Command Palette
Search for a command to run...
ACL 2025: جامعة أكسفورد وجهات أخرى تقترح استخدام GraphRAG الطبي، مما يؤدي إلى تسجيل رقم قياسي جديد في دقة الإجابة على الأسئلة وتحقيق نتائج SOTA على 11 مجموعة بيانات

يعتمد نظام المعرفة في المجال الطبي على آلاف السنين من الاكتشاف والتراكم، ويغطي قدرًا هائلاً من المبادئ والمفاهيم والمعايير العملية. إن تكييف هذه المعرفة بفعالية مع نافذة السياق المحدودة لنماذج اللغة الكبيرة الحالية يمثل عقبات تقنية لا يمكن التغلب عليها. على الرغم من أن الضبط الدقيق المُشرف (SFT) يقدم بديلاً، نظرًا لطبيعة المصدر المغلق لمعظم النماذج التجارية، فإن هذا النهج ليس مكلفًا فحسب، بل إنه أيضًا غير عملي للغاية في الممارسة العملية. بالإضافة إلى ذلك، يضع المجال الطبي متطلبات عالية للغاية على دقة المصطلحات وصرامة الحقائق. بالنسبة للمستخدمين غير المحترفين، فإن التحقق من دقة النماذج الكبيرة للإجابات المتعلقة بالطب هو في حد ذاته مهمة صعبة للغاية. لذلك، أصبحت كيفية تمكين النماذج الكبيرة من استخدام مجموعات البيانات الخارجية الكبيرة للتفكير المعقد في التطبيقات الطبية وتوليد إجابات دقيقة وموثوقة مدعومة بمصادر يمكن التحقق منها قضية أساسية في الأبحاث الحالية في هذا المجال.
إن ظهور تقنية التوليد المعزز بالاسترجاع (RAG) يوفر نهجًا جديدًا لحل المشكلات المذكورة أعلاه.يمكنه الاستجابة لاستفسارات المستخدم باستخدام مجموعات بيانات محددة أو خاصة دون الحاجة إلى تدريب إضافي للنموذج.مع ذلك، لا تزال مجموعات البحث والتحليل التقليدية (RAGs) قاصرةً في تجميع رؤى جديدة ومعالجة المهام التي تتطلب فهمًا شاملًا لمجموعة واسعة من الوثائق. يتفوق GraphRAG المقترح حديثًا بشكل ملحوظ على مجموعات البحث والتحليل التقليدية في التفكير المعقد، وذلك من خلال الاستفادة من نماذج التعلم العميق (LLMs) لبناء رسم بياني للمعرفة من الوثائق الخام، ثم استرجاع المعرفة بناءً على الرسم البياني لتحسين الإجابات. مع ذلك، يفتقر بناء الرسم البياني في GraphRAG إلى تصميم محدد لضمان مصداقية الإجابات ومصداقيتها، كما أن عملية بناء مجتمعه الهرمي مكلفة نظرًا لطبيعته العامة، مما يجعل تطبيقه المباشر والفعال في المجال الطبي أمرًا صعبًا.
ولمعالجة هذا الوضع، اقترح فريق مشترك من جامعة أكسفورد، وجامعة كارنيجي ميلون، وجامعة إدنبرة طريقة RAG تعتمد على الرسم البياني خصيصًا للمجال الطبي - Medical GraphRAG (MedGraphRAG).تعمل هذه الطريقة على تحسين أداء ماجستير الحقوق في المجال الطبي بشكل فعال من خلال توليد إجابات مبنية على الأدلة وشروحات المصطلحات الطبية الرسمية، مما لا يعزز مصداقية الإجابات فحسب، بل يحسن أيضًا الجودة الشاملة بشكل كبير.
وقد تم اختيار نتائج البحث ذات الصلة، بعنوان "نموذج اللغة الطبية الكبير الآمن من خلال استرجاع الرسم البياني - التوليد المعزز"، لـ ACL 2025.
أبرز الأبحاث:
* اقترحت هذه الدراسة لأول مرة إطار عمل Tukey RAG خصيصًا للاستخدام في المجال الطبي.
* طورت هذه الدراسة بناءًا فريدًا للرسم البياني الثلاثي وطريقة استرجاع U لتمكين نموذج اللغة الكبير (LLM) من الاستفادة بكفاءة من بيانات RAG بأكملها وتوليد إجابات قائمة على الأدلة.
* يتفوق MedGraphRAG على طرق الاسترجاع الأخرى ونماذج اللغة الكبيرة المخصصة للطب في معايير الإجابة على الأسئلة الطبية المتعددة.
عنوان الورقة:
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:
البحث يعتمد على ثلاثة أنواع من البيانات
البيانات المستخدمة في هذه الدراسة مقسمة إلى ثلاث فئات، ولكل نوع خصائص تتناسب مع دوره في الدراسة:
* بيانات RAG
مع الأخذ في الاعتبار أن المستخدمين قد يستخدمون بيانات خاصة يتم تحديثها بشكل متكرر (مثل السجلات الطبية الإلكترونية للمرضى)، اختارت الدراسة مجموعة بيانات السجلات الصحية الإلكترونية العامة MIMIC-IV، والتي يمكنها محاكاة سيناريوهات البيانات الخاصة المتغيرة ديناميكيًا في التطبيقات الفعلية وتوفير أساس للتحقق من جدوى الطريقة.
* بيانات المستودع
تُستخدم هذه المجموعة من البيانات لتوفير مصادر موثوقة وتعريفات مفردات موثوقة لإجابات النموذج الكبير. بيانات المستودع الرئيسي هي MedC-K، التي تحتوي على 4.8 مليون ورقة بحثية أكاديمية في الطب الحيوي، و30,000 كتاب دراسي، وجميع منشورات الأدلة من FakeHealth وPubHealth. يغطي محتواها نطاقًا واسعًا، وهو موثوق أكاديميًا؛ أما بيانات المستودع الأساسية فهي رسم بياني UMLS، الذي يحتوي على مفردات طبية موثوقة وعلاقات دلالية لضمان دقة المصطلحات الطبية.
* بيانات الاختبار
تُستخدم مجموعة البيانات هذه لتقييم أداء طريقة MedGraphRAG، بما في ذلك جزء الاختبار من 9 مجموعات بيانات طبية حيوية متعددة الاختيارات في MultiMedQA (بما في ذلك MedQA وMedMCQA وPubMedQA والموضوعات السريرية MMLU وما إلى ذلك)، والتي تُستخدم لاختبار أداء الطريقة في الإجابة على الأسئلة الطبية الروتينية؛ تُستخدم مجموعتان من بيانات التحقق من الحقائق الصحية العامة FakeHealth وPubHealth لتقييم قدرة الطريقة على الإجابة القائمة على الأدلة؛ بالإضافة إلى ذلك، جمعت الدراسة أيضًا مجموعة اختبار DiverseHealth، والتي تحتوي على 50 سؤالاً سريريًا حقيقيًا تغطي مجموعة واسعة من الموضوعات مثل الأمراض النادرة وصحة الأقليات، مع التركيز على المساواة الصحية، والتي يمكن أن تثري أبعاد التقييم بشكل أكبر.
MedGraphRAG: يعتمد على تقسيم النافذة المنزلقة وتجميع العلامات والبحث U
كما هو موضح في الشكل أدناه،يتضمن سير العمل الشامل لـMedGraphRAG ثلاثة روابط أساسية بشكل أساسي:إنشاء رسم بياني للمعرفة استنادًا إلى المستندات، وتنظيم الرسم البياني وتلخيصه لدعم الاسترجاع، والرد على استفسارات المستخدم عن طريق استرجاع البيانات.
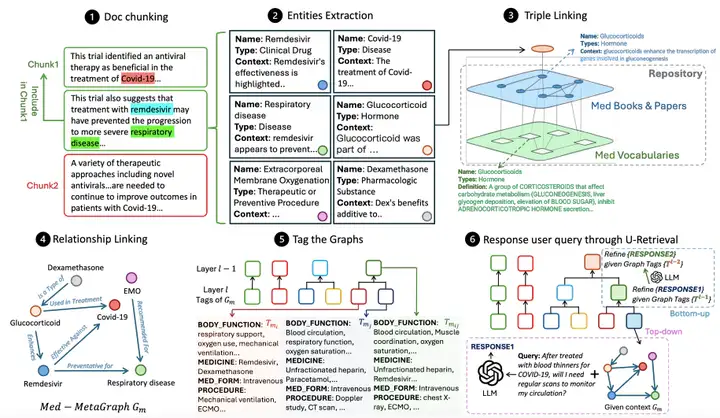
يقوم Medical Graph Construction أولاً بتقسيم المستند الدلالي، وتقسيم المستند إلى أجزاء بيانات تتوافق مع قيود سياق LLM.تعتمد الدراسة على أسلوب هجين يجمع بين فصل الحروف وتجزئة الموضوع دلاليا، أي فصل الفقرات أولا بفواصل الأسطر، ثم بناء LLM LG من خلال الرسم البياني للحكم على مدى صلة الموضوع بين الفقرة والكتلة الحالية لاتخاذ قرار تقسيم الكتلة.في الوقت نفسه، يتم تقديم نافذة منزلقة مكونة من 5 أجزاء لتقليل الضوضاء، ويتم استخدام تقييد علامة LG كعتبة صارمة لتجزئة الكتلة، مع الأخذ في الاعتبار كل من المنطق الدلالي وقيود سياق النموذج.
بعد تقسيم الكتلة، تبدأ عملية استخراج الكيان. بمساعدة موجهات استخراج الكيانات من LG، يتم تحديد الكيانات ذات الصلة من كل كتلة، ويتم توليد مُخرَج مُنَظَّم يحتوي على الاسم والنوع ووصف السياق، مما يُمهِّد الطريق لربط الكيانات لاحقًا.يعد الربط الثلاثي هو المفتاح لضمان الدقة.تم إنشاء رسم بياني للمستودع (RepoGraph) لربط مستندات RAG للمستخدم بمصادر موثوقة: الطبقة السفلية هي رسم بياني UMLS (Med Vocabularies) يحتوي على مفردات طبية وعلاقاتها، ويتم إنشاء الطبقة العليا من الكتب المدرسية الطبية والمقالات العلمية (Med Books & Papers). بعد ذلك، يحدد الباحثون الكيانات المستخرجة من مستندات RAG على أنها E1. بناءً على الارتباط بين الكيانات، ترتبط هذه الكيانات بالكيانات E2 المستخرجة من الكتب أو الأوراق الطبية. يرتبط E2 أيضًا بكيانات UMLS E3، مما يشكل بنية ثلاثية من [كيان RAG، المصدر، التعريف]، مما يضمن إمكانية تتبع كل كيان إلى مصدر واضح وتعريف قياسي. ثم يتم إجراء ربط العلاقة. يحدد LG مع تلميحات التعرف على العلاقة العلاقات بين كيانات RAG بناءً على محتوى الكيان والمراجع، مما يؤدي إلى إنشاء عبارات تحتوي على كيانات المصدر والكيانات المستهدفة وأوصاف العلاقة. وأخيرًا، يتم إنشاء رسم بياني ميتا طبي موجه لكل كتلة بيانات.
بعد إنشاء الرسم البياني، ستحتاج إلى وضع علامات على الرسوم البيانية لتحسين كفاءة الاسترجاع.بخلاف نهج GraphRAG المُكلف لبناء مجتمعات الرسوم البيانية، تستفيد هذه الطريقة من الطبيعة المُهيكلة للنصوص الطبية، وتُلخص كل رسم بياني طبي ميتافيزيقي باستخدام تسميات مُحددة مسبقًا (مثل الأعراض، والتاريخ الطبي، والوظيفة الجسدية، والأدوية) لإنشاء مُلخص مُهيكل للعلامات. ثم تستخدم هذه الطريقة التجميع الهرمي التراكمي العتبي الديناميكي القائم على تشابه العلامات لتجميع الرسوم البيانية وإنشاء مُلخص أكثر تجريدًا وشمولًا. في البداية، يُعامل كل رسم بياني كمجموعة مُستقلة. يُحسب تشابه العلامات بين أزواج المجموعات بشكل تكراري، وتُدمج أفضل 201 زوجًا من مجموعات TP3T ذات أعلى تشابه لإنشاء طبقة مُلخص علامات جديدة. تقتصر هذه العملية على 12 طبقة، مما يُحقق توازنًا بين الدقة والكفاءة.
تحقق مرحلة استرجاع U النهائية استجابة فعالة للاستعلام من خلال الاستجابة لـ LLM LR.أولاً، يُنشئ LR ملخصًا للعلامات لاستعلام المستخدم. من خلال استرجاع دقيق من أعلى إلى أسفل، بدءًا من أعلى مستوى، يُطابق أكثر العلامات تشابهًا طبقةً تلو الأخرى، مُحددًا بذلك الرسم البياني الطبي الوصفي المستهدف. بناءً على تشابه التضمين بين الاستعلام ومحتوى الكيان، يُستخرج الكيانات الأعلى تصنيفًا وأقرب جيرانها الثلاثيين، ويستخدم هذه الكيانات والعلاقات لإنشاء إجابة أولية. بعد ذلك، تبدأ مرحلة تحسين الإجابة من أسفل إلى أعلى. يُعدّل LR الإجابة بناءً على ملخص علامات الطبقة السابقة. تتكرر هذه العملية حتى الوصول إلى المستوى المستهدف (عادةً من 4 إلى 6 طبقات)، مما يُنتج في النهاية إجابةً تُوازن بين الوعي بالسياق العالمي وكفاءة الاسترجاع.
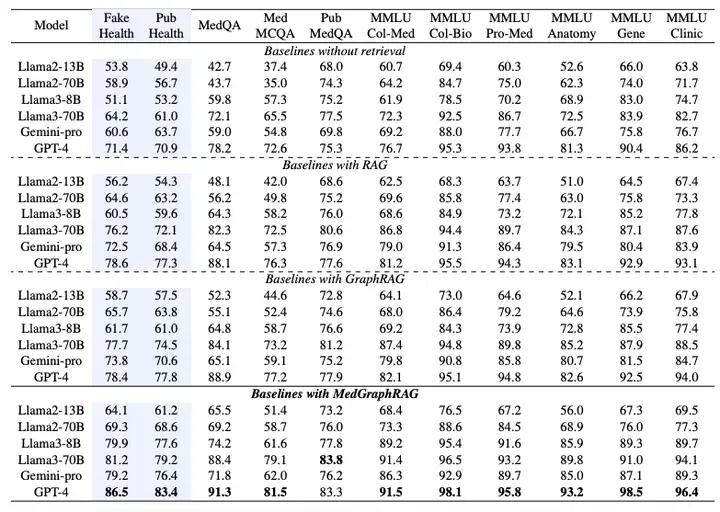
MedGraphRAG: تم التحقق من صحتها على 6 نماذج و11 مجموعة بيانات لتحقيق SOTA
للتحقق من أداء MedGraphRAG، اختارت الدراسة ستة نماذج لغوية كبيرة وصممت مجموعات متعددة من التجارب، بما في ذلك Llama2 (13B، 70B)، وLlama3 (8B، 70B)، وGemini-pro وGPT-4.المقارنة الرئيسية هي مع RAG القياسي الذي تم تنفيذه بواسطة LangChain و GraphRAG الذي تم تنفيذه بواسطة Microsoft Azure.يتم تشغيل كافة الطرق على نفس بيانات RAG وبيانات الاختبار.
كما هو موضح في الجدول أدناه، يتم قياس أداء التقييم متعدد الاختيارات من خلال دقة اختيار الخيار الصحيح.تظهر النتائج التجريبية أن MedGraphRAG يتفوق بشكل كبير على خط الأساس بدون وظيفة الاسترجاع، وRAG القياسي، وGraphRAG:بالمقارنة مع خط الأساس بدون بحث، حقق النموذج تحسنًا متوسطًا بلغ حوالي 101 نقطة من TP3T في التحقق من الحقائق و81 نقطة من TP3T في الإجابة على الأسئلة الطبية. وبالمقارنة مع GraphRAG، حقق النموذج تحسنًا بلغ حوالي 81 نقطة من TP3T في التحقق من الحقائق و51 نقطة من TP3T في الإجابة على الأسئلة الطبية. وكان التحسن أكثر وضوحًا في النماذج الأصغر (مثل Llama2 13B)، مما يدل على تكامله الفعال بين قدرات التفكير النموذجي والمعرفة الخارجية. وعند تطبيقه على نماذج أكبر (مثل Llama70B وGPT-4)، حقق النموذج أداءً متطورًا على 11 مجموعة بيانات، متجاوزًا حتى النماذج المُحسّنة بدقة على مجموعات البيانات الطبية مثل Med-PaLM 2 وMed-Gemini، مُرسخًا أداءً متطورًا جديدًا في قائمة أفضل أداء في مجال ماجستير الحقوق الطبية.
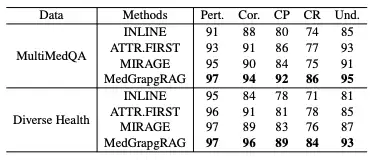
في تقييم الجيل الطويل،قامت هذه الدراسة بمقارنة MedGraphRAG مع نماذج مثل Inline Search وATTR-FIRST من حيث خمسة أبعاد: الصلة، والصحة، ودقة الاستشهاد، وتذكر الاستشهاد، والقابلية للفهم على معايير MultiMedQA وDiverseHealth.تظهر النتائج في الجدول أدناه. حقق MedGraphRAG نتائج أعلى في جميع المؤشرات، وخاصةً في دقة الاستشهادات، والتذكر، وسهولة الفهم، بفضل إجاباته المستندة إلى الأدلة وشرحه الواضح للمصطلحات الطبية.
في دراسة الحالة، التي تناولت حالةً معقدةً من مرض الانسداد الرئوي المزمن (COPD) وقصور القلب، تجاهلت توصيات GraphRAG تأثير الأدوية على قصور القلب، بينما استطاعت MedGraphRAG التوصية بأدوية آمنة. ويعود ذلك إلى الارتباط المباشر بين كياناتها ومراجعها، مما أدى إلى تجنب إغفال المعلومات الرئيسية الناتجة عن تداخل المعلومات في GraphRAG.
دمج الرسوم البيانية المعرفية ونماذج اللغة الكبيرة
عند تقاطع الطب والذكاء الاصطناعي، أصبح دمج الرسوم البيانية المعرفية ونماذج اللغة الكبيرة اتجاهًا رئيسيًا لتعزيز الاختراقات التكنولوجية، وتوفير أفكار جديدة لحل المشكلات المعقدة في المجال الطبي.
على سبيل المثال، إطار عمل KG4Diagnosis الذي اقترحه فريق مشترك من جامعة كامبريدج وجامعة أكسفورد،إنه يحاكي الأنظمة الطبية في العالم الحقيقي من خلال بنية هرمية متعددة الوكلاء ويجمع الرسوم البيانية المعرفية لتعزيز قدرات التفكير التشخيصي، ويغطي التشخيص الآلي وتخطيط العلاج لـ 362 مرضًا شائعًا.قام فريق بحثي من جامعة فودان برسم خريطة شاملة لبروتينات صحة الإنسان وأمراضه. من خلال تحليل معمق لبيانات بروتينات البلازما لـ 53,026 فردًا على مدى فترة متابعة متوسطة بلغت 14.8 عامًا، غطت الخريطة 2,920 بروتينًا بلازميًا و406 أمراض سابقة، و660 مرضًا جديدًا ظهر خلال فترة المتابعة، و986 نمطًا ظاهريًا مرتبطًا بالصحة.كشف العديد من الارتباطات بين البروتين والأمراض والبروتين والنمط الظاهري،توفير أساس مهم للطب الدقيق وتطوير الأدوية الجديدة.
نظام AMIE الذي أطلقته شركة Google DeepMind،دمج قدرات الاستدلال في السياق الطويل لنموذج الجوزاء الكبير مع الرسم البياني للمعرفة،من خلال البحث الديناميكي في الإرشادات السريرية وقواعد المعرفة الدوائية، يُمكن وضع خطة علاجية متسقة لحالات تشخيصية متعددة. على سبيل المثال، بالنسبة لمرضى الانسداد الرئوي المزمن (COPD) وقصور القلب، يُمكن التوصية بدقة بحاصرات بيتا الانتقائية للقلب، مما يُجنّب مخاطر تفاعل الأدوية مع أنظمة الذكاء الاصطناعي التقليدية.
يدمج الرسم البياني للمعرفة الطبية الحيوية الذي أنشأته شركة أسترازينيكا 3 ملايين وثيقة وبيانات بحثية داخلية، ويسرع من فحص المرشحين الجدد للأدوية من خلال تحليل شبكة ارتباط الدواء بالمرض المستهدف.لا تتضمن الخريطة مؤشرات الأدوية المعتمدة فحسب، بل تغطي أيضًا بيانات "الاستخدام خارج التسمية" في التجارب السريرية.توفير دعم القرارات لإعادة توظيف الأدوية المُستخدمة. علاوةً على ذلك، تدمج منصة الرسم البياني المعرفي من IBM Watson Health مليار قطعة من بيانات المرضى مع إرشادات قائمة على الأدلة، وذلك لوضع خطط علاجية مُخصصة لسرطان الرئة، تشمل الاختبارات الجينية، وتوقع حساسية الأدوية، وخطط المتابعة، مما يُقلل من الخطأ المتوقع في بقاء المريض على قيد الحياة إلى ±2.3 شهر.
لا تُسهم هذه الممارسات المبتكرة في دفع عجلة التطوير التكراري لتقنيات الذكاء الاصطناعي الطبي فحسب، بل تُظهر أيضًا إمكانات هائلة في تحسين دقة التشخيص، وتسريع تطوير الأدوية، وتحسين عملية اتخاذ القرارات السريرية. ومع استمرار نضوج هذه التقنية، سيُسهم دمج الرسوم البيانية المعرفية ونماذج اللغات الكبيرة في كسر حواجز المعلومات في المجال الطبي، وإعطاء زخم مستدام لتطوير الرعاية الصحية العالمية.
المقالات المرجعية:
1.https://mp.weixin.qq.com/s/WhVbnoso2Jf2PyZQwV93Rw
2.https://mp.weixin.qq.com/s/RWy4taiJCu3kMPfTzOWYSQ
3.https://mp.weixin.qq.com/s/lMLk








