Command Palette
Search for a command to run...
تم اختيار جامعة تورنتو وآخرون لـ NeurIPS 2025، واقترحوا إطار عمل Ctrl-DNA لتحقيق "التحكم المستهدف" في التعبير الجيني في خلايا محددة.

يُعدّ التنظيم الدقيق للتعبير الجيني في خلايا محددة أمرًا بالغ الأهمية للتقدم في مجالات مثل العلاج الجيني وعلم الأحياء التركيبي. تعتمد هذه العملية على فئة من تسلسلات الحمض النووي تُسمى "العناصر التنظيمية السيسيّة" (CRE)، مثل المحفزات والمعززات. تعمل هذه العناصر كمفاتيح للجينات، حيث تُحدد ما إذا كانت الجينات "مفعّلة" أو "متوقفة" في الخلايا المستهدفة، مع تجنب التنشيط غير الطبيعي في الخلايا الطبيعية الأخرى. ومع ذلك،إن عدد العناصر الكيميائية الفعالة الطبيعية محدود ويصعب مطابقتها بدقة مع سيناريوهات التطبيقات الطبية الحيوية المتنوعة.والأهم من ذلك، أن إمكانيات تسلسلات الحمض النووي تتزايد بشكل كبير. على سبيل المثال، يحتوي تسلسل من 100 قاعدة على 4¹⁰⁰ تركيبات. من الصعب للغاية التحقق منها واحدة تلو الأخرى من خلال التجارب. فهو ليس مستهلكًا للوقت والجهد فحسب، بل لا يلبي الاحتياجات العملية أيضًا.
لقد أدت أساليب التعلم العميق الحالية إلى تحسين الكفاءة التجريبية بشكل كبير، ولكن الأساليب الحالية لا تزال تواجه تحديات متعددة.على سبيل المثال، تعتمد بعض الطرق على الطفرات في الحمض النووي الموجود أو على تحسين التسلسل العشوائي، مما قد يقع بسهولة في فخ "التحسين المحلي"، مما يؤدي إلى نقص التنوع في التسلسلات الفعالة المُولّدة. في حين أن الطرق القائمة على نماذج اللغة الانحدارية الذاتية قادرة على التقاط أنماط تسلسل الحمض النووي، إلا أنها لا تستطيع سوى "محاكاة التسلسلات المعروفة" ولا تستطيع استكشاف عوامل تنظيمية جديدة خاصة بالخلايا. في حين أن الطرق القائمة على التعلم التعزيزي (RL) تُحسّن التأثيرات التنظيمية في الخلايا المستهدفة، إلا أنها تتجاهل التحكم في "الآثار الجانبية" على الخلايا الأخرى. علاوة على ذلك، غالبًا ما تتجاهل أطر التصميم القياسية هذه اعتبارات المعقولية البيولوجية. قد تفشل التسلسلات المُولّدة في مطابقة مواقع ربط عوامل النسخ الرئيسية (TFBSs)، مما يؤدي إلى فشل الوظائف التنظيمية الفعلية.
ولسد الفجوة في التصميم الدقيق للـ CRE الخاص بالخلايا، قام فريق من جامعة تورنتو، بالتعاون مع مختبر Changping ومؤسسات أخرى، بتطوير إطار عمل للتعلم التعزيزي المقيد يسمى Ctrl-DNA.يعتمد هذا الإطار، المبني على نموذج لغة الحمض النووي المُدرَّب مسبقًا، على خوارزمية تعلُّم مُعزَّز لتحقيق هدفين مُتزامنين أثناء عملية التحسين: تعظيم النشاط التنظيمي لـ CREs في الخلايا المُستهدفة مع الحدّ الصارم من نشاطها في الخلايا غير المُستهدفة. علاوةً على ذلك، تُوظَّف أداة مضاعفات لاغرانج الرياضية لموازنة هذين المتطلبين، ويُؤخذ توزيع TFBSs في الحمض النووي الحقيقي في الاعتبار لضمان الصحة البيولوجية للتسلسلات المُولَّدة.
وأظهرت نتائج الدراسة أنفي مهام تصميم 6 خلايا بشرية، تفوقت CRE التي تم إنشاؤها بواسطة Ctrl-DNA بشكل كبير على الطرق الموجودة في مؤشرين رئيسيين: "النشاط العالي في أنواع الخلايا المستهدفة" و"القيود في أنواع الخلايا غير المستهدفة".كما أنها تحافظ على تنوع كبير، وتوفر حلولاً جديدة لعلم الأحياء الاصطناعي من أجل "إنشاء أنظمة يمكن التحكم فيها"، والعلاج الجيني من أجل "تجنب المخاطر غير المستهدفة"، والطب الدقيق من أجل "إجراء التخصيص على مستوى الخلية".
وقد تم نشر نتائج الأبحاث ذات الصلة على منصة arXiv للطباعة المسبقة تحت عنوان "Ctrl-DNA: التعلم التعزيزي المقيد لتصميم العناصر التنظيمية الخاصة بالخلايا" وتم اختيارها لـ NeurIPS 2025.
أبرز الأبحاث:
* تم اقتراح إطار عمل جديد للتعلم التعزيزي الواعي للقيود لتوفير أدوات لتصميم CREs للتعبير الجيني الدقيق لنوع الخلية.
* تم تبسيط عملية التحسين، وتحسين الكفاءة التجريبية، وخفض تكاليف الحوسبة
* أثبتت التجارب أن Ctrl-DNA يتمتع بالفعالية الوظيفية والمصداقية البيولوجية

عنوان الورقة:
https://arxiv.org/abs/2505.20578
قم بمتابعة الحساب الرسمي والرد "Ctrl-DNA" للحصول على ملف PDF كامل
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:
مجموعة البيانات: استنادًا إلى مجموعات بيانات المحفزات والمعززات البشرية الحقيقية
في هذه الدراسة، استخدم الباحثون مجموعات بيانات المحفزات والمعززات البشرية الحقيقية لتقييم وإثبات صحة Ctrl-DNA.
في،تحتوي مجموعة بيانات المروج البشري على بيانات نشاط المروج من ثلاثة خطوط خلوية مشتقة من سرطان الدم.الخطوط الخلوية الثلاثة هي: Jurkat، وK562، وTHP1. جميعها خطوط خلوية مكونة للدم مشتقة من الأديم المتوسط، وتتميز بتشابه بيولوجي كبير. يبلغ طول كل تسلسل في هذه المجموعة 250 زوجًا قاعديًا. انظر الجدول أدناه:

تحتوي مجموعة بيانات المعزز البشري على بيانات نشاط CRE من ثلاثة خطوط خلوية تم قياسها بواسطة اختبار المراسل المتوازي الضخم (MPRA).الخطوط الخلوية الثلاثة هي: HepG2 (خط خلايا الكبد)، وK562 (خط خلايا الكريات الحمر)، وSK-N-SH (خط خلايا الورم الأرومي العصبي). يبلغ طول كل تسلسل في هذه المجموعة 200 زوج قاعدي. كما هو موضح في الجدول التالي:

من الجدير بالذكر أن النشاط المئوي الخامس والعشرين في سلالة خلايا THP1 بلغ 0.49، مما يُظهر توزيعًا منحرفًا نحو اليمين. قد يُفسر هذا التحيز في التوزيع جزئيًا زيادة صعوبة تقييد النشاط في سلالة خلايا THP1.
هندسة النموذج: استنادًا إلى نموذج لغة الحمض النووي المدرب مسبقًا، جنبًا إلى جنب مع استرخاء لاجرانج
Ctrl-DNA هو إطار عمل لتصميم تسلسلات الحمض النووي التنظيمي، ويعتمد على التعلم التعزيزي المقيد. هدفه الأساسي هو توليد عناصر CRE ذات خصوصية محددة لنوع الخلية.من حيث التطبيق الوظيفي، يجب تعظيم ملاءمة مُثبِّط CRE في الخلايا المستهدفة - أي تعزيز التعبير الجيني - مع التحكم الصارم في ملاءمة الخلايا غير المستهدفة ضمن حدٍّ مُحدَّد مُسبقًا. وفي الوقت نفسه، يجب ضمان توافق التسلسلات المُولَّدة مع القوانين البيولوجية الحقيقية لتجنب المواقف التي تُلبِّي فيها النتائج التجريبية المتطلبات ولكن يكون التطبيق غير فعَّال.
ولتحقيق هذه الغاية، أخذ الباحثون في الاعتبار سهولة استخدام الإطار، ومنطقيته، وجوانب أخرى، وأجروا تصميمًا تفصيليًا للإطار، كما هو موضح في الشكل التالي:
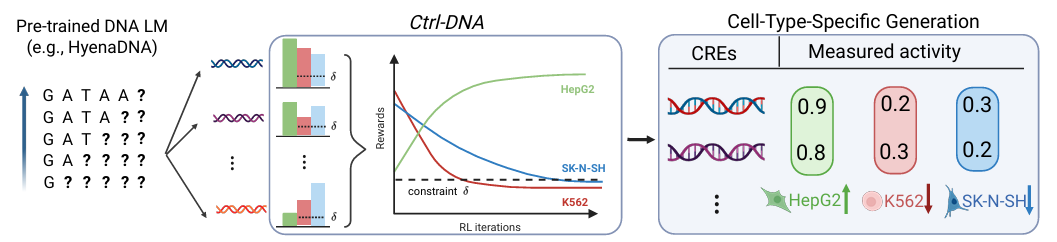
من حيث النماذج والمدخلات،يقوم Ctrl-DNA بضبط نموذج اللغة الجينومية الانحدارية HyenaDNA المدرب مسبقًا على الجينوم البشري باعتباره نموذج السياسة الأولي، ويستخدم بنية Enformer لتدريب نموذج المكافأة الخاص بنوع الخلية.وبدمج بيانات "ملاءمة التسلسل" التي تم قياسها من خلال تجارب الإبلاغ المتوازية على نطاق واسع، يتم حساب مكافآت الخلايا المستهدفة ومكافآت الخلايا غير المستهدفة بشكل منفصل.
على مستوى نمذجة المشكلة،قام الباحثون بتحويل تصميم تسلسل الحمض النووي إلى عملية اتخاذ القرار ماركوف المقيدة (CMDP). تعتمد آلية التحسين الأساسية لـ Ctrl-DNA على تحسين السياسة النسبية المقيدة على دفعات (CBROP). تُحوّل هذه الآلية مشكلة التحسين المقيدة إلى مشكلة تحسين ثنائية أولية غير مقيدة من خلال استرخاء لاغرانج. عملية التحسين تكرارية، حيث تتبع تحديثات السياسة تدرج دالة الهدف لاغرانج بمعدل التعلم. تُقيّد مكافآت الخلايا غير المستهدفة بتعديل مُضاعِف لاغرانج - بزيادة مُضاعِف لاغرانج لتعزيز القيد للخلايا غير المستهدفة التي تتجاوز حدًا معينًا، وتقليل مُضاعِف لاغرانج لإضعاف القيد للخلايا غير المستهدفة التي تُحقق الحد.
من أجل تقليل تعقيد التدريب، يتخلى Ctrl-DNA عن الاعتماد على نماذج القيمة في التعلم التعزيزي التقليدي.يتم حساب الميزة الطبيعية بشكل مباشر بناءً على إحصائيات بيانات الدفعة لتوجيه تحسين الاستراتيجية لاختيار التسلسلات ذات "مكافأة الهدف العالية + مكافأة خارج الهدف المنخفضة".
في تصميم دالة هدف تحديث الاستراتيجية، اعتمد الباحثون مزيجًا من "أهداف استبدال التقليم" و"تنظيم KL". من خلال التقليم، حدّوا من طفرات الاستراتيجية وأدخلوا تباعد KL بين الاستراتيجية الحالية والاستراتيجية المرجعية الأولية لضمان اتساق التسلسل المُولّد مع نمط الحمض النووي الطبيعي، مما أدى في النهاية إلى تشكيل دالة هدف تحديث الاستراتيجية.
لضمان المعقولية البيولوجية بشكل أكبر، يُدخل Ctrl-DNA ارتباط تردد TFBS كقيد إضافي. أولًا، تُمسح TFBSs باستخدام أداة FIMO من تسلسلات CRE حقيقية عالية التحديد لإنشاء متجه تردد TFBS حقيقي. ثم يُحسب متجه تردد TFBS المقابل لكل تسلسل مُولّد. يُستخدم بعد ذلك معامل ارتباط بيرسون كمكافأة إضافية للقيد، بينما يُقص مضاعف لاغرانج المقابل إلى [0، λmax] (λmax ≤ 1). يُوازن هذا بين المعقولية البيولوجية والتحسين الموضوعي، متجنبًا القيود المفرطة التي قد تُضعف قدرات استكشاف النموذج.
لضمان استقرار تدريب النموذج، استعرض الباحثون إعدادات المعلمات الفائقة المستخدمة في التجارب. دُرّبت جميع النماذج باستخدام مُحسِّن آدم، بمعدل تعلم سياسات يتراوح بين 1e-4، وحجم دفعة 256، و100 دورة تدريبية. دُرّبت التجارب على وحدة معالجة رسومات NVIDIA A100 واحدة بذاكرة 40 جيجابايت، كما هو موضح في الشكل أدناه.
النتائج التجريبية: بالمقارنة مع 8 أنواع من الطرق الأساسية، تتمتع Ctrl-DNA بمزايا واضحة
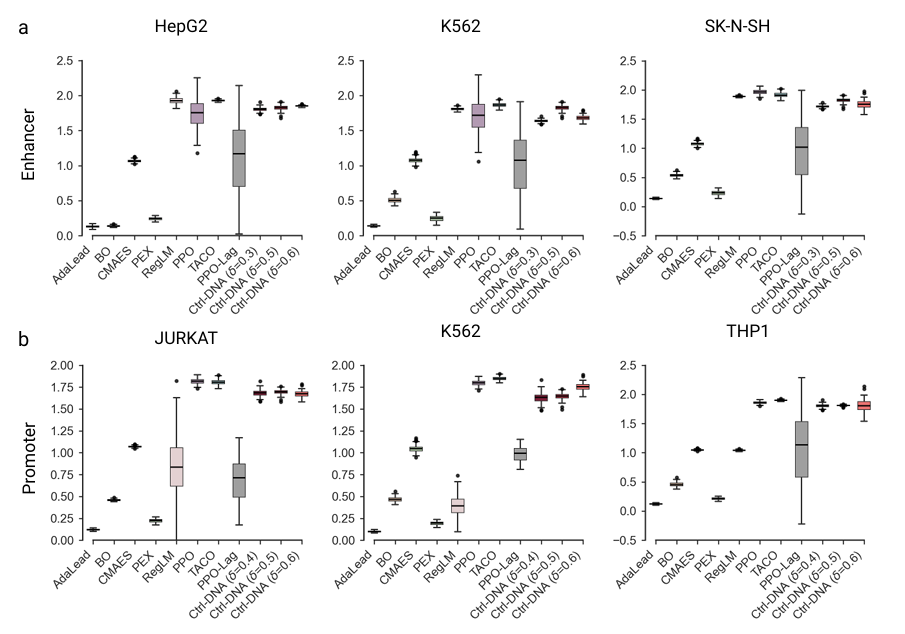
تدور تجربة تقييم أداء Ctrl-DNA حول مهمتين تصميميتين رئيسيتين: المعززات والمحفزات البشرية، وتغطي سلالات الخلايا الستة المذكورة أعلاه. قورنت التجربة بثمانية أنواع من الطرق الأساسية، بما في ذلك الخوارزميات التطورية (بما في ذلك AdaLead، والتحسين البايزي (BO)، وCMA-ES، وPEX)، والنماذج التوليدية (RegLM)، وطرق التعلم التعزيزي (بما في ذلك TACO، وPPO، وPPO-Lagrangian)، للتحقق من فعاليتها وإمكانية تطبيقها من أبعاد متعددة، مثل خصوصية نوع الخلية، والملاءمة البيولوجية، وتنوع التسلسل.
يظهر Ctrl-DNA مزايا كبيرة من حيث احتواء نوع الخلية المحدد.كما هو موضح في الشكل أدناه، يُمثل المحور الأفقي مدى ملاءمة أنواع الخلايا غير المستهدفة، بينما يُمثل المحور الرأسي مدى ملاءمة أنواع الخلايا المستهدفة. تُمثل الطريقة الموضحة في الزاوية العلوية اليمنى أفضل توازن بين تعظيم ملاءمة الخلايا المستهدفة وتقليل التعبير الجيني غير المستهدف.
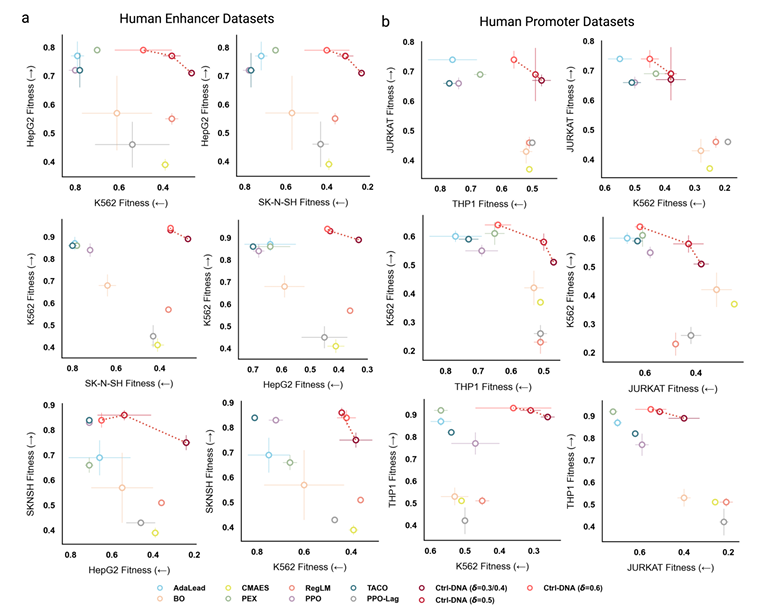
في تصميم المُحسِّن، حقق Ctrl-DNA باستمرار أعلى مستوى لياقة للخلية المستهدفة مع استيفاء قيود عدم الاستهداف عند جميع عتبات القيود المختلفة (δ = 0.3، 0.5، و0.6). هذا يعني أنه عزز لياقة الخلية المستهدفة مع استيفاء قيود عدم الاستهداف بدقة. علاوة على ذلك، بينما حققت طرق مثل TACO وCMAES مستوى تعبير عالٍ في الخلايا المستهدفة، إلا أنها لم تتمكن من تثبيط لياقة الخلية غير المستهدفة، مما أدى إلى ضعف في تحديد نوع الخلية.
بالنسبة لمهمة تصميم المُحفِّز، ولأن جميع أنواع الخلايا المستهدفة الثلاثة هي خلايا مُكوِّنة للدم من أصل الأديم المتوسط، فإن لديها تشابهًا كبيرًا في النسخ، مما يُشكِّل تحديًا كبيرًا لهذه المهمة، إلا أن Ctrl-DNA لا يزال يُؤدِّي أداءً جيدًا. حددت التجربة ثلاثة عتبات قيود مختلفة (δ=0.4 و0.5 و0.6) للاختبار. تفوقت Ctrl-DNA على جميع خطوط الأساس عند تعظيم ملاءمة نوع الخلية المستهدفة وتلبية عتبات القيود δ=0.5 و0.6. تجدر الإشارة أيضًا إلى أنه في حالات مثل خلايا THP1 حيث يكون توزيع النشاط منحرفًا إلى اليمين (كما ذُكر في قسم مجموعة البيانات أعلاه، وصل نشاط النسبة المئوية الخامسة والعشرين إلى 0.49)، لا يُمكن لأي طريقة قمع نشاطها غير المستهدف إلى العتبة الصارمة δ=0.4، ولكن Ctrl-DNA هي الطريقة الأقرب إلى متطلبات القيد بين جميع الطرق.
في التحقق من صحة الاحتمالية البيولوجية، كما هو موضح في الشكل أدناه، حقق Ctrl-DNA أعلى فرق مكافأة (ΔR) بين جميع أنواع الخلايا بالنسبة للمحفزات والمعززات البشرية، مما يشير إلى أنه يُحسّن بشكل أفضل التوافق النوعي لتسلسلات الحمض النووي للخلية. وفيما يتعلق بأهمية الزخارف، حقق Ctrl-DNA أيضًا أداءً أقوى في معظم أنواع الخلايا، باستثناء تصميم محفز THP1.
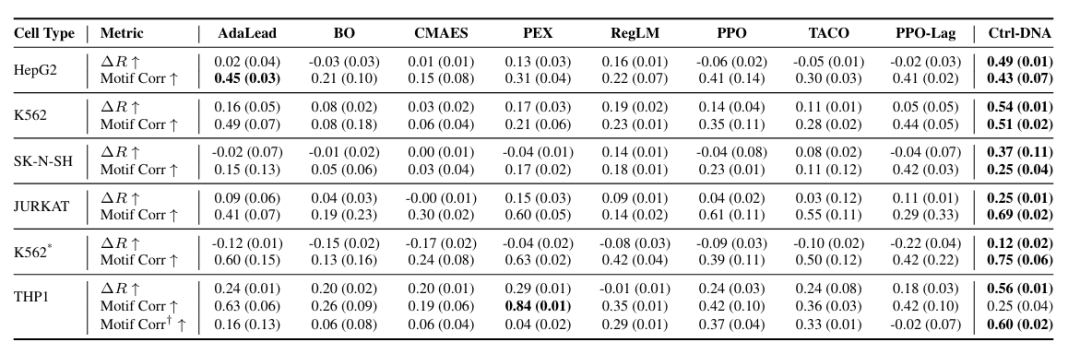
لاستكشاف هذا التناقض بشكل أعمق، استخرج الباحثون أنماطًا من تسلسلات المحفز عند النسبة المئوية التسعين من صلاحية THP1. باستخدام عتبة q < 0.05 لتجنب النتائج الإيجابية الخاطئة، أعادوا تقييم ارتباط النمط بين التسلسلات المُولّدة والمجموعة المرجعية، والمُمثلة بـ Corr† للنمط في الشكل أعلاه. أظهرت النتائج أن Ctrl-DNA تفوق على جميع خطوط الأساس حتى في ظل هذا الإعداد الصارم، حيث ارتفع معامل ارتباطه إلى 0.60، بينما انخفضت ارتباطات معظم خطوط الأساس، مما يُظهر قدرته على التقاط الأنماط التنظيمية ذات الأهمية الوظيفية بشكل تفضيلي.
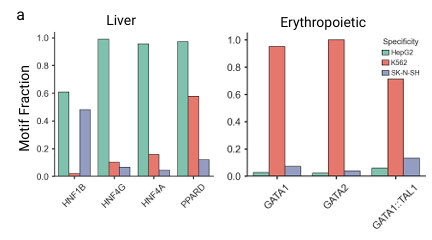
لمزيد من تحليل تردد TFBSs المحددة التي تم العثور عليها، قام الباحثون بفحص التسلسلات المولدة على وجه التحديد للعناصر المحددة لخط خلايا الكبد HepG2 وخط خلايا الكريات الحمر K562.كما هو موضح في الشكل أدناه، يُظهر تسلسل HepG2 المُولّد بواسطة Ctrl-DNA أعلى تواتر للأنماط الخاصة بالكبد، مثل HNF4A وHNF4G. وبالمثل، يحتوي التسلسل المُولّد بواسطة K562 على أعلى تواتر للأنماط الخاصة بالكرات الحمر، مثل GATA1 وGATA2. هذا يُظهر أن Ctrl-DNA لا يُحسّن فقط من لياقة الخلية المستهدفة، بل يتعلم أيضًا أنماطًا تنظيمية تعكس خصوصية نوع الخلية.
ومن حيث تنوع التسلسل، حقق Ctrl-DNA تنوعًا مماثلًا أو أعلى من معظم الخطوط الأساسية، مما يؤكد قدرته على توليد تسلسلات متنوعة دون التضحية بالرقابة التنظيمية.كما هو موضح في الشكل التالي:
أخيرًا، أثبت الباحثون فعالية وحدة Ctrl-DNA الأساسية من خلال تجارب الاستئصال. كما تم تأكيد دور وحدة تنظيم TFBS، حيث وجّهت التسلسلات بفعالية نحو أنماط بيولوجية واقعية.
تصميم "مفتاح" الحمض النووي المدعوم بالذكاء الاصطناعي يفتح فصلاً جديدًا
في الماضي، كان تصميم "مفاتيح" تسلسل الحمض النووي التنظيمي يعتمد في الغالب على "التجربة والخطأ" من خلال عدد كبير من عمليات الفحص اليدوي المتكررة.الآن، مع الجمع بين تكنولوجيا الذكاء الاصطناعي، يمكننا استخدام الخوارزميات للتنبؤ بـ "أي تسلسلات الحمض النووي لديها أعلى تطابق مع البروتين التنظيمي المستهدف"، مما يحسن بشكل كبير من كفاءة التصميم ودقته.وهذا هو أيضًا السبب الرئيسي وراء تحول تصميم مفتاح الحمض النووي المدعوم بالذكاء الاصطناعي إلى اتجاه جديد، والذي بدوره يعزز بشكل مباشر مجالات مثل العلاج الجيني وعلم الأحياء الاصطناعي من "واسع النطاق" إلى "دقيق".
هذه الورقة البحثية ليست سوى ثمرة من ثمار "تصميم مفتاح الحمض النووي المدعوم بالذكاء الاصطناعي". وبالنظر إلى الماضي، نجد أن العديد من المختبرات قد أجرت بالفعل أبحاثًا ذات صلة.
على سبيل المثال، نشر فريق من مختبر جاكسون ومعهد برود وجامعة ييل دراسة في مجلة Nature بعنوان "تصميم موجه آليًا لعناصر تنظيمية تستهدف أنواع الخلايا".استخدمت الدراسة الذكاء الاصطناعي لتصميم آلاف المفاتيح الجديدة للحمض النووي.يمكن لهذه المفاتيح التحكم بدقة في التعبير الجيني في أنواع مختلفة من الخلايا. على وجه التحديد، بنى الباحثون شبكة عصبية ملتوية عميقة (مالينوا) قادرة على التنبؤ بدقة بنشاط CRE، وطوّروا منصة معيارية (CODA) لتصميم CREs بوظائف محددة. توفر هذه المنصة أدوات فعّالة لتطوير الجينات المراسلة، وعلاج CRISPR، وطرق استبدال الجينات، وغيرها.
عنوان الورقة:
https://www.nature.com/articles/s41586-024-08070-z
بالإضافة إلى ذلك، هناك RegLM المذكور في المقالة أعلاه، والصادرة عن شركة Genentec. في الدراسة المعنونة "تصميم الحمض النووي التنظيمي الواقعي باستخدام نماذج اللغة الانحدارية التلقائية"،نقدم إطار عمل يسمى RegLM، والذي يعتمد على نموذج لغة الانحدار التلقائي جنبًا إلى جنب مع نموذج تسلسل الوظيفة المشرف لتصميم CREs الاصطناعية بخصائص محددة.وبالمثل، يعتمد RegLM أيضًا على إطار عمل HyenaDNA. فهو يُشفّر العلامات الوظيفية كرموز تلميحية، ويضيفها إلى بادئة تسلسل الحمض النووي، ويُدرّب النموذج أو يُحسّنه بدقة للتنبؤ بالرمز التالي، وبالتالي يُولّد تسلسلات حمض نووي بالوظائف المطلوبة. وفي الوقت نفسه، يجمع بين نموذج انحدار نشاط التسلسل المُشرف لفحص التسلسلات المُولّدة.
عنوان الورقة:
https://genome.cshlp.org/content/34/9/1411.full#aff-1
باختصار، يُعدّ تطوير Ctrl-DNA بلا شك خطوةً أخرى إلى الأمام في تصميم مفاتيح الحمض النووي. ورغم وجود بعض المشاكل أو المجالات التي لا تزال بحاجة إلى تحسين عاجل، مثل إضافة قيود بيولوجية لتحسين منطقية ووظائف التسلسل المُولّد، وكون تعديل مُضاعِف لاغرانج لا يزال مسألة خبرة، إلا أن تطوير هذه الأدوات وتحسينها قد فتح بلا شك آفاقًا جديدة في تصميم مفاتيح الحمض النووي، وعزز في الوقت نفسه التطور المستمر لعلم الذكاء الاصطناعي وعلم الأحياء متعدد التخصصات.








