Command Palette
Search for a command to run...
نمذجة تسلسل طويل بطول 8 كيلو بايت، نموذج لغة البروتين يمكن لـ Prot42 توليد روابط عالية الألفة باستخدام تسلسل البروتين المستهدف فقط
تلعب الروابط البروتينية (مثل الأجسام المضادة والببتيدات المثبطة) دورًا لا يمكن الاستغناء عنه في السيناريوهات الرئيسية مثل تشخيص المرض وتحليل التصوير وتوصيل الأدوية المستهدفة.تقليديا، اعتمد تطوير الروابط البروتينية عالية التخصص بشكل كبير على التقنيات التجريبية مثل عرض البكتيريا والتطور الموجه.ومع ذلك، تواجه هذه الأساليب عمومًا تحديات الاستهلاك الهائل للموارد ودورات البحث والتطوير الطويلة، كما أنها محدودة بسبب الاختناق المتأصل في تعقيد تركيبات تسلسل البروتين.
مع تطور الذكاء الاصطناعي، أصبحت نماذج لغة البروتين (PLMs) أداةً مهمةً لفهم العلاقة بين تسلسلات البروتين ووظائفه. لتصميم رابط البروتين، يُمكن لنماذج لغة البروتين تصميم بروتينات ليجند أو شظايا أجسام مضادة مباشرةً ذات ألفة ارتباط عالية، بناءً على تسلسل البروتين المستهدف، استنادًا إلى قدرة نماذج اللغة على التوليد. ومع ذلك، تواجه هذه النماذج تحدياتٍ أيضًا، مثل نقص نماذج لغة البروتين التي تتمتع بقدرات نمذجة السياق الطويل وقدرات توليد حقيقية، خاصةً في تصميم واجهات الارتباط المعقدة وروابط البروتين الطويلة. هناك فجوة تقنية كبيرة.
وبناءً على ذلك، قام فريق بحثي مشترك من معهد Inception للذكاء الاصطناعي في أبو ظبي، الإمارات العربية المتحدة، وشركة Cerebras Systems في وادي السيليكون، الولايات المتحدة الأمريكية،تم اقتراح أول عائلة PLMs، Prot42، والتي تعتمد فقط على معلومات تسلسل البروتين ولا تتطلب إدخال بنية ثلاثية الأبعاد.يستغل هذا النموذج القوة التوليدية للانحدار التلقائي والهندسة المعمارية المعتمدة على فك التشفير فقط.يتيح إنشاء روابط بروتينية عالية الألفة وبروتينات ربط الحمض النووي الخاصة بالتسلسل في غياب المعلومات البنيوية.أظهر Prot42 أداءً جيدًا في اختبارات PEER، وتوليد رابط البروتين، وتجارب توليد رابط محدد لتسلسل الحمض النووي.
البحث ذو الصلة يحمل عنوان "Prot42: عائلة جديدة من نماذج لغة البروتين لتوليد رابط البروتين المستهدف" وقد تم نشره كنسخة أولية على arXiv.
أبرز ما جاء في البحث* يستخدم Prot42 استراتيجية تدريب توسع السياق التدريجي، والتي تتوسع تدريجيًا من 1024 حمضًا أمينيًا أوليًا إلى 8192 حمضًا أمينيًا. * في اختبار PEER القياسي، يُظهر Prot42 أداءً جيدًا في 14 مهمة، مثل التنبؤ بوظائف البروتين، وتحديد المواقع الفرعية للخلايا، ونمذجة التفاعل. * بخلاف AlphaProteo، الذي يعتمد على بنية ثلاثية الأبعاد، يحتاج Prot42 فقط إلى تسلسل البروتين المستهدف لتوليد الروابط.
عنوان الورقة:
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:
https://go.hyper.ai/UuE1o
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
مجموعات البيانات: 3 مجموعات بيانات كبيرة تدعم تطوير النموذج والتدريب عليه
في هذه الدراسة، استُخدمت عدة مجموعات بيانات رئيسية لتدريب نموذجها وتقييم أدائه. لا تغطي هذه المجموعات نطاقًا واسعًا من معلومات تسلسل البروتين فحسب، بل تتضمن أيضًا بيانات تفاعل البروتين مع الحمض النووي، مما يوفر مواد تدريب ثرية لـ Prot42.
قاعدة بيانات واجهة البروتين-الحمض النووي (PDIdb) 2010
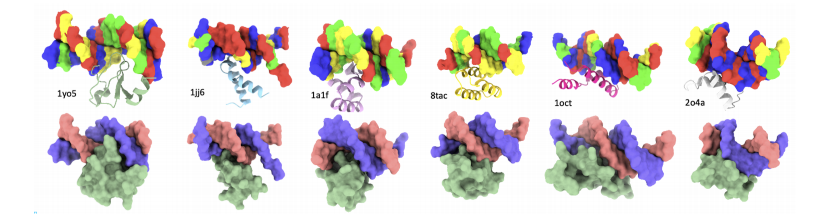
ولتصميم البروتينات القادرة على الارتباط بتسلسلات الحمض النووي المستهدفة، استخدم الباحثون مجموعة بيانات PDIdb 2010.تحتوي مجموعة البيانات هذه على 922 زوجًا فريدًا من الحمض النووي والبروتين وتم استخدامها لتدريب وتقييم قدرة Prot42 على توليد بروتينات ترتبط بتسلسلات DNA محددة.لتقييم نماذج البروتين DNA الأربعة، قام الباحثون باستخراج أجزاء من DNA من هياكل PDB المختلفة، بما في ذلك 1TUP، و1BC8، و1YO5، و1L3L، و2O4A، و1OCT، و1A1F، و1JJ6.
مجموعة بيانات UniRef50
تأتي مجموعة بيانات ما قبل التدريب لنموذج Prot42 بشكل أساسي من قاعدة بيانات UniRef50.تحتوي قاعدة البيانات على 63.2 مليون تسلسل من الأحماض الأمينية، تغطي مجموعة واسعة من الأنواع البيولوجية ووظائف البروتين.يتم تجميع هذه التسلسلات، ويتم تجميع التسلسلات ذات التشابه الذي يتجاوز 50% معًا، مما يقلل من تكرار البيانات ويحسن كفاءة التدريب.
قبل تدريب Prot42، قام فريق البحث بمعالجة مجموعة بيانات UniRef50 مسبقًا.يتم تصنيفها باستخدام مفردات مكونة من 20 حمضًا أمينيًا قياسيًا.استخدم Xtoken لتمثيل بقايا الأحماض الأمينية (يتم استخدام X لتمييز بقايا الأحماض الأمينية غير الشائعة أو الغامضة).
في مرحلة معالجة البيانات المسبقة،قام فريق البحث بمعالجة التسلسلات بأقصى طول سياق يبلغ 1024 رمزًا واستبعد التسلسلات الأطول من ذلك، وحصل في النهاية على مجموعة بيانات مفلترة تضم 57.1 مليون تسلسل.كثافة التعبئة الأولية هي ٢٧١TP3T. ولتحسين استخدام البيانات وكفاءة الحوسبة، اعتمد فريق البحث استراتيجية تعبئة بطول تسلسل متغير (VSL).لقد قمنا بزيادة معدل إشغال الرموز ضمن طول سياق ثابت، وأخيرًا قمنا بتقليص مجموعة البيانات إلى 16.2 مليون تسلسل مبطن.تصل كفاءة التعبئة إلى 96%.
قاعدة بيانات STRING
قاعدة بيانات STRING هي قاعدة بيانات شاملة للتفاعل بين البروتينات.يدمج هذا النظام البيانات التجريبية والتنبؤات الحسابية ونتائج استخراج النصوص لتوفير درجات ثقة لتفاعلات البروتينات. ولتدريب Prot42 على توليد روابط بروتينية، فحص فريق البحث أزواج تفاعلات بروتينية ذات درجات ثقة ≥ 90% من قاعدة بيانات STRING لضمان موثوقية عالية لبيانات التدريب.علاوة على ذلك، تم تقييد طول التسلسل إلى 250 حمضًا أمينيًا للتركيز على بروتينات ربط المجال الواحد القابلة للإدارة.بعد الفحص، تحتوي مجموعة البيانات النهائية على 74066 زوجًا من التفاعل بين البروتينات، ومجموعة تدريب D(train)(pb) تحتوي على 59252 عينة ومجموعة تحقق D(val)(pb) تحتوي على 14814 عينة.
هندسة النموذج: متغيران رئيسيان مشتقان من هندسة فك التشفير الانحداري التلقائي
Prot42 المذكور في هذه الورقة البحثية هو نموذج PLM قائم على بنية فك تشفير انحداري ذاتي، يُولّد تسلسلات الأحماض الأمينية واحدًا تلو الآخر، ويتنبأ بالحمض الأميني التالي باستخدام الحمض الأميني المُولّد سابقًا. تُمكّن هذه البنية النموذج من رصد التبعيات بعيدة المدى في التسلسل.إنه قادر على تعلم التمثيلات الغنية مباشرة من قواعد بيانات تسلسل البروتين غير المسمى الكبيرة، مما يسد الفجوة بشكل فعال بين العدد الهائل من تسلسلات البروتين المعروفة والنسبة الصغيرة نسبيًا من تسلسلات البروتين (<0.3%).في الوقت نفسه، يحتوي النموذج على طبقات محول متعددة، تحتوي كل منها على آلية انتباه ذاتي متعددة الرؤوس وشبكة عصبية تغذية أمامية لالتقاط الأنماط المعقدة في التسلسل.
تصميمه مستوحى من الاختراقات في معالجة اللغة الطبيعية، وخاصة نموذج LLaMA. يلتقط Prot42 المعلومات التطورية والبنيوية والوظيفية للبروتينات من خلال التدريب المسبق على تسلسلات بروتينية غير مصنفة على نطاق واسع، مما يتيح إنشاء روابط بروتينية عالية الألفة.
وعلى هذا الأساس،قام الباحثون بتدريب نموذجين مسبقًا،وهذا هو، Prot42-B وProt42-L.
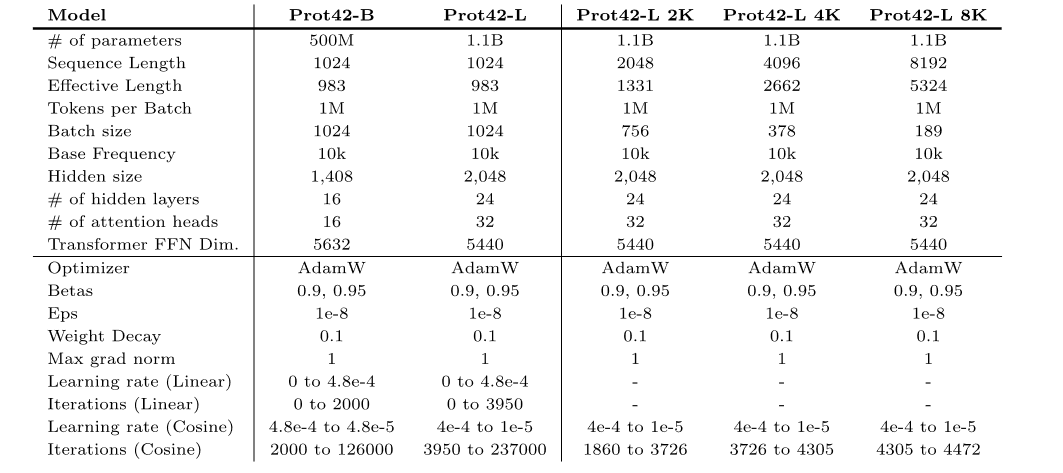
* بروت42-ب:في الإصدار الأساسي، يحتوي النموذج على 500 مليون معلمة ويدعم طول تسلسل أقصى يبلغ 1024 حمضًا أمينيًا.
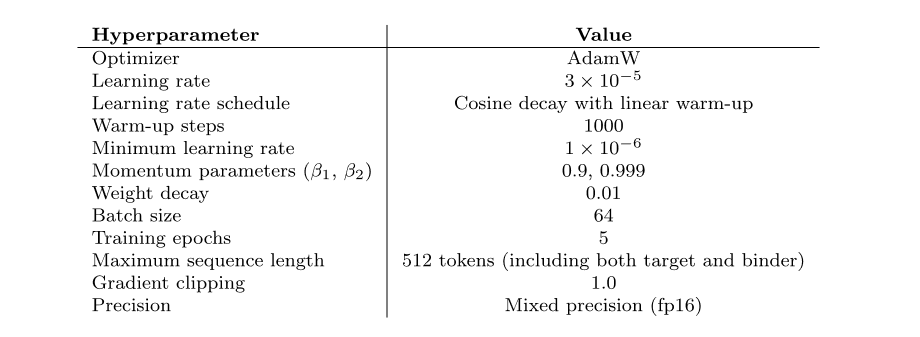
* بروت42-ل:يحتوي الإصدار الكبير على 1.1 مليار معلمة نموذجية ويدعم أيضًا طول تسلسل أقصى يبلغ 1024 حمضًا أمينيًا.تم تمديد طول سياق Prot42-L تدريجيًا من 1024 حمضًا أمينيًا إلى 8192 حمضًا أمينيًا.في هذه العملية، تم استخدام طول سياق متزايد تدريجيًا وحجم دفعة ثابت (مليون رمز غير مملوء) لضمان استقرار وكفاءة النموذج عند معالجة التسلسلات الطويلة، مما أدى إلى تحسين قدرة النموذج على معالجة التسلسلات الطويلة والهياكل البروتينية المعقدة بشكل كبير.يحتوي Prot42-L أيضًا على 24 طبقة مخفية، تحتوي كل منها على 32 رأس انتباه.البعد المخفي للطبقة هو 2,048.
الاستنتاج التجريبي: تظهر إمكانات كبيرة في جميع المهام الست
لتقييم أداء نموذج Prot42 قبل التحقق من صحته في المهام اللاحقة، استخدم الباحثون مقياس التعقيد المعياري (PPL) لتقييم نماذج اللغة الانحدارية التلقائية، أي أداء نموذج Prot42 في أطوال سياقية مختلفة.تتمتع جميع النماذج بدرجة حيرة عالية نسبيًا عند 1024 رمزًا، ولكنها تتحسن بشكل كبير إلى حوالي 6.5 عند 2048 رمزًا.تُظهر النتائج أن النموذج الأساسي والنماذج المُعدّلة بدقة للسياقات الأقصر تُظهر أنماط أداء متشابهة عبر أطوال سياقاتها القصوى. ويُعدّ أداء نموذج سياق 8k ملفتًا للنظر بشكل خاص - فرغم أن مستوى غموضه أعلى قليلًا في التسلسلات متوسطة الطول (2048 - 4096 رمزًا)، إلا أنه قادر على التعامل مع تسلسلات تصل إلى 8192 رمزًا، ويحقق أدنى مستوى غموض قدره 5.1 عند أقصى طول.بعد أكثر من 4096 رمزًا، يُظهر منحنى الحيرة اتجاهًا هبوطيًا.كما هو موضح في الشكل أدناه.
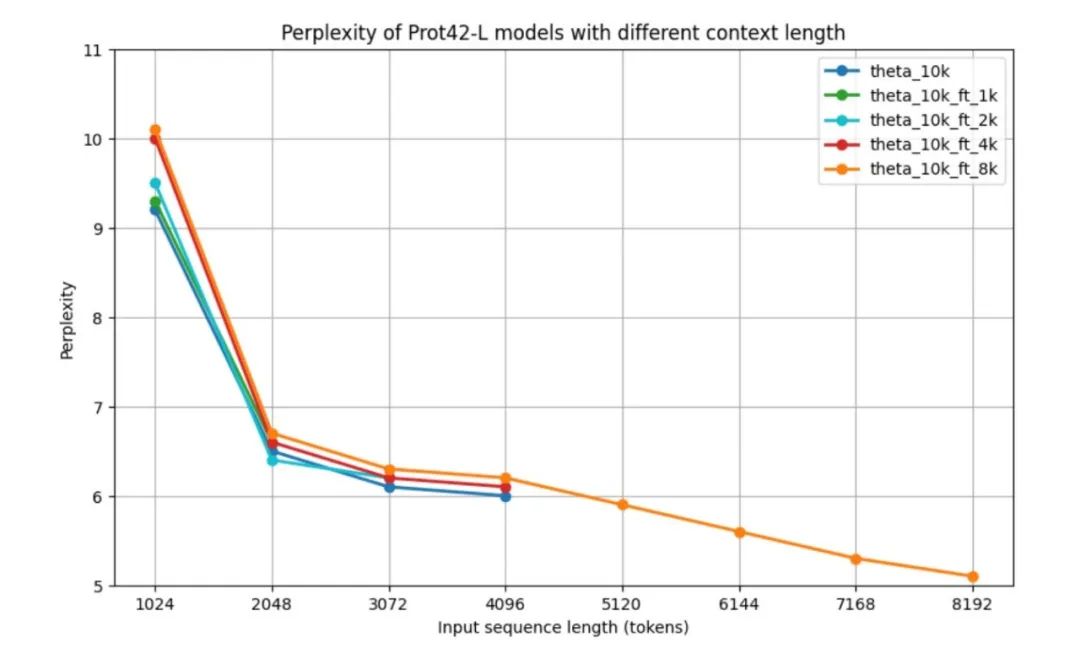
مع زيادة طول السياق، ينخفض PPL للنموذج تدريجيًا، مما يشير إلى أن قدرة النموذج على معالجة التسلسلات الطويلة قد تحسنت بشكل كبير.على وجه الخصوص، يحقق نموذج السياق 8K أدنى مستوى PPL، مما يشير إلى أنه يمكنه الاستفادة بشكل فعال من نافذة السياق الممتدة لالتقاط التبعيات طويلة المدى في تسلسلات البروتين.تُعد نافذة السياق الموسعة تقدمًا كبيرًا في مجال نمذجة تسلسل البروتين، مما يتيح تمثيلًا أكثر دقة للبروتينات المعقدة وتفاعلات البروتين-البروتين، وهو أمر بالغ الأهمية لتوليد روابط بروتينية فعالة.
من خلال سلسلة من التقييمات التجريبية الصارمة،لقد أظهر Prot42 أداءً ممتازًا في العديد من المهام الرئيسية.وقد ثبتت فعاليته في توليد روابط البروتين وتصميم البروتينات المرتبطة بتسلسلات الحمض النووي المحددة.
التنبؤ بوظيفة البروتين
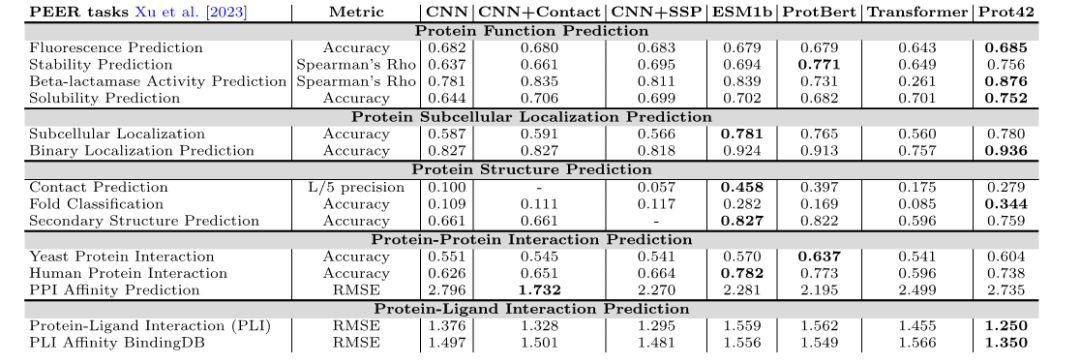
في اختبار PEER القياسي، أظهر نموذج Prot42 أداءً جيدًا في العديد من مهام التنبؤ بوظائف البروتين، بما في ذلك التنبؤ بالفلورسنت، والتنبؤ بالاستقرار، والتنبؤ بنشاط بيتا لاكتاماز، والتنبؤ بالذوبانية. وبالمقارنة مع النماذج الحالية،حقق Prot42 مزايا كبيرة في التنبؤ بالاستقرار والتنبؤ بالذوبان والتنبؤ بنشاط β-lactamase.ويشير هذا إلى إمكاناتها الكبيرة في مهام هندسة البروتين عالية الدقة.
التنبؤ بتوطين البروتين تحت الخلوي
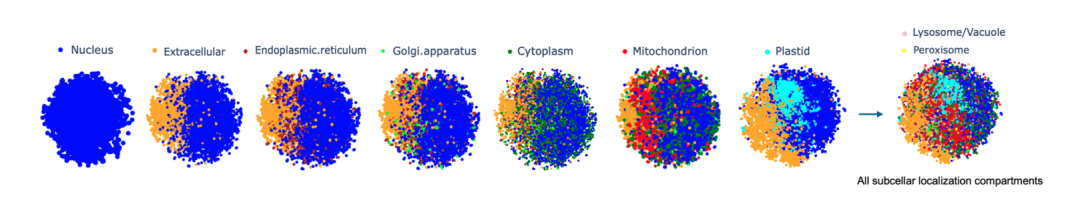
مثّل الباحثون كل تسلسل بروتيني كمتجه عالي الأبعاد بحجم 32×2048، وأدرجوا نموذج Prot42-L في تسلسل البروتين بأكمله، وأجروا حسابات. ولتقييم تمايز الجودة في التضمين والأجزاء بشكل حدسي، طبّق الباحثون تضمين الجوار العشوائي الموزع t (t-SNE) لتقليل الأبعاد، مما جعل تصوّر مجموعات البروتين واضحًا.لقد تم التحقق من أن Prot42 يؤدي بشكل جيد في مهمة التنبؤ بتوطين البروتين الفرعي للخلية، ودقته قابلة للمقارنة مع النماذج المتقدمة الموجودة.ومن خلال التحليل البصري، تمكن فريق البحث من التحقق بشكل أكبر من فعالية نموذج Prot42 في التقاط خصائص التوطين الفرعية للخلايا البروتينية.
التنبؤ ببنية البروتين
في مهمة التنبؤ ببنية البروتين،حقق نموذج Prot42 نتائج ممتازة في التنبؤ بالاتصال، وتصنيف الطي، والتنبؤ بالهيكل الثانوي.تشير هذه النتائج إلى أن نموذج Prot42 قادر على التقاط الاختلافات الدقيقة في بنية البروتين، مما يوفر دعماً قوياً لنمذجة التفاعل البيولوجي المعقد والتطبيقات الصيدلانية.
التنبؤ بالتفاعل بين البروتينات
في مهام التنبؤ بالتفاعل بين البروتينات والتفاعل بين البروتينات والربيطات، أظهر نموذج Prot42 دقة وموثوقية عالية.استخدم الباحثون برنامج Chem42 لتوليد متجهات التضمين الكيميائي وقارنوها ببرنامج ChemBert.كنموذج تمثيل كيميائي آخر، مع ذلك، لا تزال مؤشرات أدائه أفضل من الطرق الحالية، وقريبة من النتائج المحققة باستخدام Chem42. وتحديدًا، عند استخدام Chem42 لتوليد تضمينات كيميائية، تكون نتائج التنبؤ به قريبة من نتائج النماذج الكيميائية الاحترافية.يشير هذا إلى أن Prot42 يتمتع بقدرة جيدة على التوسع في الجمع بين المعلومات الكيميائية.يوفر دعمًا قويًا لتصميم الأدوية.
توليد رابط البروتين
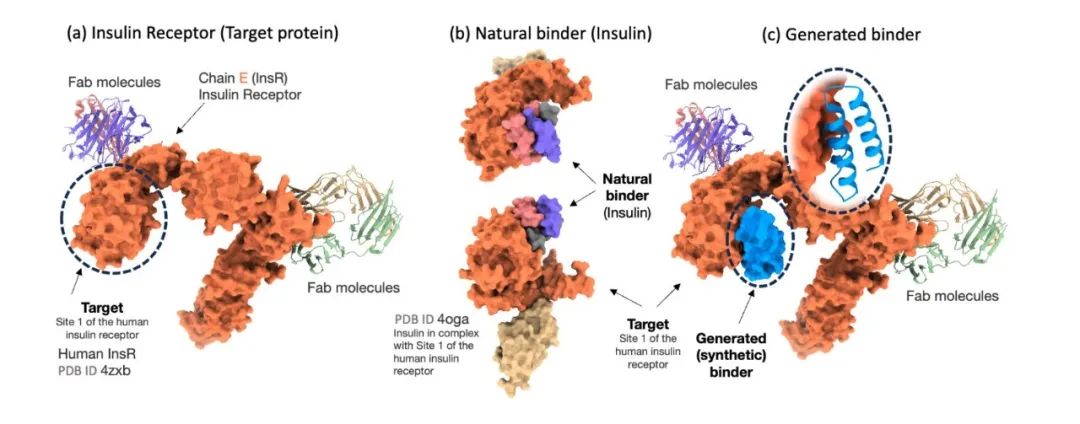
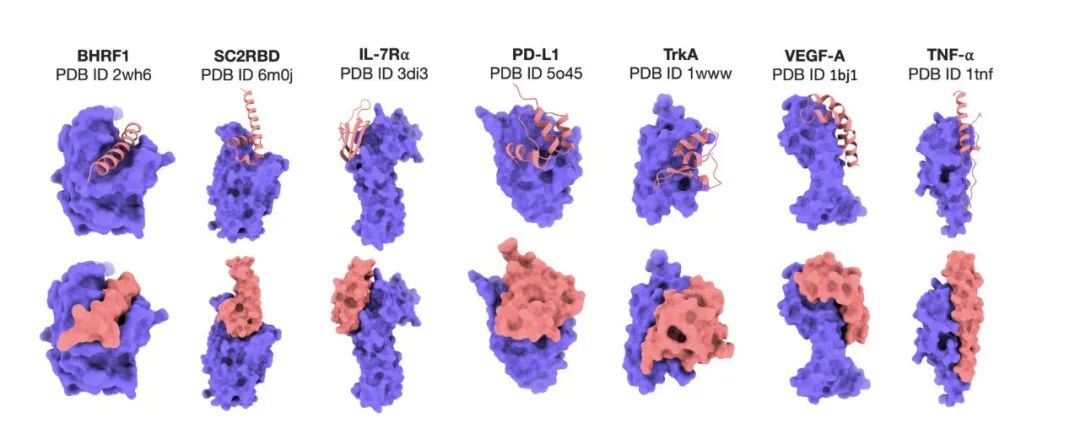
لتقييم فعالية نموذج Prot42 بدقة في توليد روابط البروتين، قارن الباحثون النموذج مع AlphaProteo، وهو نموذج متقدم مصمم خصيصًا للتنبؤ برابط البروتين. أظهرت النتائج التجريبية أنأنتج نموذج Prot42 مواد رابطة ذات تقارب قوي متوقع على أهداف علاجية متعددة.وخاصة على الأهداف مثل IL-7Rα، وPD-L1، وTrkA، وVEGF-A،أظهر نموذج Prot42 أداءً أفضل بشكل ملحوظ من نموذج AlphaProteo.تشير هذه النتائج إلى أن نموذج Prot42 يتمتع بمزايا كبيرة في توليد رابط البروتين، كما هو موضح في الشكل أدناه.
توليد رابط خاص بتسلسل الحمض النووي
في تجربة توليد رابط خاص بتسلسل الحمض النووي، حقق Prot42 أيضًا نتائج ملحوظة. أظهرت النتائج التجريبية أنمن خلال الجمع بين استراتيجية متعددة الوسائط لتضمين الجينات وتضمين البروتين، يصبح نموذج Prot42 قادرًا على توليد بروتينات ترتبط بشكل خاص بتسلسلات الحمض النووي المستهدفة وتظهر تقاربًا عاليًا.كانت خصوصية الارتباط التي قيّمها نموذج DeepPBS عالية. تشير هذه النتائج إلى أن نموذج Prot42 يتمتع بإمكانيات كبيرة في توليد روابط خاصة بتسلسل الحمض النووي، مما يوفر أدوات جديدة لتطبيقات تنظيم الجينات وتحرير الجينوم.
الإنجازات والابتكارات في مجال الذكاء الاصطناعي في تصميم البروتين
مع التكامل العميق بين التكنولوجيا الحيوية والذكاء الاصطناعي، يشهد مجال تصميم البروتينات الرائد تحولات ثورية. وباعتبارها المنفذ الأساسي للأنشطة الحيوية، لطالما كان التحليل البنيوي والوظيفي للبروتينات نقطةً صعبة في البحث العلمي، ويساهم تدخل تقنية الذكاء الاصطناعي في تسريع حل هذا اللغز المعقد، مما يفتح آفاقًا جديدة لسيناريوهات جديدة مثل تطوير أدوية جديدة وتحويل هندسة الإنزيمات.
وفي السنوات الأخيرة، حققت تكنولوجيا الذكاء الاصطناعي اختراقات جديدة، وتعمل التقنيات الجديدة التي تركز على الذكاء الاصطناعي التوليدي على دفع تصميم البروتين إلى مرحلة "التكوين".
اقترح فريق البروفيسور Xu Dong في جامعة ميسوري نموذج البروتين الواعي للبنية واللغة (S-PLM)، والذي يربط تسلسل البروتين ومعلومات البنية ثلاثية الأبعاد في مساحة كامنة موحدة من خلال تقديم التعلم التبايني متعدد الرؤية.نحن نستخدم Swin Transformer لمعالجة المعلومات البنيوية التي يتنبأ بها AlphaFold ودمجها مع التضمين التسلسلي المستند إلى ESM2 لإنشاء PLM مدرك للبنية.نُشرت مقالة "S-PLM: نموذج لغة بروتينية مدرك للبنية عبر التعلم التبايني بين التسلسل والبنية" في مجلة Advanced Science. يدمج S-PLM المعلومات الهيكلية ببراعة في تمثيل التسلسلات من خلال مواءمة تسلسلات البروتين مع هياكلها ثلاثية الأبعاد في مساحة كامنة موحدة. كما يستكشف استراتيجيات ضبط دقيقة فعّالة، مما يُمكّن النموذج من تحقيق أداء ممتاز في مهام التنبؤ المختلفة بالبروتين، مما يُمثل تقدمًا مهمًا في مجال التنبؤ ببنية البروتين ووظائفه.
عنوان الورقة:
https://advanced.onlinelibrary.wiley.com/doi/10.1002/advs.202404212
بالإضافة إلى ذلك، اقترح فريق بحث جامعة تسينغهوا وآخرون نموذجًا موحدًا للغة البروتين xTrimoPGLM، وهو إطار عمل موحد للتدريب المسبق ونموذج أساسي قابل للتوسع ليشمل 100 مليار معلمة، وهو مصمم لمختلف المهام المتعلقة بالبروتينات، بما في ذلك الفهم والتوليد (أو التصميم). باستخدام نموذج اللغة العام (GLM) كأساس لأهدافه ثنائية الاتجاه والانحدار الذاتي، يختلف هذا النموذج عن نماذج لغة البروتين السابقة التي تعتمد على المشفر فقط أو فك التشفير السببي فقط. استكشفت هذه الدراسة الفهم الموحد والتدريب المسبق للتوليد لنماذج لغة البروتين فائقة الحجم، وكشفت عن إمكانيات جديدة لتصميم تسلسلات البروتين، وعززت تطوير مجموعة أوسع من التطبيقات المتعلقة بالبروتينات. نُشرت الدراسة في مجلة Nature الفرعية بعنوان "xTrimoPGLM: محول موحد مُدرّب مسبقًا بـ 100 مليار معلمة لفك شفرة لغة البروتينات".
عنوان الورقة:
https://www.nature.com/articles/s41592-025-02636-z
لا يُعدّ إنجاز Prot42 تقدمًا تقنيًا فحسب، بل يعكس أيضًا النضج التدريجي لنموذج "التصميم القائم على البيانات + الذكاء الاصطناعي" في مجال علوم الحياة. يخطط فريق البحث مستقبلًا للتحقق من الروابط التي يُنتجها Prot42 من خلال التجارب، وتكملة التقييم الحسابي باختبارات وظيفية فعلية. ستعزز هذه الخطوة فائدة النموذج في التطبيقات العملية، وتُحسّن دقته التنبؤية، مما يُسهّل عملية توليد التسلسلات القائمة على الذكاء الاصطناعي والتكنولوجيا الحيوية التجريبية.
مراجع:
1.https://arxiv.org/abs/2504.04453
2.https://mp.weixin.qq.com/s/SDUsXpAc8mONsQPkUx4cvA
3.https://mp.weixin.qq.com/s/x7_Wnws35Qzf3J0kBapBGQ
4.https://mp.weixin.qq.com/s/SDUsXpAc8mONsQPkUx4cvA








