Command Palette
Search for a command to run...
WildSpeech-Bench Benchmark-Datensatz Zur Sprachverständnisgenerierung
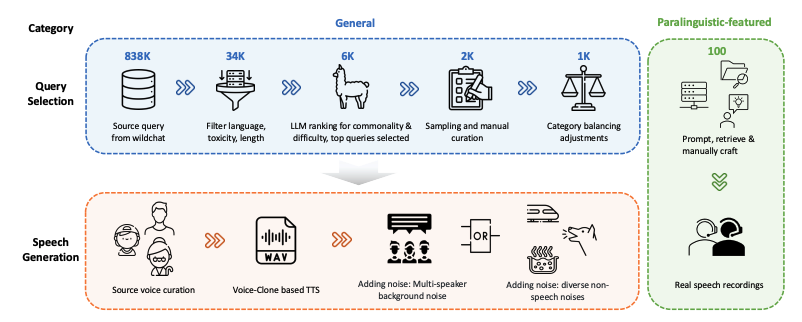
WildSpeech-Bench ist der erste Benchmark zur Bewertung der Speech-to-Speech-Fähigkeiten von SpeechLLM und wurde 2025 von Tencent veröffentlicht. Die Ergebnisse des zugehörigen Papiers lauten:WildSpeech-Bench: Benchmarking von End-to-End-SpeechLLMs in der Praxis“, dessen Ziel es ist, die Fähigkeit des Modells zu messen, in realen Szenarien der Sprachinteraktion vollständige Spracheingaben und Sprachausgaben (Speech-to-Speech, S2S) zu verstehen und zu generieren. Der Datensatz enthält 1.100 Anfragen in fünf Hauptkategorien: Informationsanfragen, Lösungsanfragen, Meinungsaustausch, Texterstellung und paralinguistische Ausdrücke. Jede Kategorie entspricht einer gemeinsamen Nutzerabsicht. 1.000 dieser Anfragen stammen aus allgemeinen Szenarien der Sprachinteraktion (einschließlich Informationsanfragen, Lösungsanfragen, Meinungsaustausch und Texterstellung), während weitere 100 durch paralinguistische Merkmale wie Pausen, Intonation, Stottern und nahezu phonetische Worterkennung gekennzeichnet sind. Jede Anfrage wird von diversen Sprachausgabebeispielen begleitet, die ein breites Spektrum an Sprecherattributen (Geschlecht, Alter, Stimmvarianten), akustischen Bedingungen und Geräuschumgebungen abdecken, um die Vielfalt und die Herausforderungen der natürlichen Sprachinteraktion realistischer zu simulieren.
Zitat
@misc{zhang2025wildspeechbenchbenchmarkingendtoendspeechllms, title={WildSpeech-Bench: Benchmarking End-to-End SpeechLLMs in the Wild}, Autor={Linhao Zhang und Jian Zhang und Bokai Lei und Chuhan Wu und Aiwei Liu und Wei Jia und Xiao Zhou}, Jahr={2025}, eprint={2506.21875}, archivePrefix={arXiv}, primaryClass={cs.CL}, }
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.