Command Palette
Search for a command to run...
Professor Hong Liang Von Der Shanghai Jiao Tong University: Wenn KI Im Ingenieurwesen Wirklich Durchbrechen Will, Muss Sie Technische Ergebnisse Erzielen, Die Bestehende Menschliche Experten Nicht Erreichen Können

Kürzlich ging die AI for Bioengineering Summer School der Shanghai Jiao Tong University erfolgreich zu Ende. Mehr als 100 Branchenexperten, Wirtschaftsvertreter und herausragende Nachwuchswissenschaftler aus Unternehmen, Forschungseinrichtungen und Universitäten kamen zusammen, um sich intensiv über die Anwendung von KI im Bereich der Biotechnik auszutauschen.
In,Hong Liang, angesehener Professor für naturwissenschaftliche Forschung an der Fakultät für Physik und Astronomie sowie der Fakultät für Pharmazie der Shanghai Jiao Tong University, erläuterte auf einfache und leicht verständliche Weise die Anwendung von KI in der wissenschaftlichen Forschung, insbesondere im Proteindesign, sowie seinen Ausblick auf die zukünftige Entwicklung von KI für die Wissenschaft.
Auszüge der wichtigsten Standpunkte:
* Um KI wirklich in der Wissenschaft einzusetzen, muss man zunächst das wissenschaftliche Problem definieren und dann eine Lösung auf Basis künstlicher Intelligenz finden.
* AI kann Hunderte von Aminosäuresequenzen transformieren und dabei eine gute Aktivität und eine hohe Positivrate aufrechterhalten. Bei dieser Art der Sequenzgenerierungsaufgabe ist KI menschlichen Experten weit überlegen. * Im Bereich des Protein-Engineerings gibt es die meisten negativen Daten. KI kann negative und positive Stellen kombinieren und so den Vorstellungsraum der Proteintechnik erweitern. Dies geht über den rationalen Entwurfsspielraum professioneller Enzymingenieure hinaus. KI hat den alten Weg der physikalischen Berechnung im Wesentlichen ersetzt. * Wenn künstliche Intelligenz in einem technischen Bereich einen Durchbruch erzielen will, geht es nicht nur darum, Wissenschaftlern als Assistent zur Seite zu stehen und grundlegende Arbeiten wie das Sammeln von Literatur zu übernehmen, sondern darum, Dinge zu tun, die menschliche Experten nicht leisten können. * In den nächsten drei Jahren wird die allgemeine künstliche Intelligenz in professionellen Bereichen in den Bereichen Proteindesign, Arzneimittelentwicklung, Krankheitsdiagnose, Entdeckung neuer Zielmoleküle, Design chemischer Synthesewege und Materialdesign einen deutlichen Paradigmenwechsel herbeiführen und das wissenschaftliche Entdeckungsmodell, das früher auf sporadischem Ausprobieren des menschlichen Gehirns beruhte, in ein automatisiertes Standarddesignmodell mit großen KI-Modellen umwandeln.
HyperAI hat die wunderbaren Beiträge von Professor Hong Liang zusammengestellt und zusammengefasst, ohne die ursprüngliche Absicht zu verletzen. Nachfolgend finden Sie eine Abschrift der wichtigsten Punkte der Rede.

KI-Kunststudenten vs. KI-Wissenschaftsstudenten
Professor Hong Liang stellte die Anwendung von KI im Leben (KI für das Leben) und in der wissenschaftlichen Forschung (KI für die Wissenschaft) aus der Perspektive von KI-Studenten der Geisteswissenschaften bzw. KI-Studenten der Wissenschaften vor.
KI-Studierende der Geisteswissenschaften: Persönliche Assistenten im Leben
In Bezug auf „AI for Life“ glaubt Professor Hong Liang, dass die aktuelle KI zu einem persönlichen Assistenten im Leben der Menschen geworden ist und ihnen hilft, die Belastung durch repetitive, kreative und unwissenschaftliche Arbeit zu reduzieren.Seine Besonderheiten liegen darin, dass der Umfang der für das Training verfügbaren Daten bereits sehr groß ist und die generierten Ergebnisse keine hohe Genauigkeit erfordern. Daher verfügt es über starke domänenübergreifende Generalisierungsfunktionen und kann große domänenübergreifende Modelle erstellen.
Anschließend verwendete er konkrete Fälle wie die KI-Textgenerierung, KI-Bildgenerierung, KI-Videogenerierung usw., kombiniert mit den derzeit beliebten großen Modellen, um die Anwendung von KI im Leben anschaulich zu beschreiben.
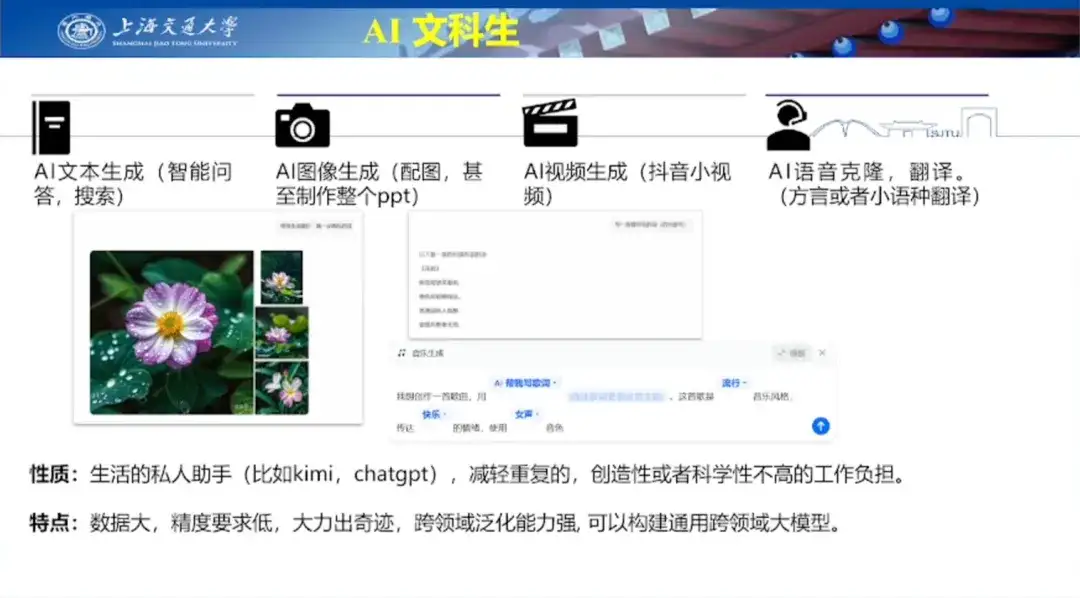
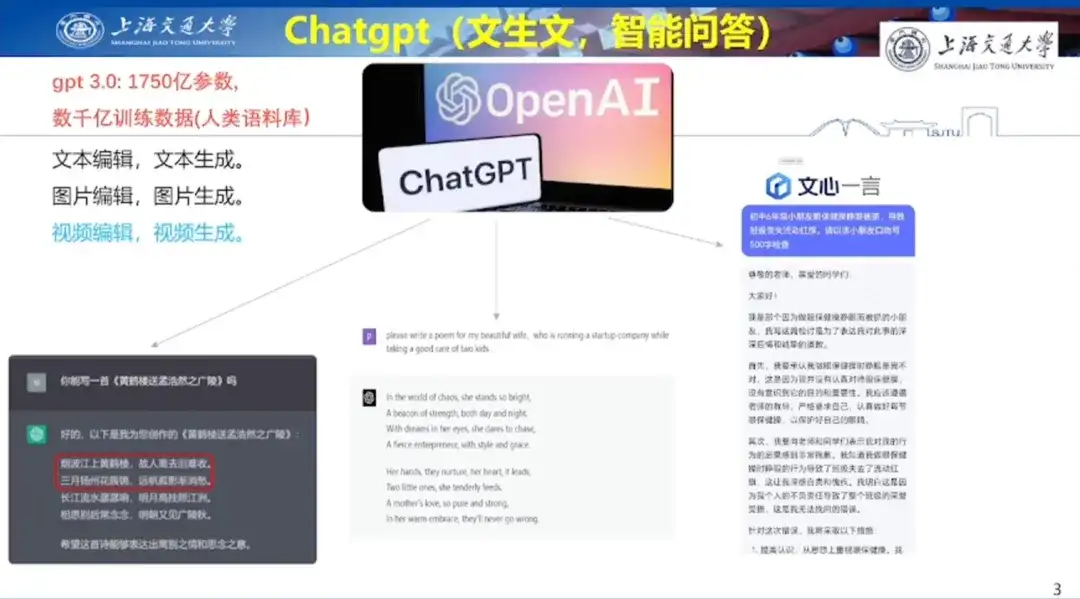
In Bezug auf die KI-Textgenerierung demonstrierte Professor Hong Liang die Fähigkeiten von ChatGPT zur Gedichterstellung am Beispiel des Schreibens eines Gedichts für seine Frau zum Valentinstag. Gleichzeitig teilte er auch das Beispiel mit, wie er seinem Sohn in der Grundschule mithilfe von Wen Xin Yi Yan beim Verfassen einer Selbstkritik geholfen hatte, und demonstrierte damit Wen Xin Yi Yans Fähigkeit zur Texterstellung.
In Bezug auf die KI-Bildgenerierung demonstrierte Professor Hong Liang Baidu Wenxin Yiyan, Adobe Firefly und Midjourney sowie die unterschiedlichen Effekte, die basierend auf denselben Eingabeaufforderungswörtern generiert wurden, wie in der folgenden Abbildung dargestellt.

In Bezug auf die KI-Videogenerierung demonstrierte Professor Hong Liang die leistungsstarken Fähigkeiten des beliebten Sora bei der Videogenerierung. Er nannte das Beispiel eines von Sora erstellten Videos einer modischen Dame, die in Tokio die Straße entlanggeht, und lobte die One-Shot-Technik und die detaillierte Verarbeitung der im Video gezeigten Gesichtsporen.
Gleichzeitig stimmte er auch der Einschätzung von Brancheninsidern zu, dass „Sora eine datengesteuerte Physik-Engine ist“, und glaubte, dass Vincent Video den Inhaltserstellern auf Plattformen wie TikTok eine große Hilfe gewesen sei.

KI-Wissenschaftsstudenten: Wissenschaftler, die eine Klasse wissenschaftlicher Probleme lösen
Für KI-Wissenschaftsstudenten, also KI für die Wissenschaft oder KI für das Ingenieurwesen, glaubt Professor Hong Liang „Es handelt sich um einen Wissenschaftler, der eine Art wissenschaftliches Problem löst. Im Wesentlichen geht es darum, einen Wissenschaftler für verschiedene Bereiche wie Biomedizin, Materialchemie, Kernphysik usw. auszubilden.“Die Kernschwierigkeit besteht darin, dass die Genauigkeitsanforderungen sehr hoch sind und relativ wenige Funktionsdaten für das Training zur Verfügung stehen, sodass nur proprietäre KI-Modelle erstellt werden können.

Um allen ein besseres Verständnis für die Anwendung von KI in der Wissenschaft zu vermitteln, hat Professor Hong Liang eine eingehende Analyse anhand spezifischer Fälle wie KI für Biologie/Medizin, KI für Materialien/Chemie und KI für kontrollierte Kernfusion durchgeführt.
Der erste Fall ist die KI im biologischen Bereich.Professor Hong Liang sagte: „Die Vorhersage der dreidimensionalen Proteinstruktur ist der wichtigste Ausgangspunkt für KI in der Wissenschaft.“ Er führte aus, dass die Vorhersage der Proteinstruktur den Wissenschaftlern seit fast 50 Jahren Kopfzerbrechen bereitet. „Bevor DeepMind das AlphaFold-Modell veröffentlichte, glaubten Wissenschaftler im Allgemeinen, dass die Verwendung von KI zur Vorhersage der Proteinstruktur nur ein Spiel sei.“
Von AlphaFold 1 bis AlphaFold 3 hat die KI ihre Leistungsfähigkeit bei der Vorhersage dreidimensionaler Proteinstrukturen unter Beweis gestellt. Insbesondere wurde die Genauigkeit von AlphaFold 3 im Vergleich zu vielen früheren Spezialwerkzeugen, wie etwa Protein-Ligand-Interaktion, Protein-Nukleinsäure-Interaktion und Antikörper-Antigen-Vorhersage, deutlich verbessert.
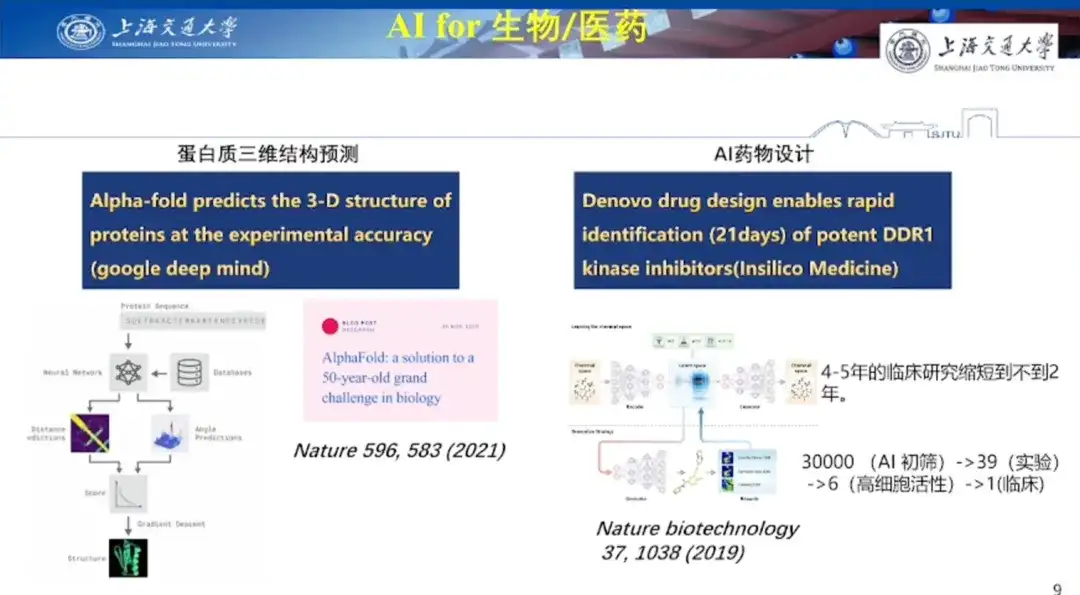
Der zweite Fall ist die Entwicklung von Medikamenten auf Basis künstlicher Intelligenz.Professor Hong Liang sagte, dass die Entwicklung von Medikamenten mithilfe künstlicher Intelligenz relativ schwierig sei, da die Anwendung nicht nur Probleme auf molekularer Ebene lösen müsse, sondern auch mit den Herausforderungen nachfolgender klinischer Studien konfrontiert sei. Bei herkömmlichen Methoden der Arzneimittelforschung, wie etwa dem Hochdurchsatz-Screening, werden Tausende kleiner Moleküle getestet und nur eine kleine Zahl von Leitsubstanzen gewonnen, von denen nur eine von zehn oder sogar weniger die klinischen Tests besteht.
Im Jahr 2019 in Nature Biotechnology veröffentlichte Forschungsergebnisse zeigten das enorme Potenzial der KI in der Arzneimittelentwicklung. Mithilfe von bestärkendem Lernen (GENTRL) entdeckten Forscher innerhalb von 21 Tagen wirksame Inhibitoren des Discoidin-Domänenrezeptors 1 (DDR1), einem mit fibrotischen Erkrankungen assoziierten Kinaseziel. Mithilfe von KI-Technologie filterten die Forscher zunächst 30.000 Moleküle heraus und führten dann 39 Zellexperimente mit verschiedenen Screening-Methoden durch. Dabei fanden sie sechs Moleküle mit hoher Zellaktivität und führten schließlich eines davon in die klinische Erprobung ein.
Darüber hinaus führte Professor Hong Liang auch Fälle von KI im Bereich Materialien/Chemie an.Er glaubt, dass„KI für Materialien, insbesondere chemische Materialien, ist schwierig umzusetzen.“Materialien sind jedoch nicht mit natürlichen Sprachen, menschlichen Sprachen und DNA-Sequenzen vergleichbar. Sie haben keine diskreten Token. Da es sich bei Materialien im Wesentlichen um ein dreidimensionales Strukturproblem handelt, ist es beim Erstellen eines großen Modells erforderlich, DFT-Berechnungen, automatisierte Experimente und KI zu kombinieren, um die Synthese spezifischer anorganischer Verbindungen rekursiv zu fördern. Beispielsweise hat das DeepMind-Materialteam im Jahr 2023 das auf Deep Learning basierende Graph Network for Materials Exploration (GNoME) auf den Markt gebracht. In einer Testaufgabe synthetisierte das A-Lab-Labor innerhalb von 17 Tagen erfolgreich 41 der 58 vorhergesagten Materialien, was erst in den letzten 10 Jahren oder sogar noch länger möglich war.

Abschließend verwies Professor Hong Liang auf Fälle wie die KI für die kontrollierte Kernfusion und sagte, dass die Fortschritte in dieser Richtung sehr erfreulich seien.Er wies darauf hin, dass das Hauptproblem bei der Kernfusion derzeit darin liege, dass das Plasma sehr leicht „zerrissen“ werden und aus dem starken Magnetfeld, in dem es eingeschlossen ist, entweichen könne, wodurch die Fusionsreaktion unterbrochen werde. Das Princeton-Team entwickelte einen KI-Controller, der das potenzielle Risiko eines Plasmarisses 300 Millisekunden im Voraus vorhersagen und rechtzeitig eingreifen kann.
Wie in der folgenden Abbildung dargestellt, haben die Forscher traditionelle physikbasierte Methoden mit fortschrittlichen KI-Techniken integriert, um die Kontrolle und das Verständnis des Plasmaverhaltens zu verbessern. Die folgenden Abbildungen a, b und c zeigen den Zustand des Plasmas in einem Fusionsreaktor.
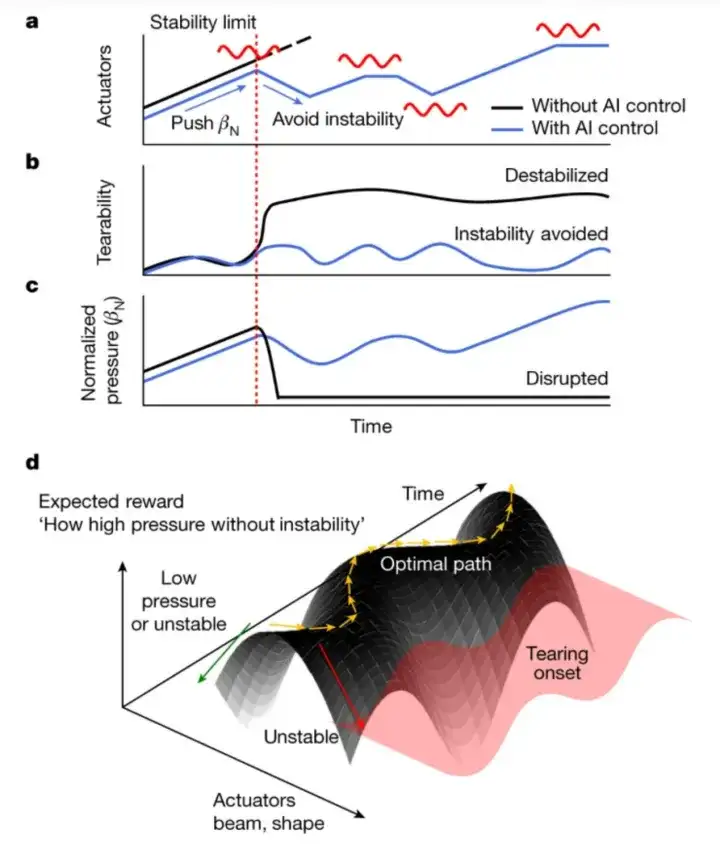
Die schwarze Linie in Feld a zeigt, dass bei einer Erhöhung des Plasmadrucks durch Erhöhung der Außentemperatur (z. B. ein neutraler Teilchenstrahl) schließlich eine Stabilitätsgrenze erreicht wird. Bei Überschreiten dieser Grenze kommt es zur Anregung von Reißinstabilitäten. Sobald die Tearing-Instabilität angeregt wird, wird das Plasma schnell zerstört, was im tatsächlichen Betrieb zu schwerwiegenden Folgen führen kann, wie in den Abbildungen b und c gezeigt.
Auf der Grundlage tiefer neuronaler Netzwerke und bestärkendem Lernen entwickelten die Forscher ein intelligentes Steuerungssystem, das in Echtzeit auf Änderungen des Plasmazustands reagieren, den zukünftigen Zustand des Plasmas vorhersagen und die Steuerungsmaßnahmen entsprechend anpassen kann, sodass der Tokamak-Betrieb dem idealen Verlauf folgt und Rissinstabilitäten bei gleichzeitiger Aufrechterhaltung eines hohen Drucks vermieden werden.
Abschließend betonte Professor Hong Liang:„Um KI wirklich in der Wissenschaft einzusetzen, muss man zunächst das wissenschaftliche Problem definieren und dann eine KI-Lösung finden.“
KI für Bioengineering: Technische Probleme lösen und Produkte für mehrere Szenarien implementieren
Anschließend erläuterte Professor Hong Liang die Definition und Herausforderungen des traditionellen Protein-Engineerings, die Anwendung von KI im Bereich des Protein-Engineerings, die F&E-Ergebnisse des Teams und deren Umsetzung sowie die wichtigsten Vorteile des Teams und verdeutlichte so den Wert von KI für das Bioengineering.
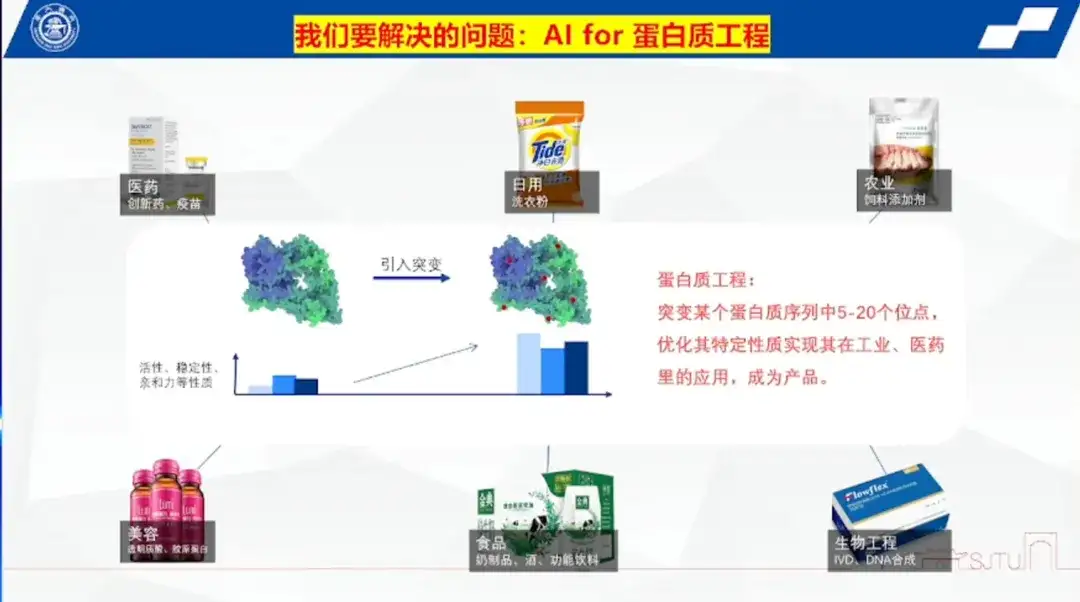
Protein-Engineering: Mutation von Proteinsequenzstellen zur Erfüllung der Produktanwendungsanforderungen
Professor Hong Liang wies darauf hin, dass es sich beim Protein-Engineering um die Mutation von 5 bis 20 Stellen in einer Proteinsequenz handelt, um deren spezifische Eigenschaften zu optimieren und ihre Anwendung in Industrie und Medizin zu realisieren und sie so in ein Produkt umzuwandeln.
Er erklärte, dass Protein nicht nur ein wichtiger Bestandteil von Organismen, sondern auch ein unverzichtbares Produkt im täglichen Leben der Menschen sei. Enzyme werden als Proteinmoleküle häufig in industriellen Szenarien eingesetzt und haben eine katalytische Wirkung. Beispiele hierfür sind Antikörper-ADC-gebundene Enzyme im Bereich innovativer Arzneimittel, Enzyme in Waschmitteln, Enzymzusätze in Futtermitteln, die den Stoffwechsel von Tieren unterstützen, und verschiedene Enzyme in den Bereichen Schönheit, Lebensmittel und Biotechnik.
Anschließend stellte Professor Hong Liang die beiden gängigsten Verfahren der aktuellen Proteintechnik vor.
Das erste ist rationales Design/semi-rationales Design.Im Allgemeinen ist es notwendig, die Proteinstruktur und den katalytischen Mechanismus genau zu untersuchen und dann entsprechend dem Mechanismus Modifikationen vorzunehmen. Der Nachteil des rationalen Designs besteht jedoch darin, dass es zeitaufwändig ist, die zu ändernden Sites sich hauptsächlich um die aktiven Taschen herum konzentrieren, der Gestaltungsspielraum relativ begrenzt ist und auch der Denkspielraum eingeschränkt ist.
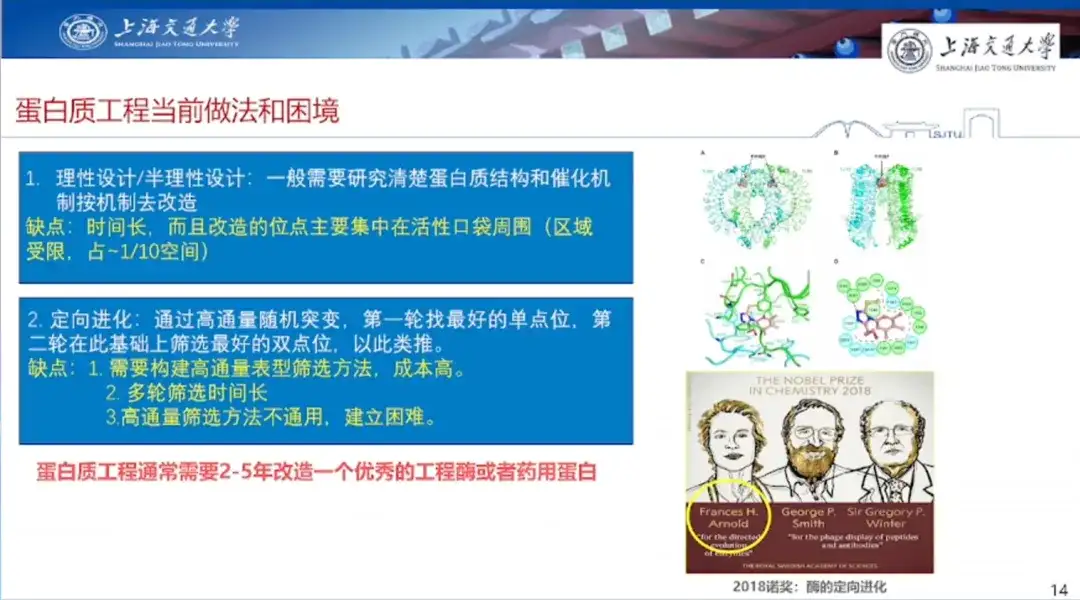
Die zweite ist die gerichtete Evolution.Das heißt, das menschliche Denkparadigma wird durchbrochen, indem man Hochdurchsatz-Screening und Hochdurchsatz-Einzelstellen-Zufallsmutagenese auf Basis der Natur durchführt, in der ersten Runde nach dem besten Einzelstellenmutanten sucht und in der zweiten Runde auf dieser Basis den besten Doppelstellenmutanten durchsucht und so weiter. Der Vorteil besteht darin, dass es nicht auf Erfahrungen aus der Vergangenheit beruht und nur mit Geld durchgeführt werden kann. Der Nachteil besteht darin, dass hierfür die Entwicklung einer phänotypischen Hochdurchsatz-Screeningmethode erforderlich ist, die kostspielig ist, eine lange Screeningrunde erfordert und Hochdurchsatz-Screeningmethoden nicht universell einsetzbar und schwer zu etablieren sind.
Professor Hong Liang stellte das Experiment zum grün fluoreszierenden Protein am Beispiel der 2016 in Nature veröffentlichten Forschungsarbeit vor. Er wies darauf hin, dass bei diesem Experiment zwar durch Hochdurchsatz-Screening positive Stellen ausgewählt und die Eigenschaften des Proteins verbessert werden können, wenn die Forscher die Stellen einzeln mutieren, das synthetische Protein jedoch seine Aktivität verliert, wenn mehrere Mutationsstellen kombiniert werden.
Er sagte:„Die Herausforderung, vor der das Protein-Engineering derzeit steht, besteht darin, im riesigen Phasenraum hervorragende Mutationsstellen zu finden und diese zu hervorragenden Multi-Site-Mutanten zu kombinieren, um ihren Anwendungswert zu realisieren.“

Allgemeine künstliche Intelligenztechnologie für das Protein-Engineering: End-to-End-funktionsorientiertes Sequenzdesign
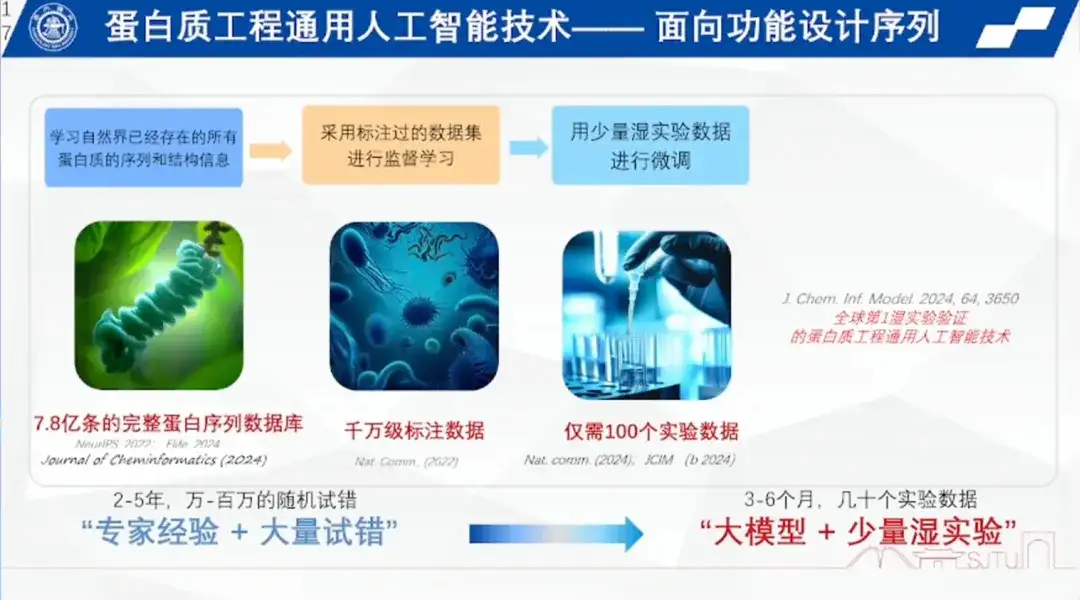
„Wenn künstliche Intelligenz einen Durchbruch in einem technischen Bereich erzielen will, geht es nicht nur darum, einen Assistenten für Wissenschaftler zu bauen und grundlegende Arbeiten wie das Sammeln von Literatur zu erledigen, sondern darum, Dinge zu tun, die menschliche Experten nicht leisten können.“Auf dieser Grundlage begann das Team von Professor Hong Liang im Jahr 2021 mit der Erforschung proprietärer Modelle im Bereich des Protein-Engineerings und entwarf durchgängig funktionelle Sequenzen.
Das Forschungsteam stellte eine Datenbank mit Hunderten Millionen vollständiger Proteinsequenzen zusammen, die auf allen bekannten Proteinen in der Natur basieren, und entwickelte eine allgemeine künstliche Intelligenz für das Protein-Engineering, um auf der Grundlage dieser Datenbank die Anordnung und Regeln von Aminosäuren zu erlernen.
Professor Hong Liang erläuterte ausführlich die Anwendungsszenarien allgemeiner künstlicher Intelligenztechnologie im Protein-Engineering anhand von fünf praktischen Anwendungsfällen aus der Praxis. Dazu gehörten die Zusammenarbeit mit Professor Liu Jia von der ShanghaiTech University zur Verbesserung der thermischen Stabilität von Crisper cas12a, die Zusammenarbeit mit Jinsai Pharmaceutical zur Verbesserung der alkalischen Resistenz von Einzeldomänen-Antikörpern und die Zusammenarbeit mit Hanhai New Enzymes zur Einführung enzymatischer Innovationen.
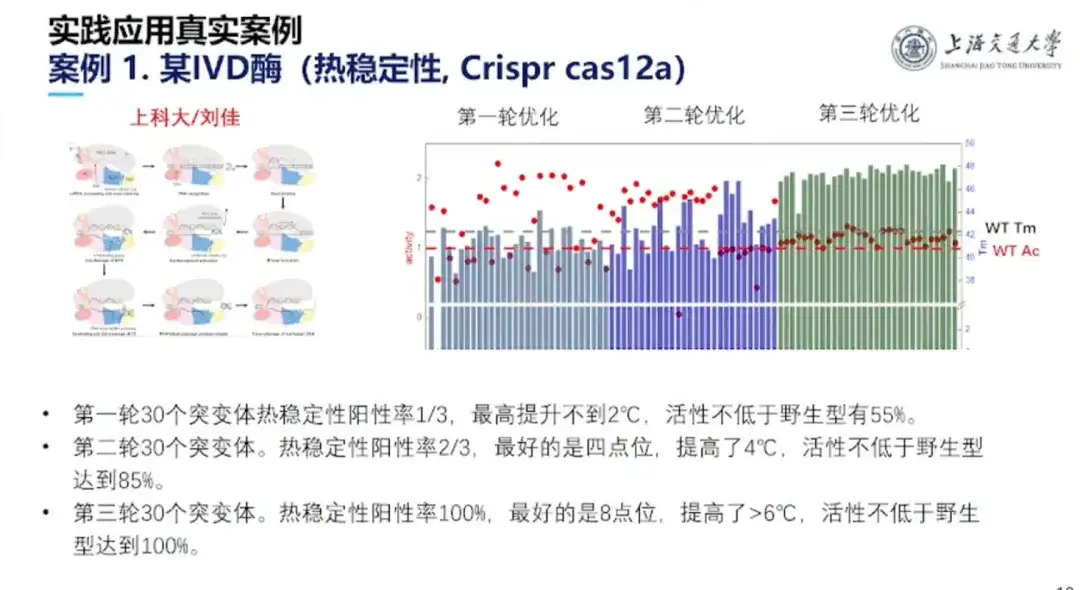
Fall 1: Verbesserung der thermischen Stabilität von Crisper cas12a
Dieses Projekt wurde vom Team von Professor Hong Liang und Professor Liu Jia von der ShanghaiTech University durchgeführt. Crisper cas12a besteht aus 1.300 Aminosäuren. Der Wildtyp weist eine gute Aktivität, aber eine geringe Stabilität auf. Als In-vitro-Diagnostikkit kann es nicht bei Raumtemperatur verwendet werden und die Kühlkosten sind hoch. Zu diesem Zweck führte das Forschungsteam drei Experimentierrunden durch. Schließlich erreichte die Stabilität des Mutanten einen kontinuierlich zunehmenden Zustand und das Verhältnis der Proteinaktivität, das nicht niedriger war als das des Wildtyps, erreichte 100%.
Professor Hong Liang stellte vor:„Das Gebiet des Protein-Engineerings weist die meisten negativen Daten auf. KI kann negative und positive Stellen kombinieren und so den Vorstellungsraum des Protein-Engineerings erweitern. Dies geht über den rationalen Entwurfsspielraum professioneller Enzymingenieure hinaus. KI hat im Grunde den alten Weg der physikalischen Berechnung ersetzt.“
Darüber hinaus stellte er die zugrunde liegende Logik vor, mit der KI Daten zu negativen und positiven Proteinmutationen kombiniert. Diese Logik ist in drei Schritte unterteilt.
Der erste Schritt besteht darin, ein Proteinsprachenvokabular aufzubauen.Er verglich den Prozess des Vorabtrainings von Proteinsequenzinformationen mit einem Cloze-Test, bei dem mithilfe eines Modells jede beliebige Sequenz in einer Datenbank mit Hunderten Millionen vollständiger Proteinsequenzen entweder kontinuierlich oder diskret nach dem Zufallsprinzip blockiert wird und das Modell dann die blockierten Bereiche ausfüllen kann. Dieser Vorgang wird in mehreren Runden wiederholt, um sicherzustellen, dass ein Modell Hunderte Millionen Proteinsequenzen vorab trainieren und so ein Vokabular der Proteinsprache aufbauen kann.
Der zweite Schritt ist die Beschriftung.Das Forschungsteam hat zig Millionen solcher Parameter markiert, beispielsweise Temperatur, Druck und pH-Wert.
Der dritte Schritt ist das Lernen kleiner Stichproben.Das heißt, die Feinabstimmung wird mithilfe einer kleinen Menge nasser experimenteller Daten durchgeführt, um das bestärkende Lernen abzuschließen und so das Problem der kleinen Stichproben in der Biotechnik zu lösen.

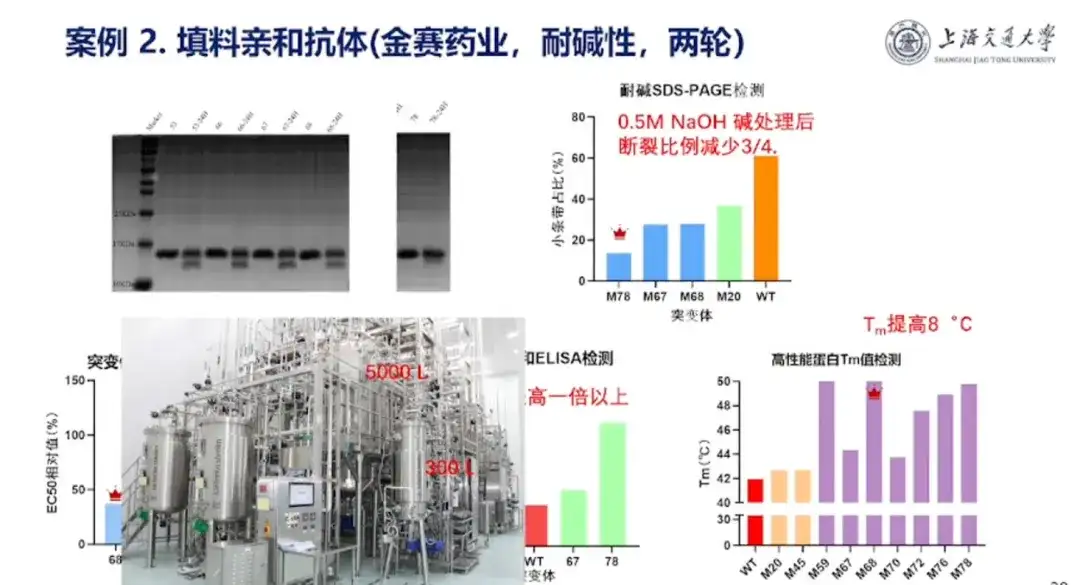
Fall 2: Zusammenarbeit mit Jinsai Pharmaceuticals bei der Entwicklung extrem alkaliresistenter Einzeldomänen-Antikörper
Professor Hong Liang wies darauf hin, dass Jinsai Pharmaceutical Wachstumshormone häufig dadurch reinigt, dass es Einzeldomänen-Antikörper aus der Alpaka-Einzeldomänen-Antikörperbibliothek filtert und sie auf eine Wasserstoffsäule legt. Während des Reinigungsprozesses werden Wasserstoff und Säulen jedoch zwangsläufig durch einige Verunreinigungen verunreinigt und müssen mit starker Lauge gereinigt werden, bevor sie im nächsten Reinigungsexperiment verwendet werden können. Allerdings sind Organismen gegenüber starken Laugen nicht resistent und es besteht Korrosionsgefahr. Daher hofft Jinsai Pharmaceutical, die alkalische Resistenz von Einzeldomänen-Antikörpern zu verbessern.
In diesem ZusammenhangDas Forschungsteam behandelte die vom großen Modell der Pro-Serie entwickelten Einzeldomänen-Antikörper 24 Stunden lang mit 0,5 M NaOH und verbesserte erfolgreich die alkalische Resistenz der Einzeldomänen-Antikörper.Das in diesem Projekt entwickelte alkaliresistente Protein hat eine Massenproduktion von 5.000 l erreicht.Es handelt sich um das erste großtechnisch hergestellte Proteinprodukt, das industriell eingesetzt werden konnte.
Fall 3: Verbesserung der Selektivität, Aktivität und Ausbeute von Glykosyltransferasen durch Enzyminnovation
Das Kernmaterial für das Screening auf akute Pankreatitis und Sialadenitis ist Maltoheptaglykosid, das eine sehr komplexe Struktur und hohe chemische Produktionskosten aufweist. In China wird es für Hunderttausende Yuan pro Kilogramm verkauft. Als Reaktion darauf haben das Team von Professor Hong Liang und Hanhai New Enzyme gemeinsam eine enzymatische Innovation auf den Markt gebracht, bei der eine Glykosyltransferase zur Herstellung von Maltoheptaglykosid verwendet wird. Das Forschungsteam muss vier Indikatoren verbessern, nämlich die Transglykosylierungsreaktion verbessern, die Reaktionsspezifität verbessern, die Hydrolyseaktivität verringern und die Ausbeute erhöhen.
Durch zwei Runden von Transformationsexperimenten verbesserten die Forscher den BUG-Index von 80 Mutanten, erhöhten die gesamte Transglykosylierungsaktivität um das Achtfache, erhöhten die Reinheit des Zielprodukts von 80 auf 95, reduzierten den Hydrolyseaktivitätsindex auf 10 und verdoppelten die P3-Ausbeute.Die Produktion dieses Produkts wurde bereits auf einer 1.000-Kilogramm-Produktionslinie in Yichang, Hubei, aufgenommen, wodurch die Produktionskosten erheblich gesenkt wurden.
Fall 4: Antikörperaffinitätstest basierend auf Small-Sample-Learning im Einfachblindtest
„KI für die Wissenschaft muss das Problem kleiner Stichproben lösen. Das bloße Veröffentlichen von Artikeln hat wenig praktischen Nutzen.“ Professor Hong Liang erläuterte dies anhand einer Demo, die in Zusammenarbeit mit einem Antikörper-Pharmaunternehmen durchgeführt wurde.
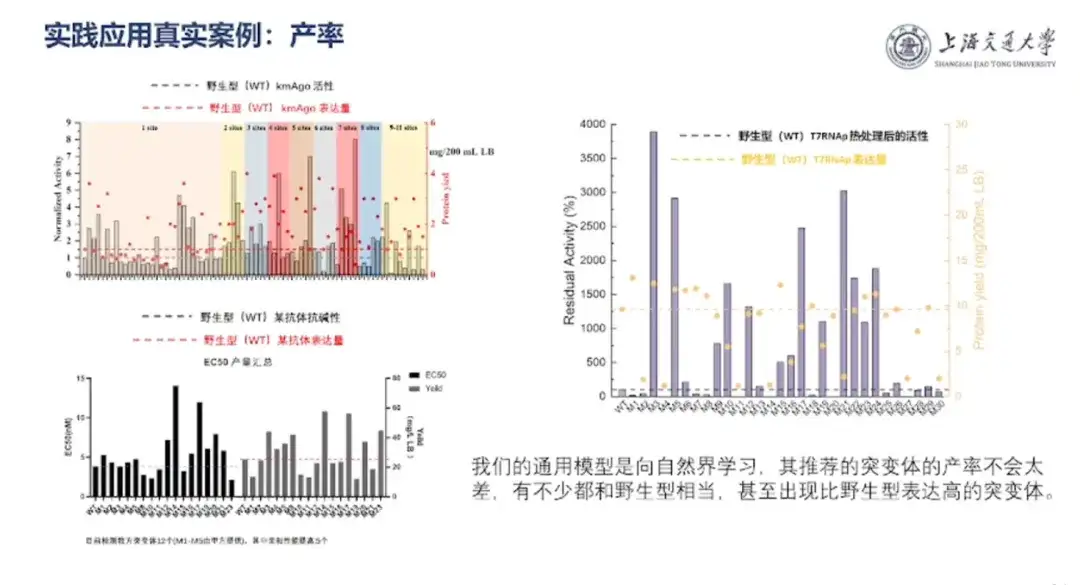
Professor Hong Liang stellte vor, dass es sich um einen ScFv-Antikörper mit einer Gesamtlänge von 245 Aminosäuren und 21 Mutationsstellen handelt und dass seine möglichen Mutationssequenzen 10 Millionen überschreiten. Der Mitarbeiter lieferte jedoch nur Affinitätsdaten für 33 bekannte Mutanten und Affinitätsdaten für 14 neue Sequenzen, von denen angenommen wurde, dass sie unbekannt sind. Basierend auf dem Lernen anhand kleiner Stichproben erreichte das Team in einem Einfachblindtest einen Korrelationskoeffizienten von 0,65.
„Ob Biomedizin oder synthetische Biologie, bei der endgültigen Umsetzung muss noch die Kostenfrage gelöst werden, das heißt, der Ertrag muss hoch sein.“Professor Hong Liang führte aus: „Das KI-Proteindesignmodell des Teams lernt von der Natur und die Ausbeute der von ihm empfohlenen Mutanten wird nicht allzu schlecht sein. Viele von ihnen sind mit dem Wildtyp vergleichbar und es gibt sogar Mutanten mit einer höheren Expression als der Wildtyp.“
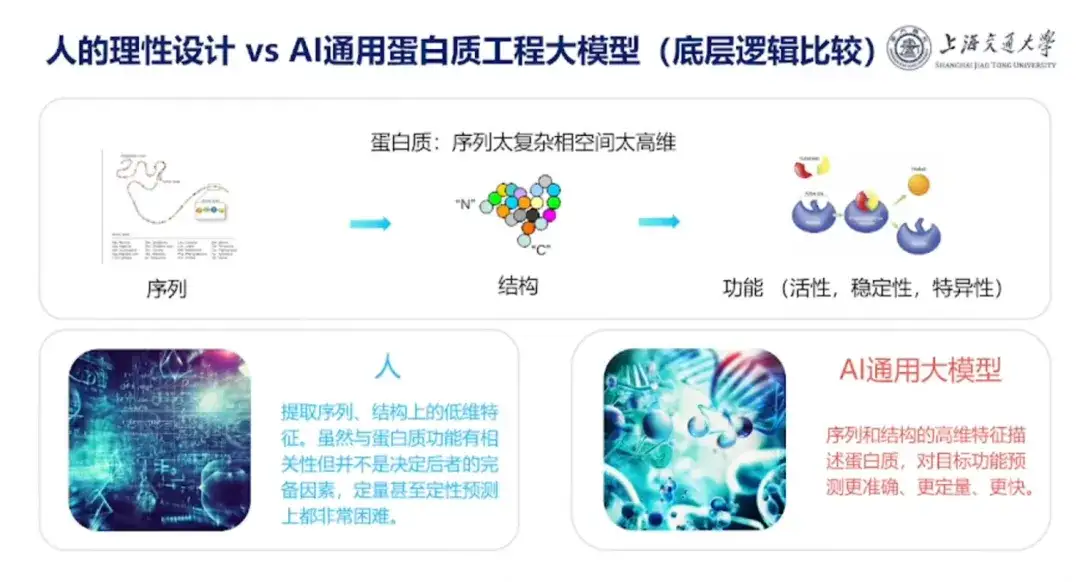
In Bezug auf den Unterschied zwischen dem Proteindesign im menschlichen Gehirn und dem Proteindesignmodell der KI wies Professor Hong Liang darauf hin, dass der Hauptunterschied darin liege, dass Menschen zwar gerne Erfahrungen zusammenfassen, menschliche Erfahrungen jedoch im Allgemeinen niedrigdimensional seien, wie etwa Proteinextraktionssequenzen und niedrigdimensionale Strukturmerkmale. Obwohl diese Eigenschaften mit der Proteinfunktion korrelieren, stellen sie keine vollständigen Faktoren für deren Bestimmung dar und sind sowohl quantitativ als auch qualitativ schwer vorherzusagen.Das KI-Proteindesignmodell kann hochdimensionale Merkmale verwenden, um die Sequenz und Struktur von Proteinen zu beschreiben und Zielfunktionen genauer, quantitativer und schneller vorherzusagen.
Fall 5: De-novo-Proteinsequenzdesign
Um dieses Problem weiter zu veranschaulichen, teilte Professor Hong Liang ein Ergebnis seiner Forschungsgruppe Cell Discovery. Er sagte, dies sei die größte Proteinsequenz, die je durch De-novo-Design gewonnen wurde, ein Gen-Editierungsenzym mit 6 Domänen und mehr als 700 Aminosäuren.
In der Natur sind nur über 600 Editierenzyme bekannt und das Forschungsteam hat auf dieser Grundlage 27 neue Sequenzen erstellt. Im Vergleich zur Natur sind die Sequenzähnlichkeiten alle geringer als 65%, wobei 49% die geringste Ähnlichkeit aufweist. Mit anderen Worten: Das Forschungsteam modifizierte mehr als 300 der über 700 Aminosäuresequenzen, von denen 23 aktiv waren, 2/3 aktiver als der Wildtyp waren und die höchste Aktivität 8,6-mal so hoch war wie die des Wildtyps.
Professor Hong Liang sagte: „Das KI-Proteindesignmodell kann die Modifikation von 300 Aminosäuresequenzen erreichen und dabei eine gute Aktivität und eine hohe Positivrate aufrechterhalten. KI ist menschlichen Experten bei dieser Art von Sequenzgenerierungsaufgaben bereits weit überlegen.“
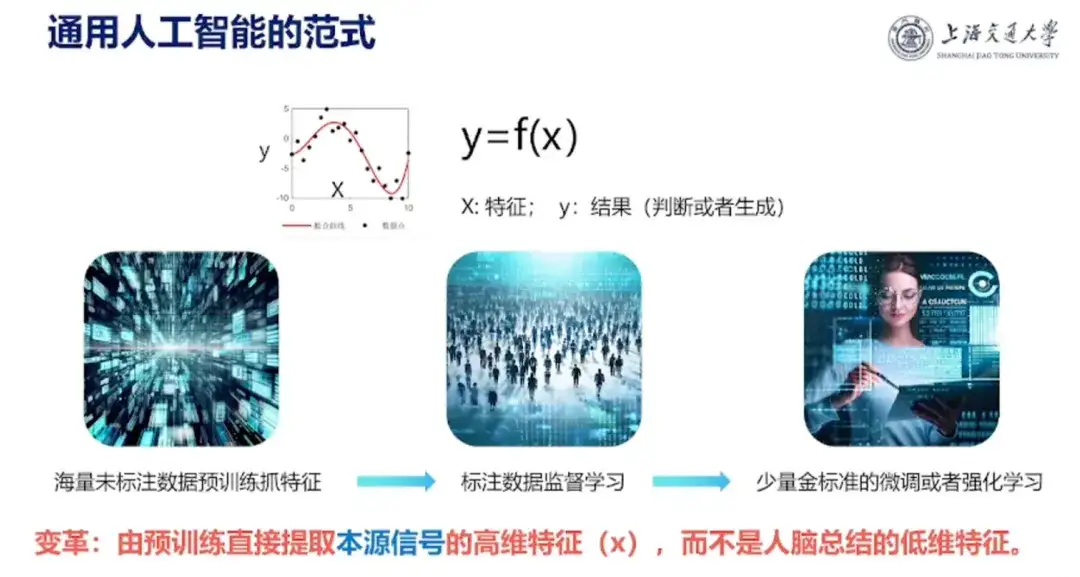
Darüber hinaus teilte Professor Hong Liang auch sein Verständnis von künstlicher Intelligenz:„Künstliche Intelligenz ist eine Abbildung von y auf x, wobei x das Eingabemerkmal und y das gewünschte Ergebnis ist, beispielsweise die Stabilität und Aktivität eines Proteins. Künstliche Intelligenz führt jetzt eine hochdimensionale Anpassung durch.“
KI-Proteindesign-Großmodell erzielt enorme Produktivitätssteigerung
Professor Hong Liang demonstrierte das vom Team erstellte KI-Proteindesignmodell und stellte vor: „Forscher geben eine Sequenz in die interne Software ein, und die Plattform wählt 30 bis 50 Sequenzen aus, die den Naturgesetzen für Experimente entsprechen. Anschließend beginnt die Lernphase mit kleinen Stichproben, in der das KI-Modell auf die von den Forschern benötigten Indikatoren abgestimmt wird. Schließlich werden die dominanten Mutanten erzeugt.“
Erwähnenswert ist, dass sich derzeit nur zwei Forscher im Team auf Proteindesign konzentrieren, einer im Bereich Biomedizin und der andere im Bereich synthetische Biologie, das Team jedoch gleichzeitig mehr als 40 Projekte durchführt.Dies bestätigt auch die Aussage von Professor Hong: „Sobald KI die Fähigkeit hat, die zugrunde liegende Technik zu durchbrechen, wird sie enorme Produktivität freisetzen.“
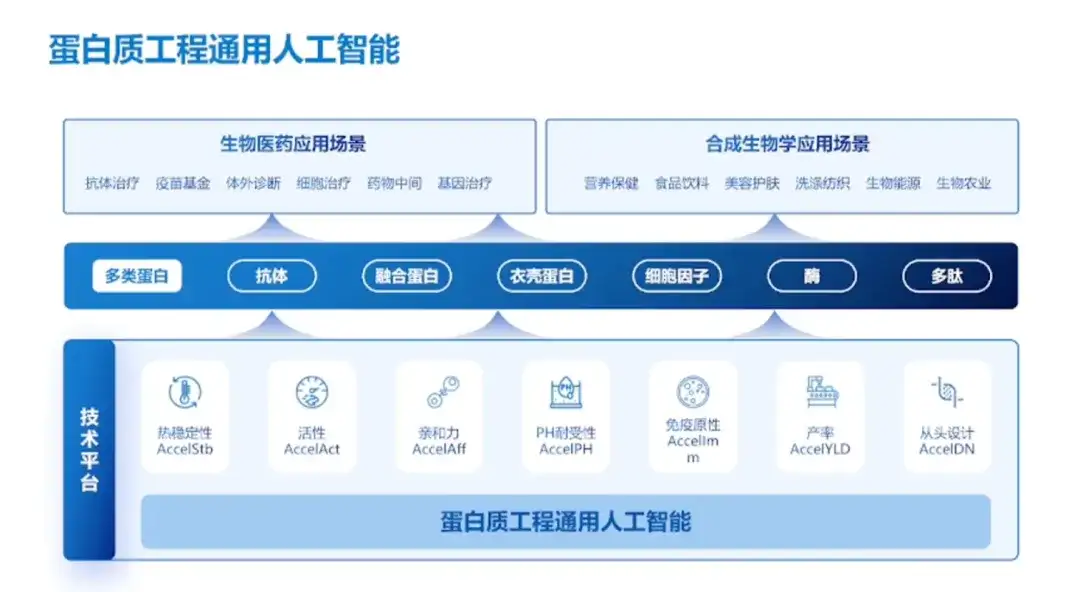
Wir arbeiten eng mit vielen Universitäten und Unternehmen zusammen und verfügen über drei wesentliche Vorteile
Darüber hinaus demonstrierte Professor Hong Liang auch die Erfolge und Kernvorteile des Teams.
Zu den Erfolgen des Teams gehört eine intensive Zusammenarbeit mit Universitäten/Forschungsinstituten wie der Tsinghua-Universität und dem Institut für Immunchemie der ShanghaiTech University sowie mit Unternehmen wie Jinsai Pharmaceuticals, Hanhai New Enzyme und Corning Jeol.Im vergangenen Jahr wurden 20 Proteine erfolgreich transformiert, mit fruchtbaren Ergebnissen.
In Bezug auf Teamvorteile sagte Professor Hong Liang:Das Team „verfügt über wesentliche Vorteile in dreierlei Hinsicht: neue Daten, unabhängige Modelle und Produkte, die als erste auf den Markt kommen.“Erstens verfügt das Team über vollständige Proteinsequenzdaten, die wesentlich umfangreicher sind als öffentliche Datensätze. Zweitens verfügt das Team über unabhängige Modelle, ein selbst erstelltes Proteinvokabular, Lernmethoden für kleine Stichproben sowie Sequenz- und Struktur-Vortrainingsmethoden, und die experimentelle Genauigkeit und Forschungsgeschwindigkeit sind weltweit führend. Und schließlich hat das Team auf globaler Ebene die Führung bei der Realisierung der praktischen Anwendung mehrerer Proteinprodukte übernommen.

KI für die Wissenschaft: In den nächsten drei Jahren werden wir den Standard-Designmodus der KI-Großmodellautomatisierung realisieren
Professor Hong Liang ist davon überzeugt, dass „künstliche Intelligenz im Allgemeinen in den nächsten drei Jahren in den Bereichen Proteindesign, Arzneimittelentwicklung, Krankheitsdiagnose, Entdeckung neuer Zielmoleküle, Design chemischer Synthesewege und Materialdesign einen deutlichen Paradigmenwechsel herbeiführen wird. Dabei wird das wissenschaftliche Entdeckungsmodell, das früher auf sporadischem Ausprobieren des menschlichen Gehirns beruhte, in ein automatisiertes Standarddesignmodell mit großem KI-Modell umgewandelt.“

Zu den spezifischen Änderungen gehören die Entwicklung von Lernmethoden mit Nullstichproben oder kleinen Stichproben sowie die Entwicklung von Technologiemodellen für das Vortraining.In Ermangelung von Daten wird zur Vorschulung mithilfe eines physischen Simulators eine große Menge gefälschter Daten mit etwas geringerer Genauigkeit generiert und anschließend mit echten und wertvollen Daten feinabgestimmt, um das bestärkende Lernen abzuschließen. Professor Hong betonte: „Gefälschte Daten sind Daten, die nicht aus der realen Welt stammen, aber ein gewisses Maß an Zuverlässigkeit aufweisen. Sie können durch KI generiert oder durch physikalische Computersimulation zur Datenverbesserung gewonnen werden. Schließlich sind reale Nassversuchsdaten am wertvollsten und werden für die endgültige Feinabstimmung des Modells verwendet.“
Am Ende dieser Austauschsitzung fasste Professor Hong Liang noch einmal den Vergleich zwischen KI-Studenten der Geisteswissenschaften und KI-Studenten der Naturwissenschaften zusammen. Er glaubt, dass KI-Studenten der Geisteswissenschaften sind im Wesentlichen persönliche Assistenten für das menschliche Leben und die Arbeit, wie Kimi und ChatGPT, können Menschen dabei helfen, sich wiederholende kreative oder weniger wissenschaftliche Arbeiten zu reduzieren. Seine Merkmale sind große Datenmengen, geringe Genauigkeitsanforderungen, die Fähigkeit, mit großem Aufwand Wunder zu vollbringen, eine starke domänenübergreifende Generalisierungsfähigkeit und die Möglichkeit, damit große domänenübergreifende allgemeine Modelle zu erstellen. Allerdings sollte es großen Unternehmen vorbehalten sein und ist nicht für Universitäten und Forschungsinstitute geeignet.
Und Studierende der KI-Wissenschaft müssen ein wissenschaftliches oder technisches Problem lösen.Indem sie die F&E-Köpfe von Wissenschaftlern aus Unternehmen und wissenschaftlichen Instituten ersetzen, äußerst kreative Dinge tun, die Kosten erheblich senken und die Effizienz steigern und sogar Produkte entwickeln, die mit der bisherigen wissenschaftlichen Erfahrung nicht möglich gewesen wären, können Teams aus Universitäten und Forschungsinstituten ihre einzigartigen beruflichen Barrieren kombinieren, um KI-Lösungen in verwandten Bereichen zu erforschen.

Über Professor Hong Liang
Professor Hong Liang absolvierte sein Grundstudium im Fachbereich Physik an der University of Science and Technology of China und sein Aufbaustudium an der Chinese University of Hong Kong, wo er sich in seiner Forschung auf die Synthese/Charakterisierung von Nanomaterialien konzentrierte. Er promovierte an der University of Akron in den USA, wo seine Forschungsschwerpunkte die physikochemischen Eigenschaften, die Dynamik und die Phasenübergänge von Polymeren/Proteinen waren.

Im Jahr 2010Professor Hong Liang kam als Postdoktorand zum Oak Ridge National Laboratory in den Vereinigten Staaten und konzentrierte sich auf die Struktur, Dynamik und Funktion von Proteinen im Bereich der Computerbiologie. Im Jahr 2015Professor Hong Liang kam als unabhängiger PI zur Shanghai Jiao Tong University, um molekularbiophysikalische Forschung zu betreiben. Im Jahr 2020Professor Hong Liang kombiniert KI, Computertechnik und Nassexperimente, um Proteindesignforschung zu betreiben. Sein Übergang von der Physik zur Chemie, von der Chemie zur Biologie und schließlich von Nassexperimenten zur Informatik und künstlichen Intelligenz ist ein typischer interdisziplinärer Forschungshintergrund.
Nach drei Jahren entwickelte das Team von Professor Hong Liang unabhängig die AI-Protein-General-Artificial-Intelligence-Pro-Serie „von der Sequenz zur Funktion“.: Vom Vortraining großer Modelle über die Erkundung der zugrunde liegenden Vokabellisten bis hin zu überwachten Lernmethoden haben wir eine Datenbank mit Bezeichnungen für physikalische und chemische Proteineigenschaften erstellt. Auf dieser Grundlage haben wir eine Methode zur Feinabstimmung kleiner Stichproben entwickelt und schließlich eine künstliche Intelligenzlösung für das funktionale Design von Proteinsequenzen bereitgestellt.
Weitere Ergebnisse finden Sie auf der Homepage der Forschungsgruppe:
https://ins.sjtu.edu.cn/people/lhong/papers.html
Bisher hat das von Professor Hong Liang geleitete Forschungsteam einen umfassenden und intensiven Austausch und eine enge Zusammenarbeit mit akademischen und industriellen Partnern gepflegt.Es umfasst viele Bereiche wie Biomedizin, In-vitro-Diagnostik, pharmazeutische Zwischenprodukte, Ernährung und Gesundheitspflege, Lebensmittel und Getränke, Schönheits- und Hautpflege, Waschen und Textilien, Bioenergie, Biolandwirtschaft und Umwelttechnik.In einer Zeit, in der wissenschaftliche Forschungsergebnisse in rasantem Tempo, wenn nicht gar in rasender Geschwindigkeit, produziert werden, halten sie noch immer an ihrer ursprünglichen Absicht fest, „praktische Forschung zu betreiben“, praktizieren, was sie predigen, bleiben auf dem Boden der Tatsachen und bringen ein wissenschaftliches Forschungsergebnis nach dem anderen aus dem Labor in die Produktion.
Weitere Informationen zu Professor Hong Liang finden Sie unter:
https://ins.sjtu.edu.cn/people/








