Command Palette
Search for a command to run...
在线教程丨香港科技大学团队开源首个确定性视频深度框架 DVD,零样本刷新 SOTA

深度估计是三维视觉领域最基础也最关键的任务之一。从自动驾驶、机器人导航,到 AR/VR 、数字孪生和视频内容生成,系统都需要准确理解场景中物体与相机之间的空间关系。然而,视频深度估计长期面临一个难以调和的矛盾:以扩散模型为代表的生成式方法拥有强大的语义理解能力,能够借助海量预训练数据推断复杂场景结构,但其预测结果往往受到随机采样过程影响,容易出现几何幻觉、尺度漂移以及时序不稳定等问题;而传统判别式方法虽然具备较好的确定性,却严重依赖大规模标注数据,训练成本高昂,在复杂场景中的泛化能力也受到限制。
针对这一行业痛点,香港科技大学(广州)团队提出了 DVD(Deterministic Video Depth Estimation),首次实现了将预训练视频扩散模型确定性地转化为单次前向传播的视频深度估计器。与传统扩散模型需要多轮迭代生成结果不同,DVD 通过一次前向计算即可完成深度预测,不仅显著提升推理效率,更彻底消除了随机采样带来的几何幻觉问题,从根本上保证了视频序列中的时序一致性和结构稳定性。
更重要的是,DVD 成功保留了视频基础模型中蕴含的大量几何与语义先验知识。通过创新性的结构锚点机制以及潜在流形校正(LMR)技术,模型能够在保持全局场景稳定性的同时准确恢复物体边缘、高频纹理和运动细节,大幅提升深度图的结构保真度。
在多个公开基准测试中,DVD 的零样本性能达 SOTA 级别,并且仅使用 36.7 万帧训练数据便达到领先水平,相比主流判别式方法所需的 6,000 万帧训练数据减少约 163 倍。这不仅验证了生成式基础模型在几何理解上的巨大潜力,也为未来低成本、高精度的视频三维感知提供了一条全新的技术路线。
为了便于开发者快速体验 DVD,HyperAI 上线了易于部署的 Notebook,降低使用门槛,一键直达 SOTA 模型 ⬇️
在线运行:https://go.hyper.ai/w8kUO
开源地址:https://github.com/EnVision-Research/DVD
更多在线教程:
Demo 运行
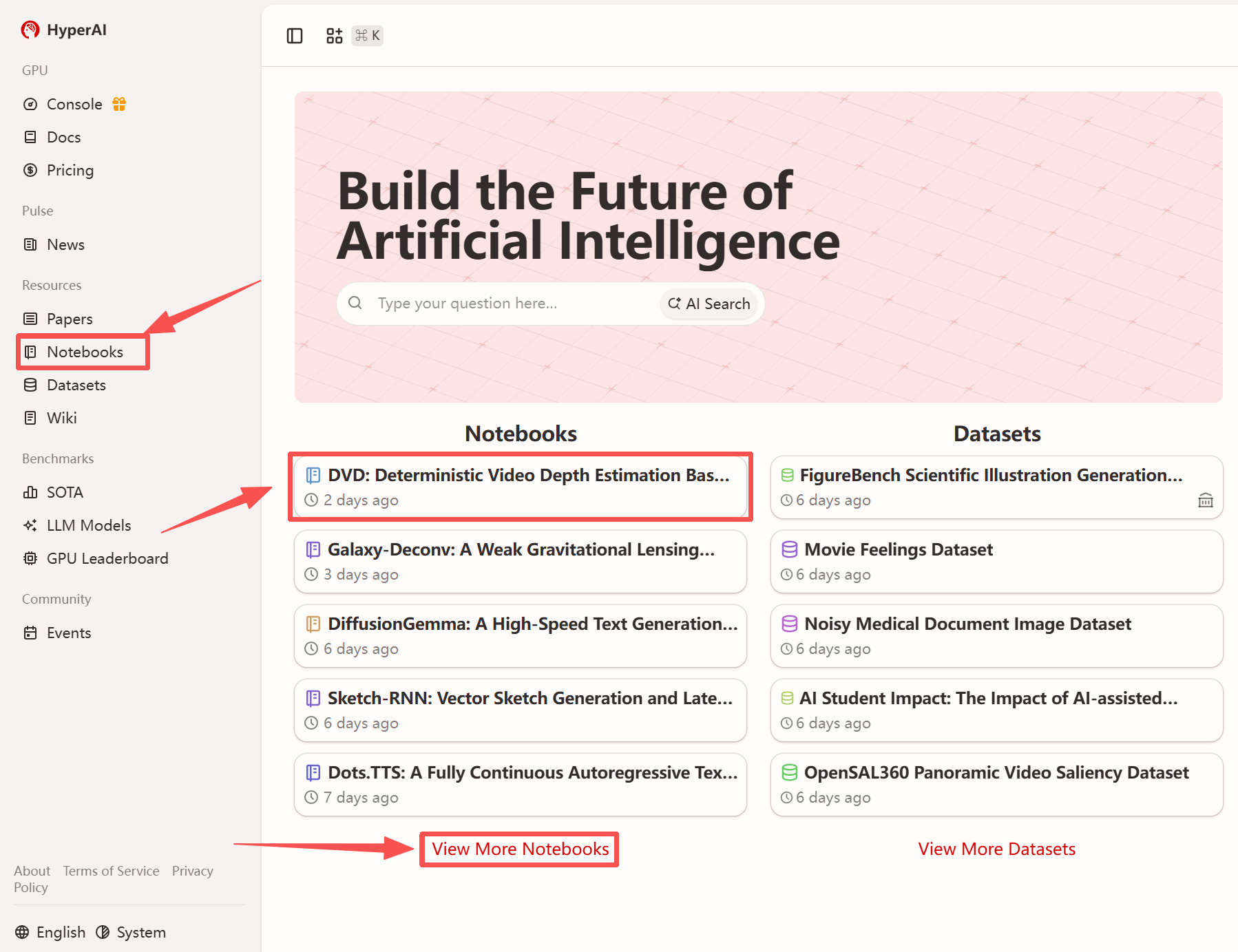
1. 进入 hyper.ai 首页后,选择「教程」页面,或点击「查看更多教程」,选择「DVD:基于生成先验的确定性视频深度估计」,点击「运行此教程」。
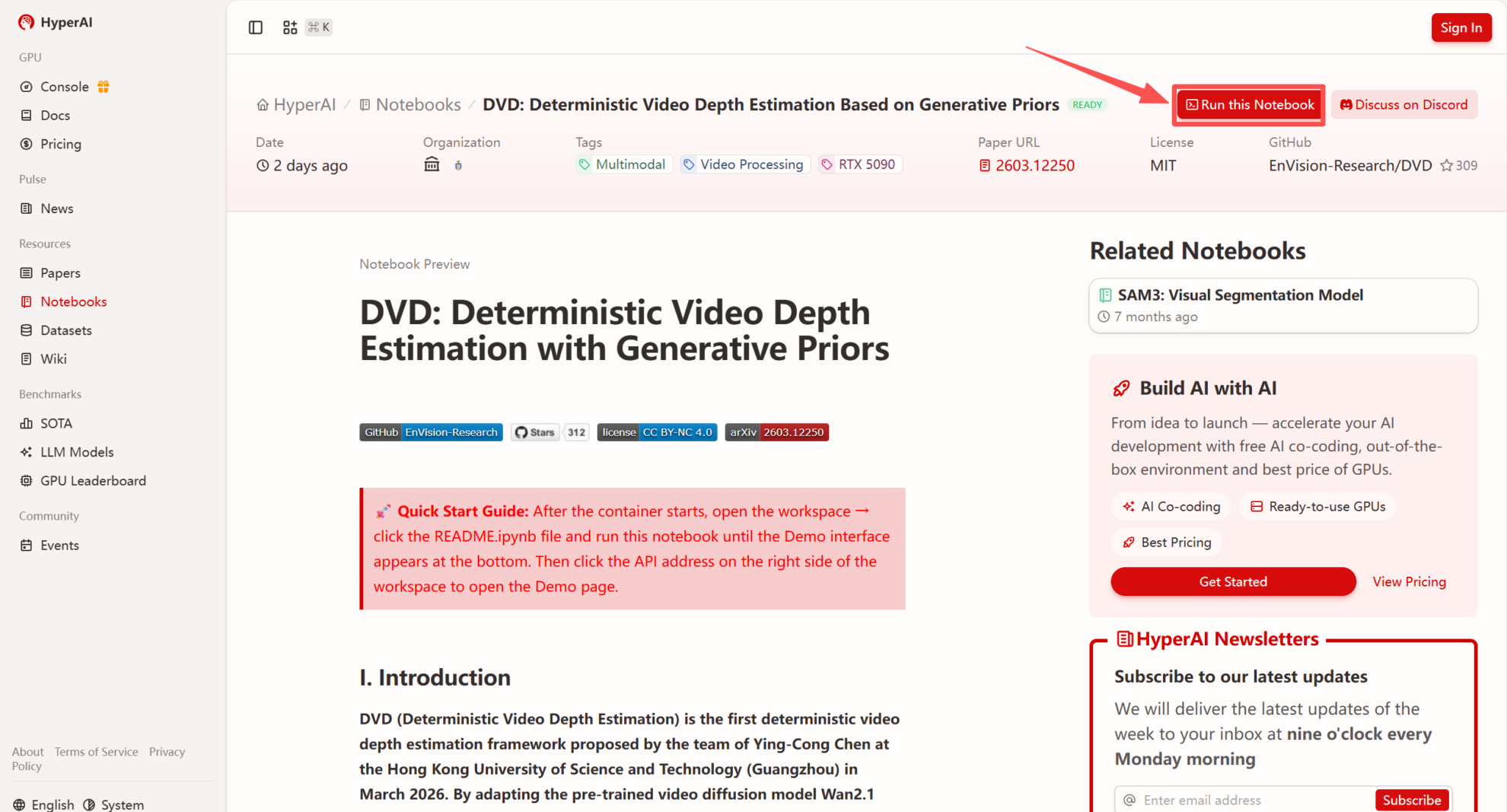
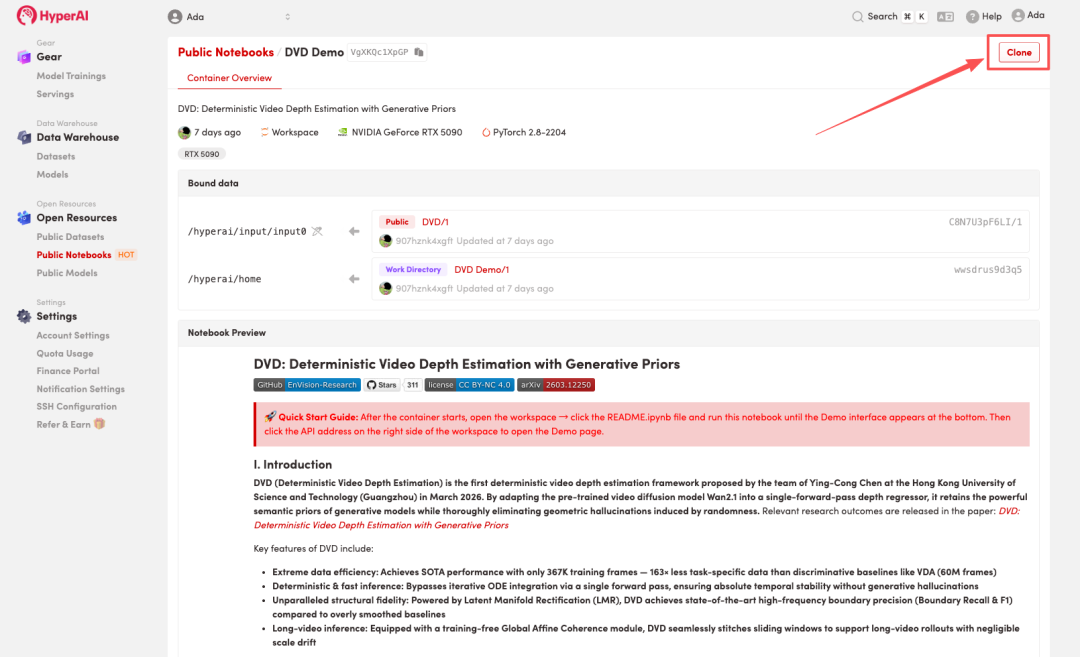
2. 页面跳转后,点击右上角「Clone」,将该教程克隆至自己的容器中。
注:页面右上角支持切换语言,目前提供中文及英文两种语言,本教程文章以英文为例进行步骤展示。
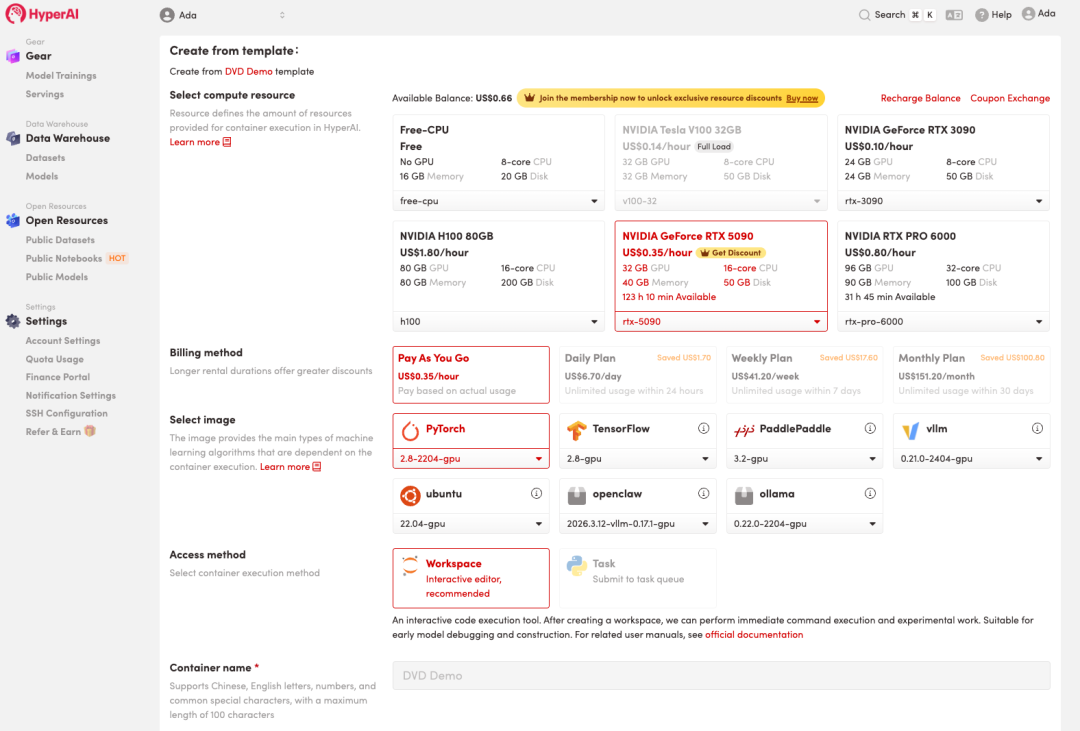
3. 选择「NVIDIA RTX 5090」以及「PyTorch」镜像,点击「Continue job execution(继续执行)」。
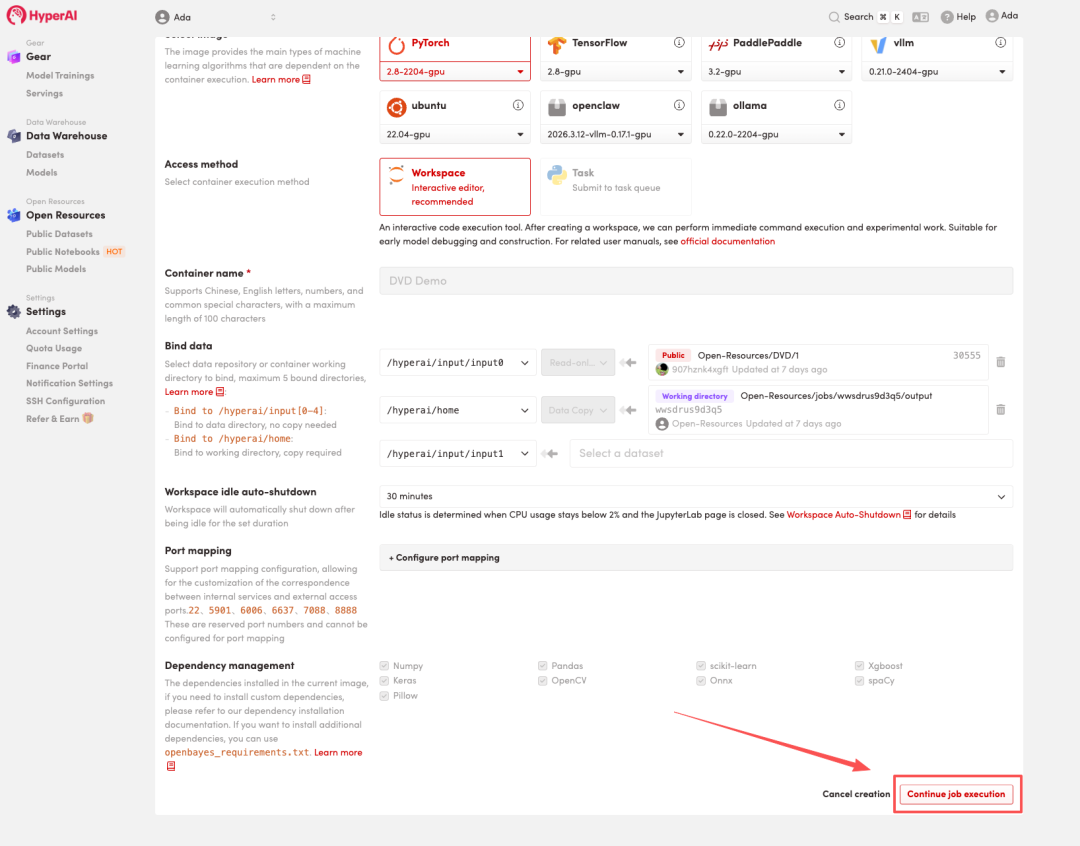
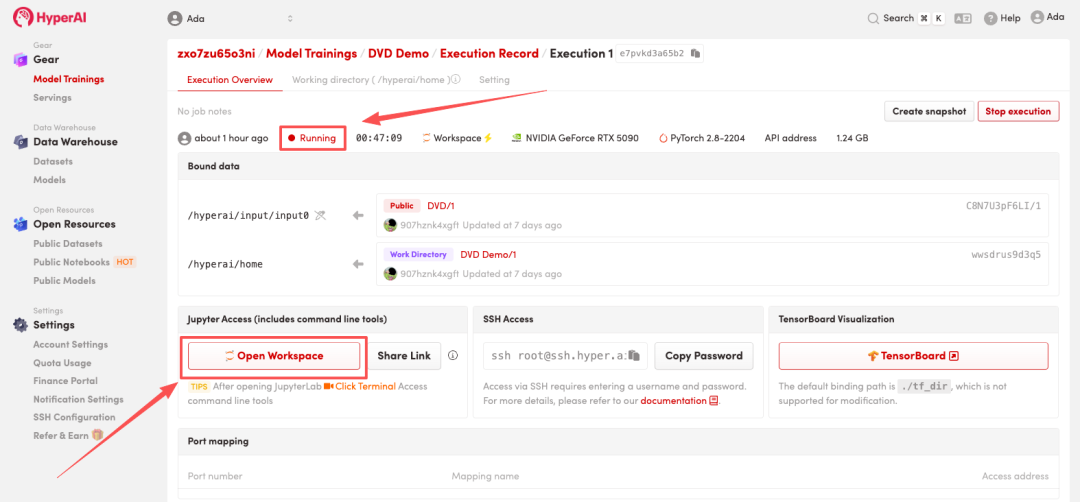
4. 等待分配资源,当状态变为「Running(运行中)」后,点击「Open Workspace」进入 Jupyter Workspace 。
效果展示
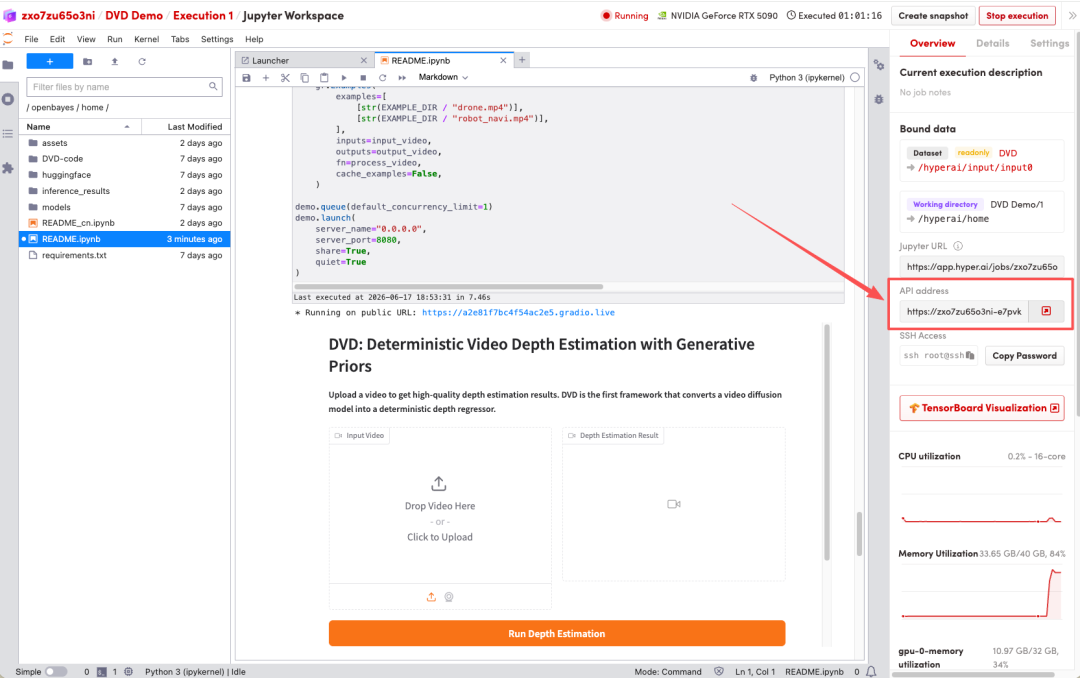
1. 页面跳转后,点击左侧 README 文件,进入后点击上方 Run(运行)。
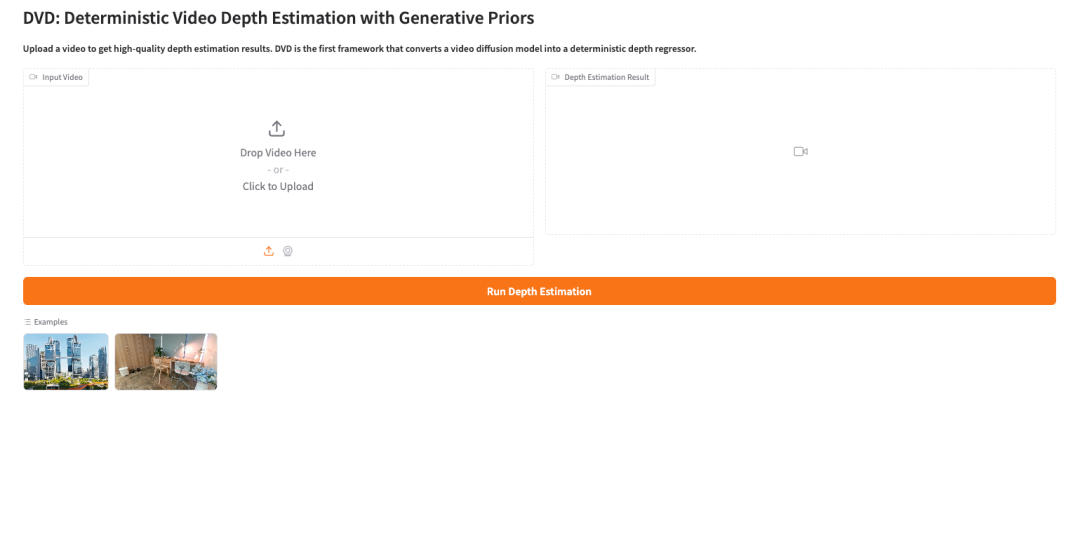
2. 待运行完毕后,点击右侧 API 地址即可打开 Demo 界面。