Command Palette
Search for a command to run...
灵敏度提高 56%,港中文/复旦/耶鲁等联袂提出全新蛋白质同源物检测方法

蛋白质是构成生命的物质基础,是生命活动的主要承担者。在后基因组时代,随着蛋白质测定技术的发展,蛋白质序列数据库规模呈爆炸式增长。为了深入了解蛋白质的多样性和功能,识别蛋白质在生物学中也就显得尤为重要。
在对蛋白质的识别过程中,蛋白质序列的同源性鉴定则是其中一项至关重要的任务,它能够帮助科学家们理解蛋白质的进化关系、结构特征以及功能。传统的蛋白质序列比对方法虽然在许多情况下表现出色,但在面对远端同源物时显得力不从心。这些远端同源物由于序列相似性较低,在常规比对中往往被忽视,从而限制了研究人员对蛋白质多样性和复杂性的全面认识。
为解决蛋白质远同源性研究的痛点,基于蛋白质语言模型和密集检索技术 (dense retrieval),香港中文大学李煜,联合复旦大学智能复杂体系实验室、上海人工智能实验室青年研究员孙思琦、耶鲁大学 Mark Gerstein 提出了一种超快速、高灵敏度的同源物检测框架——密集同源物检索器 (DHR) 。
DHR 能在不依赖传统序列比对的情况下,通过双编码器结构和蛋白质语言模型的强大能力,鉴定那些隐藏在序列深处的远端同源物,为同源物鉴定带来了前所未有的速度和灵敏度。该研究以「Fast, sensitive detection of protein homologs using deep dense retrieval」为题,发表在国际著名期刊 Nature Biotechnology 上。
研究亮点:
* 与以前的方法相比,DHR 的灵敏度提高超 10%,对于那些使用基于比对方法难以识别的样品,在超家族水平上的灵敏度提高了超 56%
* DHR 编码查询序列和数据库的速度比 PSI-BLAST 和 DIAMOND 等传统方法快 22 倍,比 HMMER 快 28,700 倍

论文地址:
https://doi.org/10.1038/s41587-024-02353-6
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
多维度构建数据集,旨在探索更广泛的蛋白质序列谱系
该研究构建的训练集包括从 UR90 中精心挑选的 200 万个查询序列。利用 JackHMMER 算法,该研究在 Uni-Clust30 中迭代搜索候选序列,并将候选序列与多序列比对 (MSA) 进行比对。每个 MSA 包含 1,000 个同源物,确保只保留最相关的序列。经过严格的筛选后,JackHMMER 被重新部署来处理获得的不同序列,并与 AF2 (AlphaFold 2) 使用相同的超参数设置,以便于进行公平比较。
在大数据集研究方面,该研究选用了 BFD/MGnify 数据集,这是一个庞大的数据库,包含了大约 3 亿个蛋白质,以便能够探索更广泛的蛋白质序列谱系。
DHR 方法:一种超快速、灵敏的蛋白质同源物搜索管道
DHR 方法的核心思想是将蛋白质序列编码成密集的嵌入向量,从而有效地计算出序列间的相似性。具体来说,该研究通过初始化 ESM 和集成对比学习技术来有效训练序列编码器,从而为蛋白质语言模型的构建创造了条件,并使得 DHR 能被更有效的用来检索同源物。
如下图 a 所示,随着双编码器训练阶段的完成,该研究能够生成高质量的离线蛋白质序列 (protein sequence) 嵌入。然后,该研究利用这些嵌入 (embedding) 和相似搜索算法 (similarity search algorithms) 来检索每个查询蛋白的同源体 (homologs),通过指定相似度作为检索指标 (retrieval metric),可以比传统方法更准确地找到类似蛋白质,并且使用两个蛋白质之间的相似性进一步分析。最后,JackHMMER 构建检索到的同源物 MSA,该研究就得到了能够快速有效发现同源物的 DHR 技术。
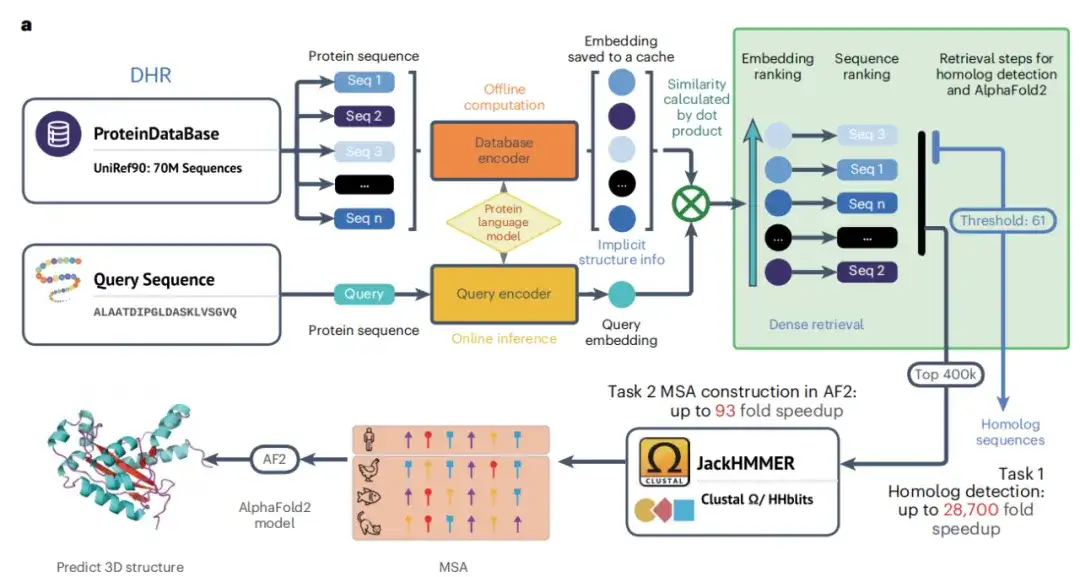
不仅如此,该研究还开发了一个混合模型 DHR-meta,它通过结合 DHR 和 AF2 default,在 CASP13DM(结构域序列)和 CASP14DM 靶标上的表现优于单独的管道。
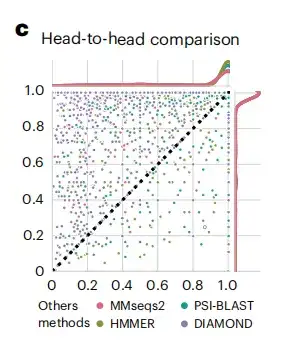
在获得生成的蛋白质嵌入后,该研究将其与标准 SCOPe(蛋白质结构分类)数据集上的方法进行比较,从而评估 DHR 的性能。如下图 c 所示,DHR 数据的灵敏度优于其他方法。
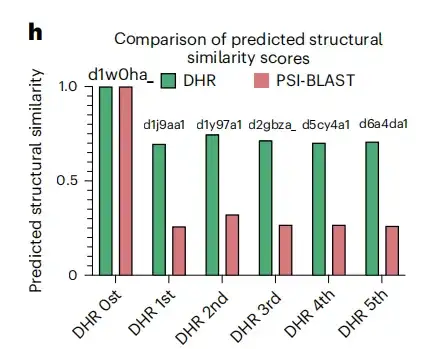
另外,如下图 h 所示,在 d1w0ha 查询的具体示例中,PSI-BLAST 和 MMseqs2 都没有匹配到任何结果,但 DHR 检索到了 5 个同源物,这些同源物在 SCOPe 中也与 d1w0ha 被归为同一家族。这意味着 DHR 可以捕获更多的结构信息。相较于 PSI-BLAST 、 MMseqs2 、 DIAMOND 、 HMMER 等传统方法,DHR 检测到的同源物最多(灵敏度为 93%),这表明,DHR 能够整合丰富的结构信息,并且在许多情况下灵敏度可达到 100%。
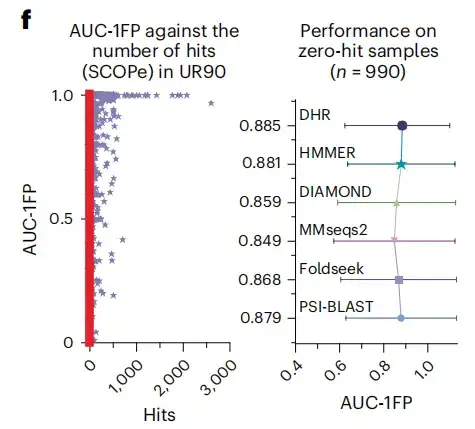
为了加强研究结果的可信度,该研究还纳入了另一个标准指标,即第一次 FP 前的曲线下面积。结果表明,如下图 d 所示,DHR 达到 89% 的分数,同时其他方法也表现出了与 DHR 相当的性能,但它们的执行时间明显更长。当该研究进一步分析更具挑战性的远亲同源物的超家族水平时,所有方法都经历了显著的性能下降,整体下降了大约 10% 。尽管如此,DHR 的表现仍然保持领先,其 AUC-1FP 分数高达 80% 。
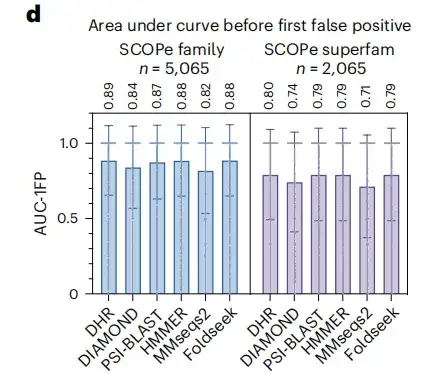
该研究还发现,在使用 BLAST 对 SCOPe 数据库和 UniRef90 进行对比分析时,大多数样本产生的匹配数量少于 100 个,甚至有大约 500 个样本没有得到任何匹配,表明这些样本是训练数据集「未见过的」的结构。作为对比,DHR 面对这些结构时仍然实现了高质量的预测,达到了 89% 的 AUC-1FP 得分,这表明 DHR 有能力处理全新数据。
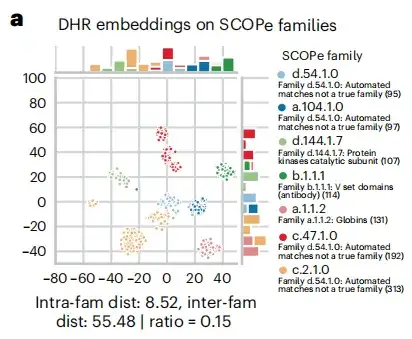
在同源检索过程中,如下图 a 所示,该研究发现 DHR 序列嵌入包含大量的结构信息,并且 DHR 检索到同源物的准确性甚至超过了基于结构对齐 (structure-based alignment methods) 的方法。基于这一结果,该研究进一步揭示了 DHR 的序列相似性排名和结构相似性的相关性。
研究结果:DHR 的准确性和有效性更优,可在大规模数据集上构建高质量 MSA
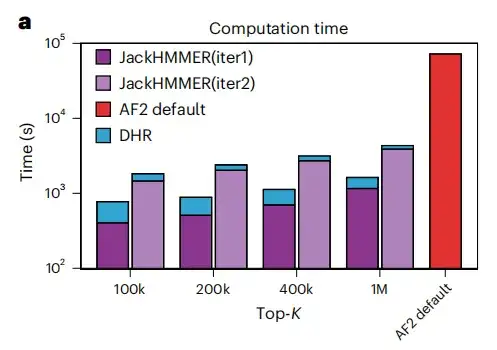
该研究使用 DHR 提供的同源物从 JackHMMER 中创建 MSA,并将其与 AF2 默认管道进行了比较。如下图 a 所示,DHR + JackHMMER 所有配置的平均运行速度都快于 AF2 的普通 JackHMMER 。而且,DHR 在 UniRef90 上构建 MSA 时与 JackHMMER 重叠了大约 80%,这表明许多与 MSA 相关的下游任务可以使用 DHR 执行,既能产生类似的结果,速度还更快。
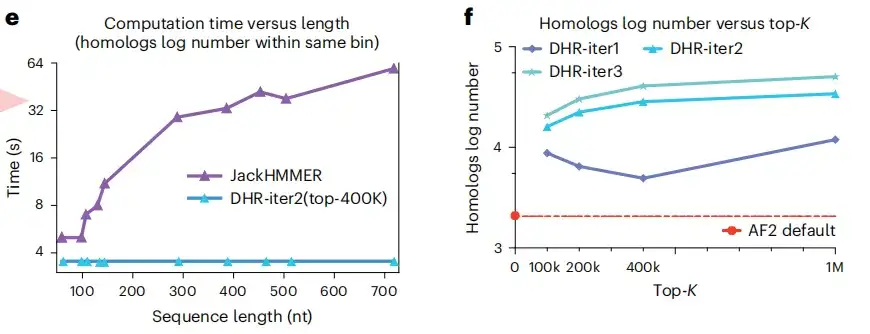
如下图 e, f 所示,DHR 的另一个优势是能在恒定的时间内,构建相同数量不同长度的同源物,而 JackHMMER 则是线性扩展的。而且与 AF2 相比,DHR 还能够为查询嵌入 (query embedding) 提供更多的同源物和 MSA 。这些结果都表明,DHR 是一种针对所有类别的 MSA 构建均有前景的方法。
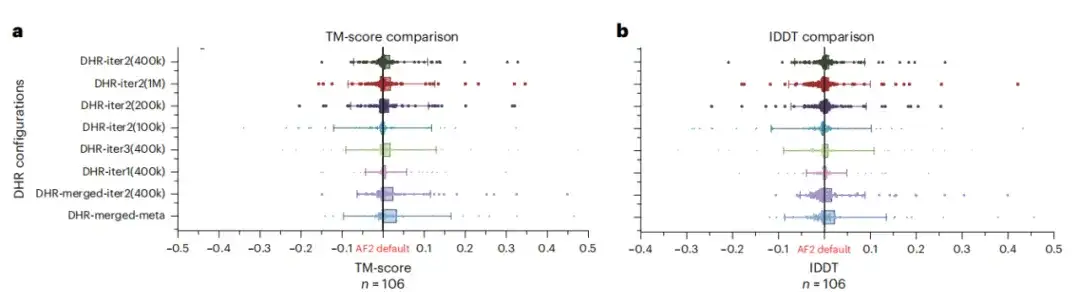
虽然 DHR 能够产生不同的 MSA,但该研究还进一步分析了它是否可以作为 AF2 基准的 MSA 补充。研究结果发现,如下图 a, b 所示,在不同的 DHR 设置下合并所有 MSA 与 AF2 的性能最佳。这意味着 DHR 可以快速且准确的为 AF2 的 MSA 管道进行补充。
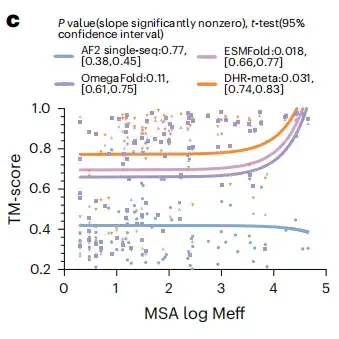
为了检验大语言模型对蛋白质结构预测的潜在益处,该研究评估了所有在 CASP14DM 靶点上用大语言模型替代 MSA 是否会产生更好的结果。如下图 c 所示,在具有大量可用 MSA 的简单情况下,语言模型可以传递与 MSA 一样多的信息。但随着序列长度的增加,DHR-meta 的性能越来越好,在几乎所有情况下都优于 ESMFold 。这意味着与基于语言模型的方法相比,基于 MSA 的模型可以大大提高预测的准确性和有效性。
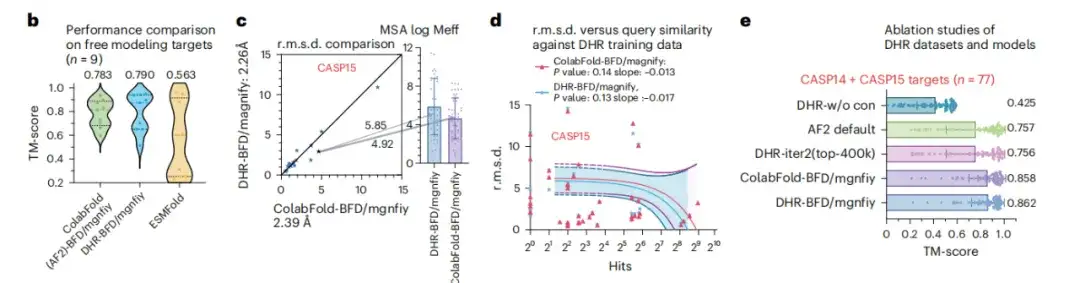
为了研究 DHR 在大数据集中的扩展性,该研究基于 BFM/MGnify 对 DHR 进行了深入分析。如下图 b 所示,在预测调频靶蛋白(FM targets)结构的复杂场景中,DHR 能够通过生成更有意义的 MSA 而脱颖而出,使用 MMseqs2 构建 MSA 的 ColabFold 方法的性能高出 0.007 个 TM-score 。
在下图 c 中,相对于 ColabFold-MMseqs2, DHR 显示了微小的性能改进。下图 d 也表明,在对 CASP14 和 SCOPe 进行相似性测试后发现,DHR 不是简单地记住查询或命中的结果,而是对所有目标进行了全面的相似性评估。这些结果都证明,DHR 能够在具有高多样性的大规模搜索数据集上构建无序蛋白的 MSA 。
蛋白质结构预测领域的青年力量
毋庸置疑,蛋白质结构预测在药物研发、抗体设计等应用中发挥着重要作用,AI 或将成为解决蛋白质结构预测精度有限这一历史性难题的破局关键。在这一关键领域,国内的科研团队已经逐渐形成百家争鸣之势,冉冉升起的年轻研究学者也成为了一股不可忽视的力量,牵头上述研究成果的李煜与孙思琦都是其中的佼佼者。

李煜于 2015 年,在中国科学技术大学贝时璋精英班获得生物科学荣誉学士学位,于 2016 年 12 月在沙特阿卜杜拉国王科技大学 (KAUST) 获得计算机科学硕士学位,并在 2020 年获得该校计算机科学博士学位。
同年 12 月,他回国加入香港中文大学计算机科学与工程系,担任助理教授,领导医疗保健人工智能 (AIH) 小组,围绕机器学习、医疗保健和生物信息学的交叉点展开深度研究,带领团队开发新的机器学习方法来解决生物学和医疗保健中的计算问题,特别是结构化学习问题。
面向其所深耕的生物学与医疗保健领域,李煜表示,「我的长期目标是改进医疗保健系统,通过提升人们的健康和福祉,直接造福社会」。值得一提的是,他还曾入选 2022 年福布斯亚洲「30 位 30 岁以下精英」榜单(医疗保健与科学领域)。

孙思琦曾在全球蛋白质结构预测比赛中获得优异成绩,现担任复旦大学智能复杂体系基础理论与关键技术实验室和上海人工智能实验室青年研究员。他致力于深度学习在生命科学和自然语言处理等交叉学科中的应用研究,并侧重于提高模型的精度和速度,解决模型在实践落地中的具体问题。
在蛋白质预测方面,他专注于通过深度学习模型来预测蛋白质的结构和序列,通过训练模型来识别序列中的模式和规律,从而预测蛋白质的序列和折叠方式,改进蛋白质从头测序和结构预测的准确性和效率,进而创造药物设计和疾病治疗的新可能。
在国内的 AI4S 领域,正在活跃越来越多的青年力量。可以预见,AI 技术将在蛋白质结构预测领域发挥更加关键的作用,但道阻且漫长。可喜的是,国内科研团队展现出了坚韧不拔的探索精神和创新能力,不仅在算法优化和模型构建上下功夫,更在数据处理、实验验证等方面进行了深入研究,以确保研究成果的科学性和实用性。这些努力正在逐步转化为实际应用,为医药研发、生物技术等领域带来了新的活力和希望。
最后推荐一个学术分享活动!
Meet AI4S 第三期直播邀请到了上海交通大学自然科学研究院 &上海国家应用数学中心博士后周子宜,点击预约观看直播!
https://hdxu.cn/6Bjomhdxu.cn/6Bjom









