Command Palette
Search for a command to run...
5 个章节、 25 条规范,全方位 Get 数据集选择与创建的「百科全书」

内容一览:如果你正在学习如何创建或选择一个合适的数据集,那么这篇文章会给你一些实用的建议,帮助你在选择和创建数据集时做出明智的决策。
关键词:机器学习 数据集
本文首发自 HyperAI 超神经微信公众平台~
作者 | xixi
审校 | 三羊
一个高质量的数据集不仅可以提高模型的准确率和运行效率,还可以节省训练时间和算力资源。
本篇文章中,我们参考 Jan Marcel Kezmann 的文章「The Dos and Don’ts of Dataset Selection for Machine Learning You Have to Be Aware of」,对创建和选择数据集的方式方法进行了详细说明,希望帮助各位数据科学工程师避免陷阱、践行模型训练的最佳实践,一起来看看都有哪些 Tips 吧~
阅读英文原文:
目录
1. 选择数据集的最佳实践
2. 注意规避的陷阱
3. 5 个 Tips
4. 创建数据集的最佳实践
5. 数据集评估
适用人群:
初学者,数据科学家,机器学习相关从业者
1. 选择数据集的最佳实践
这部分将深入探讨选择公开数据集的最佳实践,需要牢记以下 6 个关键步骤:
1.1 理解问题
理解要解决的问题非常重要,包括确定输入和输出变量、问题类型(分类、回归、聚类等)以及性能指标。
1.2 定义问题
通过指定行业或领域、需要的数据类型(文本、图像、音频等)以及数据集相关的限制条件,从而缩小数据集的范围。
1.3 关注质量
寻找可靠、准确且与问题相关的数据集。检查缺失数据、异常值和不一致性,因为这些问题可能会对模型的性能产生负面影响。
1.4 考虑数据集大小
数据集的大小会影响模型的准确性和泛化能力。较大的数据集虽然有助于提高模型的准确性和稳健性,但也意味着更多的计算资源和更长的训练时间。
1.5 检查 Bias
数据集中的 Bias 可能会导致不公平或不准确的预测。要注意与数据收集过程相关的 bias,例如抽样偏差,以及与社会问题相关的偏差,例如性别、种族或社会经济地位。
1.6 寻求多样性
选择不同来源、人群或地点多样化的数据集,有助于帮助模型从各种不同的例子中学习,避免过拟合。
2. 注意规避的陷阱
本部分适用于预定义数据集及自行创建的数据集。
2.1 数据不足
数据不足会导致模型无法捕捉数据中的潜在模式,从而使得性能不佳。如果没有足够的数据,可以考虑借助数据增强或迁移学习等技术,来增强数据集或模型能力。如果标签一致,可以将多个数据集合并成一个。
2.2 不平衡的类别
类别不平衡是指一个类 (class) 的样本数明显多于另一个类,这会导致预测偏差或其他模型错误。为了解决这个问题,建议使用过采样、欠采样或类别加权等技术。增强代表性不足的类也可以减少这个问题。
温馨提示:
不同的机器学习任务,类不平衡问题对模型的影响也不一样,例如在异常检测任务中,类严重不平衡是正常现象;而在标准图像分类问题中,这种情况比较少见。
2.3 异常值 (Outlier)
异常值是与其他数据样本明显不同的数据点,可能会对模型性能产生负面影响。如果数据集中包含太多的异常值,机器学习或深度学习模型通常会难以学习所需的分布。
可以考虑使用诸如 winsorization 之类的技术删除或校正异常值,或者使用均值/中位数插补方法,将样本中出现的所有缺失值替换为均值或中位数。
2.4 数据窥探和泄漏
数据窥探 (data snooping) 会导致过拟合和性能降低,为了避免这种情况,应该将数据集分为训练集、验证集和测试集,并只使用训练集来训练模型。
另一方面,用测试集的数据训练模型会引发数据泄漏,从而导致过于乐观的性能估计。为了避免数据泄漏,应该始终保持验证和测试集的隔离,并只使用它们来评估最终模型。
3. 5 个 Tips
- 借助迁移学习,用预训练模型解决相关问题,对于特定问题,可以使用较小的数据集进行微调。
- 合并多个数据集以增加数据集的大小和多样性,从而得到更准确和更稳健的模型。需要注意数据兼容性和质量问题。
- 用众包方式以较低成本快速收集大量标记数据。需要注意质量控制和偏差问题。
- 留意各种公司和组织的数据 API,以便以代码方式访问其数据。
- 检查提供标准化数据集及评估指标的可用 benchmark,便于比较针对同一问题不同模型的性能区别。
4. 创建数据集的最佳实践
4.1 定义问题和目标
在收集任何数据之前,明确想要预测的目标变量、想要解决的问题范围以及数据集的预期用途。
明确问题和目标有助于专注收集相关数据,避免在无关或嘈杂的数据上浪费时间和资源,同时有助于理解数据集的假设和局限性。
4.2 收集多样化和具有代表性的数据集
从不同的来源和领域收集数据,可以确保数据集能够代表现实世界的问题。这包括从不同的地点、人口统计学和时间段收集数据,保证数据集不偏向于特定的群体或领域。
此外,要确保数据不含任何混淆变量 (confounding variable),影响假定原因和假定结果的第 3 个未测量变量,会对结果产生影响。
4.3 仔细标注数据
使用明确并且能清晰反映 ground truth 的标签标注数据,通过多位标注人员 (annotator) 或众包方式,减少个人偏见对数据的影响,提高标签的质量和可靠性。建议对数据进行版本控制,以更轻松地跟踪、共享和重现训练和评估过程。
温馨提示:
如果数据集只包含 80% 的正确标签,那么即使是最好的模型,在大多数情况下其准确率也不会超过 80% 。
4.4 确保数据的质量和完整性
数据质量是指数据的准确性 (accuracy) 、完整性 (completeness) 和一致性 (consistency) 。借助数据清洗、异常值检测和缺失值插补等技术,有助于提高数据集质量。此外,还需要确保数据格式易于机器学习算法的理解和处理。
4.5 确保数据隐私和安全
为了保护隐私,需要确保数据的收集和存储都是安全的,任何敏感信息都已被匿名化或加密处理。此外,还可以考虑使用加密技术来保护数据在传输和静态存储时的安全。
温馨提示:
注意验证数据的使用规范,确保其符合法律法规。
5. 数据集评估
检查数据集是否已经充分满足以下 5 个标准:
- 数据规模:通常来说,数据越多越好。
- 数据分布:确保数据集是平衡和有代表性的。
- 数据质量:干净、一致和无误的数据至关重要
- 数据复杂度:确保数据不过于复杂。
- 数据相关性:数据应与问题相关。
以上就是数据集选择与创建指南的完整内容,选择一个合适的数据集是机器学习的关键,希望这份指南可以帮助各位选择或创建优质数据集,训练出准确、稳健的模型!
海量公开数据集在线下载
截至目前,HyperAI 超神经官网已上线 1200+ 优质公开数据集,完成近 50 万次下载,贡献 2000+TB 流量,极大降低了海内外优质公开数据集的访问门槛。
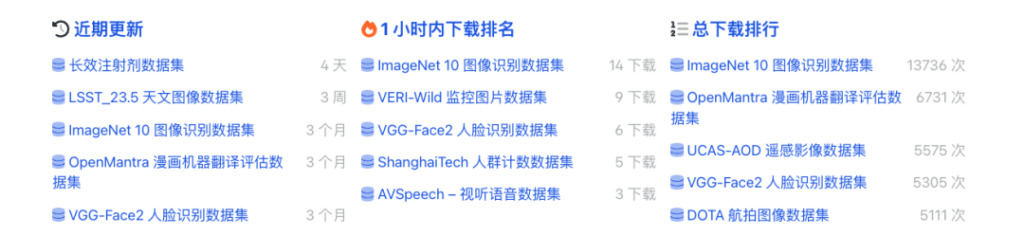
访问以下链接,即刻搜索下载你需要的数据集,开启模型训练之旅!
访问官网:https://orion.hyper.ai/datasets
本文首发自 HyperAI 超神经微信公众平台~