Command Palette
Search for a command to run...
Lyft 发布最大 L5 自动驾驶预测数据集,发起运动预测竞赛
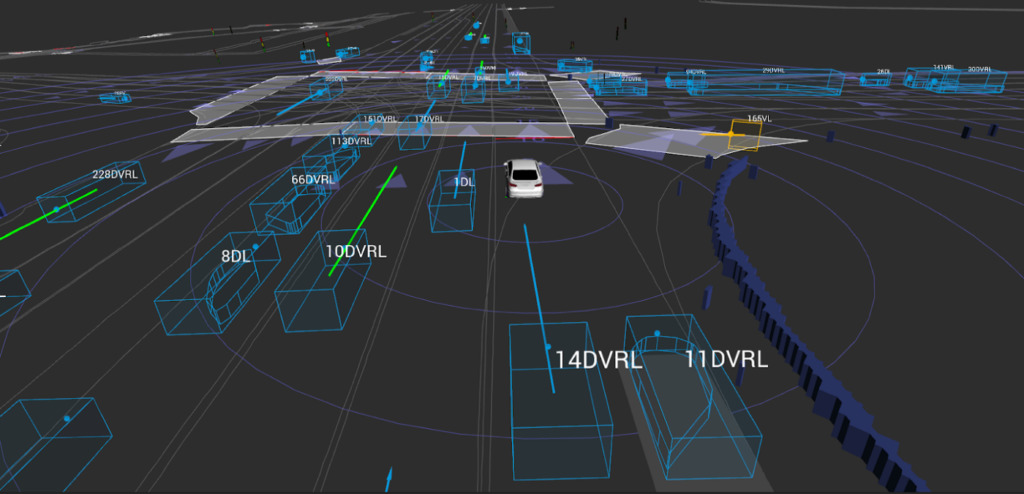
Lyft 近日发布了一个 Level 5 级别的自动驾驶预测数据集,包含了超过 1000 个小时的驾驶记录。此外,公司还发起自动驾驶运动预测挑战赛,奖金池 3 万美金。
Lyft 又发布了新的数据集。
去年 7 月,Lyft 发布了 L5 级别自动驾驶感知数据集,包含超过 5 万 5 千个由人类标记的 3D 注释帧。当时官方称作是目前同类产品中最大的公开数据集。
这才刚过去一年,Lyft 又发布了一套 L5 级别的自动驾驶预测数据集。

申请下载地址:https://www.catalyzex.com/paper/arxiv:2006.14480/dataset
17 万个场景,2500 多公里道路数据
Lyft 此次发布的数据集侧重于运动预测。官方表示,自动驾驶领域长期研究的一个问题是,创建足够健壮和可靠的模型,来预测交通运动。
这些数据是由 23 辆自动驾驶车辆组成的车队,在加州帕洛阿尔托的一条固定路线上收集的,历时 4 个月,包含遇到的汽车,行人和其他障碍物的行驶日志。
该数据集具体包括:
- 1000 个小时:超过 1000 个小时的自动驾驶汽车移动记录;
- 17 万个场景:每个场景持续约 25 秒,包括交通信号灯、航拍地图、人行道等;
- 16000 英里:来自公共道路的 16000 英里(约合 2575 公里)数据;
- 15242 个注释图:包括已标记元素的高清语义图以及该区域的高清鸟瞰图。

这些运动数据由安装在 Lyft 车顶的传感器组收集,当车辆行驶数万英里时,传感器组会捕捉激光雷达、摄像机以及雷达数据。
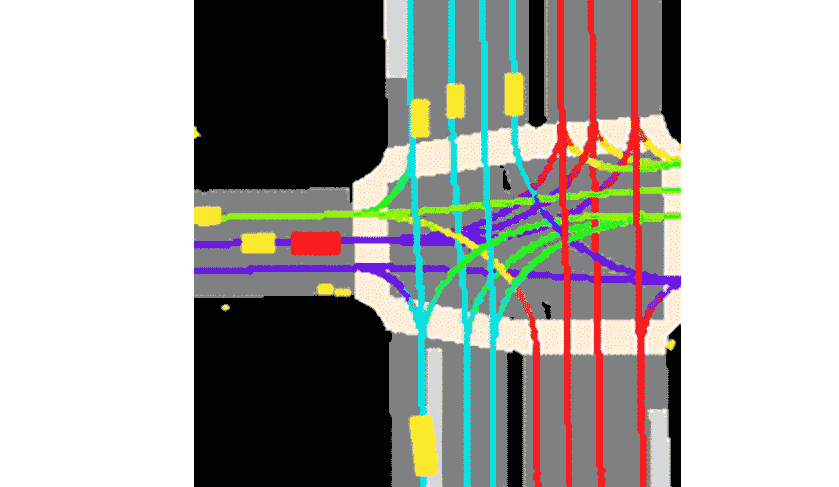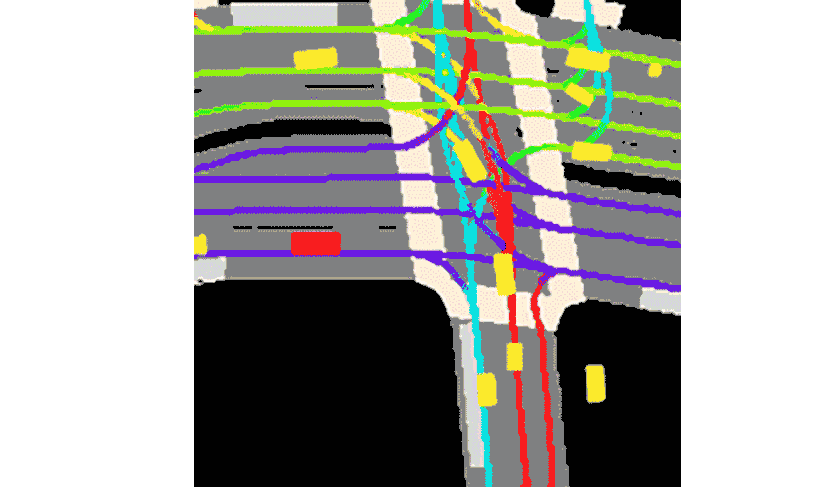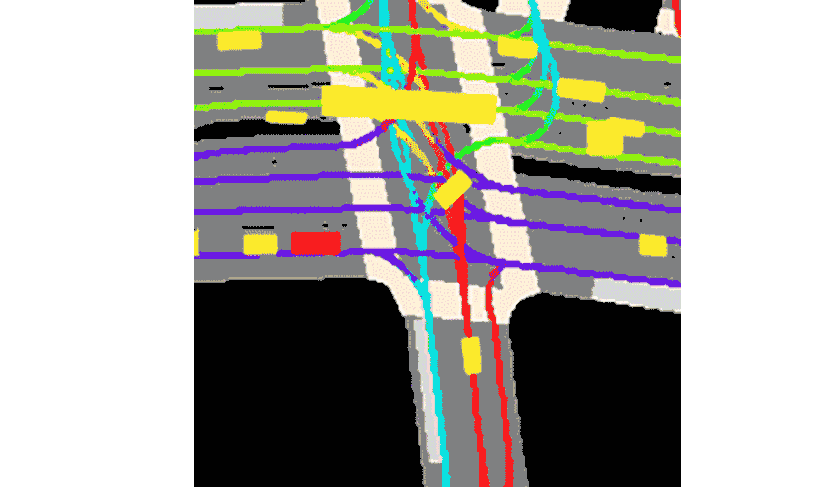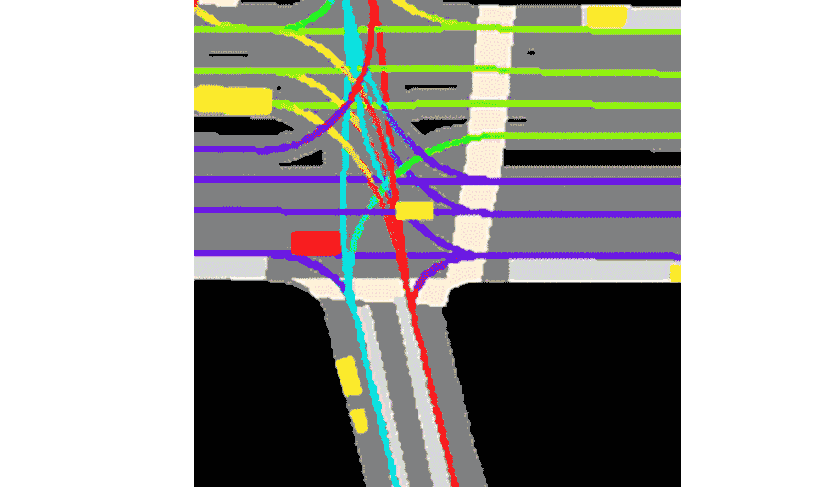
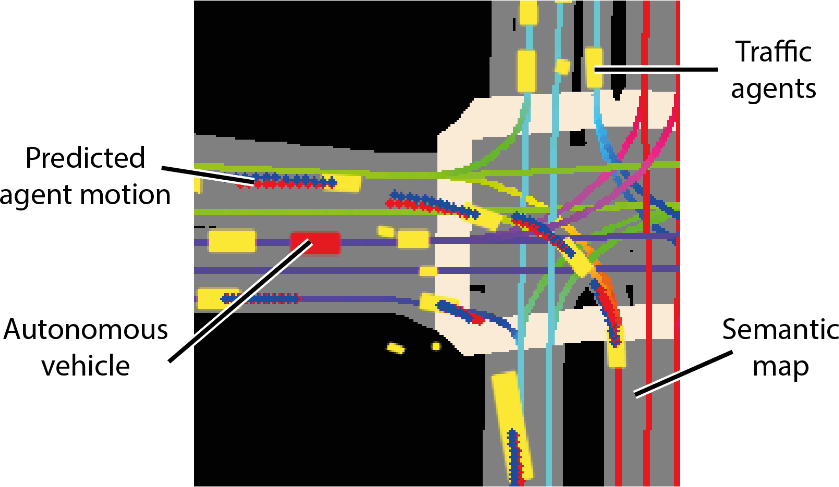
Lyft 表示,该集合与提供的工具包一起,构成了迄今为止最大、最完整、最详细的数据集,用于开发自动驾驶,机器学习任务,如运动预测、规划和仿真。
目前,该数据集只开放部分子集下载,包括:
- 样本数据集(53 MB)
- 训练数据集(分三部分,共 69.4 GB)
- 鸟瞰图(2 GB)
- 语义图(2 MB)
下载地址:
发起挑战赛,奖金池 3 万美金
与此同时,Lyft 还计划发起一项挑战,将于 8 月在谷歌 Kaggle 平台上开始,并颁发总计 30000 美元的奖金。

本次挑战赛重点:
- 竞赛要求:参赛者预测交通工具的动向;
- 准备工作:官方提醒,各位研究人员和工程师从现在起,就可以下载训练数据集和基于 Python 的软件包,对数据进行实验。因为测试和验证套件将作为竞赛的一部分来发布;
- 最终目的:通过数据集与竞赛,增强研究界能力,加速创新。
Lyft 工程高级总监 Sacha Arnoud 和音视频研究总监 Peter Ondruska 在博客中写道,「数据是尝试最新的机器学习技术的动力,对大规模、高质量的自动驾驶数据数据的获取虽然是有限的,但这并不应妨碍我们在这一研究上的实验。」
「我们相信无人驾驶将成为交通系统中,更便捷、更安全和可持续发展的部分,」Arnoud 和 Ondruska 说道,「通过与研究社区共享数据,我们希望明确自动驾驶中,重要的和未解决的挑战。」
点击阅读原文,可获取更多优质数据集哦!
博客地址:
论文地址:
https://arxiv.org/pdf/2006.14480.pdf
GitHub 地址:
https://github.com/lyft/l5kit/
—— 完 ——








