLO-Modellreihe und integriert Zero-Shot-Learning sowie multimodale Prompting-Funktionen. Dadurch ermöglicht es Objekterkennung und -segmentierung in verschiedenen Szenarien, darunter Text-, Bild- und unstrukturierte Szenarien. Zugehörige Forschungsarbeiten sind verfügbar. YOLOE: Alles in Echtzeit sehen .
YOLO (You Only Look Once) ist seit seiner Einführung im Jahr 2015 führend in der Objekterkennung und Bildsegmentierung.Nachfolgend finden Sie die Entwicklung der YOLO-Reihe und der zugehörigen Tutorials:
- YOLOv2 (2016): Einführung von Batch-Normalisierung, Ankerboxen und Dimensionsclustering.
- YOLOv3 (2018): Verwendung effizienterer Backbone-Netzwerke, Multi-Anker und räumliches Pyramiden-Pooling.
- YOLOv4 (2020): Einführung der Mosaik-Datenerweiterung, des ankerfreien Erkennungskopfes und der neuen Verlustfunktion. → Anleitung:DeepSOCIAL realisiert Crowd Distance Monitoring basierend auf YOLOv4 und sortiert Multi-Target-Tracking
- YOLOv5 (2020): Hyperparameteroptimierung, Experimentverfolgung und automatische Exportfunktionen hinzugefügt. → Anleitung:YOLOv5_deepsort Echtzeit-Multi-Target-Tracking-Modell
- YOLOv6 (2022): Meituan Open Source, wird häufig in autonomen Lieferrobotern verwendet.
- YOLOv7 (2022): Unterstützt die Posenschätzung für den COCO-Keypoint-Datensatz. → Tutorial:So trainieren und verwenden Sie ein benutzerdefiniertes YOLOv7-Modell
- YOLOv8 (2023):Ultralytics veröffentlicht, unterstützt eine breite Palette visueller KI-Aufgaben. → Tutorial:Training von YOLOv8 mit benutzerdefinierten Daten
- YOLOv9 (2024): Einführung in Programmable Gradient Information (PGI) und Generalized Efficient Layer Aggregation Network (GELAN).
- YOLOv10 (2024): Es wurde von der Tsinghua-Universität eingeführt, führt einen End-to-End-Header ein und eliminiert die Anforderung der nicht maximalen Unterdrückung (NMS). → Anleitung:YOLOv10 Echtzeit-End-to-End-Objekterkennung
- YOLOv11(2024): Das neueste Modell von Ultralytics, das Erkennung, Segmentierung, Posenabschätzung, Verfolgung und Klassifizierung unterstützt. → Anleitung:Ein-Klick-Bereitstellung von YOLOv11
- YOLOv12 🚀 NEU (2025): Die doppelten Spitzenwerte bei Geschwindigkeit und Genauigkeit, kombiniert mit den Leistungsvorteilen des Aufmerksamkeitsmechanismus!
Kernfunktionen
- Beliebiger Texttyp

2. Multimodale Eingabeaufforderungen:
- Visuelle Hinweise (Kästchen/Punkte/handgezeichnete Formen/Referenzbilder)

- Vollautomatische Lautloserkennung – Szenenobjekte automatisch identifizieren

Demoumgebung: YOLOv8e/YOLOv11e-Serie + RTX4090
2. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Bitte warten Sie etwa 1–2 Minuten und aktualisieren Sie die Seite.

2. YOLOE-Funktionsdemonstration
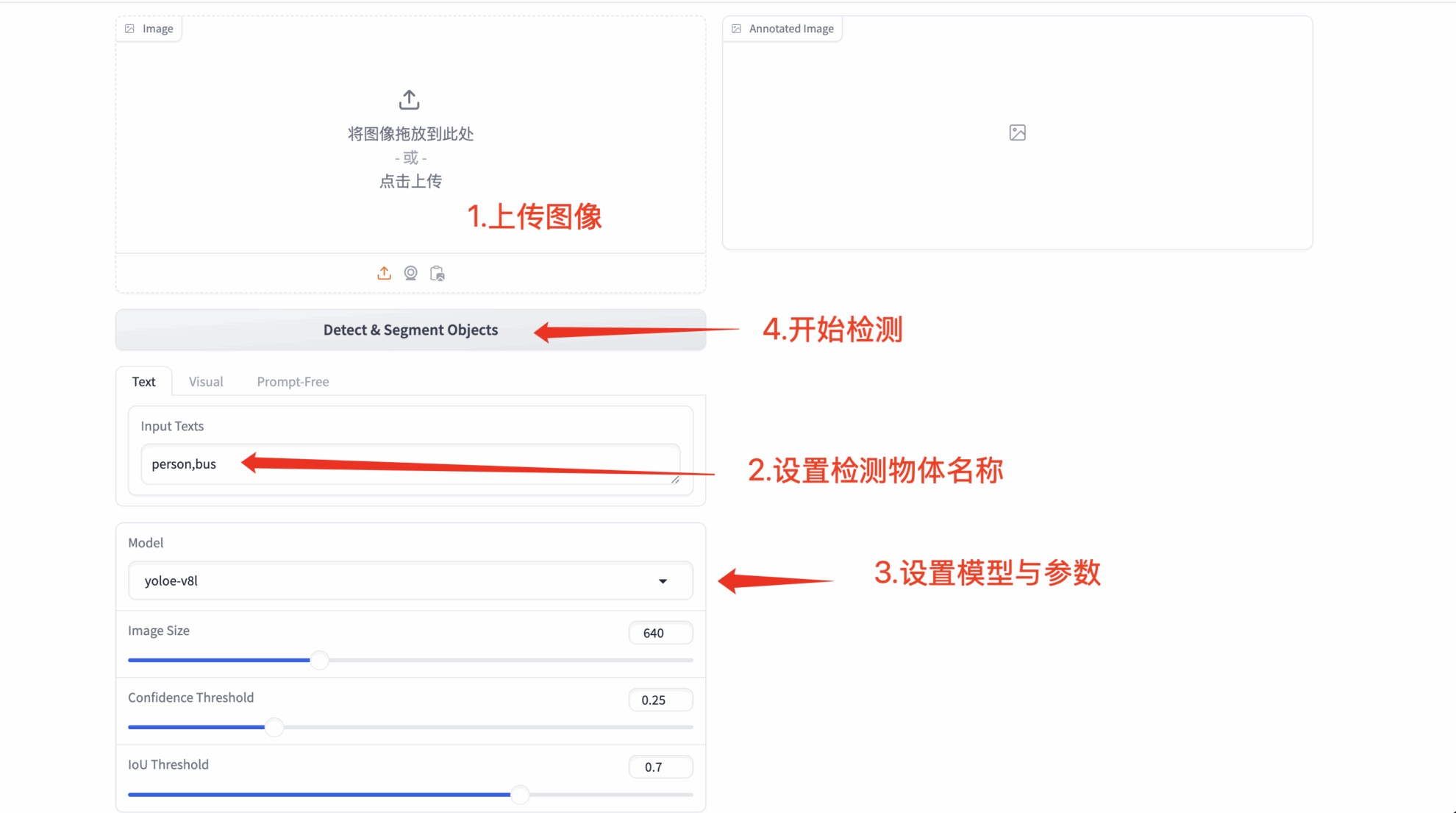
1. Texteingabeaufforderungserkennung
- Beliebiger Texttyp
- Benutzerdefinierte Eingabeaufforderungswörter: Ermöglicht dem Benutzer die Eingabe von beliebigem Text (die Erkennungsergebnisse können je nach semantischer Komplexität variieren)

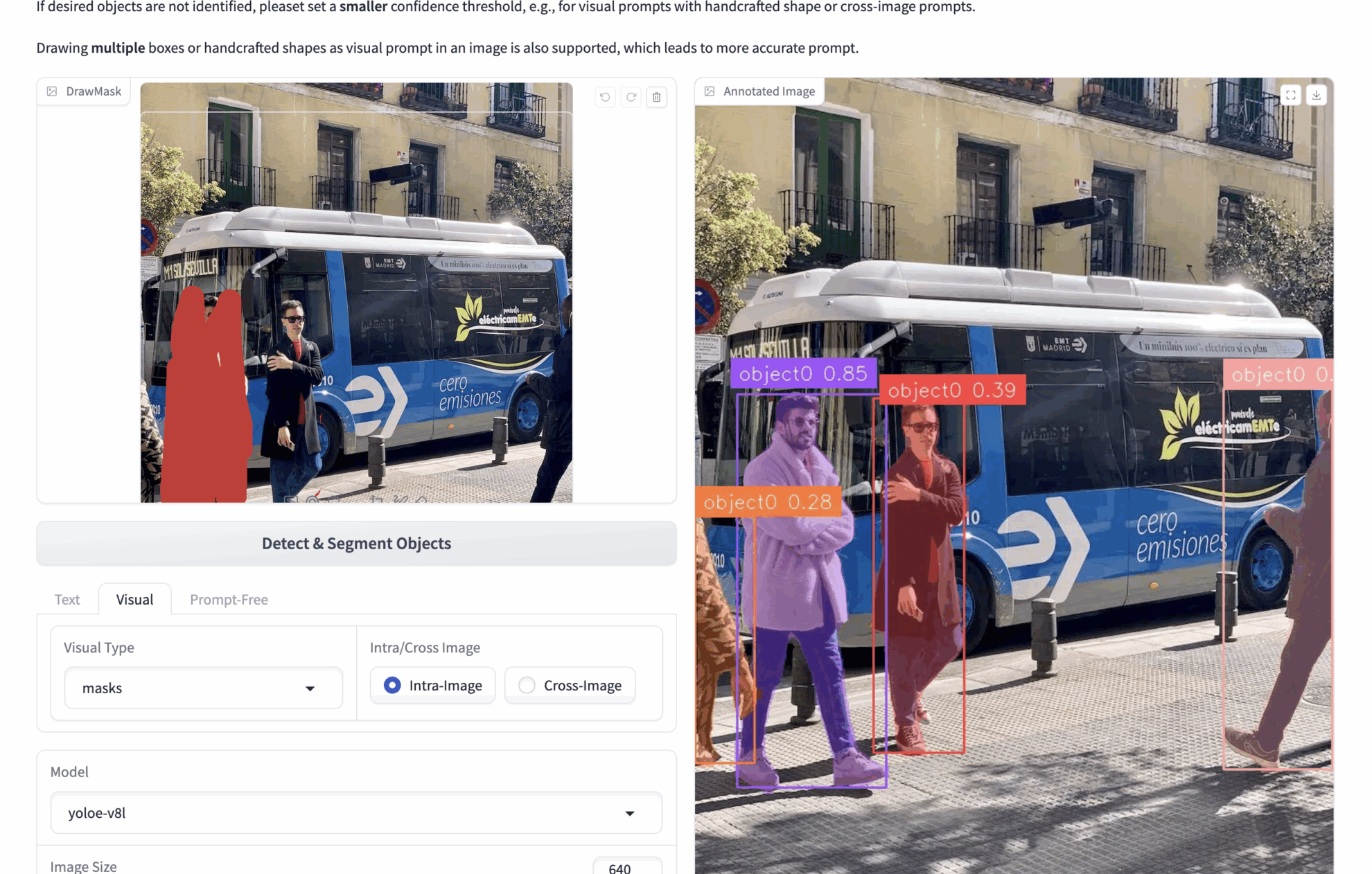
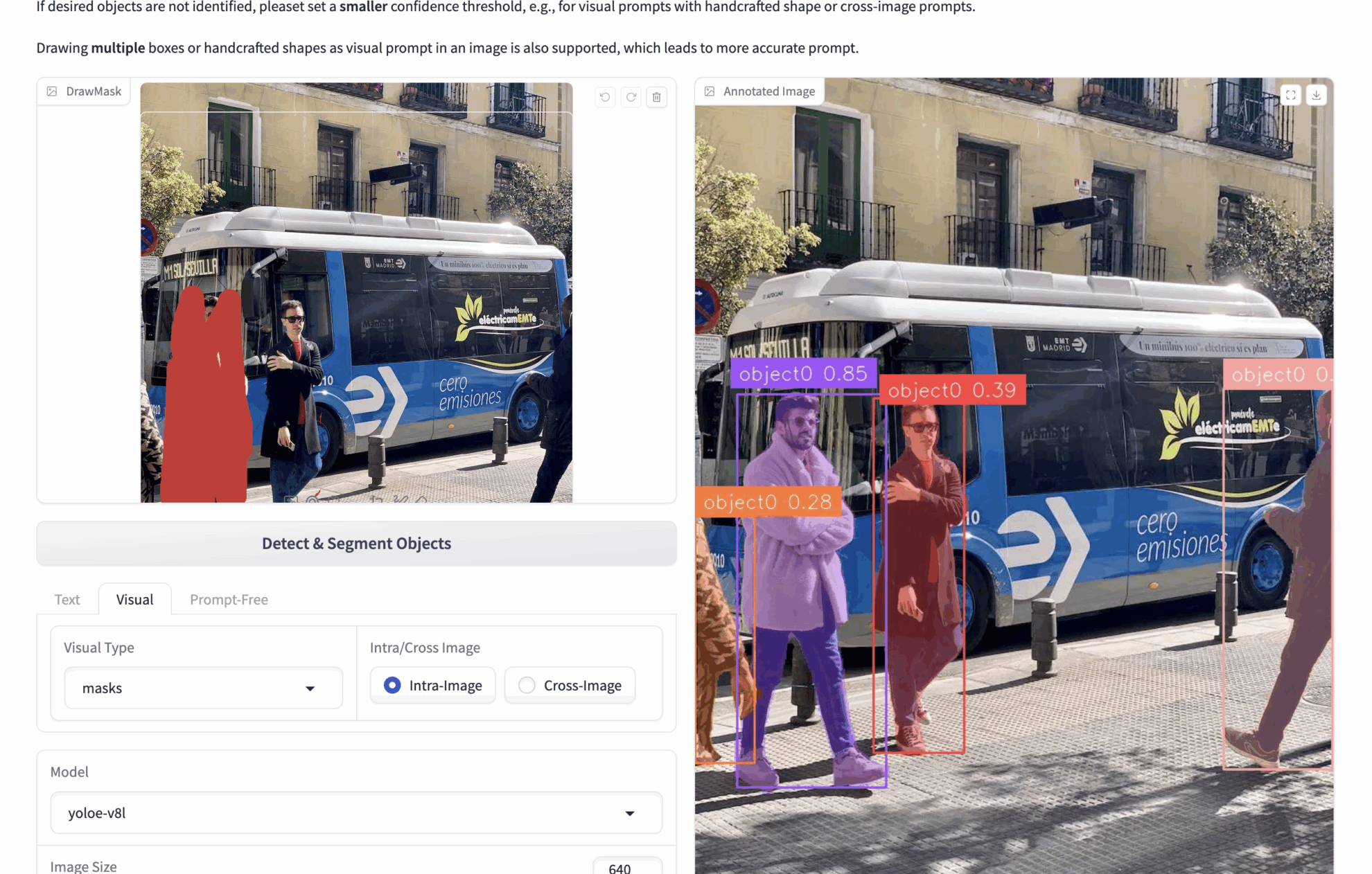
2. Multimodale visuelle Hinweise
- 🟦 Erkennung der Boxauswahl (bboxen)
bboxes: Wenn Sie beispielsweise ein Bild hochladen, auf dem viele Personen zu sehen sind, und die Personen auf dem Bild erkennen möchten, können Sie bboxes verwenden, um eine Person einzurahmen. Während der Inferenz identifiziert das Modell alle Personen im Bild basierend auf dem Inhalt der Bboxen.
Um genauere visuelle Hinweise zu erhalten, können mehrere Bboxen gezeichnet werden. - ✏️ Klicken/Zeichnen-Bereich (Masken)
Masken: Wenn Sie beispielsweise ein Bild hochladen, auf dem viele Personen zu sehen sind, und die Personen auf dem Bild erkennen möchten, können Sie Masken verwenden, um eine Person abzudecken. Während der Inferenz erkennt das Modell alle Personen im Bild anhand des Inhalts der Masken.
Sie können mehrere Masken zeichnen, um genauere visuelle Hinweise zu erhalten. - 🖼️ Referenzbildvergleich (Intra/Cross)
Intra: Bedienen Sie Bboxen oder Masken auf dem aktuellen Bild und führen Sie Inferenzen auf dem aktuellen Bild durch.
Cross: Behandeln Sie Bboxen oder Masken auf dem aktuellen Bild und ziehen Sie Rückschlüsse auf andere Bilder.
Kernkonzepte
| Modell | Funktionsbeschreibung | Anwendungsszenario |
|---|---|---|
| Intra-Bild | Modellieren von Objektbeziehungen innerhalb eines einzelnen Diagramms | Lokale, zielgenaue Positionierung |
| Kreuzbild | Bildübergreifender Merkmalsabgleich | Ähnliches Objektabrufen |

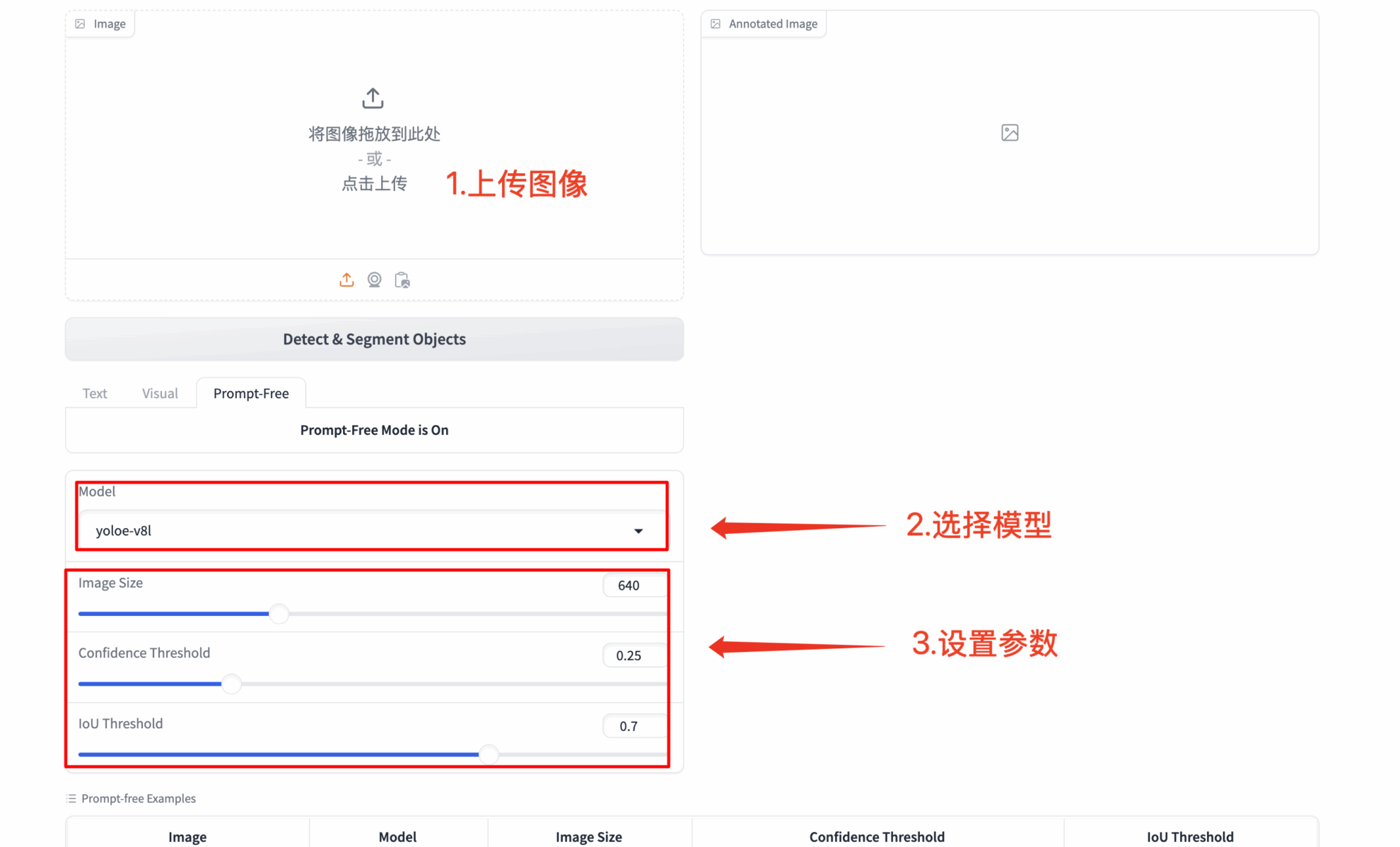
3. Vollautomatische Erkennung ohne Rückfrage
- 🔍 Intelligente Szenenanalyse: Automatisches Identifizieren aller auffälligen Objekte in einem Bild
- 🚀 Start ohne Konfiguration: Funktioniert ohne Eingabeaufforderung

Austausch und Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Notebook-Übersicht
Stufe
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.