Command Palette
Search for a command to run...
基于超 2 万条配方,MIT 等采用扩散模型规划材料合成,成功制备硅铝比高达 19 的新型沸石材料

材料合成作为化学、物理与工程学深度交织的前沿领域,始终是现代科技创新的核心驱动力。然而,一种新材料的诞生,从来不是对既定配方的简单实现,而是一场融合了科学直觉、精密调控与持久探索的不确定性创造。若将这一过程比作烹饪,即便面对同一道菜肴,不同的厨师、原料配比、加工技艺,乃至分秒间的火候差异,都会深刻影响最终的风味;材料合成亦是如此——每一次参数的选择,每一次条件的微调,都足以对材料性能产生巨大甚至决定性影响,使其走向不同的归宿。
当前,科研人员们通过高通量计算与数据驱动方法,已从海量化合物中筛选出数百万种具备潜在稳定性与可合成性的材料。这就如同一本收录了无数珍贵名菜的「菜单」,初步解答了材料合成领域「what to synthesize(合成什么)」的根本问题。然而,正如烹饪不仅依赖菜谱,更考验制作程序,仅有「菜单」而缺乏可行的「烹饪方法」,依然是材料合成面临的关键瓶颈。因此,如何将理论中的材料「烹饪」出来,即解决「how to synthesize(如何合成)」这一难题,正是当前材料研究迈向实际应用所必须跨越的重要关卡。
针对上述挑战,来自麻省理工学院、德国慕尼黑工业大学和西班牙瓦伦西亚理工大学的研究团队创新地提出了一种生成式扩散模型 DiffSyn 。该模型基于超 50 年时间跨度文献中 23,000 余条生成配方训练得到,能够根据目标沸石结构和有机模板生成可能的合成路线。其核心优势是通过捕捉材料中结构 – 合成关系的「一对多」和「多模态」特性,为科研人员完成材料的制备过程提供科学、精准的指导。相较于传统采用回归模型、其他生成模型的方法相比,DiffSyn 展示出更为显著的优越性。
研究过程中,团队展示了 DiffSyn 在预测沸石(zeolites)材料(一类结晶态微孔材料,可广泛应用于催化、吸附和离子交换等领域)的有效合成途径方面的能力。根据其生成的合成路线,研究团队成功制备出一种 UFI 型沸石材料。经密度泛函理论结合能计算验证,其通过电感耦合等离子体光谱法(ICP)测得的硅铝比(Si/Al)高达 19.0,这一优异特性有望显著提升多孔材料的热稳定性,为高温苛刻场景中的应用奠定了基础。
相关研究成果以「DiffSyn: a generative diffusion approach to materials synthesis planning」为题,收录于 Nature Computational Science 。
研究亮点:
* DiffSyn 基于超 50 年文献的 23,961 条合成配方训练,解决了传统回归模型确定性映射的局限
* 与回归模型及其他深度生成模型的对比中,DiffSyn 对 12 项合成参数中 10 项实现最低平均绝对误差,具有显著优越性
* 成功制备出目标材料,硅铝比高达 19.0,体现出 DiffSyn 模型的实用价值

论文地址:
https://www.nature.com/articles/s43588-025-00949-9
关注公众号,后台回复「沸石预测」获取完整 PDF
聚焦沸石合成:训练数据跨越 50 年,涵盖 23000 多条配方
作为材料合成领域中一项深度、成功的研究成果,DiffSyn 最大的特点便是聚焦。 DiffSyn 模型训练所采用的核心数据集为 ZeoSyn 数据集,这是由同一团队提出的一个涵盖 23,961 条沸石水热合成路线的数据集,其中包括了 233 种沸石拓扑结构和 921 种有机结构导向剂(OSDA)。数据来源是跨度超 50 年的沸石合成相关文献。
强化模型能力:基于生成扩散模型构建,创新引入化学引导
材料合成的路径从来都不是唯一的,正如本研究第一作者 Elton Pan 所言,现实中材料结构 – 合成关系可能是有不同合成路径的,这种范式转变就需要结构 – 合成关系从「一对一」向「一对多」转变。
基础模型选择——生成扩散模型
对于机器学习的方法而言,结构 – 合成间「一对多」的关系会带来巨大挑战,研究人员还不得不考虑其逆向关系,即合成 – 结构间的「一对多」关系,同样单一配方可能因热力学、动力学等复杂因素相互作用而形成产物混合物,即竞争相。另外,合成参数之间也存在复杂的非线性作用,需要采用能够跨越多个合成参数联合概率建模的方法,以便捕捉变量之间的关系,并能够对合成参数予以权衡。
在 DiffSyn 之前,传统基于机器学习的方法主要是采用回归模型构建的。这类方法将材料的某种表征形式与合成参数进行确定性映射,这也直接导致结构 – 合成关系只能是「一对一」存在。更重要的是,其合成参数之间的关系也相互独立,无法表达出各个参数之间的强耦合关系,这些局限都极大限制了回归模型的预测精度。
相比之下,DiffSyn 模型采用了一种全新的思路,基于生成式扩散模型构建。与经典生成式对抗网络相比,扩散模型通过训练去除含噪声数据中的噪声,能生成多样化输出;与变分自编码器等深度生成方法相比,扩散模型迭代式去噪过程使其具备高度表现力,从而可实现优异的样本质量,甚至能够使其捕捉合成空间中竞争相之间的边界。这是本研究区别于以往研究的核心特征,借用作者的一句话而言,「这是一种范式转变,从结构 – 合成之间的一对一映射到一对多映射。」

当然,这也是 DiffSyn 能够预测具有高维合成空间的沸石材料的关键。
核心调控机制——化学引导
DiffSyn 的另一大特征在于「化学引导」。 DiffSyn 并非随机输出参数组,而是通过化学引导让扩散模型生成符合化学规律、针对目标沸石结构的的合成路线。具体来说,是以目标沸石结构 Czeo 和有机结构导向剂(OSDA)Cosda 作为输出入。如下图所示:
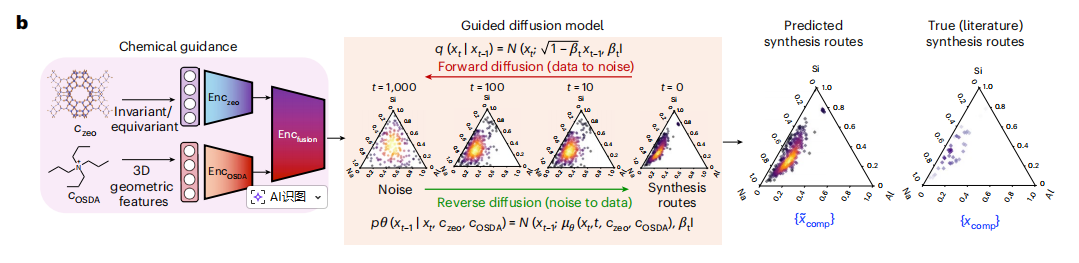
其中,OSDA 是一种有机分子,能够「模板化」沸石的孔道结构,从而引导合成过程形成特定结构。如下图 e 所示。
而最重要的是,该模型并非学习确定性的参数,而是学习条件概率分布,在给定目标结构和 OSDA 的条件下,生成包含凝胶组成 Xcomp 和合成条件 Xcond 的合成路线集合。这是解决上述提到「一对多」关系的关键。
在训练过程中,正向扩散过程(工作流程示意图中红色箭头部分)向 Xcomp 和 Xcond 中添加高斯噪声,逐步将其转化为高斯分布。在推理阶段,反向扩散过程(工作流程示意图中绿色箭头部分)从高斯噪声出发,基于分类器无关引导策略,通过受化学引导的 U 型网络(U-Net)迭代去噪。如下图所示:
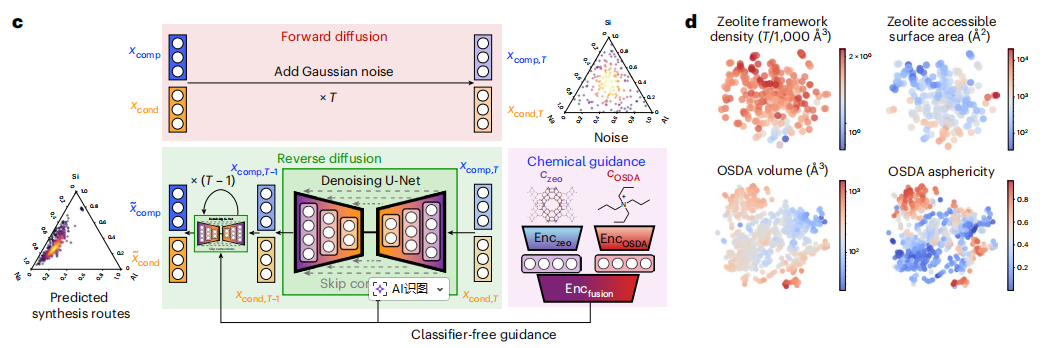
经过 T 个时间步的去噪后,模型即可生成目标结构对应的合成路线。在反向扩散过程中,生成指标如 Wasserstein distance 、 COV-P(精确率)等得到持续优化,这验证了去噪过程的有效性,也表明了化学引导所起的作用。
DiffSyn 工作流程的实现——双编码器、特征融合编码器
在模型架构上,DiffSyn 采用了双编码器架构,分别通过独立编码器(Enczeo 和 EncOSDA)处理沸石结构和 OSDA 。
针对沸石结构的表征,研究团队采用了双表征策略对沸石结构特征进行提取:不变几何特征,研究团队利用 Zeo++ 软件包,从沸石结构中提取有关物理描述符,如孔容、环尺寸、最大包容球直径等,然后将其输入多层感知器编码器进行学习;等变图神经网络(EGNN)表征,研究团队则通过等变图神经网络编码器,直接从沸石晶体结构图谱数据中学习具有化学意义的隐空间特征。
* 数据来源于国际沸石协会(IZA)数据库
对于有机结构导向剂表征,研究团队利用 RDKit 生成有机结构导向剂的多种构象,并采用 MMFF94 力场对每种构象进行气相几何优化。然后,再计算所有构象的物理化学描述符均值,如分子体积、二维形状描述符等,作为该有机结构导向剂的特征。
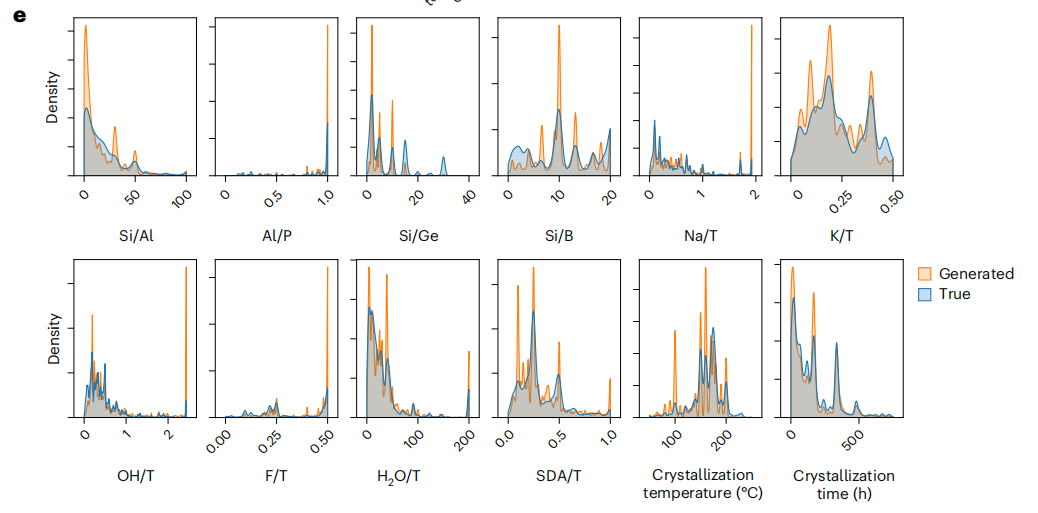
之后,研究团队将沸石的结构特征与有机结构导向剂的特征进行拼接,再通过融合编码器(Encfusion)学习两者的联合表征,并生成化学引导信息。这样将联合表征用于引导扩散模型的反向去噪过程,从而能够确保生成的合成路线符合化学规律。最具实践性的表现是,DiffSyn 能够生成反映训练中未见但在文献中已有报道的合成路线的合成参数。如下图所示:
另外,分类器无关引导也是 DiffSyn 的关键组成部分。核心是不增加额外分类器,通过加权组合条件得分函数(含化学引导信息)和无条件得分函数(不含引导信息),调控生成过程。实验中,当 Puncond = 0.1,W = 1.0 时为最优值,能够使生成合成路线的多样性和质量达到最佳平衡的状态。
* Puncond 为训练时随机省略化学引导的概率,值过高会导致生成路线过度受限,值过低则降低对目标结构的针对性;
* W 为推理时加权条件得分的权重,即引导强度。
总而言之,以上对于保证目标沸石材料生成的合成路线符合化学合理性、精准靶向目标结构,以及提升模型泛化能力奠定了重要基础。
多维实验对比:对比性能达到 SOTA,实践成果刷新报道最高值
为了验证 DiffSyn 的性能,研究团队在实验阶段针对性设立了多组实验,包括与先前方法的比较、通过预测沸石合成路线与文献报道的比较等。
与回归模型、经典生成/深度生成模型的比较
研究团队设置了三类基线模型,将 DiffSyn 与其进行对比,从而评估所提方法的性能和能力。三类基线模型分别是:
* 回归模型:AMD(average minimum distance)和 BNN(Bayesian neural network)
* 经典生成模型:GMM(Gaussian mixture model)
*深度生成模型:GAN(conditional generative adversarial network)、 NF(normalizing flow)和 VAE(variational autoencoder)
实验采用 Wasserstein distance 作为衡量生成数据与真实数据分布差异的指标,采用覆盖率指标 COV-F1(范围从 0 到 1,数值越高越好)作为生成合成路线多样化程度的评价指标。
Wasserstein distance 表明,GAN 、 NF 、 VAE 和 DiffSyn 等深度生成模型明显优于经典方法,而 DiffSyn 比次优基线(VAE)优化了 25% 以上。如下图 a 中所示:
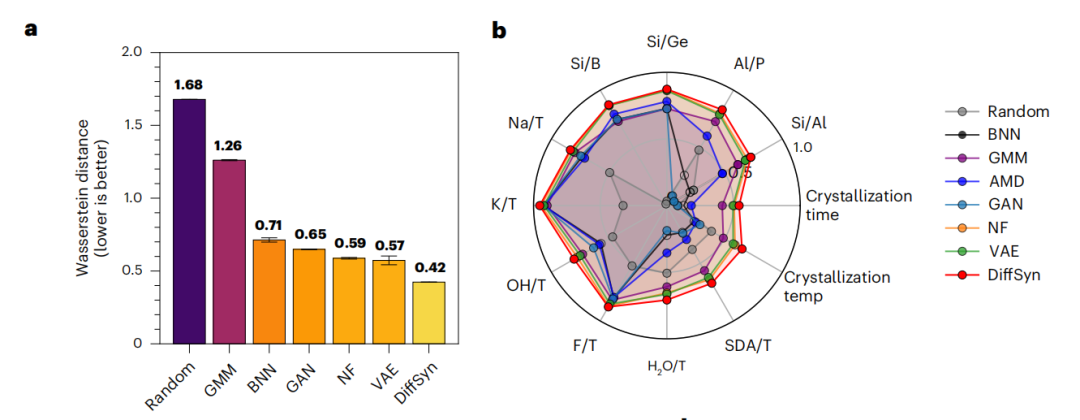
而且深度生成方法的整体表现都要优于回归模型,这主要得益于更高的 COV-R(召回率)。值得一提的是,DiffSyn 由于更高的 COV-P 而优于其他深度生成模型。并且,虽然 DiffSyn 没有像基于回归的方法那样接受明确的平均绝对误差目标训练,却也在 12 个合成参数中实现 10 个参数达到最低平均绝对误差。如下图 c 中所示:
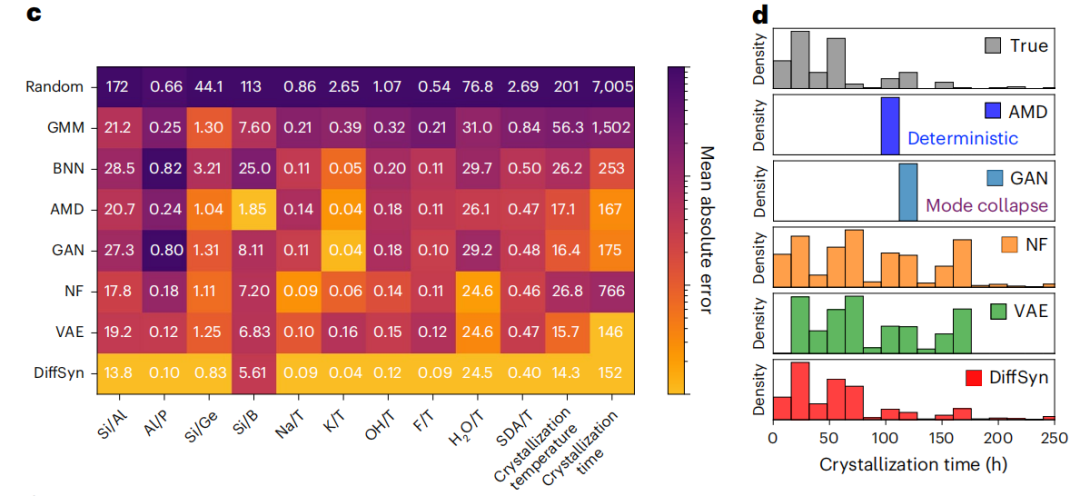
另外,研究团队针对 AEL 沸石比较了所有方法对多个合成参数的预测联合分布与真实联合分布,只有深度生成方法能够捕捉该类晶体结构的结晶温度与时间的真实联合分布。其中,DiffSyn 对该联合分布的捕捉最为准确,包括大部分真实数据点(含部分异常值),但未能预测次要模式中的数据点(极端异常值)。
在后续验证中,基于 DiffSyn 学习了多个合成参数的联合分布,研究团队针对两个未见过的沸石 – OSDA 体系检查了两个合成参数,其结果证实了 DiffSyn 已经掌握了材料合成领域的特定规则,具有重要的化学意义。
将生成合成路线与文献报道合成路线对比
研究团队选取了多种具有研究价值和工业应用前景的沸石 – OSDA 体系,对比了 DiffSyn 生成的合成路线与文献报道的合成路线间的差异,并针对未见过的 MWW 、 BEC 型沸石,以及 FAU/LTA 竞争晶相体系的生成路线验证了 DiffSyn 对合成 – 结构关系的学习能力。如下图所示:
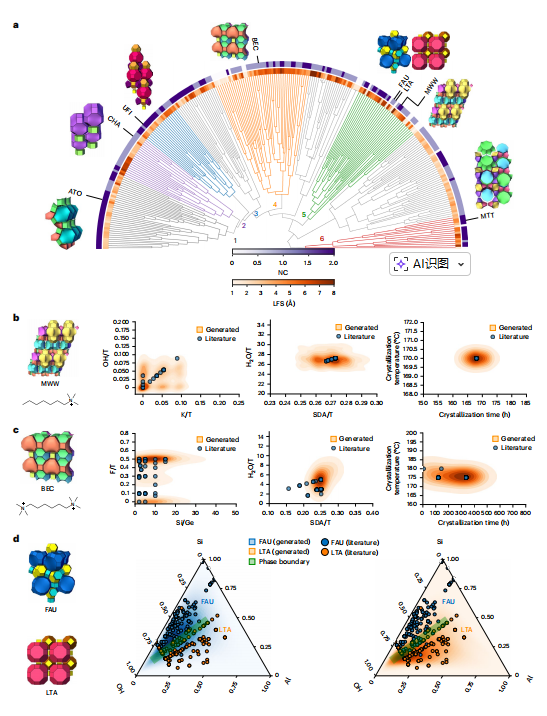
首先,关于 MWW 体系,这是一种具有十元环和大孔腔的二维结构,应用于异构化和芳构化反应。 DiffSyn 生成的 OH⁻/T 、 K⁺/T 、 H₂O/T 、 SDA/T 以及温度和时间等与真实合成参数高度吻合,这证明了 DiffSyn 在未见结构中仍可复现合理窗口。
其次,关于 BEC 体系,这是一种具有三维孔道拓扑结构的大孔沸石,包含交叉的十二元环通道,适用于异构化和环氧化反应。 DiffSyn 生成的合成参数 Si/Ge 、 F⁻/T 以及温度/时间与文献报道高度一致,尤其是文献指出 Ge 与 F⁻ 在合成过程中稳定 BEC 结构的双四元环(d4r),而 DiffSyn 同样如此。这表明了 DiffSyn 能够学习特定杂原子,或合成条件来促进沸石中特定结构单元的形成。
最后,研究团队应用 DiffSyn 预测了无 OSDA 下 FAU 和 LTA 沸石的合成路径,DiffSyn 生成的合成路线与文献报道高度吻合。值得注意的是,DiffSyn 精准预测了无 OSDA 下 FAU 与 LTA 之间的相边界区域,清晰界定了竞争相形成的合成空间。这一结果表明 DiffSyn 不能能准确捕捉结构 – 合成关系,还能逆向解析合成 – 结构的决策边界,从而展现了其实现相选择性合成的潜力,且具有高度推广能力和泛化能力,能在多种沸石结构及其对应化学体系中应用。
生成最优合成路线的检验
能生成合成路线和规划最优合成路线是同一问题在两个维度上的探讨。针对于此,研究团队评估了 DiffSyn 在实现后者上的能力。
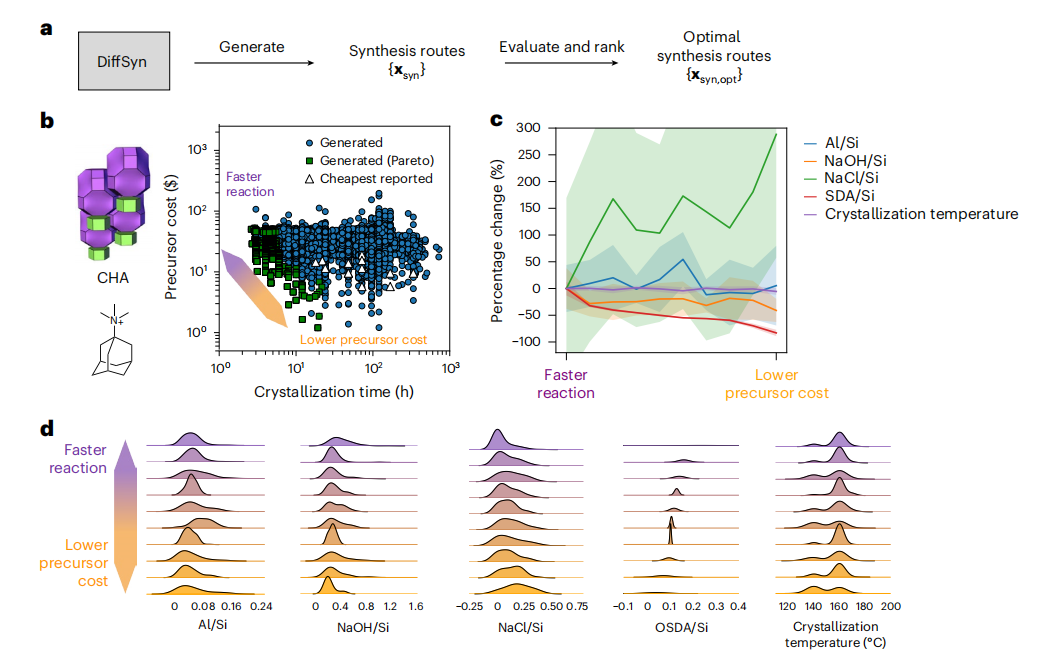
实验采用三甲基金刚烷基铵(TMAda)为有机结构导向剂,合成 CHA 型沸石,生成多组合路线并计算其对应的前驱体成本和结晶时间。如下图所示。 DiffSyn 生成的部分 Praeto-optimal routes,与文献中报道的 20 条成本最低的合成路线相比,具有更短的结晶时间和更低的前驱体成本。
最后,研究团队对 DiffSyn 生成 UFI 型沸石合成路线进行了实验验证,并成功合成出 4 种 UFI 型沸石材料。而对于 UFI 型沸石的合成,研究团队选择了 Kryptofix 222(K222)作为 OSDA,这是因为该体系未在训练数据中出现,有利于检验 DiffSyn 的泛化能力。
DiffSyn 生成了 1000 条合成路线,且其分布位于所有沸石文献报道路线分布的子空间内,如下图所示。并且研究揭示了大多数竞争晶相与目标晶相不存在共同的复合结构单元,证实结构 – 合成关系具有复杂性,无法仅通过结构单元进行解释。
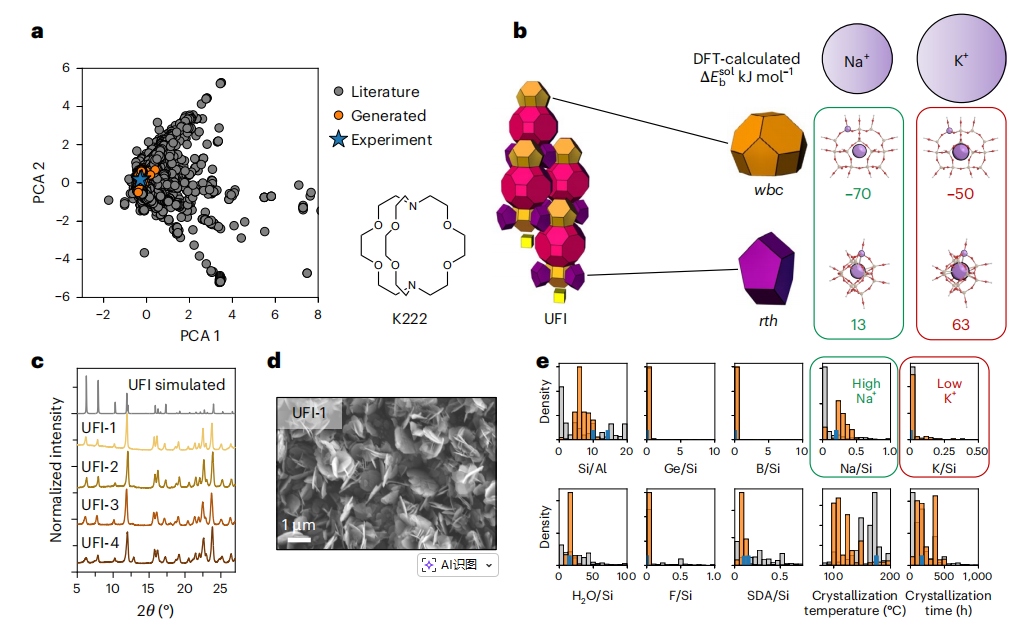
检验结果显示,合成样品的粉末 X 射线衍射图谱与模拟图谱高度吻合,证实所得晶体为 UFI 型沸石结构,经 ICP 测得的硅铝比高达 19.0,是目前 UFI 型沸石合成报道中最高值之一。
更加重要的是,研究团队提到 DiffSyn 与人类专家之间的协同是实现实验理想合成结果的关键,并通过结晶温度的例子验证了这句话的含金量。总而言之,模型提供合成路线,人类专家运用经验做出矫正和决策,或许才是未来人工智能应用于材料合成规划的关键。
丰富材料合成这本「食谱」,连接「合成什么」与「如何合成」
材料合成领域与人工智能领域的交叉融合正在不断加深,这为材料合成领域走向智能化、精准化、一体化提供了加速器。
首先,人工智能尤其是生成式人工智能的大力发展,正在加速材料合成数据库的形成,尤其在产业界,谷歌、 Meta 等科技巨头大量投资的生成式人工智能,为其创建了大量的材料合成配方数据库,这些配方从理论上为材料合成与创新提供了丰富的土壤。
再者,针对细分领域,相关数据库也正在不断完善、丰富,尤其在学研界发展更为聚焦。如该项研究之前,团队就已针对沸石材料进行了长期的跟踪。基于当前公共沸石合成数据库规模小、数量少的难题,提出了 ZeoSyn 数据集——一个包含 23,961 条沸石水热合成路线的数据集。与此同时,相关研究还开发了一个机器学习分类器,以给定的合成路线预测沸石,准确率达到 70% 。这为团队的进一步研究可谓奠定了坚实的基础和牢靠的理论支撑。
* 论文标题:
ZeoSyn: a comprehensive zeolite synthesis dataset enabling machine-learning rationalization of hydrothermal parameters
* 论文地址:https://dspace.mit.edu/handle/1721.1/164092
而材料合成配方数据库就如同「食谱」中的「菜单」,如前述所言,仅有「菜单」而缺乏「烹饪方法」亦不能成。从回归模型到生成模型再到扩散模型的应用,无异于是科研人员针对一道佳肴的不断探索和创新,这些人工智能技术的应用,也就像是给「菜单」上的每道菜添加了各派的「烹饪方法」,最终也使得「食谱」得以完善。
最后,材料合成的过程虽如烹饪,但也存有巨大不同。与寻常烹饪相比,材料合成的每一次成功都是非一道风味独特的佳肴可比的,每一种新材料的诞生都可能开启一扇未知世界的大门,其背后蕴藏着的是推动人类文明和时代进步的无限可能。








