Command Palette
Search for a command to run...
WideSearch-Benchmark-Datensatz Zur Informationserfassung
Datum
Organisation
Paper-URL
Lizenz
Other
*Dieser Datensatz unterstützt die Online-Nutzung.Klicken Sie hier, um zu springen.
WideSearch ist der erste Benchmark-Datensatz zur Agentenbewertung, der für die „breite Informationssuche“ entwickelt wurde und 2025 vom Seed-Team von ByteDance veröffentlicht wurde. Die zugehörigen Ergebnisse des Papiers lauten:WideSearch:Benchmarking Agentic Broad Info-Seeking“, dessen Ziel es ist, die Zuverlässigkeit und Integrität großer Sprachmodelle bei der groß angelegten Faktensammlung, Synthese und überprüfbaren strukturierten Ausgabe systematisch zu bewerten und zu fördern. Der Benchmark besteht aus 200 hochwertigen Fragen (100 englische und 100 chinesische Fragen), die vom Forschungsteam sorgfältig ausgewählt und manuell aus echten Benutzeranfragen bereinigt wurden. Diese Fragen stammen aus mehr als 15 verschiedenen Bereichen.
Datenfelder:
- instance_id: eindeutige ID der Aufgabe (entsprechend dem Namen der Gold-CSV-Datei).
- Abfrage: Eine Anweisung in natürlicher Sprache, die normalerweise die erforderlichen Spaltennamen und Anforderungen für die Markdown-Tabellenausgabe angibt.
- Auswertung: ein serialisiertes (String-)Objekt, das für die automatische Auswertung verwendet wird und Folgendes enthält:
- unique_columns: Primärschlüsselspalten (für die Zeilenausrichtung);
- erforderlich: Spaltenname, der angezeigt werden muss;
- eval_pipeline: Auswertungskonfiguration auf Spaltenebene (z. B. Vorverarbeitung, Metrik, Kriterium).
- Sprache: Aufgabensprache, der Wert kann en oder zh sein.
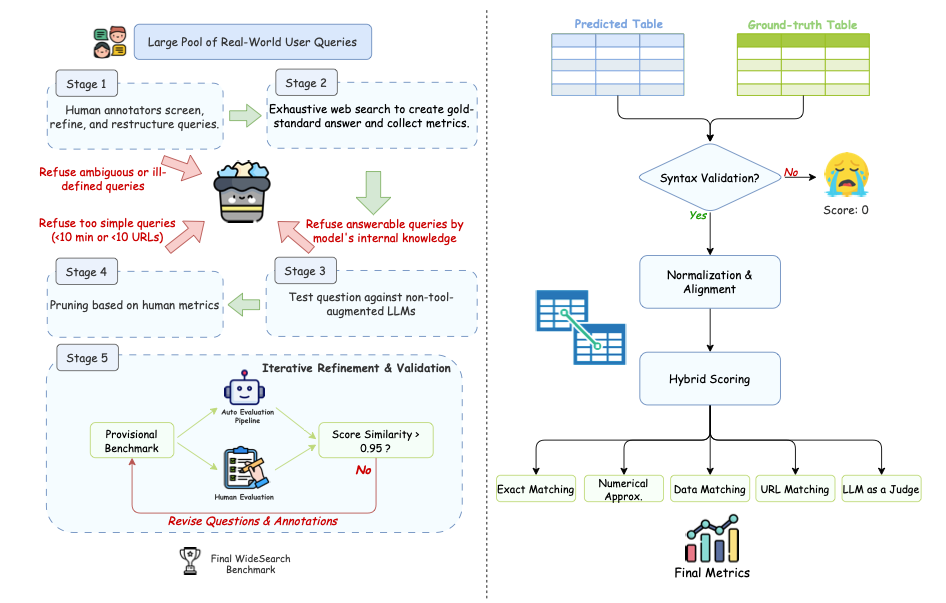
Flussdiagramm zur Datenkonstruktion und automatischen Auswertung
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.