HyperAI
Command Palette
Search for a command to run...
VibeVoice-Realtime TTS:实时语音合成服务
一、教程简介

VibeVoice-Realtime TTS 是一个高质量的实时文本转语音(Text-to-Speech, TTS)系统,由 Microsoft Research 团队于 2025 年 12 月发布的 VibeVoice-Realtime-0.5B 流式语音合成模型构建。该系统采用一种新颖的次令牌扩散(next-token diffusion)方法,用于在长篇多说话者语音合成中建模连续数据,并引入高效的连续语音分词器,使模型能够在 64K 上下文窗口内生成长达 90 分钟的语音,最多支持 4 名说话者,同时在保持音频忠实度的前提下大幅提升计算效率,捕捉真实对话氛围。相关论文成果为 VibeVoice: High-Fidelity Multi-Speaker Streaming Text-to-Speech 。该系统支持多说话人语音生成、低延迟实时推理,以及 Gradio Web 端可视化交互。
核心特性:
- 多说话人实时语音合成
- 流式推理,低延迟输出
- 高保真 24000Hz 语音采样率
- 支持 CFG Scale 可控生成
- GPU 加速推理
- 完整本地离线部署,不依赖外网
本教程使用 Gradio 部署 VibeVoice‑Realtime‑0.5B 核心模型,算力资源采用「RTX_5090」,可稳定支撑实时语音合成服务运行。本模型仅支持英文文本输入。
二、效果展示
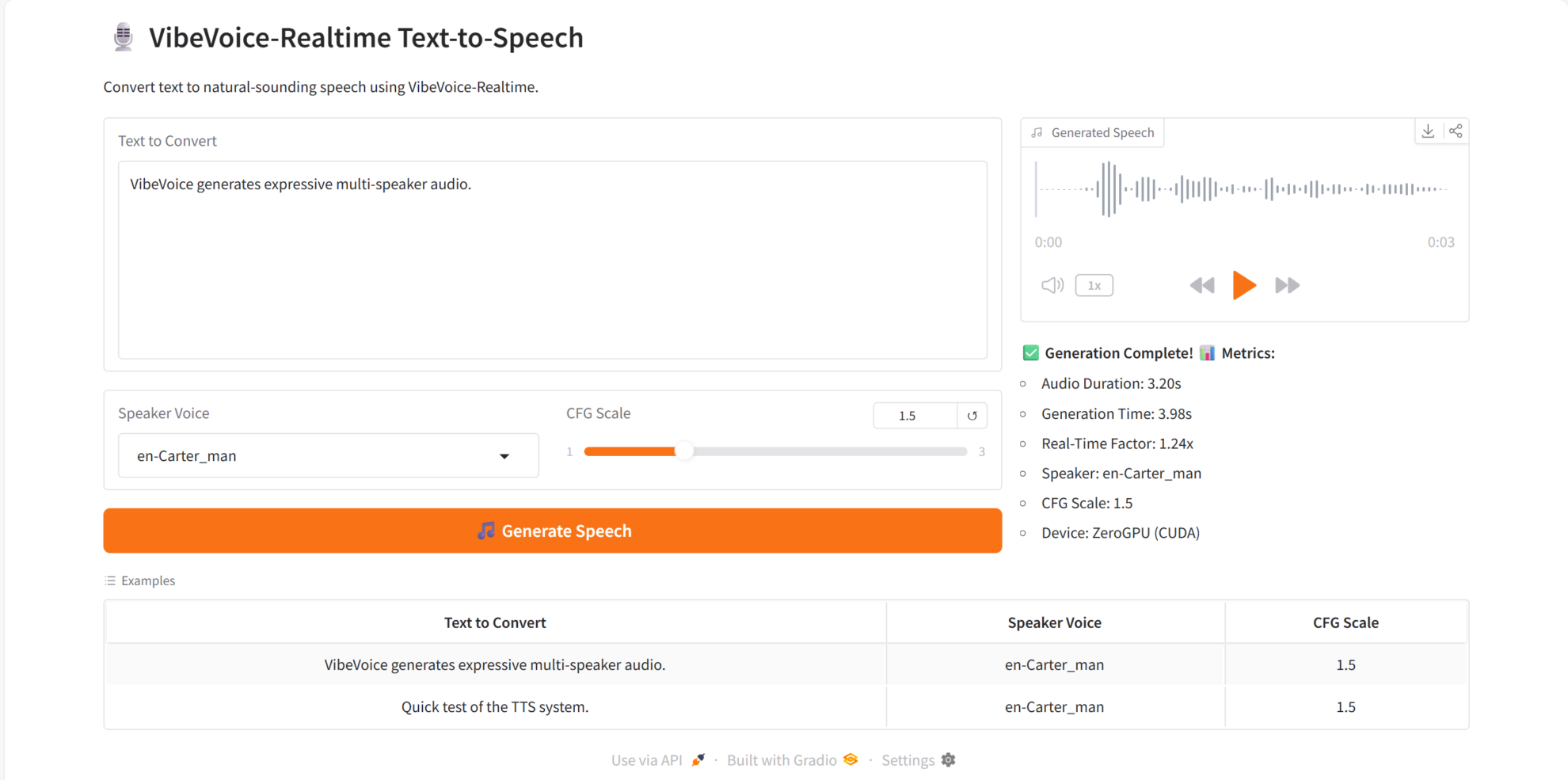
VibeVoice-Realtime 在核心能力上表现优异:
- 实时 TTS:输入文本后可快速生成语音输出
- 多说话人支持:同一文本可切换不同音色风格
- 高自然度语音:音质清晰,语调自然
- 长文本稳定合成:无明显断句或失真问题
- 实时交互能力强,适用于对话系统、语音助手等场景
三、运行步骤
1. 启动容器
启动容器后点击 API 地址即可进入 Web 界面
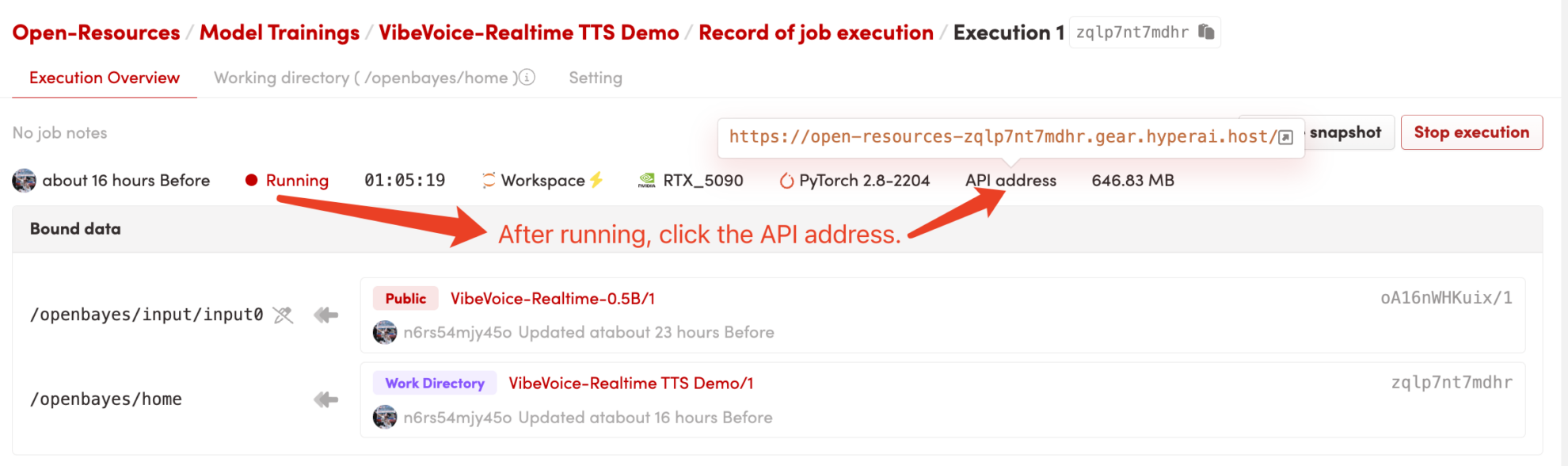
2. 开始使用
若显示「Bad Gateway」, 这表示 模型正在初始化,由于模型较大,请等待 1-2 分钟后刷新页面。
使用 Safari 浏览器时,音频可能无法直接播放,需要下载后进行播放。
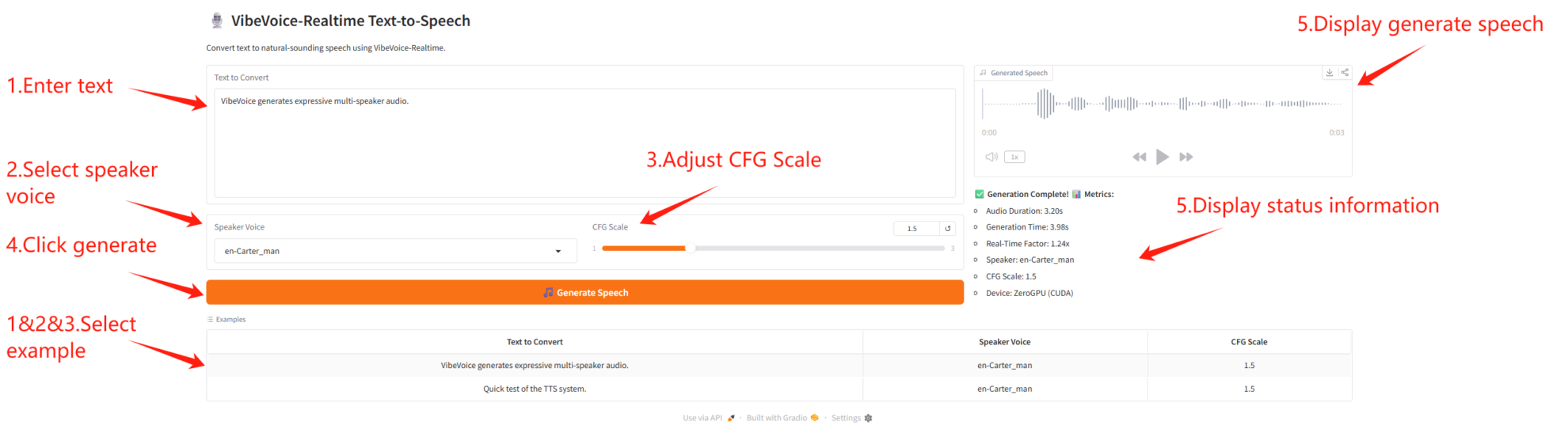
参数说明
- 语音生成参数
- CFG Scale:控制语音风格强度,数值越大情感越强。
- 说话人参数
- Speaker Voice:选择不同的说话人音色。

引用信息
本项目引用信息如下:
@article{vibevoice2024,
title={VibeVoice: Real-Time Streaming Text-to-Speech with Multi-Speaker Support},
author={Zhiliang Peng and Jianwei Yu and Wenhui Wang and Yaoyao Chang and Yutao Sun and Li Dong and Yi Zhu and Weijiang Xu and Hangbo Bao and Zehua Wang and Shaohan Huang and Yan Xia and Furu Wei},
journal={arXiv preprint arXiv:2412.08635},
year={2024}
}
@article{vibevoice2025,
title={VibeVoice: High-Fidelity Multi-Speaker Streaming Text-to-Speech},
author={Zhiliang Peng and Jianwei Yu and Wenhui Wang and Yaoyao Chang and Yutao Sun and Li Dong and Yi Zhu and Weijiang Xu and Hangbo Bao and Zehua Wang and Shaohan Huang and Yan Xia and Furu Wei},
journal={arXiv preprint arXiv:2508.19205},
year={2025}
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。