Command Palette
Search for a command to run...
揭秘 AI 推理:OpenAI 稀疏模型让神经网络首次透明化;Calories Burnt Prediction:为健身模型注入精准能量数据

原创 林佳敏 HyperAI 超神经2026 年 1 月 14 日 17:06北京
近年来,大语言模型在能力上突飞猛进,但其内部决策过程如同一个深度纠缠的「黑箱」,难以追溯和理解。这一根本性难题,严重阻碍了 AI 在医疗、金融等高风险领域的可靠应用。如何让模型的思考过程变得透明、可追溯,仍是悬而未决的关键问题。
基于此,OpenAI 于 2025 年 12 月发布的 0.4B 参数大语言模型 Circuit Sparsity,它采用电路稀疏技术,将 99.9% 的权重置零,构建出可解释的稀疏计算架构,突破传统 Transformer 的「黑箱」决策限制,使 AI 推理过程可逐层解析。该模型的核心,是通过一套独特的训练方法,将传统密集神经网络改造为结构化的稀疏「电路」。
*动态强制稀疏:与传统方法不同,它在训练的每一步都执行「动态剪枝」,每轮仅保留权重中绝对值最大的极少数(如 0.1%),其余强制归零,迫使模型从一开始就学习在极简连接下工作。
*激活稀疏化:在注意力机制等关键位置引入激活函数,使神经元的输出趋于「非此即彼」的离散状态,从而在稀疏网络中形成清晰的信息通道。
*定制化组件:采用 RMSNorm 替代 LayerNorm 以防止破坏稀疏性;并引入 Bigram 查找表来处理简单词汇预测,让主网络更专注于复杂逻辑。
通过上述方法训练出的模型,其内部自发形成了功能明确、可被解析的「电路」。每个电路负责一个特定子任务。研究人员可明确识别出,某些神经元专门用于检测「单引号」,而另一些则充当逻辑「计数器」,相比传统密集模型,完成相同任务所需的活跃节点数量大幅减少。其配套的「桥梁网络」技术,试图将稀疏电路中获得的解释映射回 GPT-4 等高性能密集模型,也为分析现有大模型提供了潜在工具。
目前,HyperAI 超神经官网已上线了「Circuit Sparsity:OpenAI 开源新稀疏模型」,快来试试吧~
在线使用:https://go.hyper.ai/WgLQc
1 月 5 日-1 月 9 日,hyper.ai 官网更新速览:
* 优质公共数据集:8 个
* 优质教程精选:4 个
* 本周论文推荐: 5 篇
* 社区文章解读:5 篇
* 热门百科词条:5 条
* 1 月截稿顶会:9 个
访问官网:hyper.ai
公共数据集精选
1. MCIF 多模态跨语言指令跟随数据集
MCIF 是由 Fondazione Bruno Kessler 联合 Karlsruhe Institute of Technology 、 Translated 于 2025 年发布的一个基于科学演讲构建的多语言、多模态人工标注评测数据集,旨在评估多模态大语言模型在跨语言场景下的指令理解与执行能力,以及其融合语音、视觉和文本信息进行推理的能力。
直接使用:https://go.hyper.ai/SyUiL
2. TxT360-3efforts 多任务推理数据集
TxT360-3efforts 是由 Mohamed bin Zayed University of Artificial Intelligence 于 2025 年发布的一个用于监督微调(SFT)的超大规模语言模型训练数据集,旨在通过聊天模板控制模型的三种推理强度。
直接使用:https://go.hyper.ai/fMEbf
3. X-ray 违禁品检测数据集
X-ray 违禁品检测数据集是由华南师范大学联合香港理工大学、萨斯喀彻温大学于 2025 年发布的一个面向 X 射线安检场景下违禁品目标检测任务的数据集,旨在提升检测模型在复杂、拥挤安检图像中的识别能力,尤其针对类别不平衡和样本稀缺等现实问题进行设计。
直接使用:https://go.hyper.ai/ppXub
4. MCD-rPPG 多摄像头远程光体积描记数据集
MCD-rPPG 是由 Sber AI Lab 于 2025 年发布的一个多摄像头视频数据集,该数据集由 600 名受试者在不同状态下拍摄的同步视频和生物信号数据组成,旨在进行远程光体积描记(rPPG)和健康生物标记估计。
直接使用:https://go.hyper.ai/6KY40
5. LongBench-Pro 长上下文综合评测数据集
LongBench-Pro 是一个面向长上下文语言模型评测的数据集,旨在系统评估模型在不同上下文长度、任务类型和运行条件下的长文本理解与处理能力。
直接使用:https://go.hyper.ai/7esQI
6. Human Faces 人脸数据集
Human Faces 是于 2025 年发布的一个面向人脸相关计算机视觉任务的数据集,旨在为人脸识别、检测、表情分析以及生成建模等应用提供高质量、结构清晰的图像数据支持。
直接使用:https://go.hyper.ai/9WlDl

7. Calories Burnt Prediction 卡路里消耗预测数据集
Calories Burnt Prediction 是一个面向运动能量消耗预测的监督学习数据集,旨在利用个体的生理特征与运动状态信息,预测其在一次锻炼过程中所消耗的卡路里数量。
直接使用:https://go.hyper.ai/o6X59
8. MapTrace 路径追踪数据集
MapTrace 是由 Google 联合宾夕法尼亚大学于 2025 年发布的一个大规模合成地图路径追踪数据集,该数据集旨在提升多模态大语言模型(MLLMs)在地图场景中的精细空间推理与路径规划能力,核心目标是训练模型生成从起点到终点像素级准确、连续且可通行的路径。
直接使用:https://go.hyper.ai/BGHUu
公共教程精选
1.Circuit Sparsity:OpenAI 开源新稀疏模型
Circuit-sparsity 是 OpenAI 发布的 0.4B 参数大语言模型。它采用电路稀疏技术,将 99.9% 的权重置零,构建出可解释的稀疏计算架构,突破传统 Transformer 的「黑箱」决策限制,使 AI 推理过程可逐层解析。随模型发布的 Streamlit 工具包提供「激活桥」技术,支持研究者追踪内部信号路径、分析功能对应电路,并比较稀疏与密集模型的性能差异。
在线运行:https://go.hyper.ai/zui8w
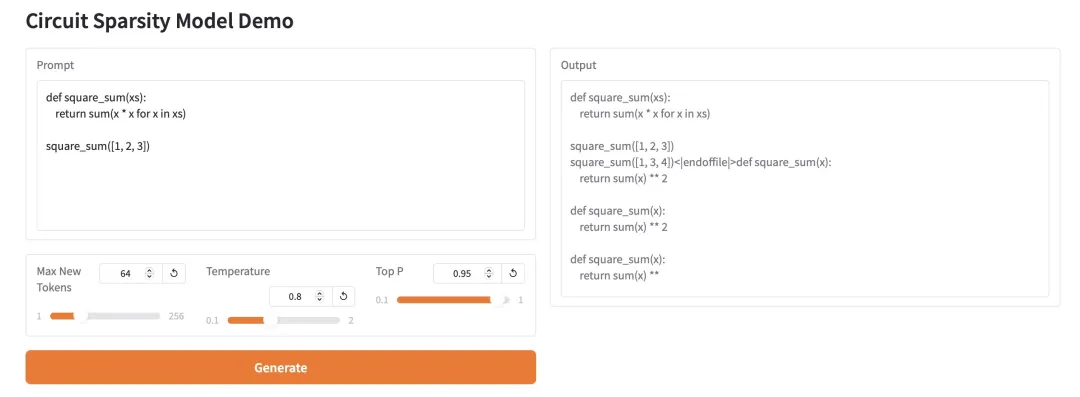
2.HY-MT1.5-1.8B:多语言神经机器翻译模型
HY-MT1.5-1.8B 是腾讯混元团队发布的 18 亿参数多语言机器翻译模型。它基于统一 Transformer 架构,支持 33 种语言与 5 种民族语言/方言的互译,并针对混合语言、术语控制等真实场景优化。该模型在接近 7B 模型翻译质量的同时,参数规模仅为三分之一,支持量化部署与 HuggingFace 生态集成,适用于高效、低成本的多语言在线翻译服务。
在线运行:https://go.hyper.ai/I0pdR
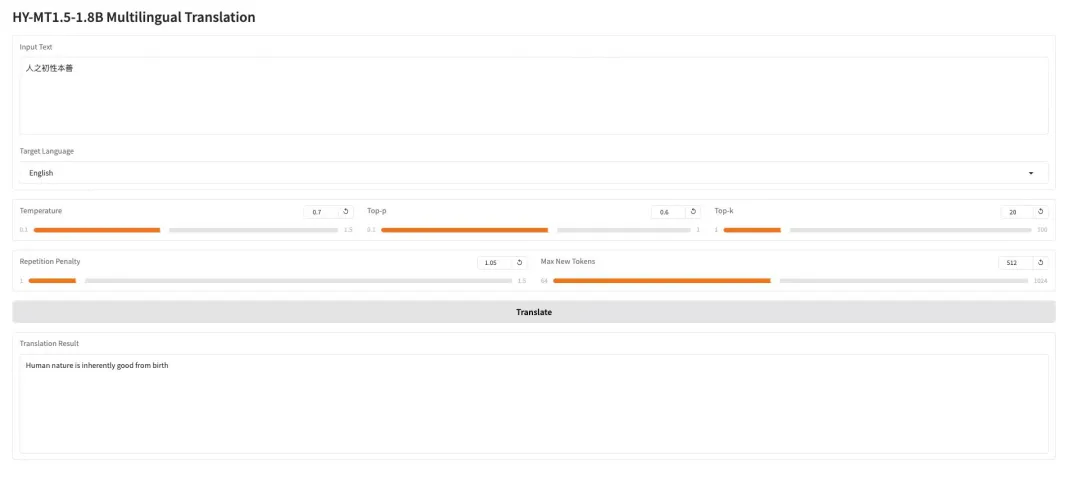
3.AWPortrait-Z 肖像美术 LoRA
AWPortrait-Z 是一款基于 LoRA 技术的肖像增强模型。它作为插件与主流文生图扩散模型结合,无需重训基础模型,即可显著提升人像生成的真实感与摄影质感。该模型专门优化了面部结构、肤质纹理与光影氛围的渲染,生成效果更自然、细腻,适用于需要摄影级真实感的人像创作与图像合成。
在线运行:https://go.hyper.ai/wRjIp
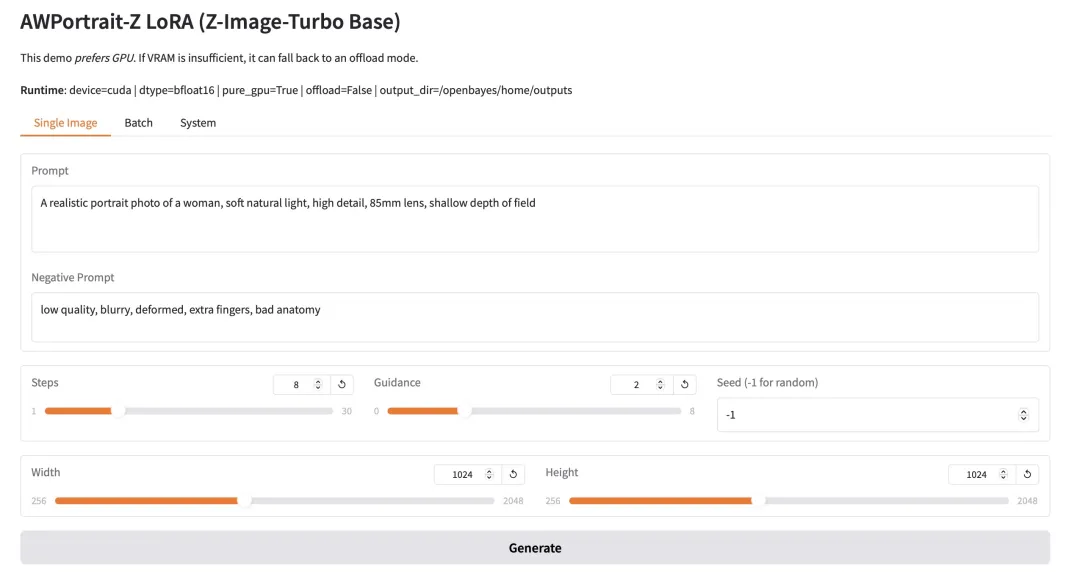
4.Granite-4.0-h-small 一站式进行多语言对话与代码任务
Granite-4.0-h-small 是 IBM 发布的 32 亿参数长上下文指令微调模型。它基于基础模型微调,融合开源与合成数据,采用监督微调、强化学习对齐及模型合并技术。该模型具有优秀的指令遵循与工具调用能力,采用结构化对话格式,专为高效的企业级应用场景优化。
在线运行:https://go.hyper.ai/1HhB9
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD 教程】,入群探讨各类技术问题、分享应用效果~

本周论文推荐
1. mHC:流形约束超连接
本文提出流形约束超连接(Manifold-Constrained Hyper-Connections, mHC),这是一种通用框架,通过将 HC 的残差连接空间投影至特定流形,恢复其恒等映射性质,同时结合严格的基础设施优化,保障计算效率。实验结果表明,mHC 在大规模训练中表现优异,不仅带来切实的性能提升,还展现出卓越的可扩展性。我们预期,作为 HC 的一种灵活且实用的扩展,mHC 将有助于深化对拓扑结构设计的理解,并为基础模型的演进提供富有前景的新方向。
论文链接:https://go.hyper.ai/ZePnH
2. Youtu-LLM:释放轻量级大语言模型的原生智能体潜力
作者提出 Youtu-LLM,一个由 Youtu-LLM 团队开发的 19.6 亿参数轻量级语言模型,通过从零开始采用 “常识-STEM-代理” 原则性课程进行预训练,实现了子 20 亿参数模型中的最先进性能。该模型融合了紧凑的多潜空间注意力架构、面向 STEM 的分词器以及可扩展的流水线,用于在数学、编程、深度研究和工具使用等领域生成高质量的代理轨迹数据。这使得模型能够内化原生的规划、反思和行动能力,在代理基准测试中显著超越更大模型,同时保持强大的通用推理和长上下文能力。
论文链接:https://go.hyper.ai/gitUc
3. Youtu-LLM:释放轻量级大语言模型的原生智能体潜力
本文首先沿着从认知神经科学到大语言模型,再到智能体的演进路径,阐明记忆的定义与功能。随后,从生物与人工两个维度,对记忆的分类体系、存储机制以及完整的管理生命周期进行了对比分析。在此基础上,系统梳理了当前主流的智能体记忆评估基准。此外,本文还从攻击与防御双重视角探讨了记忆系统的安全性问题。最后,展望了未来研究方向,重点关注多模态记忆系统与技能习得机制的构建。
论文链接:https://go.hyper.ai/01H6H
4. 让思维流动:在摇滚乐中构建智能体,于开放智能体学习生态中打造 ROME 模型
作者提出 ROME,一个基于 Agenetic Learning Ecosystem (ALE) 的开源代理模型,该框架整合了 ROCK 的沙箱编排、 ROLL 的后训练优化以及 iFlow CLI 的上下文感知代理执行,通过一种新颖的策略优化算法(IPA)对语义交互块进行信用分配,实现了在 Terminal-Bench 2.0 和 SWE-bench Verified 上的最先进性能,并支持真实场景部署,从而构建可扩展、安全且适用于生产环境的智能体工作流。
论文链接:https://go.hyper.ai/UaAXZ
5. IQuest-Coder-V1 技术报告
本文提出了一套全新的代码大语言模型(LLMs)家族, IQuest-Coder-V1 系列(7B/14B/40B/40B-Loop),与传统的静态代码表征不同,作者提出了一种基于代码流的多阶段训练范式,通过流水线中不同阶段动态捕捉软件逻辑的演化过程。模型通过一条演进式训练流水线构建而成。 IQuest-Coder-V1 系列的发布将显著推动自主代码智能与真实世界智能体系统的研究进展。
论文链接:https://go.hyper.ai/DBYN7
更多 AI 前沿论文:https://go.hyper.ai/iSYSZ
社区文章解读
1. 生成 1.8 万年气候数据,英伟达等提出长距离蒸馏,仅需单步计算实现长期天气预报
英伟达研究院联合华盛顿大学的研究团队推出了一种长距离蒸馏(Long-Range Distillation)新方法,其核心思路是利用擅长生成真实大气变率的自回归模型作为「教师」,通过其低成本、快速模拟产生海量合成气象数据;再用这些数据训练一个概率化的「学生」模型。学生模型仅需单步计算即可生成长期预报,既避免了迭代误差累积,也绕过了复杂的数据校准难题。初步实验表明,基于此训练出的学生模型,在 S2S 预报上与 ECMWF 集成预报系统相当,且其性能随合成数据量增加而持续提升,有望在未来实现更可靠、更经济的气候尺度预测。
查看完整报道:https://go.hyper.ai/Ljebq
2. 黄仁勋最新演讲:5 项创新加持,Rubin 性能数据首曝;多样化开源,覆盖 Agent/机器人/自动驾驶/AI4S
新年伊始,素有「科技春晚」之称的 CES 2026(Consumer Electronics Show,国际消费电子展)在美国拉斯维加斯拉开序幕。黄仁勋虽然并未出现在 CES 官方 Keynotes 演讲名单中,但仍在到处赶场站台,尤为值得关注的便是其在 NVIDIA LIVE 中的个人演讲,在刚刚结束的演讲中,身着标志性黑色皮衣的老黄进一步介绍了这个引入了 5 项创新的 Rubin 平台,并发布了多项开源成果。具体而言: 面向 Agentic AI 的 NVIDIA Nemotron 系列; 面向 Physical AI 的 NVIDIA Cosmos 平台; 用于自动驾驶研发的 NVIDIA Alpamayo 系列;面向机器人领域的 NVIDIA Isaac GR00T; 服务于生物医药领域的 NVIDIA Clara 。
查看完整报道:https://go.hyper.ai/YMK1J
3. 贝佐斯/比尔盖茨/英伟达/英特尔等押注,NASA 工程师带队打造通用机器人大脑,公司估值达 20 亿美元
在大模型可以从互联网、图像库和海量文本中「无限生长」的今天,机器人却被困在另一个世界——真实世界的数据极度稀缺、昂贵且不可复用。针对机器人在物理世界中数据规模不足、结构化程度有限的现实约束,FieldAI 选择了一条不同于主流感知优先路线的解决方式,从底层构建以物理约束为核心的通用机器人智能体系,以提升机器人在真实环境中的泛化与自主能力。
查看完整报道:https://go.hyper.ai/9T1rE
4. 完整回放|上海创智/TileAI/华为/先进编译实验室/AI9Stars 深度拆解 AI 编译器技术实践
在持续演进的 AI 编译器技术浪潮中,越来越多的探索正在发生、沉淀与交汇。 12 月 27 日,Meet AI Compiler 第八期正是在这样的背景下与大家如期相见。本期活动邀请了来自上海创智学院、 TileAI 社区、华为海思、先进编译实验室、 AI9Stars 的 5 位专家,带来了覆盖软件栈设计、算子开发到性能优化的全链路分享。讲师们结合各自团队的长期探索,展示了不同技术路线在真实场景中的实现方式与取舍思路,让抽象概念有了更具体的落脚点。
查看完整报道:https://go.hyper.ai/8ytqF
5. 实现高选择性底物设计,MIT 联手哈佛用生成式 AI 发现全新蛋白酶切割模式
麻省理工学院与哈佛大学联合提出了基于人工智能的端到端设计流程 CleaveNet,通过预测模型与生成模型的协同工作,旨在彻底改变蛋白酶底物设计的现有范式,为相关基础研究与生物医药开发提供全新的解决方案。
查看完整报道:https://go.hyper.ai/tcYYZ
热门百科词条精选
1. 人机回圈 HITL
2. 超倒数排序融合 RRF
3. 具身导航 Embodied Navigation
4. 多层感知机 Multilayer Perceptron
5. 强化微调 Reinforcement Fine-Tuning
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
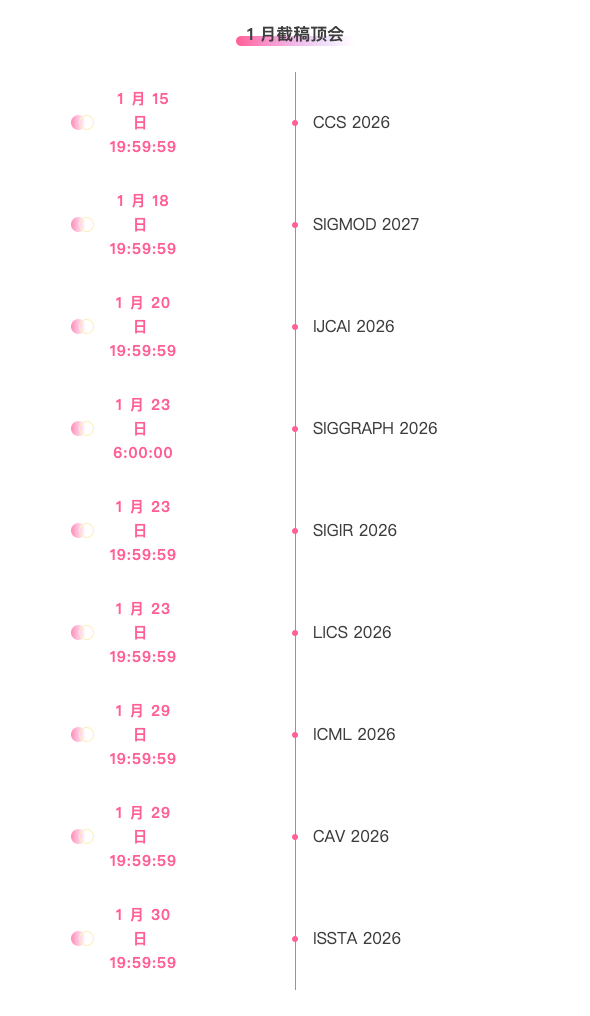
一站式追踪人工智能学术顶会:https://go.hyper.ai/event
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!








