HyperAI
Command Palette
Search for a command to run...
Ovis-Image:高质量图像生成模型
一、教程简介

Ovis-Image 是一个高质量图像生成模型(Text-to-Image, T2I)系统,由 AIDC-AI 团队于 2025 年 11 月发布的 Ovis-Image-7B 高保真文本到图像生成模型构建。该系统采用多尺度 Transformer 编码器与自回归生成架构,在高分辨率图像生成、细节表现及多风格适配能力上表现卓越。通过优化的噪声采样和 classifier-free guidance 技术,Ovis-Image 能够在 1024×1024 分辨率下生成自然、连贯、细节丰富的图像,支持写实、赛博朋克、动漫、科幻等多种风格。相关论文成果为 Ovis-Image 7B: Text-to-Image Generation with Multi-Scale Transformer 。
核心特性:
- 高分辨率原生生成:支持最高 1024×1024 分辨率原生生成,无需额外超分模型即可获得细节清晰的结果
- 多尺度语义建模:基于多尺度 Transformer 编码结构,同时兼顾整体构图与局部纹理细节
- 高质量细节还原:在人物、材质、光影、环境复杂度等方面具备稳定表现
- 多风格泛化能力强:原生支持写实、赛博朋克、动漫、科幻、插画等多种主流风格
- 可控生成能力强:通过 Guidance Scale 、采样步数、分辨率与随机种子实现精细可控生成
- 推理精度与效率兼顾:支持 BF16 低显存推理,同时可使用 FP32 Decode 提升最终图像精度
本教程使用 Gradio 部署 Ovis-Image 7B 核心模型,算力资源采用「RTX_5090」,可实现 1024×1024 高分辨率文本生成,无显存/内存瓶颈。
二、效果展示

Ovis-Image 7B 在核心任务上表现优异:
- 复杂场景生成:从详细文本 prompt 生成自然且逻辑合理的图像
- 多风格支持:可生成写实、赛博朋克、动漫、科幻等多种视觉风格
- 高分辨率细节:纹理、阴影、光照表现丰富
- 可控性:通过步数、 guidance scale 、分辨率调节生成效果
三、运行步骤
1. 启动容器
启动容器后点击 API 地址即可进入 Web 界面
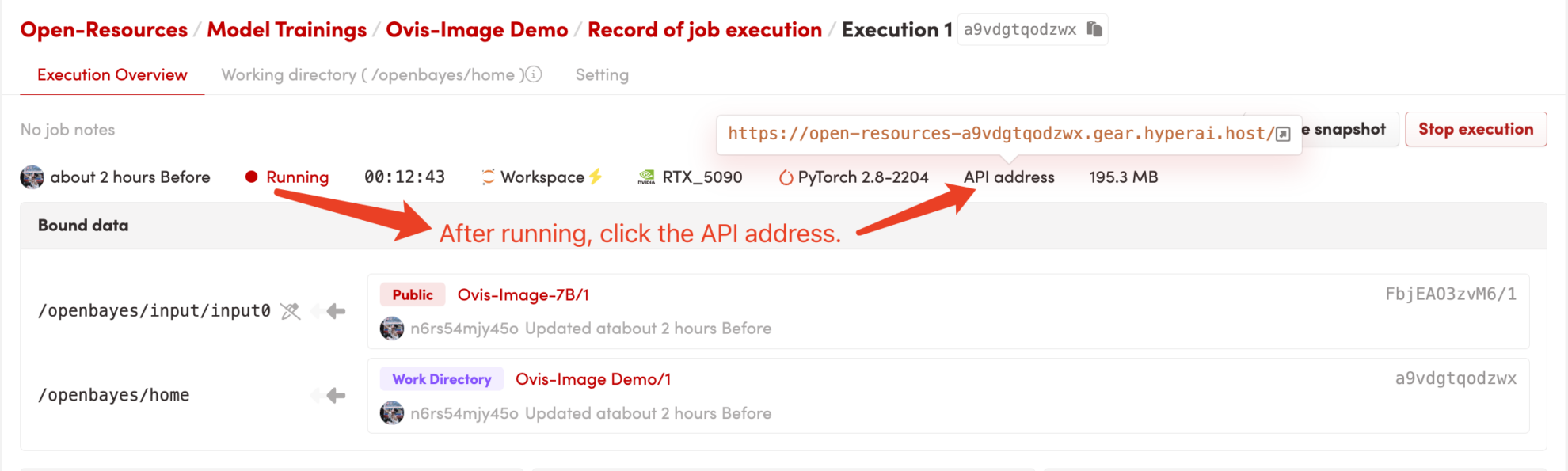
2. 开始使用
若显示「Bad Gateway」,表示模型正在初始化,由于模型较大,请等待 2-3 分钟后刷新页面。
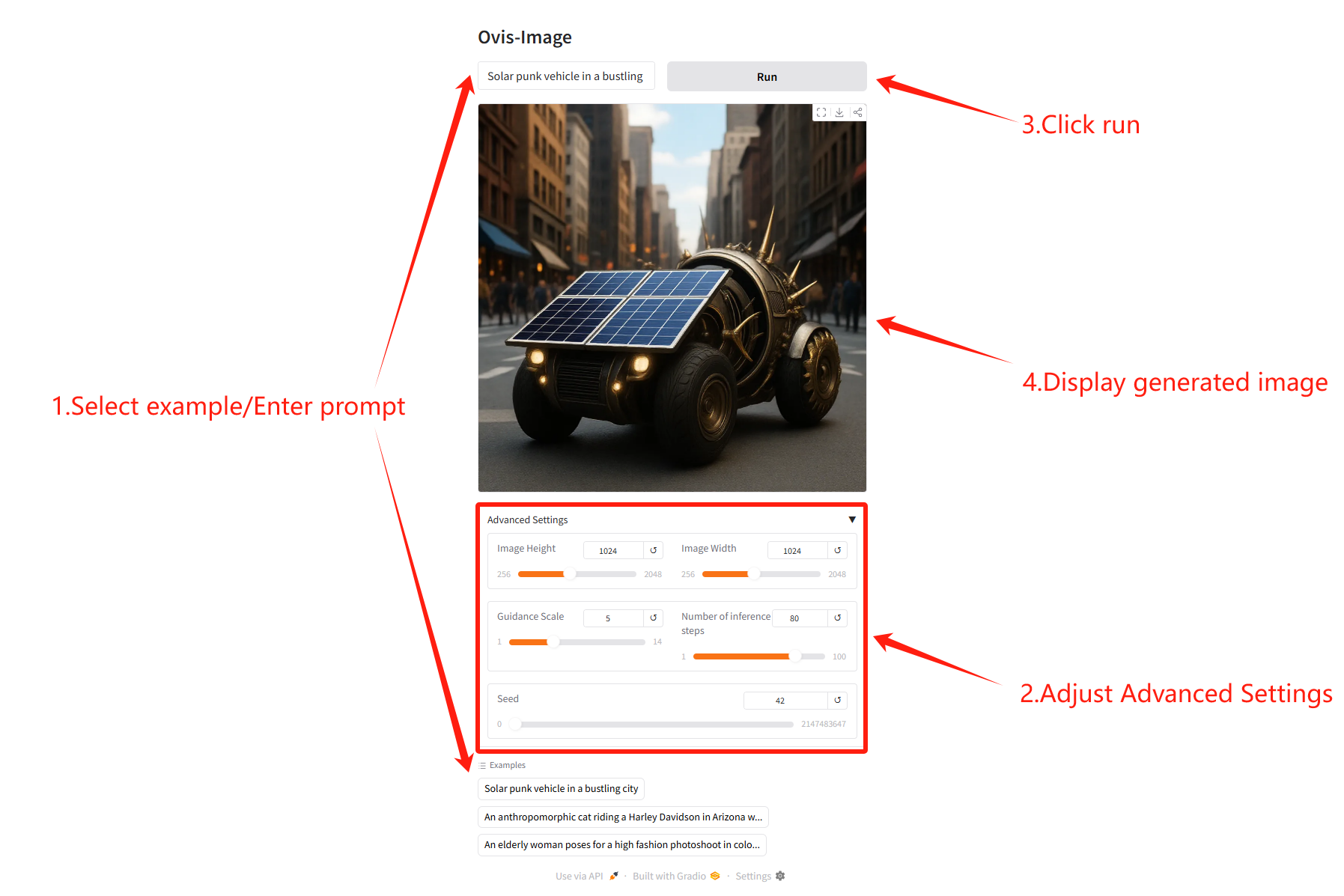
参数说明
- Image Height / Width:生成图像的高度与宽度,步长为 32
- Number of inference steps:生成步数,步数越多图像细节越丰富
- Guidance Scale:文本引导强度,数值越大图像越贴近 prompt
- Seed:随机种子,可保证生成可复现
引用信息
本项目引用信息如下:
@article{ovisimage7b,
title={Ovis-Image 7B: Text-to-Image Generation with Multi-Scale Transformer},
author={AIDC-AI Team},
journal={arXiv preprint arXiv:2511.22982},
year={2025}
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。