Command Palette
Search for a command to run...
تم اختيار مشروع Zhiyuan وجامعة بكين وجامعة بكين للبريد والاتصالات ضمن مؤتمر NeurIPS 2025، حيث اقترح إطار عمل لتوليد الفيديو متعدد التدفقات يحقق تزامنًا دقيقًا بين الصوت والصورة بناءً على فصل الصوت.

بالمقارنة مع النصوص، يتميز الصوت بطبيعته ببنية زمنية متصلة ومعلومات ديناميكية غنية، مما يتيح تحكمًا زمنيًا أكثر دقة في توليد الفيديو. ولذلك، مع تطور نماذج توليد الفيديو، أصبح توليد الفيديو المعتمد على الصوت اتجاهًا بحثيًا هامًا في مجال التوليد متعدد الوسائط. حاليًا، تغطي الأبحاث ذات الصلة سيناريوهات متعددة مثل تحريك المتحدث، والفيديو المعتمد على الموسيقى، وتوليد التزامن السمعي البصري؛ ومع ذلك، لا يزال تحقيق محاذاة سمعية بصرية مستقرة ودقيقة في محتوى الفيديو المعقد يمثل تحديًا كبيرًا.
يكمن القيد الرئيسي للأساليب الحالية في طريقة نمذجة الإشارات الصوتية. إذ تُدخل معظم النماذج الصوت المدخل كشرط شامل في عملية التوليد، دون تمييز الأدوار الوظيفية لمكونات الصوت المختلفة، كالكلام والمؤثرات الصوتية والموسيقى، على المستوى المرئي. ويُسهم هذا النهج في تقليل تعقيد النمذجة إلى حد ما.ومع ذلك، فإن هذا يطمس أيضًا التوافق بين الصوت والصورة، مما يجعل من الصعب تلبية متطلبات مزامنة الشفاه، ومحاذاة توقيت الأحداث، والتحكم العام في الجو البصري في آن واحد.
ولمعالجة هذه المشكلة،اقترحت أكاديمية بكين للذكاء الاصطناعي وجامعة بكين وجامعة بكين للبريد والاتصالات بشكل مشترك إطار عمل لتوليد الفيديو المتزامن السمعي البصري بناءً على فصل الصوت.يُقسّم الصوت المُدخل إلى ثلاثة مسارات صوتية: الكلام، والمؤثرات الصوتية، والموسيقى، ويُستخدم كل منها لتوجيه مستويات مختلفة من توليد الصور. يُحقق هذا الإطار، من خلال شبكة تحكم زمني متعددة المسارات ومجموعة بيانات واستراتيجية تدريب مُناسبة، توافقًا صوتيًا بصريًا أوضح على المستويين الزمني والعام. تُظهر البيانات التجريبية أن هذه الطريقة تُحقق تحسينات مُستقرة في جودة الفيديو، وتوافق الصوت والصورة، ومزامنة حركة الشفاه، مما يُؤكد فعالية فصل الصوت والتحكم متعدد المسارات في مهام توليد الفيديو المُعقدة.
تم اختيار نتائج البحث ذات الصلة، بعنوان "توليد الفيديو المتزامن مع الصوت مع التحكم الزمني متعدد التدفقات"، لمؤتمر NeurIPS 2025.
عنوان الورقة:
https://arxiv.org/abs/2506.08003
أبرز الأبحاث:
* نقوم بإنشاء مجموعة بيانات DEMIX، والتي تتكون من خمس مجموعات فرعية متداخلة لتوليد الفيديو المتزامن مع الصوت، ونقترح استراتيجية تدريب متعددة المراحل لتعلم العلاقات السمعية البصرية.
يقترح هذا البحث إطار عمل لقناة MTV يقسم الصوت إلى ثلاثة مسارات: الكلام، والمؤثرات الصوتية، والموسيقى. تتحكم هذه المسارات في عناصر بصرية مختلفة مثل حركة الشفاه، وتوقيت الأحداث، والجو البصري العام، مما يتيح تحكمًا دلاليًا أكثر دقة.
* تصميم شبكة تحكم زمني متعددة التدفقات (MST-ControlNet) للتعامل في وقت واحد مع التزامن الدقيق للفترات الزمنية المحلية وتعديل النمط العالمي ضمن نفس إطار الجيل، ودعم التحكم التفاضلي لمكونات الصوت المختلفة على نطاق زمني.
قدرة توليد متعددة الوظائف
تمتلك قناة MTV قدرات إنتاج متعددة الوظائف، مثل السرد القصصي الذي يركز على الشخصيات، والتفاعلات بين الشخصيات المتعددة، والأحداث التي يتم تشغيلها بالصوت، والأجواء التي تخلقها الموسيقى، وحركة الكاميرا.
تقدم مجموعة بيانات DEMIX تعليقات توضيحية للمسارات المفصولة لتمكين التدريب المرحلي.
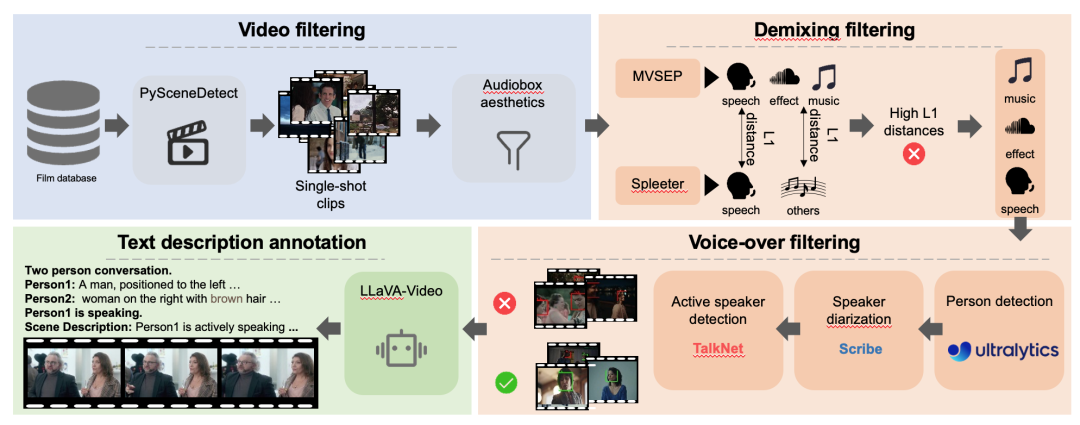
تحصل هذه الورقة البحثية أولاً على مجموعة بيانات DEMIX من خلال عملية ترشيح مفصلة. ثم يتم تنظيم بيانات DEMIX المُرشحة في خمس مجموعات فرعية متداخلة:ملامح الوجه الأساسية، وتأثيرات الشخص الواحد، وتأثيرات الأشخاص المتعددين، والمؤثرات الصوتية للأحداث، والجو المحيط. بناءً على خمس مجموعات فرعية متداخلة.تقدم هذه الورقة البحثية استراتيجية تدريب متعددة المراحل.يتم توسيع نطاق النموذج تدريجياً. أولاً، يتم تدريب النموذج على مجموعة فرعية أساسية من تعابير الوجه لتعلم حركات الشفاه؛ ثم يتعلم وضعية الجسم البشري، ومظهر المشهد، وحركة الكاميرا على مجموعة فرعية لشخص واحد؛ بعد ذلك، يتم تدريبه على مجموعة فرعية لعدة أشخاص للتعامل مع المشاهد المعقدة التي تضم متحدثين متعددين؛ ثم يتحول تركيز التدريب إلى توقيت الأحداث، ويتم توسيع فهم الموضوع من البشر إلى الأشياء باستخدام مجموعة فرعية من المؤثرات الصوتية للأحداث؛ وأخيراً، يتم تدريب النموذج على مجموعة فرعية من الأجواء المحيطة لتحسين تمثيله للمشاعر البصرية.
بفضل آلية التحكم في التوقيت متعددة التدفقات، يتم تحقيق رسم خرائط سمعية بصرية دقيقة ومحاذاة زمنية دقيقة.
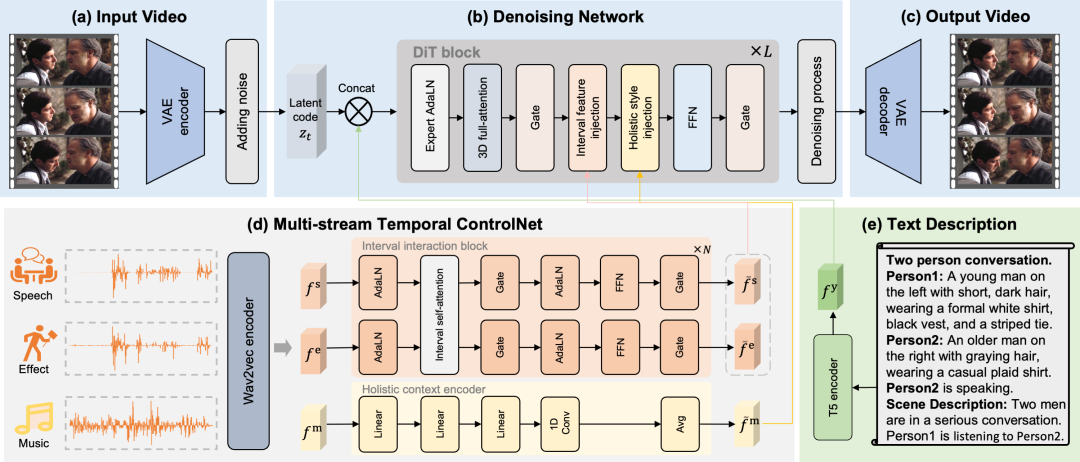
تقسم هذه المقالة الصوت بشكل صريح إلى ثلاثة مسارات تحكم متميزة: الكلام، والمؤثرات الصوتية، والموسيقى.تُمكّن هذه المسارات المتميزة إطار عمل MTV من التحكم بدقة في حركات الشفاه، وتوقيت الأحداث، والتعبير البصري، ما يحل مشكلة التداخل في التعيين. ولجعل إطار عمل MTV متوافقًا مع مهام متنوعة، تُقدّم هذه الورقة نموذجًا لإنشاء وصف نصي. يبدأ هذا النموذج بجملة تُشير إلى عدد المشاركين، مثل "محادثة بين شخصين". ثم يسرد كل شخص، بدءًا بمعرّف فريد (الشخص 1، الشخص 2)، ويصف مظهره بإيجاز. بعد سرد المشاركين، يُحدّد النموذج بوضوح الشخص الذي يتحدث حاليًا. أخيرًا، تُقدّم جملة وصفًا عامًا للمشهد. ولتحقيق تزامن زمني دقيق، تقترح هذه الورقة شبكة تحكم زمني متعددة المسارات تتحكم في حركات الشفاه، وتوقيت الأحداث، والتعبير البصري من خلال مسارات منفصلة بوضوح للكلام، والمؤثرات، والموسيقى.
حقن ميزة الفاصل الزمني
فيما يتعلق بميزات الصوت والمؤثرات الصوتيةتصمم هذه الورقة تدفق الفترات للتحكم بدقة في حركات الشفاه وتوقيت الأحداث.تُستخلص خصائص كل مسار صوتي بواسطة وحدة التفاعل الفاصل، ويُحاكى التفاعل بين الكلام والمؤثرات الصوتية بواسطة آلية الانتباه الذاتي. وأخيرًا، تُضاف خصائص الكلام والمؤثرات الصوتية التفاعلية إلى كل فاصل زمني بواسطة آلية الانتباه المتبادل، وهو ما يُعرف بآلية إضافة خصائص الفاصل الزمني.
حقن الميزات العالمية
فيما يتعلق بالخصائص الموسيقية،تصمم هذه الورقة تدفقًا عامًا للتحكم في العاطفة البصرية لجزء الفيديو بأكمله.بما أن السمات الموسيقية تعكس الجمالية العامة، يتم أولاً استخلاص المشاعر البصرية العامة من الموسيقى عبر مُشفِّر سياق شامل، ثم يُطبَّق التجميع المتوسط للحصول على السمات العامة للمقطع بأكمله. وأخيرًا، تُستخدم هذه السمات العامة كتضمينات، ويتم تعديل الشفرة الكامنة للفيديو عبر AdaLN، وهو ما يُعرف بآلية حقن السمات العامة.
قم بإنشاء فيديو متزامن مع الصوت بجودة سينمائية بدقة عالية.
مؤشرات التقييم الشامل
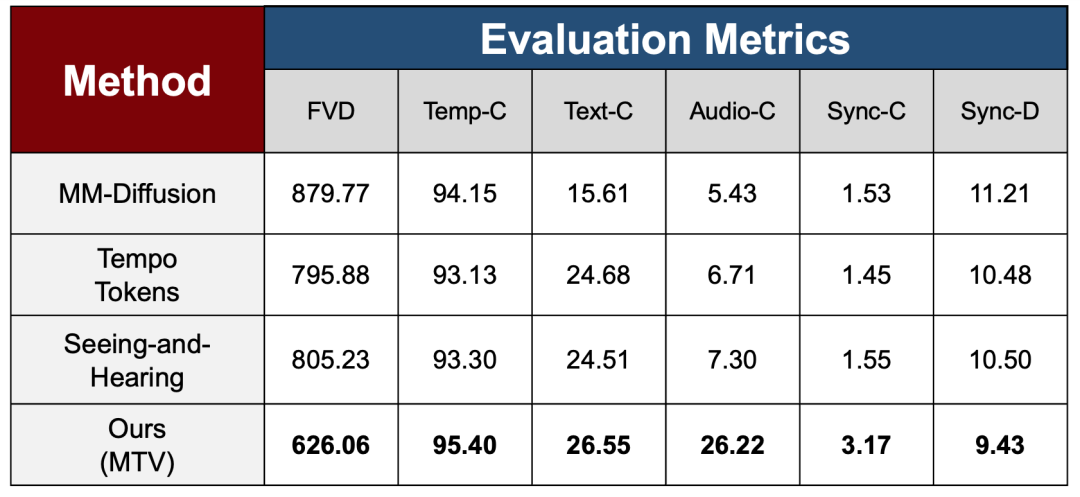
للتحقق من فعالية استراتيجية التدريب متعددة المراحل في مراحل التعلم المختلفة، تستخدم الورقة مجموعة من مقاييس التقييم الشاملة التي تغطي جودة الفيديو والاتساق الزمني وقدرة المحاذاة متعددة الوسائط في القسم التجريبي لتقييم استقرار النموذج وأدائه المتسق بشكل منهجي بعد إدخال إشارات تحكم معقدة تدريجياً، ومقارنته بثلاث طرق حديثة.
فيما يتعلق بجودة الإنتاج والاستقرار الزمني، تستخدم الدراسة مقياس FVD لقياس الفرق في التوزيع بين مقاطع الفيديو المُولّدة والفيديوهات الحقيقية، وتستخدم مقياس Temp-C لتقييم الاستمرارية الزمنية بين الإطارات المتجاورة. تُظهر النتائج أن MTV يتفوق بشكل ملحوظ على الطرق الحالية في مقياس FVD، مما يدل على أن النموذج لا يُضحي بجودة الإنتاج الإجمالية مع الحفاظ على استقرار زمني عالٍ في مقياس Temp-C، حتى مع إدخال تحكم صوتي أكثر تعقيدًا.
على مستوى التوافق متعدد الوسائط، تقيس الدراسة مدى التناسق بين الفيديو والنص/الصوت باستخدام مقياسي Text-C وAudio-C على التوالي. وقد أظهرت تقنية MTV تحسناً ملحوظاً في مقياس Audio-C، متجاوزةً بذلك طرق المقارنة الأخرى، مما يعكس فعالية آليات فصل الصوت والتحكم في التدفقات المتعددة في تعزيز التوافق بين الصوت والصورة.
لمعالجة القضايا الرئيسية في السيناريوهات التي تعتمد على الصوت، تقدم هذه الورقة مقياسين للتزامن، Sync-C و Sync-D، لتقييم ثقة التزامن وحجم الخطأ، على التوالي، وتحقيق الأداء الأمثل.
نتائج المقارنة

كما هو موضح في الشكل أعلاه، قارن الباحثون إطار عمل MTV بأحدث النتائج المتاحة. من الناحية البصرية، تعاني الطرق الحالية عمومًا من عدم استقرار كافٍ عند التعامل مع أوصاف النصوص المعقدة أو المشاهد السينمائية.
على سبيل المثال، حتى بعد ضبط خوارزمية MM-Diffusion بدقة على مدى 320,000 خطوة باستخدام ثماني وحدات معالجة رسومية NVIDIA A100 وبرنامجها الرسمي، لا تزال تواجه صعوبة في توليد صور متماسكة بصريًا وذات بنية سردية، حيث يميل أسلوبها العام إلى دمج أجزاء متفرقة. من ناحية أخرى، تميل خوارزمية TempoTokens إلى إنتاج تعابير وجه وحركات غير طبيعية في المشاهد المعقدة، خاصةً في سيناريوهات متعددة الأشخاص أو ذات نطاق ديناميكي عالٍ، مما يؤثر بشكل كبير على واقعية النتائج المُولَّدة. أما فيما يتعلق بمزامنة الصوت والصورة، فإن طريقة Xing et al. تواجه صعوبة في تحقيق مزامنة الصوت لتسلسلات أحداث محددة، مما يؤدي إلى أخطاء في عرض إيماءات الشخصيات أثناء العزف على الغيتار (كما هو موضح على الجانب الأيمن من الصورة أعلاه).
في المقابل، يمكن لإطار عمل MTV الحفاظ على جودة بصرية عالية وتزامن صوتي بصري مستقر في سيناريوهات مختلفة، ويمكنه توليد مقاطع فيديو متزامنة صوتيًا بدقة وبجودة سينمائية.
روابط مرجعية:
1.https://arxiv.org/abs/2506.08003








