Command Palette
Search for a command to run...
F5-E2 TTS 只需 3 秒克隆任何音色
一、教程简介

该教程包含了两个模型的 Demo 使用,分别为 F5-TTS 和 E2 TTS 。
F5-TTS 是由上海交通大学、剑桥大学和吉利汽车研究院(宁波)有限公司于 2024 年共同开源的一款高性能文本到语音 (TTS) 系统,它基于流匹配的非自回归生成方法,结合了扩散变换器 (DiT) 技术。相关论文成果为 F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching 。这一系统能够在没有额外监督的情况下,通过零样本学习快速生成自然、流畅且忠实于原文的语音。 F5-TTS 支持多语言合成,包括中文和英文,且能在长文本上进行有效的语音合成。此外,F5-TTS 还具备情感控制功能,能根据文本内容调整合成语音的情感表现,并支持速度控制,允许用户根据需要调整语音的播放速度。系统在 10 万小时的大规模数据集上进行训练,展现出了卓越的性能和泛化能力。 F5-TTS 的主要功能包括零样本声音克隆、速度控制、情感表现控制、长文本合成以及多语言支持。它的技术原理涉及到流匹配、扩散变换器 (DiT) 、 ConvNeXt V2 文本表示改进、 Sway Sampling 策略以及端到端的系统设计。 F5-TTS 的应用场景广泛,包括有声读物、语音助手、语言学习、新闻播报、游戏配音等,为各种商业和非商业用途提供强大的语音合成能力。
E2 TTS,全称为「Embarrassingly Easy Text-to-Speech」,是一种先进的文本转语音 (TTS) 系统,它通过简化的流程实现了人类水平的自然度和说话人相似性。 E2 TTS 的核心在于它完全非自回归的特性,这意味着它可以一次性生成整个语音序列,而不需要逐步生成,从而显著提高了生成速度并保持了高质量的语音输出。相关论文成果为 E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS,已被 SLT 2024 接受。 在 E2 TTS 框架中,文本输入被转换为带有填充标记的字符序列。然后根据音频填充任务训练基于流匹配的梅尔频谱图生成器。与许多以前的工作不同,它不需要额外的组件(例如持续时间模型、字素到音素)或复杂的技术(例如单调对齐搜索)。尽管 E2 TTS 很简单,但它实现了最先进的零样本 TTS 功能,可与包括 Voicebox 和 NaturalSpeech 3 在内的以前的作品相媲美或超越。 E2 TTS 的简单性还允许输入表示的灵活性。
该教程支持如下模型和功能: 2 个模型检查点: F5-TTS E2 TTS 3 个功能:单人语音生成(Batched TTS): 根据上传的音频进行文本生成。 双人语音生成(Podcast Generation):根据双人音频模拟双人对话。多种语音类型生成(Multiple Speech-Type Generation):可根据同一讲话人不同情绪下的音频,生成不同情绪的音频。
本教程采用资源为单卡 RTX 5090 。
二、项目示例
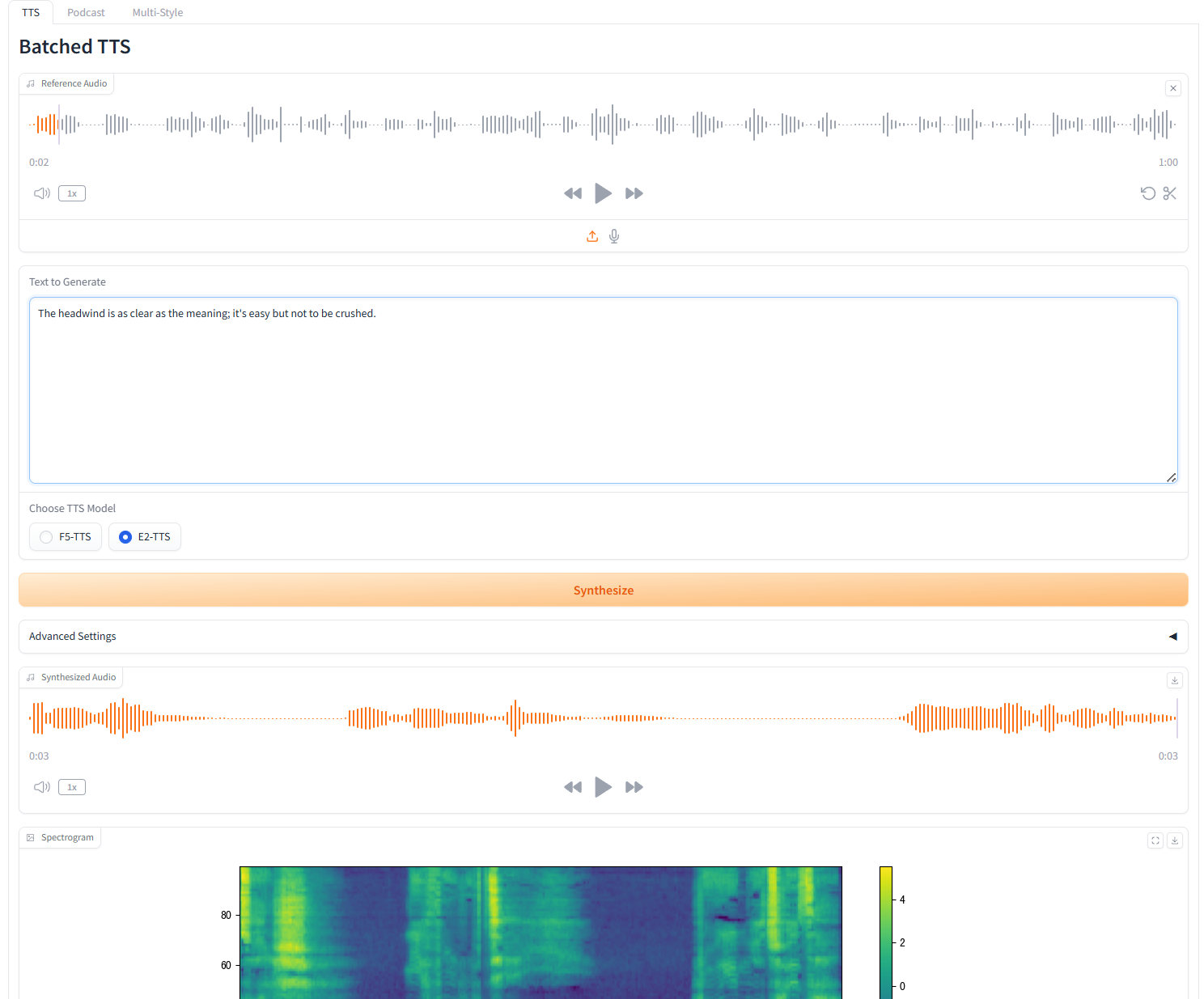
1. 单人语音生成(Batched TTS)
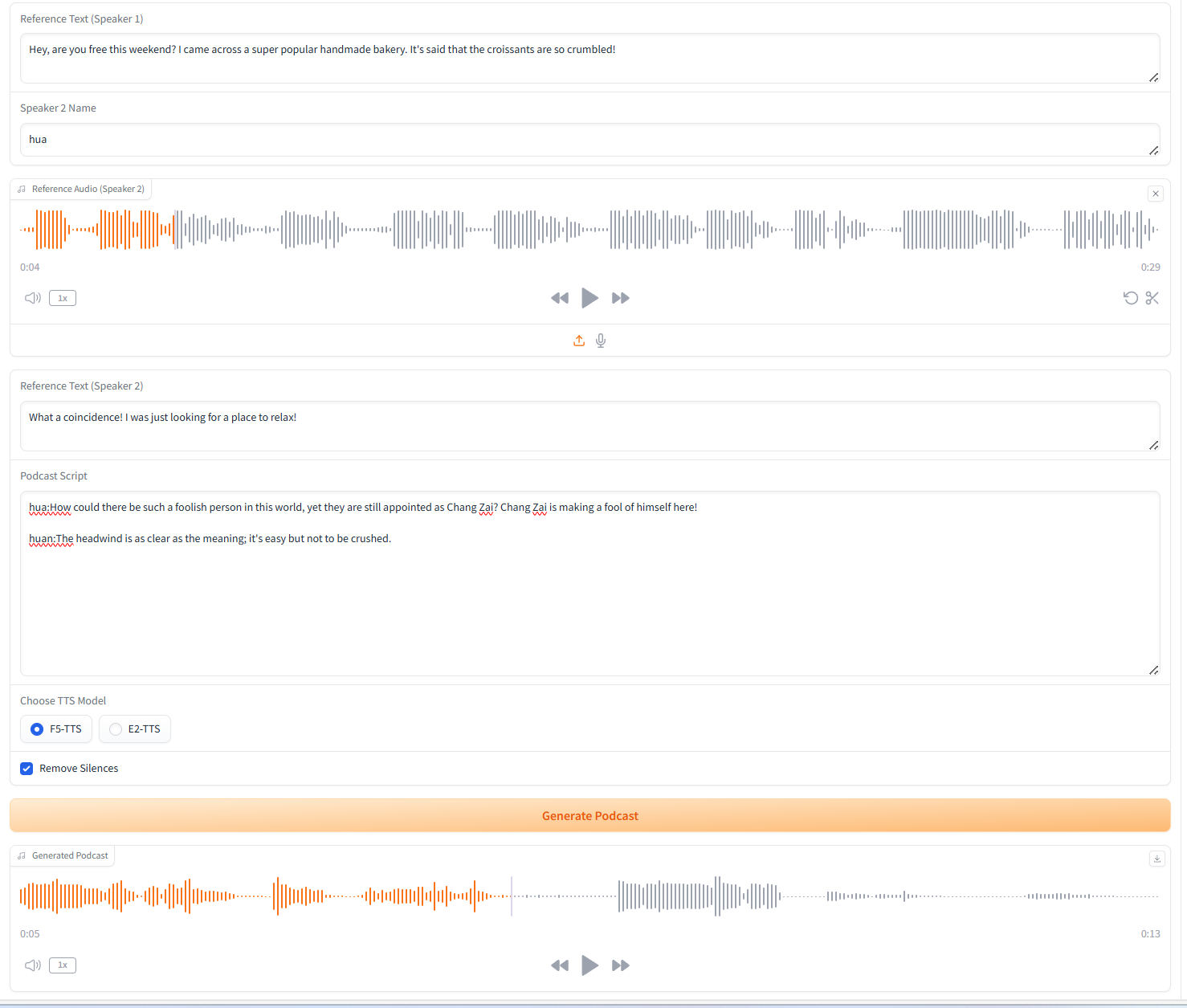
2. 多人语音生成(Podcast Generation)
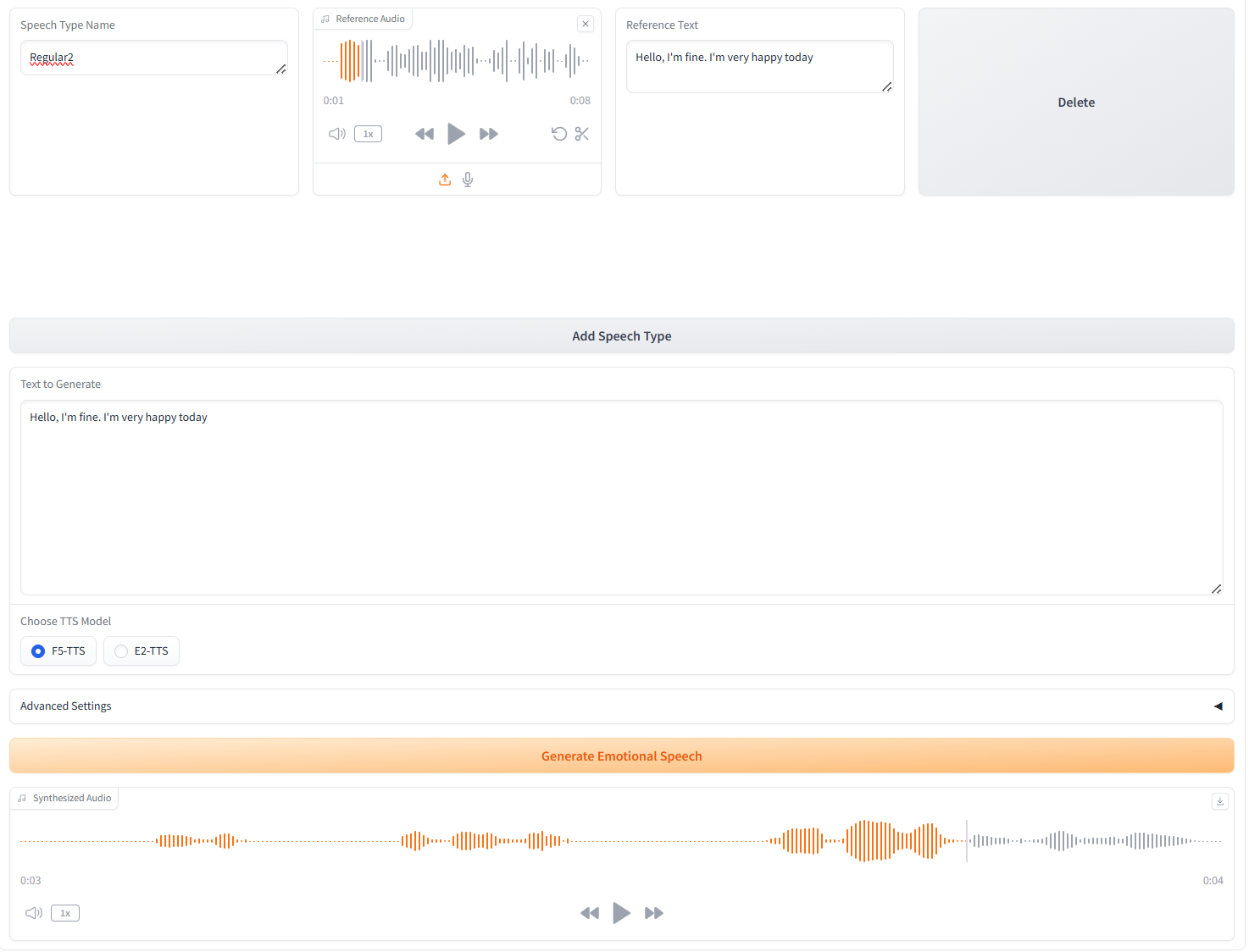
3. 多种语音类型生成(Multiple Speech-Type Generation)
三、运行步骤
1. 启动容器后点击 API 地址即可进入 Web 界面
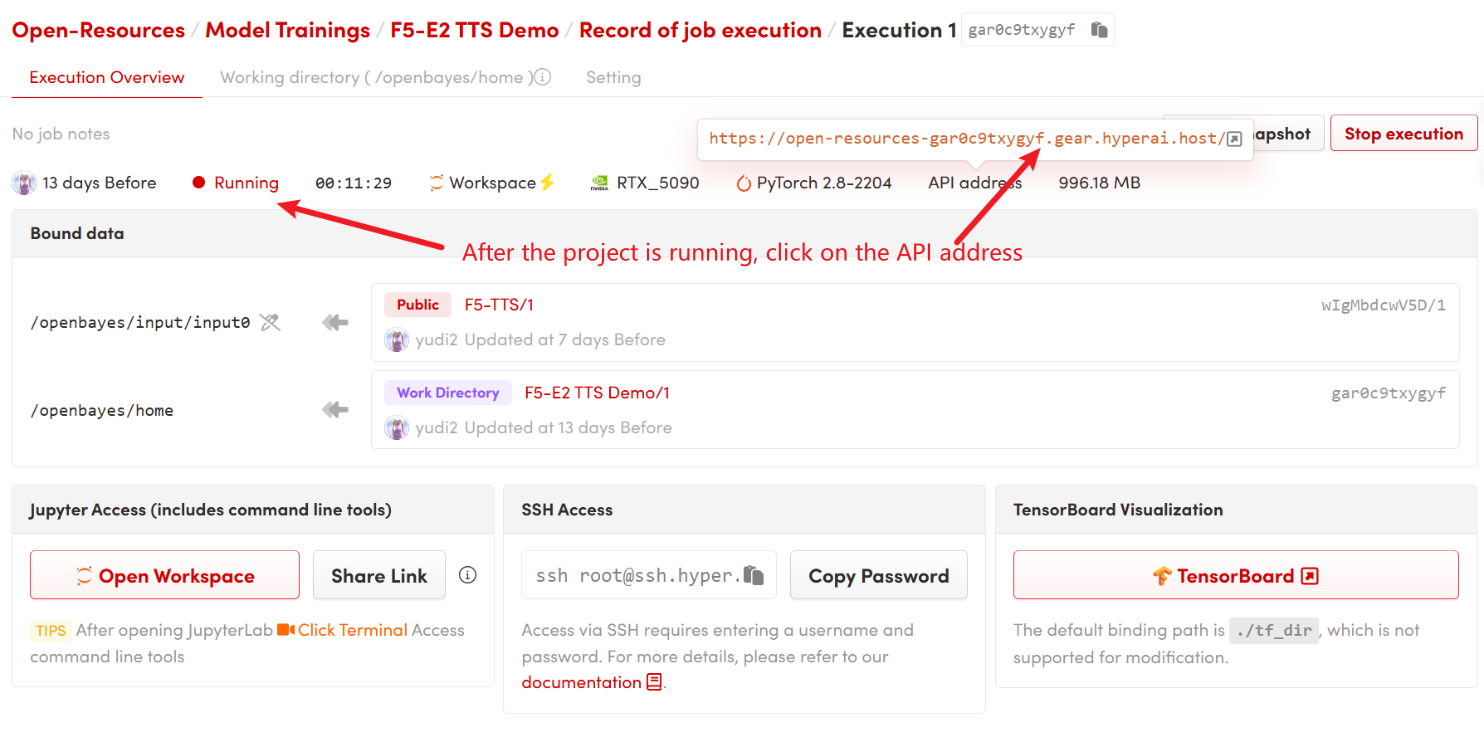
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 9 分钟后刷新页面。
使用 Safari 浏览器时,音频可能无法直接播放,需要下载后进行播放。
1. 单人语音生成(Batched TTS)
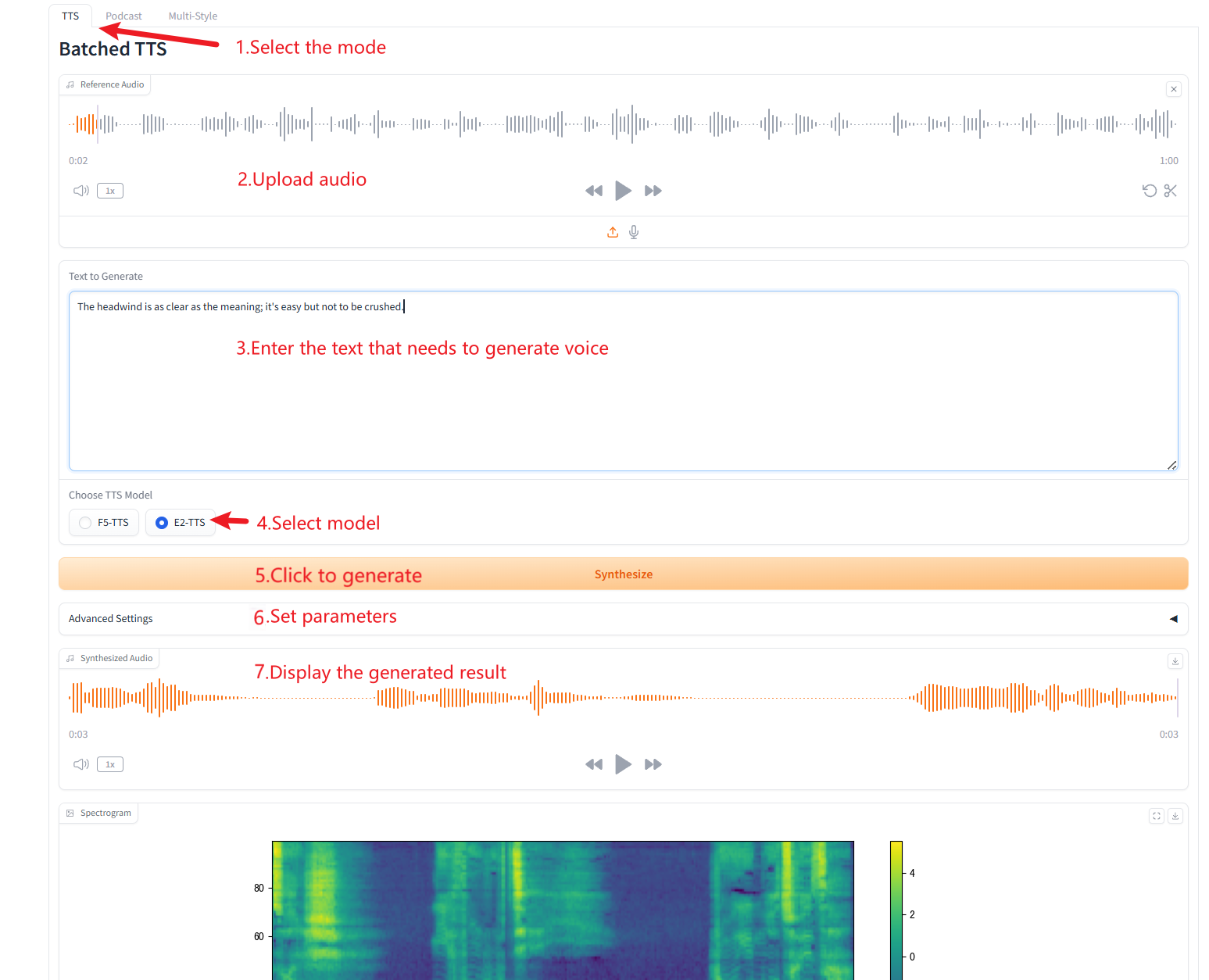
参数说明
- 参考文本(Reference Text):留空以自动转录参考音频。如果您输入文本,它将覆盖自动转录。
- 移除静音(Remove Silences):该模型往往会产生静音,尤其是在较长的音频上。如果需要,我们可以手动删除静音。请注意,这是一个实验性功能,可能会产生奇怪的结果。这也会增加生成时间。
- 断句符号(Custom Split Words):输入要分割的自定义单词,以逗号分隔。留空以使用默认列表。
- 速度:控制生成的语速
2. 多人语音生成(Podcast Generation)
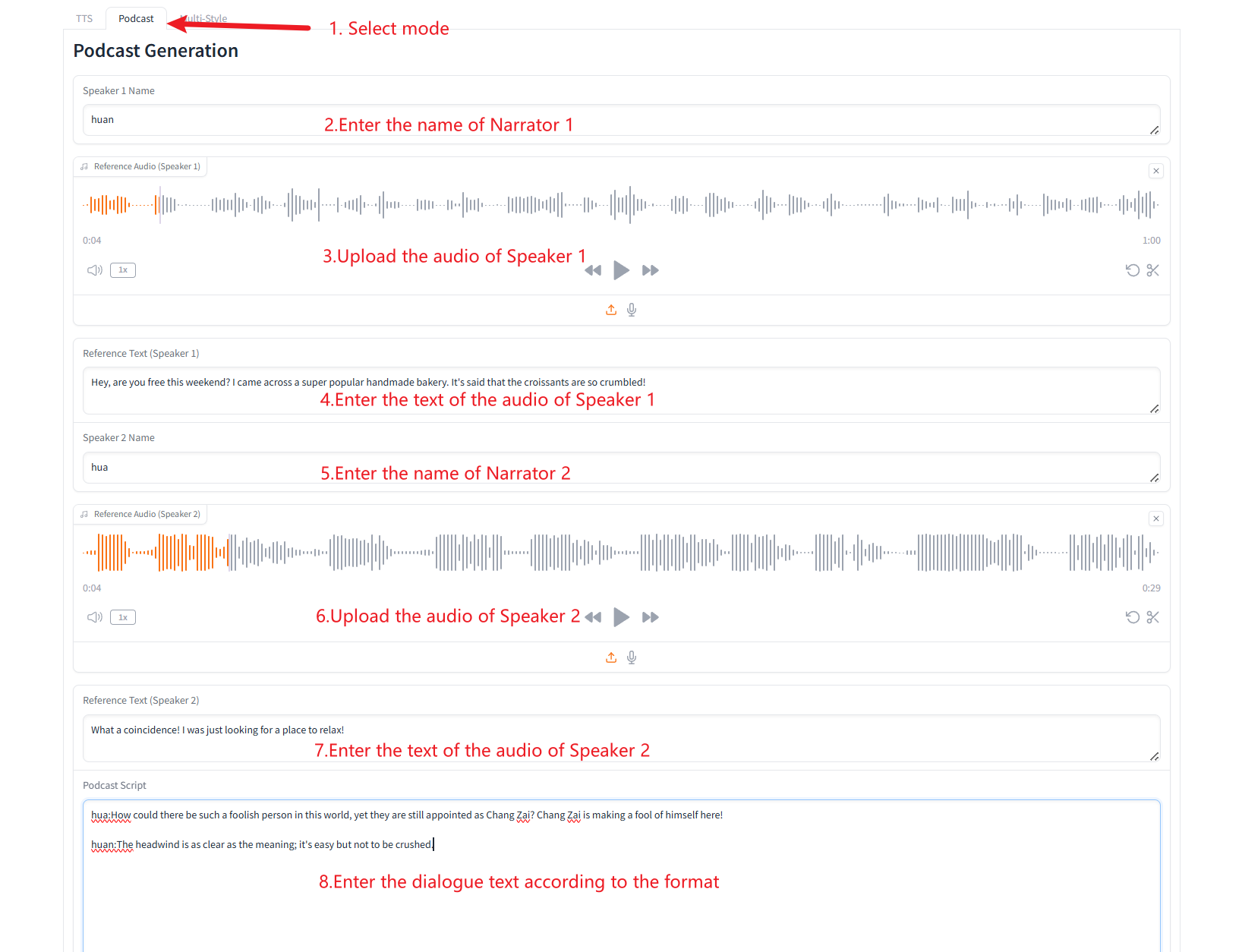
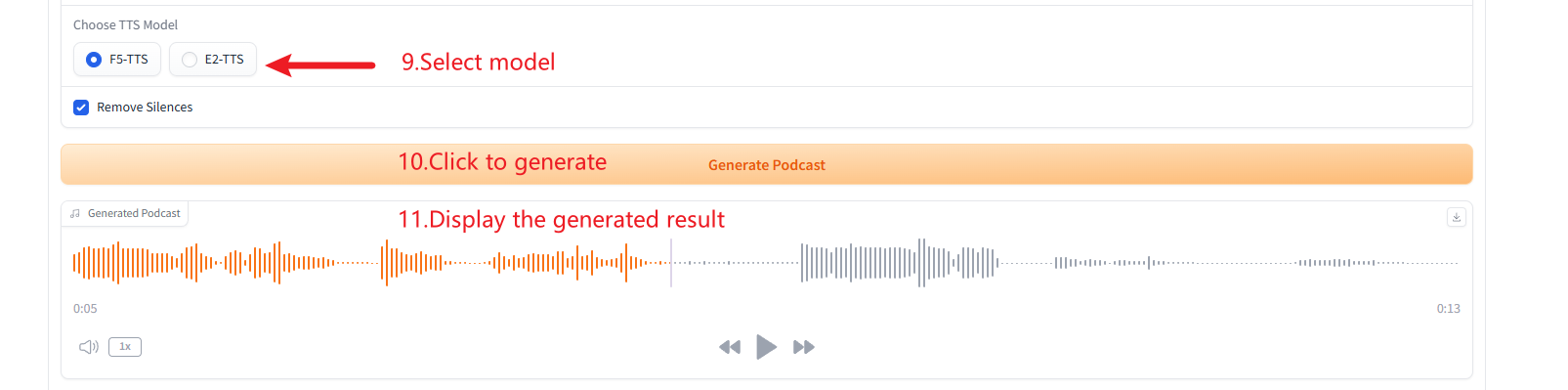
3. 多种语音类型生成(Multiple Speech-Type Generation)
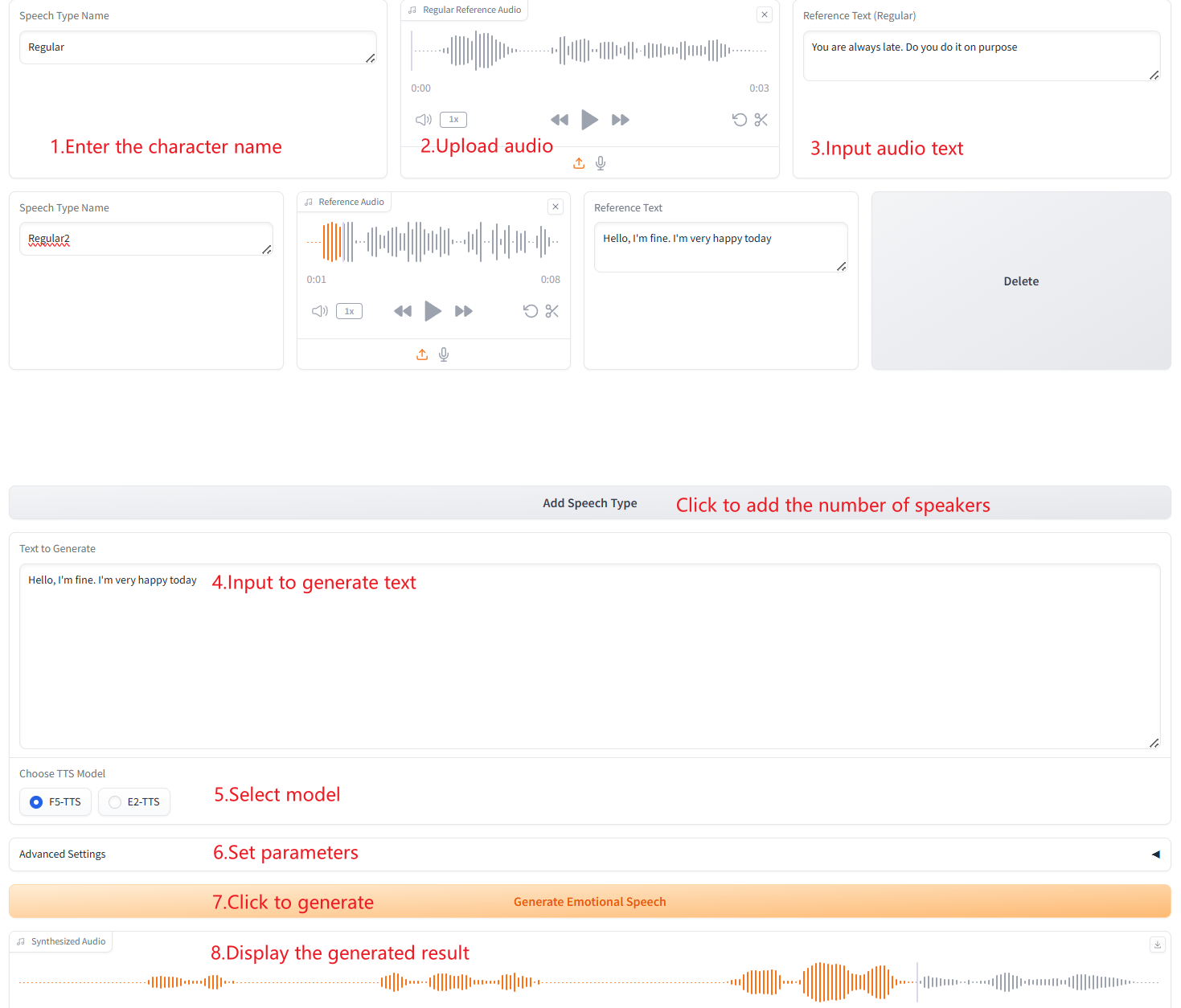
引用信息
@article{chen-etal-2024-f5tts,
title={F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching},
author={Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen},
journal={arXiv preprint arXiv:2410.06885},
year={2024},
}