Command Palette
Search for a command to run...
ICLR 2026 | NVIDIA/جامعة أكسفورد وآخرون يقترحون طريقة لتوليد روابط البروتين على المستوى الذري مع أداء متطور (SOTA).

في مجال البيولوجيا الحاسوبية،يُعد تصميم البروتينات التي يمكنها الارتباط بدقة بأهداف محددة أحد أكثر المشاكل أهمية وتحديًا.لا يرتبط الأمر بشكل مباشر فقط بالمجالات الرئيسية مثل تطوير الأدوية والعلاج البيولوجي وهندسة الإنزيمات، ولكنه يحدد أيضًا الحد الأعلى للكفاءة البشرية في التدخل في الأمراض المعقدة والتصنيع الحيوي.
من منظور جزيئي، فإن ارتباط البروتين بالهدف هو في الأساس مسألة هيكلية ثلاثية الأبعاد:يشكل تركيب الأحماض الأمينية والتكوين المكاني والتفاعلات بين الجزيئات في الواجهة مجتمعة تقارب وخصوصية الارتباط.لذلك، تعود جميع طرق تصميم المواد الرابطة تقريبًا في النهاية إلى المتغير الأساسي المتمثل في "البنية"، باستخدام تحليل البنية أو التنبؤ بها لتوجيه البناء الجزيئي.
في السنوات الأخيرة، أدى إدخال تقنيات التعلم الآلي إلى إعادة تشكيل هذا النموذج. فمع تحقيق طفرات في نماذج التنبؤ بالبنية وتوليدها، يتجه البحث تدريجياً نحو التخلي عن اعتماده الكبير على البنى التجريبية، متحولاً من "تحليل البنى" إلى "توليدها"، مما يتيح تصميم المواد الرابطة من الصفر، ويقلل بشكل كبير من تكاليف البحث والتطوير والوقت اللازم لذلك.
ومع ذلك، من حيث المنهجية، لا يزال تصميم المجلدات الحالي المدعوم بالذكاء الاصطناعي يُظهر تباينًا واضحًا:أحد أنواعها هو الأساليب التوليدية، والتي يمثلها RFDiffusion.يعتمد على التدريب واسع النطاق لتوليد الهياكل المرشحة بشكل مباشر، ولكنه يفتقر إلى القدرة على التكيف بمرونة أثناء مرحلة الاستدلال؛وهناك نوع آخر هو الأسلوب الوهمي، الذي يمثله BindCraft.يُتيح تحسين التدرج من خلال تقييم مُتنبئات البنية مرونةً، ولكنه يفتقر إلى المعلومات التوليدية المسبقة، مما يُصعّب استكشاف فضاءات هيكلية جديدة كليًا. ويتناقض هذا "الفصل بين التوليد والتحسين" مع النموذج الموحد "للنماذج المُدرّبة مُسبقًا + امتدادات حسابية وقت الاستدلال" المُعتمد بالفعل في مجالي معالجة اللغة الطبيعية ومعالجة الصور.
وفي هذا السياقاقترح فريق بحث مشترك من NVIDIA وجامعة أكسفورد ومعهد كيبيك للذكاء الاصطناعي ومؤسسات أخرى إطار عمل Proteina-Complexa (يشار إليه فيما يلي باسم Complexa).يهدف هذا النهج إلى سد الفجوة بين الأساليب التوليدية والوهمية، حيث يوحد النموذج التوليدي الأساسي وآليات تحسين وقت الاستدلال ضمن نظام واحد. وهو يعتمد على التدريب المسبق لنموذج تيديمر.تتيح Complexa تصميم عوامل الربط من الصفر باستخدام أحدث التقنيات دون الحاجة إلى خطوات إعادة تصميم التسلسل الإضافية.من خلال تكييف تقنية قياس وقت الاختبار من نموذج الانتشار إلى هذا الإطار، يتم توحيد التوليد والتحسين بشكل مباشر، وبالتالي التفوق على الطرق التقليدية القائمة على الوهم من حيث الأداء.
تم قبول نتائج البحث ذات الصلة، بعنوان "توسيع نطاق تصميم رابط البروتين الذري باستخدام التدريب المسبق التوليدي والحساب في وقت الاختبار"، في مؤتمر ICLR 2026.
أبرز الأبحاث:
* تقترح هذه الدراسة Complexa، التي توسع La-Proteina لتصميم الرابط، وتستخدم Teddymer، وتحقق تحسين وقت الاستدلال الفعال الذي يتم تسريعه بواسطة المعلومات الأولية التوليدية.
* تم تحقيق معدلات نجاح محاكاة حاسوبية متطورة في معايير تصميم البروتينات والجزيئات الصغيرة المستهدفة والإنزيمات دون الحاجة إلى إعادة تصميم التسلسل.
عنوان الورقة:
https://openreview.net/forum?id=qmCpJtFZra
تابع حسابنا الرسمي على WeChat وأجب بكلمة "Complexa" في الخلفية للحصول على ملف PDF كامل.
مجموعات البيانات: من "إثراء الوحدة المفردة" إلى "إعادة البناء المعقدة"
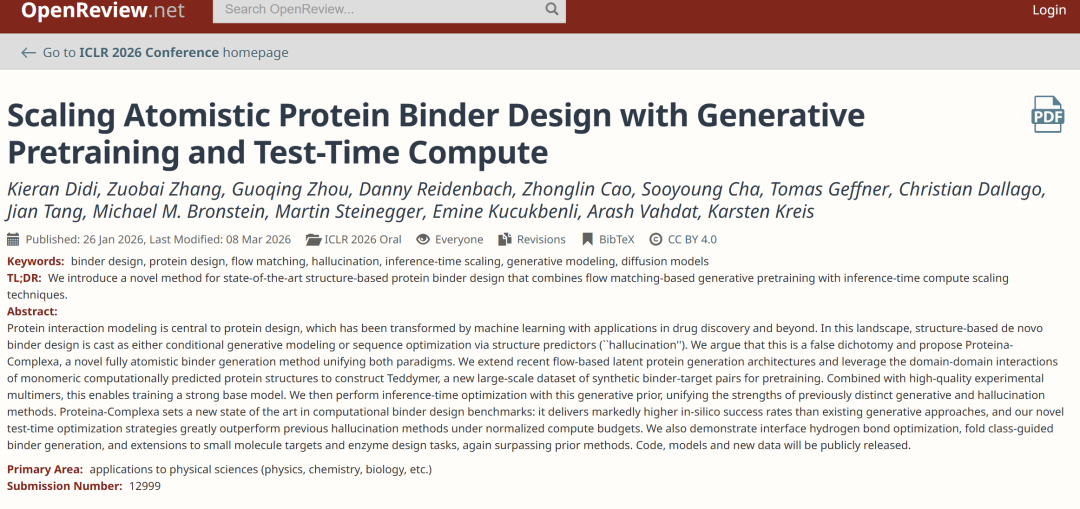
تكمن إحدى القيود الأساسية لنماذج توليد الروابط في البيانات. فمن الناحية المثالية، يتطلب النموذج كمية كبيرة من بيانات "معقدات الربط بين العامل والهدف" للتدريب، ولكن في الواقع، يأتي هذا النوع من البيانات بشكل رئيسي من قواعد بيانات البروتينات التي تم تحليلها تجريبياً (PDBs)، وهي محدودة الحجم، كما أن العينات عالية الجودة فيها نادرة للغاية؛ في حين أن قاعدة بيانات AlphaFold (AFDB) الأكبر حجماً توفر كمية هائلة من هياكل البروتينات، إلا أن جميعها تقريباً عبارة عن هياكل أحادية، تفتقر إلى معلومات المعقدات.إن هذه الفجوة الهيكلية المتمثلة في "المكونات الفردية الوفيرة والمكونات المعقدة النادرة" تحد بشكل مباشر من قدرة النموذج على التدريب على نطاق واسع.
يكمن الإنجاز الرئيسي لهذه الدراسة في فهم متجدد للبنية الداخلية لـ AFDB. معظم البروتينات في AFDB هي بروتينات متعددة المجالات، وتوفر أداة تجزئة المجالات TED لها شروحًا دقيقة. وكشف تحليل إضافي أن التفاعلات بين المجالات المختلفة داخل البروتين نفسه تُظهر خصائص متشابهة إحصائيًا مع تلك الموجودة في المركبات متعددة السلاسل. هذه الملاحظة تقود إلى تحول هام:لا تعتبر هياكل المونومر "بيانات عديمة الفائدة" في حد ذاتها، ولكن يمكن إعادة تفسيرها كمصدر محتمل للبيانات للهياكل المعقدة.
وبناءً على هذه الرؤية، تقترح الدراسة طريقة "لإنشاء متعددات الوحدات الاصطناعية".من خلال تقسيم البروتينات متعددة المجالات إلى مجالات مستقلة ومعاملتها كسلاسل مختلفة، يمكن بناء بنية تشبه المعقد داخل المونومر.تبدأ العملية المحددة بقاعدة بيانات AFDB50، حيث يتم فحص البروتينات باستخدام شروح TED، ثم تقسيمها إلى "متعددات زائفة"، واستخراج الثنائيات وتصفيتها بناءً على التقارب المكاني، مع الاحتفاظ بالعينات ذات الشروح الكاملة. وأخيرًا، بعد التجميع لإزالة التكرار، يتم الحصول على ما يقارب 3.5 مليون مجموعة من الثنائيات. تُسمى هذه المجموعة من البيانات Teddymer، وجوهرها ليس مجرد توسيع نطاق البيانات، بل تحويل "ميزة المونومر" إلى "وفرة معقدة" من خلال إعادة التنظيم الهيكلي.
أثناء عملية التدريب، كما هو موضح في الشكل أدناه، لم تعتمد الدراسة على مصدر بيانات واحد، بل دمجت بيانات المونومر AFDB، وبيانات بناء Teddymer، وبيانات PDB التجريبية المعقدة، وبيانات PLINDER للبروتين-الرابط، مما مكن النموذج من إنشاء تمثيل موحد بين بنية المونومر، وبنية المركب، وتفاعلات الجزيئات الصغيرة، وبالتالي أخذ كل من القدرات التوليدية والتعميمية في الاعتبار.
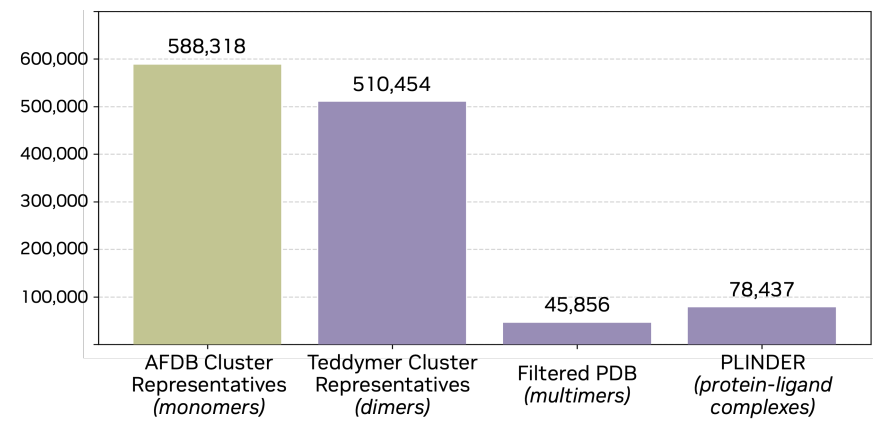
كومبلكسا: إطار ذري كامل لتوليد عوامل ربط البروتين
من حيث تصميم النموذج، فإن التغيير الأساسي في Complexa ليس مجرد "قدرة توليد أقوى"، بل هو تحول في الهدف التوليدي من "هياكل البروتين الكاملة" إلى "عوامل الربط عند واجهات محددة". وباعتبارها مبنية على La-Proteína، فإن ميزتها تكمن في قدرتها على التوليد على مستوى الذرة بأكملها.وفي الوقت نفسه، واستنادًا إلى بنية Transformer الفعالة، فإنه يتجنب الوحدات ذات التكاليف الحسابية العالية في النماذج الهيكلية التقليدية، مما يمنحه قابلية جيدة للتوسع في سيناريوهات أخذ العينات واسعة النطاق.
وانطلاقاً من ذلك، تُقدّم الدراسة آلية توليد تعتمد على النقاط المستهدفة ونقاط التفاعل الرئيسية. تمنع هذه الآلية النموذج من توليد مُركّبات كاملة، بل تُولّد فقط الجزء الرابط، وتعتمد بشكل صريح على معلومات الهدف أثناء عملية التوليد. تحديداً،نموذج مطابقة التدفق مسؤول عن توليد الهياكل في ظل قيود مشروطة، بينما يتم استخدام المشفر التلقائي فقط لترميز وفك ترميز روابط المونومر، مما يقلل من تعقيد النمذجة مع الحفاظ على القدرة التعبيرية.
لتمكين النموذج من فهم معلومات الهدف بفعالية، تم تطبيق تصميم منهجي لتمثيل المدخلات. تم ترميز أهداف البروتين باستخدام طريقة Atom37، حيث تم إدخال إحداثيات ثلاثية الأبعاد على مستوى البقايا، وأنواع الأحماض الأمينية، ومعلومات النقاط الساخنة على السطح البيني بشكل موحد إلى النموذج. تشير النقاط الساخنة إلى مناطق الارتباط المحتملة. أثناء التدريب، تم استخراج هذه النقاط الساخنة من الأسطح البينية الحقيقية، بينما أثناء الاستدلال، تم استخدامها كمعلومات مسبقة أو الحصول عليها من خلال المعالجة المسبقة. بالنسبة لأهداف الجزيئات الصغيرة، قام النموذج بترميز النوع والشحنة والإحداثيات المكانية على المستوى الذري، وتم إدخال هذه المعلومات مع تمثيل عامل الارتباط إلى Transformer للنمذجة المشتركة.
فيما يتعلق بأهداف التدريب،يتمثل أحد التحسينات الرئيسية في إدخال ضوضاء ترجمة عالمية عشوائية في إحداثيات الرابط، مما يجبر النموذج على تعلم قدرة التوطين المكاني للجزيئات.لا يُعدّ هذا الأمر مهمًا في توليد المونومر، ولكنه قدرة أساسية تُحدّد جودة التوليد للمهام التي تتطلب وضعًا دقيقًا للمادة الرابطة على السطح المستهدف. تعتمد عملية التدريب بأكملها استراتيجية مرحلية، حيث تتقدم خطوة بخطوة من نمذجة المونومر إلى توليد البنية العامة، ثم إلى التدريب الخاص بالمادة الرابطة. في الوقت نفسه، يتم التحكم في التجاوز من خلال LoRA، ويُعاد استخدام المُشفّر التلقائي على مستوى المونومر طوال العملية للحفاظ على بساطة البنية.
في مرحلة الاستدلال،كما يقدم Complexa آلية "توسيع الحساب في وقت الاختبار"، والتي تجمع بين عملية التوليد وتحسين البحث.من خلال زيادة عدد العينات، أو استخدام البحث عن الحزم، أو البحث الشجري باستخدام طريقة مونت كارلو، يستطيع النموذج تحسين جودة توليده باستمرار ضمن ميزانية حسابية أكبر. يتيح هذا التصميم توسيع قدرات النموذج ديناميكيًا أثناء الاستدلال، بدلًا من اقتصارها كليًا على مرحلة التدريب.
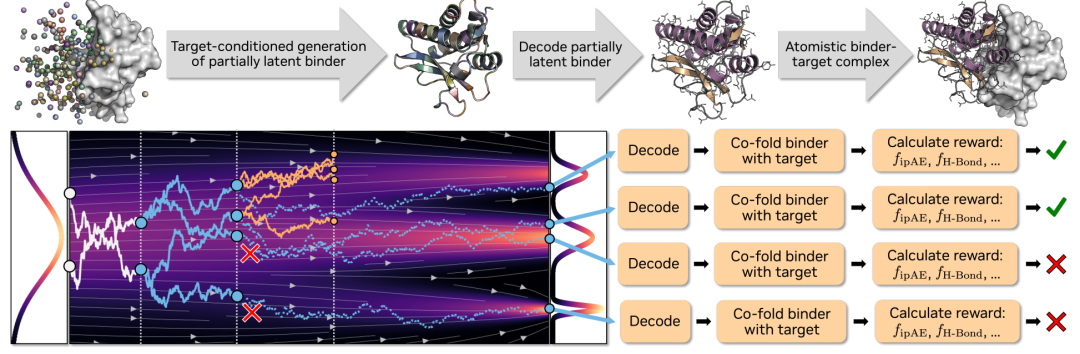
معدل نجاح أعلى، وسرعة أكبر، وقابلية توسع أقوى
لتقييم قدرات النموذج، صممت هذه الدراسة سلسلة من التجارب تتراوح بين البسيطة والمعقدة. والسؤال الأساسي هو: هل يتفوق نموذج Complexa ليس فقط في الأداء الأساسي، بل يستمر في تحسين أدائه مع زيادة موارد الحوسبة؟
فيما يتعلق بقدرات التوليد الأساسية،سواء كان الهدف هو استهداف البروتينات أو الجزيئات الصغيرة، فإن Complexa تتفوق بشكل كبير على الطرق الحالية، حيث تتميز بمعدلات نجاح أعلى وسرعات أخذ عينات أسرع.في الوقت نفسه، تتحسن حداثة الهياكل المُولَّدة بشكل ملحوظ. والأهم من ذلك، أن النموذج قادر على إخراج تسلسلات عالية الجودة مباشرةً دون الاعتماد على أدوات مثل ProteinMPNN للتصميم الثانوي، مما يُبسط العملية برمتها.
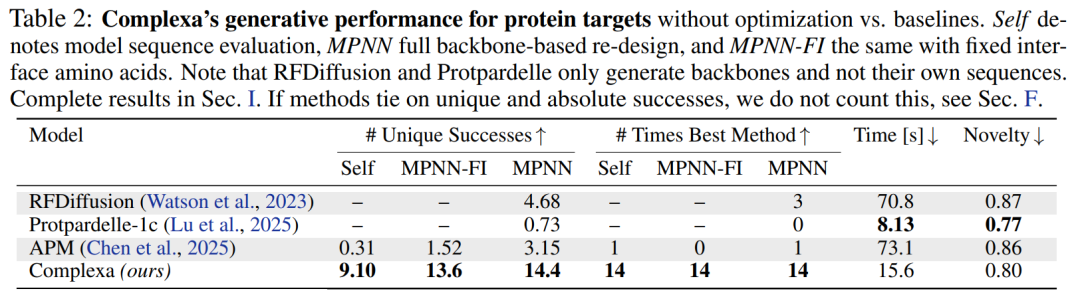
من حيث إمكانية التحكم الهيكلي،تقدم الدراسة تصنيفات مشروطة، مما يُمكّن النموذج من التحكم بشكل صريح في نوع البنية المُولّدة.على سبيل المثال، يمكن للاختيار بين الحلزونات ألفا والطيات بيتا أن يخفف بشكل فعال من مشكلة البنية الواحدة للنماذج التوليدية السابقة ويحسن التنوع الهيكلي بشكل كبير.
في تجارب التوسيع الحسابي خلال مرحلة الاستدلال، تظهر النتائج أنه في المهام البسيطة، يكفي ببساطة زيادة عدد العينات للتفوق على جميع الطرق الأساسية، بينما في المهام المعقدة، فإن إدخال استراتيجيات بحث أكثر تقدماً (مثل البحث عن الحزم والبحث عن شجرة مونت كارلو) يزيد من الميزة.يشير هذا إلى أن أداء النموذج يمكن أن يستمر في التحسن مع زيادة الميزانية الحسابية.كما هو موضح في الشكل أدناه
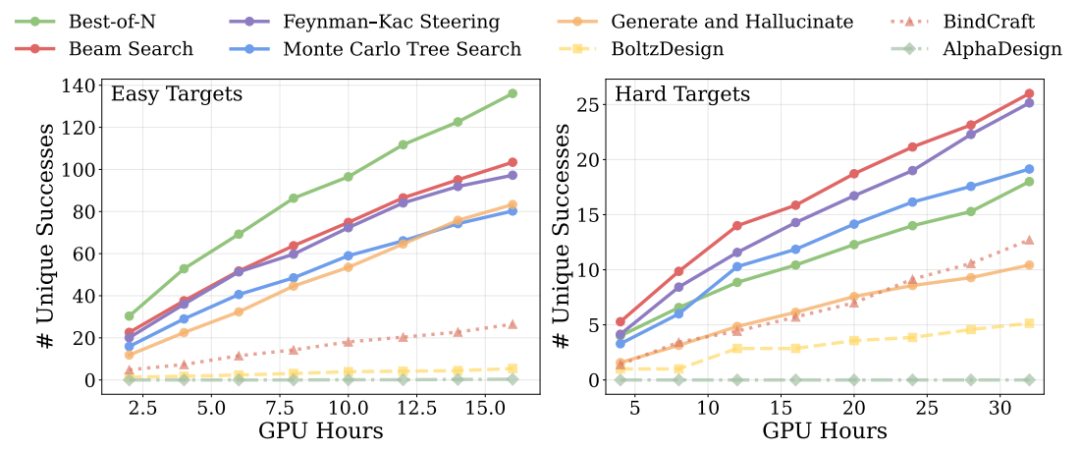
فيما يتعلق بالجدوى الفيزيائية، هناك حاجة إلى مزيد من البحث لتحسين الروابط الهيدروجينية البينية ومؤشرات الطاقة ذات الصلة.وقد تبين أن النموذج لا يقوم فقط بتوليد مواد رابطة سليمة من الناحية الهيكلية، بل يقوم أيضًا بتحسينها على مستوى التفاعل الدقيق.وهذا يحسن استقرار عملية الربط.
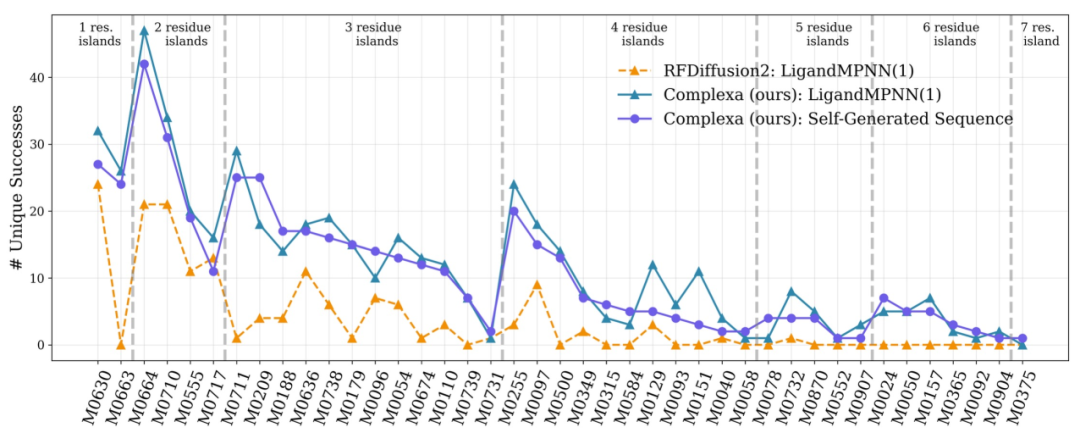
في مهام الأهداف متعددة السلاسل الأكثر صعوبة، لا تستطيع الطرق الحالية الحصول على حلول فعالة في ظل ميزانيات حسابية محدودة.نجحت شركة Complexa في توليد مرشحين ذوي جودة عالية بعد توسيع موارد الحوسبة، مما يدل على قابليتها للتوسع في المشكلات المعقدة.وأخيرًا، تُظهر الصورة أدناه نتائج الاختبارات على مهام مختلفة، مثل تصميم الإنزيمات. يتميز هذا الإطار بقدرة تعميم جيدة، ويمكن توسيعه من تصميم الروابط إلى نطاق أوسع من مشاكل هندسة البروتينات.
تحول نموذجي في تصميم البروتينات بالذكاء الاصطناعي
في السنوات الأخيرة، شهد تصميم عوامل ربط البروتينات باستخدام الذكاء الاصطناعي تحولاً سريعاً من النظرية إلى التطبيق، ولا يزال ديفيد بيكر، الحائز على جائزة نوبل، وفريقه من الرواد البارزين في هذا المجال. وفي عام 2025، نشر فريقهم عدة دراسات في مجلة ساينس.لقد تحقق النظام من جدوى تصميم روابط pMHC عالية التخصص بناءً على تقنية RFDiffusion.استهدفت الأعمال ذات الصلة 11 فئة من الأمراض، ونجحت في توليد بروتينات ربط يمكنها دفع الخلايا التائية للتعرف على الأورام، وتحققت من دقة التصميم على المستوى الذري باستخدام المجهر الإلكتروني المبرد، مما يمثل بداية إمكانية التحقق من تصميم الذكاء الاصطناعي.
في غضون ذلك، استكشف فريق معهد ماساتشوستس للتكنولوجيا نهجًا أكثر تكاملاً في نموذج BoltzGen، حيث قام بتوحيد التنبؤ بالبنية وتوليد التجميع في نموذج واحد لجميع الذرات، واستخدم تمثيلات هندسية مستمرة بدلاً من النمذجة المنفصلة التقليدية.في التجارب التي استهدفت 26 هدفًا، حقق المركب 66% تقاربًا نانومولاريًا كمركب رابط.كما أنها تحافظ على معدل نجاح عالٍ في استهداف الأهداف خارج نطاق التوزيع، مما يدل على قدرة معينة على التعميم.
يركز القطاع بشكل أكبر على التطبيق الهندسي لهذه القدرات. في أوائل عام 2026، دخلت شركتا باير وكرايدل في تعاون لمدة ثلاث سنوات لدمج منصة هندسة البروتينات المدعومة بالذكاء الاصطناعي في عملية تطوير الأجسام المضادة. وقد طُبقت هذه المنصة في أكثر من 50 مشروعًا، مما أدى إلى تقصير دورات التطوير بشكل ملحوظ ودعم عملية تكرارية مغلقة الحلقة تقوم على "التصميم والاختبار والتعلم". وهذا يدل على أن الذكاء الاصطناعي ينتقل من كونه أداة مساعدة إلى قدرة أساسية ضمن عملية البحث والتطوير.
بشكل عام، يتحول التنافس في تصميم البروتينات من التركيز على أداء النموذج الواحد إلى كفاءة النظام وقابليته للتوسع. وتواصل الأوساط الأكاديمية توسيع آفاق قدرات النماذج، بينما يدفعها القطاع الصناعي نحو عملية بحث وتطوير مستقرة وقابلة لإعادة الاستخدام. وهكذا، يدخل تصميم البروتينات بالذكاء الاصطناعي مرحلة أكثر عملية: لم يعد السؤال "هل يمكن تصميمه؟" بل "هل يمكن تصميمه باستمرار وبكفاءة؟".
روابط مرجعية:
1.https://news.bioon.com/article/00bf92186439.html
2.https://mp.weixin.qq.com/s/1zKXUQtXgCJ7GA1_OUEShg
3.https://www.bayer.com/en/us/news-stories/ai-enabled-antibody-discovery-and-optimization








