Command Palette
Search for a command to run...
用自定义数据训练 YOLOv8
在本教程中,我们将研究 Ultralytics 新模型 YOLOv8 的新功能,深入了解与 YOLOv5 相比架构的变化,并通过测试其在我们的篮球数据集上进行检测的 Python API 功能来演示新模型。主要涵盖 YOLOv8 的原理、演示如何创建和标记数据集、训练模型以及如何在任何传入的视频文件或流上使用该模型。
目标检测仍然是 AI 技术最受欢迎和最直接的用例之一。自 Joseph Redman 等人在 2016 年的开创性工作中发布第一个版本以来,“You Only Look Once:Unified,Real-Time Object Detection”,YOLO 系列模型一直引领着潮流。这些目标检测模型为研究使用 DL 模型在图像中执行实时实体主题和位置识别铺平了道路。
在本文中,我们将重新审视这些技术的基础知识,讨论 Ultralytics 最新版本 YOLOv8 的新功能,并使用 RoboFlow 和 Paperspace Gradient 以及新的 Ultralytics API 步骤性地演示微调自定义 YOLOv8 模型的步骤。在本教程结束时,用户应该能够快速轻松地将 YOLOv8 模型适配到任何一组标记图像中。
YOLO 如何工作?
首先,让我们讨论 YOLO 的基本工作原理。以下是原始 YOLO 论文中从模型功能的总和中分解的简短引用:
「单个卷积网络同时预测多个边界框和这些框的类概率。 YOLO 在完整图像上进行训练并直接优化检测性能。这个统一的模型比传统的目标检测方法有几个优点。」
如上所述,该模型能够预测图像中多个实体的位置并识别其主题,前提是它已经训练过了这些特征。它通过将图像分成 N 个网格,每个网格的大小为 s * s,来在单个阶段中完成此操作。这些区域同时被解析以检测和定位其中包含的任何对象。然后,模型预测每个网格中的边界框坐标 B,并为其中包含的对象预测标签和预测分数。
将所有这些放在一起,我们得到了一种能够执行对象分类,对象检测和图像分割任务的技术。由于 YOLO 的基本技术保持不变,因此我们可以推断这也适用于 YOLOv8 。有关 YOLO 如何工作的更完整的分解,请务必查看我们早期关于 YOLOv5 和 YOLOv7 的文章,我们使用 YOLOv6 和 YOLOv7 进行基准测试,以及原始 YOLO 论文。
YOLOv8 中有什么新功能?
由于 YOLOv8 刚刚发布,因此尚未发布涵盖该模型的论文。作者打算很快发布它,但是现在,我们只能根据官方发布的帖子,从提交历史中推断出更改,并尝试自己确定 YOLOv5 和 YOLOv8 之间的更改程度。
根据官方发布,YOLOv8 采用了新的骨干网络、无锚点检测头和损失函数。 Github 用户 RangeKing 分享了 YOLOv8 模型基础设施的概述,展示了更新后的模型骨干和头结构。通过将此图与 YOLOv5 的类似检查进行比较,RangeKing 在他们的帖子中确定了以下更改:

C2f 模块,图片来源:RoboFlow (来源)- 他们用
C2f模块替换了C3模块。在C2f中,来自Bottleneck(两个带有残差连接的 3×3convs)的所有输出都被连接在一起,但在C3中,只使用了最后一个Bottleneck的输出。 (来源)

- 他们在
Backbone中用一个3x3 Conv块替换了第一个6x6 Conv - 他们删除了两个
Conv(在 YOLOv5 配置中的第 10 个和第 14 个)

- 他们在
Bottleneck中用一个3x3 Conv替换了第一个1x1 Conv - 他们改用解耦头,并删除了
objectness分支
请在 YOLOv8 的论文发布后再回来查看,我们将更新本节以提供更多信息。有关上述更改的详细分析,请查看 RoboFlow 文章,该文章介绍了 YOLOv8 的发布。
可访问性
除了旧的克隆 Github 存储库和手动设置环境的方法外,用户现在可以使用新的 Ultralytics API 访问 YOLOv8 进行训练和推理。请查看下面的 训练模型 部分,了解设置 API 的详细信息。
无锚定边界框
根据 Ultralytics 合作伙伴 RoboFlow 的博客文章 YOLOv8,YOLOv8 现在具有无锚定边界框。在 YOLO 的最初版本中,用户需要手动识别这些锚定框,以便促进对象检测过程。这些预定义的边界框具有预定的大小和高度,捕获数据集中特定对象类别的比例和纵横比。从这些边界到预测对象的偏移量有助于模型更好地识别对象的位置。
在 YOLOv8 中,这些锚定框会自动预测在对象的中心。
在训练结束前停止马赛克增强
在训练的每个时期,YOLOv8 都会看到它所提供的图像的略微不同的版本。这些变化被称为增强。其中之一,马赛克增强,是将四个图像组合在一起的过程,强制模型学习对象在新位置的身份,通过遮挡部分地阻挡彼此,周围像素的变化更大。已经证明,在整个训练过程中使用这种增强会对预测准确性产生不利影响,因此在训练的最后几个时期,YOLOv8 可以停止这个过程。这允许最佳的训练模式在不扩展到整个运行的情况下运行。
效率和准确性
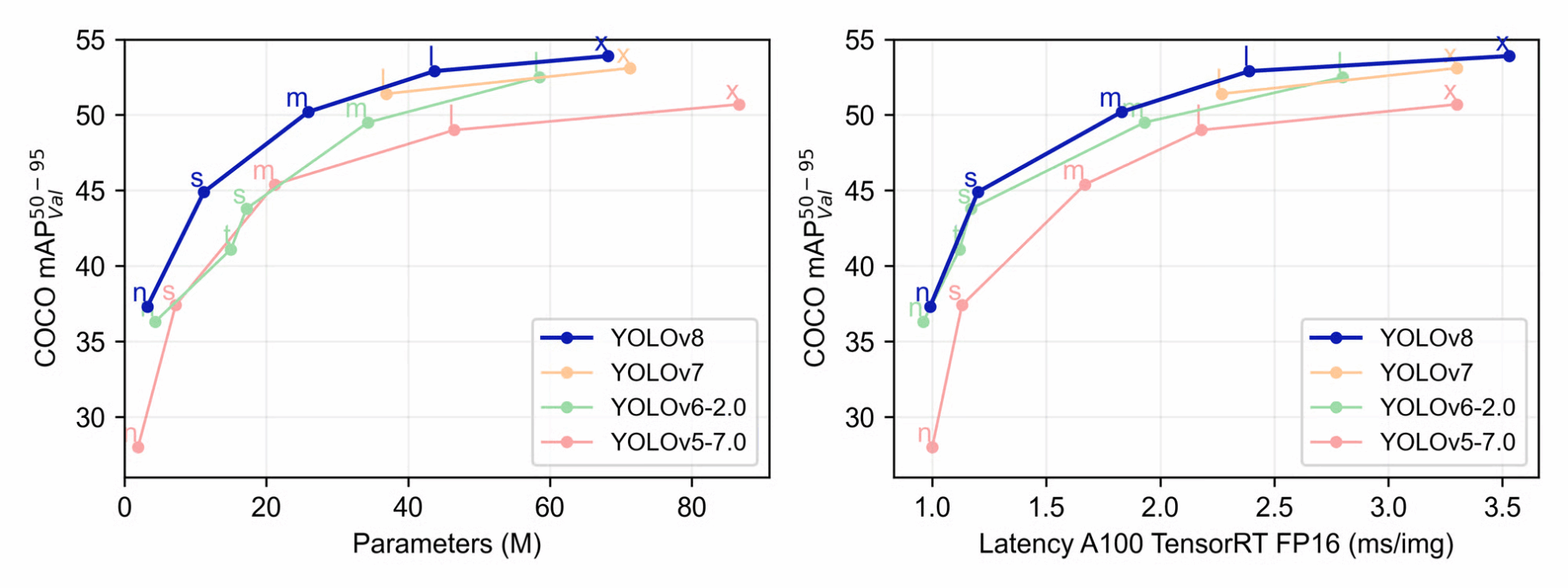
我们在这里的主要原因是在推理和训练过程中提高性能准确性和效率。 Ultralytics 的作者为我们提供了一些有用的样本数据,我们可以用来比较新版本的 YOLO 和其他版本。从上面的图表中可以看出,在训练过程中,YOLOv8 在平均精度、大小和延迟方面优于 YOLOv7 、 YOLOv6-2.0 和 YOLOv5-7.0 。

在它们各自的 Github 页面上,我们可以找到不同大小的 YOLOv8 模型的统计比较表。从上表中可以看出,随着参数、速度和 FLOPs 的大小增加,mAP 也会增加。最大的 YOLOv5 模型 YOLOv5x 的最大 mAP 值为 50.7 。 mAP 值的 2.2 单位增加代表了能力的显著提高。这在所有模型大小上都得到了保持,新的 YOLOv8 模型始终优于 YOLOv5,如下所示。

总的来说,我们可以看出,YOLOv8 是从 YOLOv5 和其他竞争框架中迈出的重要一步。
微调 YOLOv8
运行教程:在 OpenBayes 上开启线上运行
微调 YOLOv8 模型的过程可以分为三个步骤:创建和标记数据集、训练模型和部署模型。在本教程中,我们将详细介绍前两个步骤,并展示如何在任何传入的视频文件或流上使用我们的新模型。
设置数据集
我们将重新创建我们用于比较两个模型的 YOLOv7 实验,因此我们将返回到 Roboflow 上的篮球数据集。请查看上一篇文章的「设置自定义数据集」部分,以获取设置数据集、标记数据集并将其从 RoboFlow 拉入我们的 Notebook 的详细说明。
由于我们使用的是以前制作的数据集,因此现在只需要将数据拉入即可。以下是用于将数据拉入 Notebook 环境的命令。对于您自己标记的数据集,请使用相同的过程,但将工作区和项目值替换为您自己的值,以相同的方式访问您的数据集。
请确保如果您想使用下面的脚本跟随 Notebook 中的演示,则将 API 密钥更改为您自己的。
!pip install roboflow
from roboflow import Roboflow
rf = Roboflow(api_key="")
project = rf.workspace("james-skelton").project("ballhandler-basketball")
dataset = project.version(11).download("yolov8")
!mkdir datasets
!mv ballhandler-basketball-11/ datasets/训练模型
使用新的 Python API,我们可以使用 ultralytics 库在 Gradient Notebook 环境中轻松完成所有工作。我们将使用提供的配置和权重从头构建 YOLOv8n 模型。然后,我们将使用刚刚加载到环境中的数据集,使用 model.train() 方法进行微调。
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.yaml") # 从头构建新模型
model = YOLO("yolov8n.pt") # 加载预训练模型(建议用于训练)
# 使用模型
results = model.train(data="datasets/ballhandler-basketball-11/data.yaml", epochs=10) # 训练模型测试模型
results = model.val() # 在验证集上评估模型性能我们可以使用 model.val() 方法 将新模型设置为在验证集上评估。这将在输出窗口中输出一个漂亮的表格,显示我们的模型的表现如何。由于我们只在这里训练了十个时期,因此可以预期这个相对较低的 mAP 50-95 。

从那里开始,提交任何照片都很简单。它将输出边界框的预测值,将这些框叠加到图像上,并上传到 “runs/detect/predict” 文件夹。
from ultralytics import YOLO
from PIL import Image
import cv2
# from PIL
im1 = Image.open("assets/samp.jpeg")
results = model.predict(source=im1, save=True) # 保存绘制的图像
print(results)
display(Image.open('runs/detect/predict/image0.jpg'))我们得到了边界框和它们的标签的预测,如下所示:
[Ultralytics YOLO <class 'ultralytics.yolo.engine.results.Boxes'> masks
type: <class 'torch.Tensor'>
shape: torch.Size([6, 6])
dtype: torch.float32
+ tensor([[3.42000e+02, 2.00000e+01, 6.17000e+02, 8.38000e+02, 5.46525e-01, 1.00000e+00],
[1.18900e+03, 5.44000e+02, 1.32000e+03, 8.72000e+02, 5.41202e-01, 1.00000e+00],
[6.84000e+02, 2.70000e+01, 1.04400e+03, 8.55000e+02, 5.14879e-01, 0.00000e+00],
[3.59000e+02, 2.20000e+01, 6.16000e+02, 8.35000e+02, 4.31905e-01, 0.00000e+00],
[7.16000e+02, 2.90000e+01, 1.04400e+03, 8.58000e+02, 2.85891e-01, 1.00000e+00],
[3.88000e+02, 1.90000e+01, 6.06000e+02, 6.58000e+02, 2.53705e-01, 0.00000e+00]], device='cuda:0')]然后将它们应用到图像中,如下面的示例所示:

正如我们所看到的,我们轻量级训练的模型表明它可以从场上的球员和场边的球员和观众中识别出球场上的球员,只有一个角落的例外。几乎肯定需要更多的训练,但很容易看出模型非常快地获得了任务的理解。
如果我们对模型训练感到满意,那么我们可以将模型导出为所需的格式。在这种情况下,我们将导出一个 ONNX 版本。
success = model.export(format="onnx") # 将模型导出为 ONNX 格式总结
在本教程中,我们研究了 Ultralytics 强大的新模型 YOLOv8 的新功能,深入了解了与 YOLOv5 相比的架构变化,并通过在新模型上测试我们的 Ballhandler 数据集来测试新模型的 Python API 功能。我们能够展示这代表了简化微调 YOLO 目标检测模型过程的重要进展,并展示了该模型在使用比赛中的照片来区分 NBA 比赛中的球权方面的能力。