HyperAI
Command Palette
Search for a command to run...
KV-Edit 背景一致性图像编辑
一、教程简介

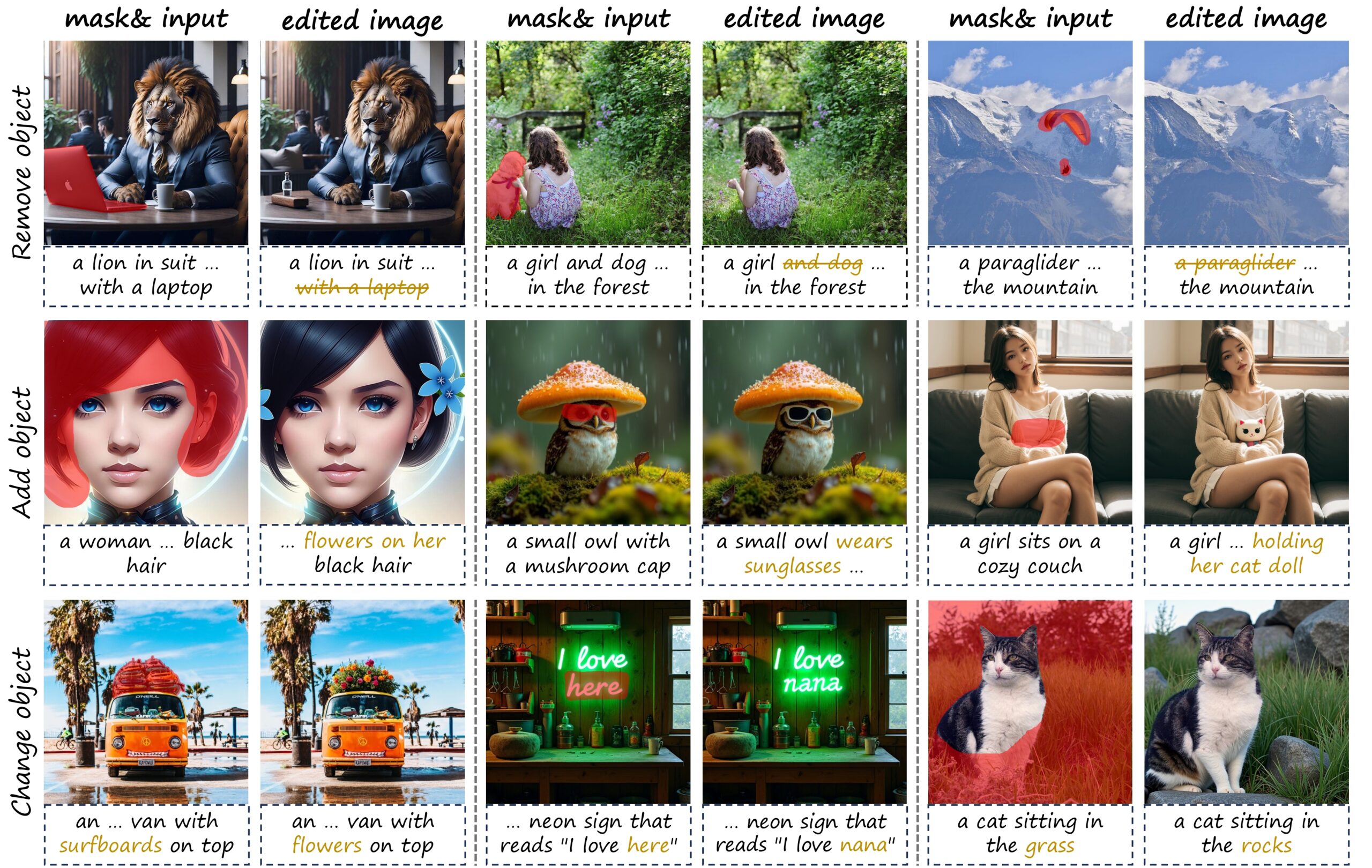
KV-Edit 项目由清华大学人工智能学院于 2025 年 2 月 25 日推出,该模型是一种无训练图像编辑方法,能够严格保持原始图像和编辑图像之间的背景一致性,并在各种编辑任务上取得了令人印象深刻的性能,包括物体添加、移除和替换。 KV-Edit 的核心在于利用 KV 缓存来存储背景标记的键值对。在图像反转过程中,这些键值对被保存,而在去噪阶段,它们与前景内容结合,生成与背景无缝集成的新内容。这种方法避免了复杂机制或昂贵的训练需求,同时确保了背景的一致性和图像的整体质量。相关论文成果为 KV-Edit: Training-Free Image Editing for Precise Background Preservation 。
本教程采用资源为单卡 A6000 。
👉 该项目提供了两种型号的模型:
- black-forest-labs/FLUX.1-dev:FLUX.1 [dev] 是一个具有 120 亿参数的校正流变换器,能够根据文本描述生成图像。
- black-forest-labs/FLUX.1-schnell:FLUX.1 [schnell] 是一个具有 120 亿参数的校正流变换器,能够根据文本描述生成图像。
项目示例
二、运行步骤
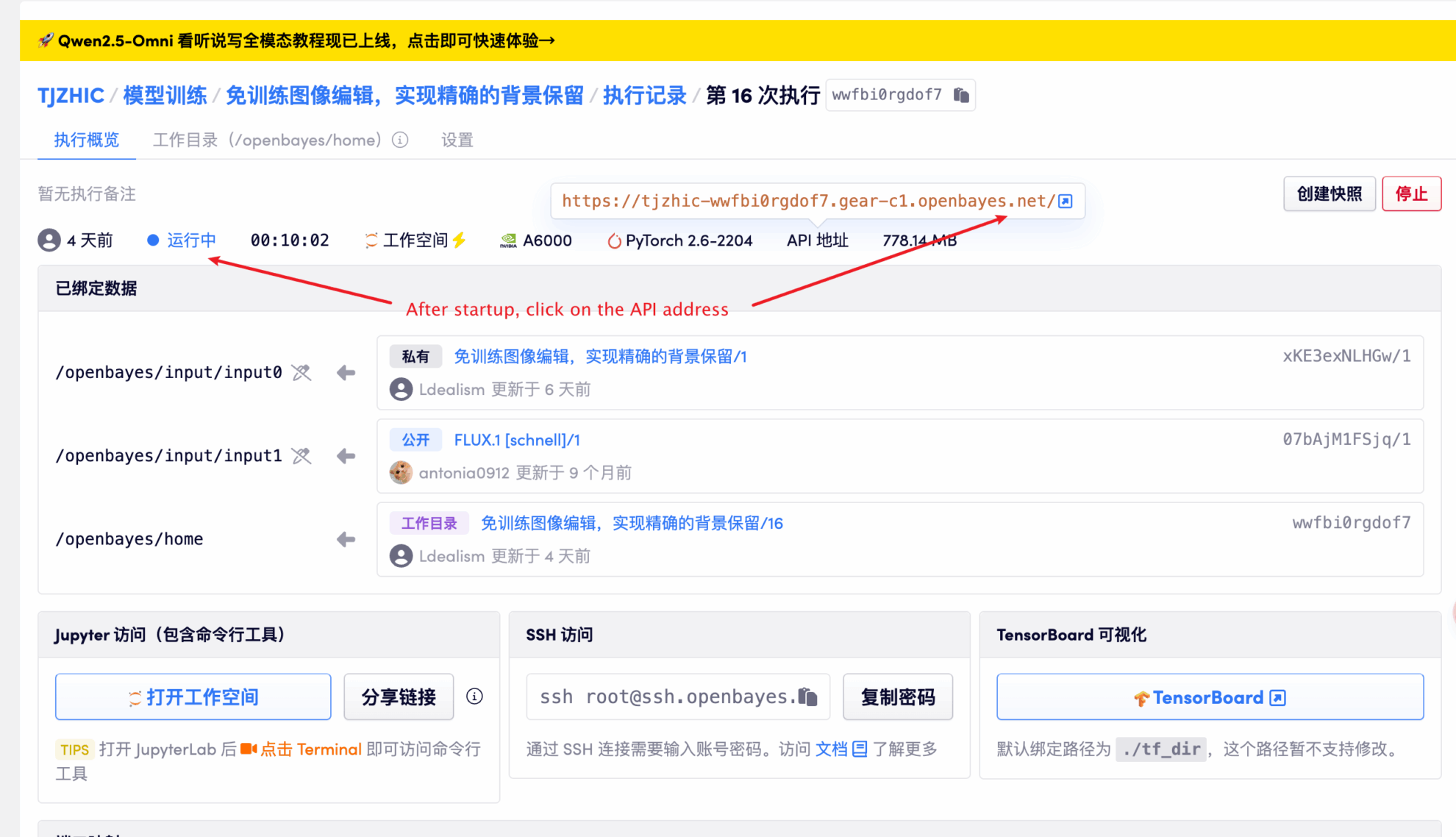
1. 启动容器后点击 API 地址即可进入 Web 界面
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。
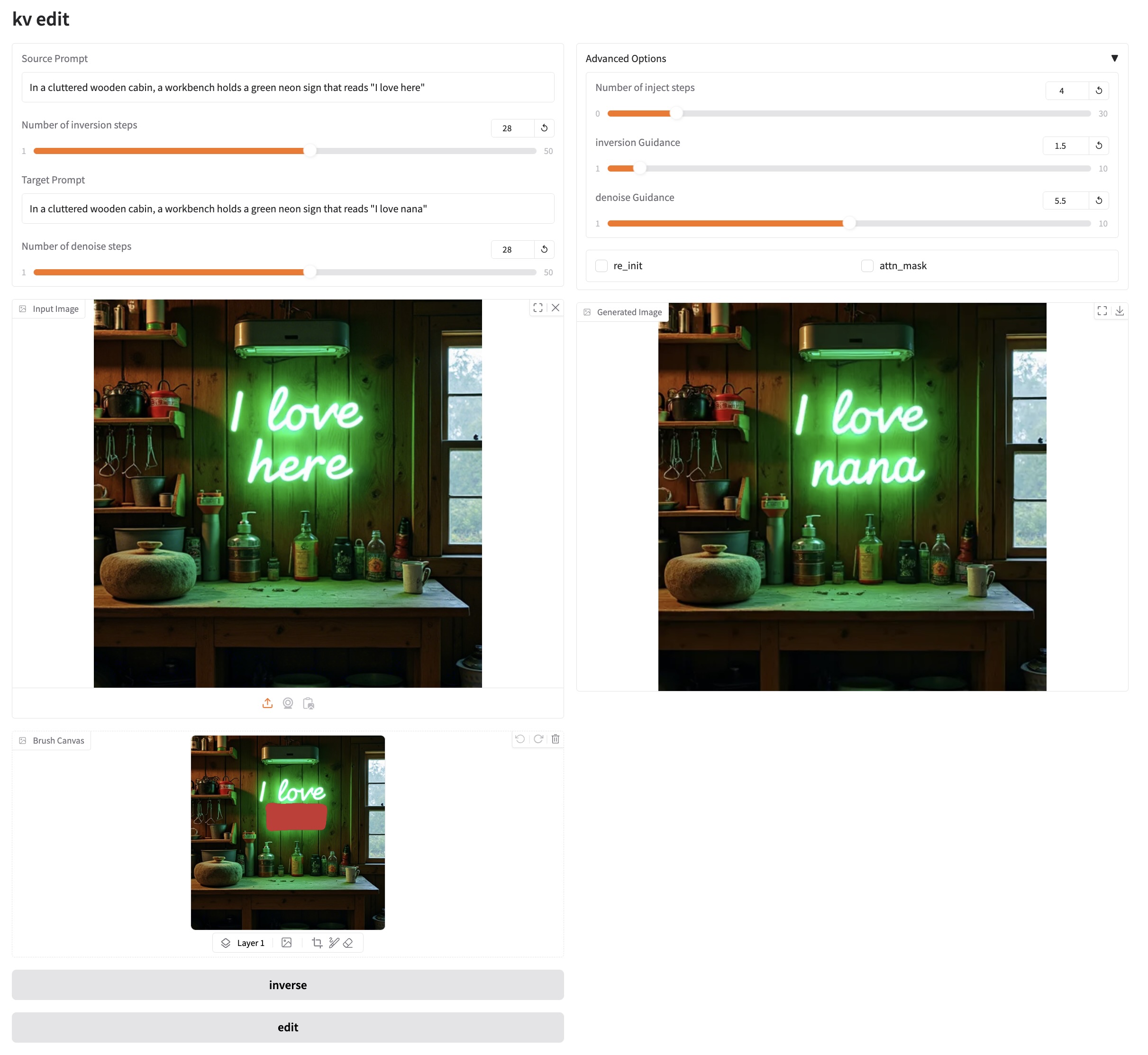
2. 进入网页后,即可与模型展开对话
步骤说明:
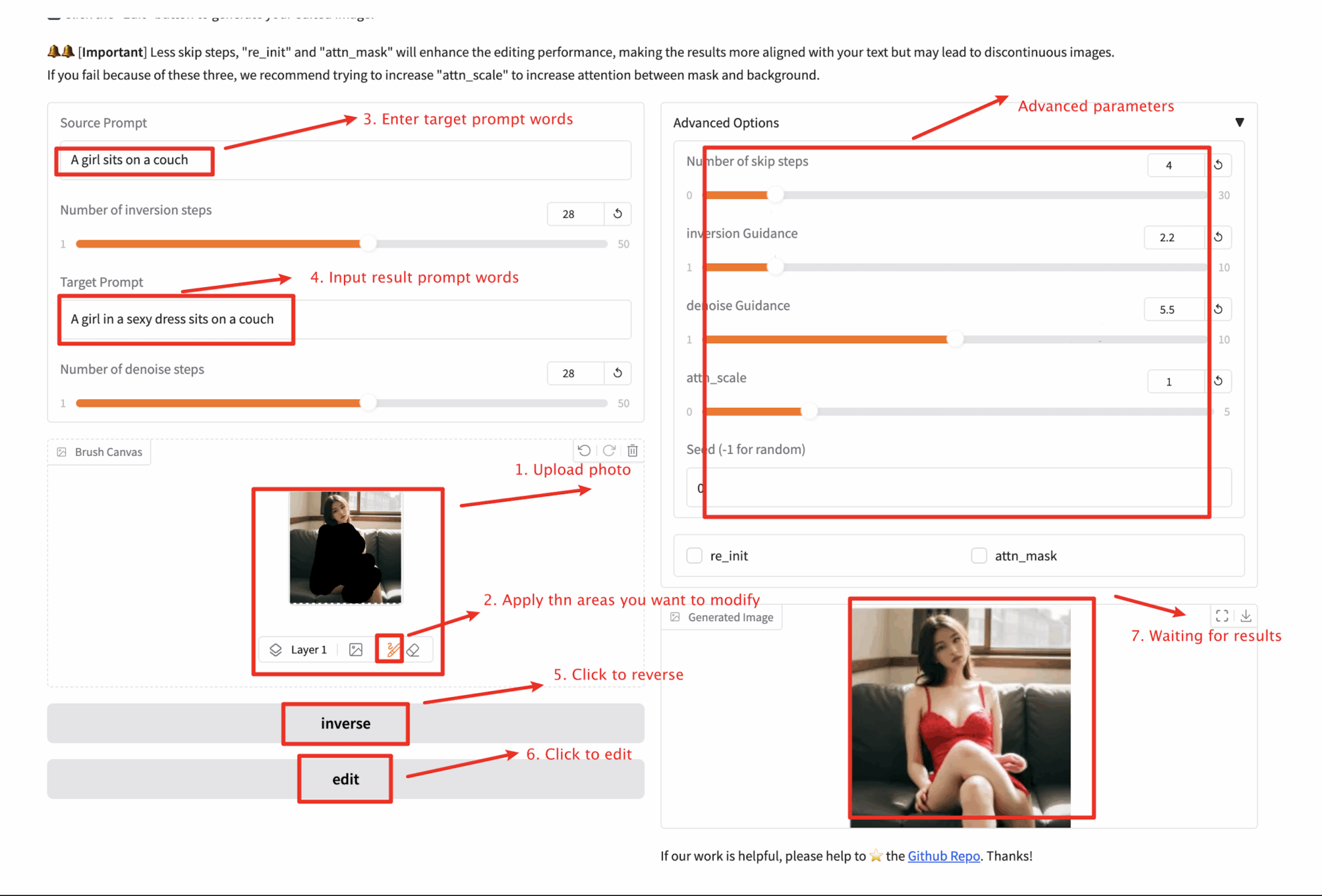
1️⃣ 上传您需要编辑的图片。
2️⃣ 填写您的源提示词,然后点击「inverse」按钮以执行图像反转。
3️⃣ 使用画笔工具绘制您的遮罩区域。
4️⃣ 填写您的目标提示词,然后调整超参数。
5️⃣ 点击「Edit」按钮生成您的编辑后的图片。
❗️重要的使用技巧:
- 图片不能超过 100 KB 。
- 在使用基于反转的版本时,您只需对每张图片进行一次反转,然后可以重复步骤 3-5 进行多次编辑尝试!
- re_init 表示使用带有噪声的图像混合而不是反转的结果来生成新内容。
- 当勾选 attn_mask 选项时,在进行反转之前需要输入掩码。
- 当掩码较大,且使用较少的跳过步骤或 re_init 时,掩码区域的内容可能与背景不连续,您可以尝试增加 attn_scale 。
- inverse 为反转,edit 为编辑去除背景。
- Number of skip steps 控制跳过步骤数。
- inversion Guidance 倒置指导参数。
- denoise Guidance 降噪指导参数。
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
感谢 Github 用户 zhangjunchang 对本教程的部署,本项目引用信息如下:
@article{zhu2025kv,
title={KV-Edit: Training-Free Image Editing for Precise Background Preservation},
author={Zhu, Tianrui and Zhang, Shiyi and Shao, Jiawei and Tang, Yansong},
journal={arXiv preprint arXiv:2502.17363},
year={2025}
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。