Command Palette
Search for a command to run...
التنبؤ بدقة بمعدل البطالة ومعدل الفقر في الولايات المتحدة. تم توفير نموذج جوجل الأساسي لديناميكيات السكان PDFM كمصدر مفتوح لتعزيز النماذج الجغرافية المكانية الحالية

الأمراض، الأزمات الاقتصادية، البطالة، الكوارث... لقد كان العالم البشري منذ فترة طويلة "مُغزواً" بمشاكل مختلفة.إن فهم ديناميكيات السكان أمر بالغ الأهمية لحل المشاكل الاجتماعية المعقدة مثل هذه.ويستطيع المسؤولون الحكوميون استخدام بيانات ديناميكيات السكان لمحاكاة انتشار الأمراض، والتنبؤ بأسعار المساكن ومعدلات البطالة، وحتى التنبؤ بالأزمات الاقتصادية. ومع ذلك، فإن التنبؤ الدقيق بديناميكيات السكان كان يشكل تحديًا للباحثين وصناع السياسات على مدى العقود القليلة الماضية.
غالبًا ما تعتمد الطرق التقليدية لفهم ديناميكيات السكان على بيانات التعداد السكاني أو المسح أو صور الأقمار الصناعية. ورغم قيمة هذه البيانات، إلا أن لكل منها عيوبها الخاصة. على سبيل المثال، على الرغم من أن التعدادات السكانية شاملة، إلا أنها نادرة ومكلفة لإجرائها؛ يمكن أن توفر المسوحات رؤى محلية ولكنها غالبًا ما تفتقر إلى الحجم والانتشار؛ وتوفر صور الأقمار الصناعية نظرة عامة واسعة النطاق ولكنها تفتقر إلى معلومات مفصلة حول الأنشطة البشرية. ولتعويض هذه العيوب، قامت جوجل ببناء مجموعات بيانات ضخمة على مر السنين على أمل فهم السلوك الديموغرافي.
في الآونة الأخيرة، اقترحت شركة جوجل نموذجًا جديدًا لأساس ديناميكيات السكان (PDFM)، والذي يستخدم التعلم الآلي لدمج البيانات الجغرافية المكانية الغنية المتاحة في جميع أنحاء العالم، مما يؤدي إلى توسيع قدرات النماذج الجغرافية المكانية التقليدية بشكل كبير.قام الباحثون بمقارنة أداء PDFM في الاستيفاء والاستقراء ومشاكل الدقة الفائقة عبر 27 مهمة تغطي الصحة والاقتصاد الاجتماعي والبيئة. توصلت الدراسة إلى أن PDFM حقق أداءً متطورًا في الاستيفاء لجميع المهام الـ 27 وفي 25 من مهام الاستقراء والدقة الفائقة.وأظهر الباحثون أيضًا أنه يمكن دمج PDFM مع نموذج أساسي للتنبؤ متطور (TimesFM) للتنبؤ بنجاح بمعدلات البطالة والفقر، متفوقًا على طرق التنبؤ الخاضعة للإشراف الكامل.
وقد تم نشر البحث ذي الصلة على arXiv تحت عنوان "الاستدلال الجغرافي العام باستخدام نموذج أساس ديناميكيات السكان". وفي الوقت نفسه، أصدر الباحثون جميع تضمينات PDFM وأكواد العينة على GitHub لتسهيل قيام مجتمع البحث بتطبيقها على حالات استخدام جديدة وتمكين البحث والممارسة الأكاديمية بشكل أكبر.
عنوان مشروع PDFM مفتوح المصدر:
https://github.com/google-research/population-dynamic
أبرز الأبحاث:
* قدم الباحثون بنية تضمين منفصلة تقسم بُعد التضمين حسب مصدر البيانات، مما يضمن أن النموذج يمكنه الاهتمام بجميع المدخلات والاحتفاظ بالمعلومات ذات الصلة لكل بيانات، مع توفير إمكانية تفسير مستوى مصدر البيانات للمهام اللاحقة
* أظهر الباحثون كيف يمكن استخدام PDFM لتعزيز TimesFM، وهو نموذج أساسي للتنبؤ متطور، لتحسين توقعات معدلات البطالة على مستوى المقاطعة ومعدلات الفقر على مستوى الرمز البريدي. يمكن أيضًا استخدام طرق مماثلة لتحسين نماذج التصنيف والانحدار الجغرافي المكاني الأخرى الموجودة باستخدام تضمينات PDFM.
* من خلال الأداء القوي في مهام الاستيفاء والاستقراء والدقة الفائقة والتنبؤ، أثبت الباحثون أنه يمكن توسيع PDFM بسهولة ليشمل مجموعة متنوعة من سيناريوهات التطبيق التي تتطلب النمذجة الجغرافية المكانية، بما في ذلك البحث العلمي والرفاهية العامة والصحة العامة والبيئية والمجالات التجارية

عنوان الورقة:
https://arxiv.org/abs/2411.07207
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
مجموعات البيانات: خمس مجموعات بيانات شائعة
لتطوير نموذج بيانات PDFM، جمع الباحثون ونظموا خمس مجموعات بيانات كبيرة تغطي المناطق الجغرافية على مستوى الرمز البريدي والمقاطعات:
① اتجاهات البحث المجمعة:قام الباحثون بحساب الأعداد الإجمالية لأول 500 استعلام في يوليو 2022، الأمر الذي تطلب ما لا يقل عن 20 عملية بحث في كل منطقة رمز بريدي، مما أدى إلى أكثر من مليون استعلام فريد. تم بعد ذلك تصنيف هذه الاستعلامات حسب الشعبية الوطنية، والتي تم قياسها من خلال العدد الإجمالي للرموز البريدية التي ظهر فيها كل استعلام، والتي تم من خلالها اختيار أفضل 1000 استعلام شائع كممثل لنشاط اتجاه البحث الإجمالي على مستوى الرمز البريدي في جميع أنحاء البلاد.
② مجموعة بيانات الخريطة (الخرائط):قام الباحثون باختيار 1192 فئة من النقاط المثيرة للاهتمام الأكثر شيوعًا في خرائط Google في مايو 2024 والتي ظهرت في الرمز البريدي 5% على الأقل. تغطي كل فئة مجموعة واسعة من المواقع ذات الأهمية؛ على سبيل المثال، تشمل فئة "المرافق الطبية" مستشفيات الأطفال والمستشفيات الجامعية. ثم قامت بحساب العدد الإجمالي للمرافق المتاحة ضمن كل حدود جغرافية وأنشأت متجه ميزات طبيعيًا مكونًا من 1192 بُعدًا على مستوى الرمز البريدي والمقاطعة.
③ مجموعة بيانات الانشغال:بالنسبة لكل فئة من فئات نقاط الاهتمام في بيانات الخريطة، قام الباحثون بحساب مجموع الزيارات إلى الأماكن ذات الصلة في هذه الفئات خلال شهر واحد لتلخيص انشغال هذه الفئات.
④ الطقس وجودة الهواء:قام الباحثون بجمع بيانات الطقس وجودة الهواء وتلخيص البيانات الساعية لشهر يوليو 2022، ووصفوها باستخدام القيم المتوسطة والدنيا والقصوى. تتضمن القائمة الكاملة للمتغيرات: متوسط ضغط مستوى سطح البحر، إجمالي الغطاء السحابي، مكون الرياح U عند 10 أمتار، مكون الرياح V عند 10 أمتار، درجة الحرارة عند 2 متر، درجة حرارة نقطة الندى عند 2 متر، الإشعاع الشمسي، معدل هطول الأمطار الإجمالي، مؤشر جودة الهواء، تركيز أول أكسيد الكربون، تركيز ثاني أكسيد النيتروجين، تركيز الأوزون، تركيز ثاني أكسيد الكبريت، تركيز الجسيمات القابلة للاستنشاق (<10 ميكرومتر)، تركيز الجسيمات الدقيقة (<2.5 ميكرومتر).
⑤ الاستشعار عن بعد:قام الباحثون بدمج بيانات تضمين صور الأقمار الصناعية المولدة من إصدار ViT16-L40 من نموذج SatCLIP للحصول على تضمينات مفهرسة بواسطة مركز كل رمز بريدي. تم تصميم نموذج SatCLIP ليكون مشفرًا جغرافيًا قابلًا للاستخدام عالميًا ويجمع 100000 بلاطة من صور القمر الصناعي Sentinel-2 من 1 يناير 2021 إلى 17 مايو 2023.
قام الباحثون بدمج مجموعة البيانات مع بنية الشبكة العصبية الرسومية (GNN) لتدريب نموذج أساسي يولد تضمينات عامة بدلاً من تضمينات خاصة بمهمة معينة.
هندسة النموذج: استخدام GNN لحل المشكلات الجغرافية المكانية بكفاءة وبديهية
يظهر بناء نموذج PDFM في الشكل أدناه: في المرحلة 1،قام الباحثون بدمج مجموعة البيانات مع بنية الشبكة العصبية الرسومية (GNN) لتدريب نموذج أساسي يولد تضمينات عامة بدلاً من تضمينات خاصة بمهمة معينة.في المرحلة الثانية،باستخدام هذه التضمينات وبيانات الحقائق الأساسية المحددة للمهمة المطروحة، يتم تعلم نموذج لاحق (مثل الانحدار الخطي، أو الإدراك البسيط متعدد الطبقات، أو شجرة القرار المعززة بالتدرج)، والذي يمكن تطبيقه على مجموعة متنوعة من المهام بما في ذلك الاستيفاء، والاستقراء، والدقة الفائقة، والتنبؤ.
* مهمة الاستيفاء: تشير إلى استنتاج وملء قيم نقاط البيانات غير المعروفة بناءً على قيم نقاط البيانات المعروفة
* مهام الاستقراء: استقراء البيانات أو الخبرة الموجودة للتنبؤ بالمواقف أو الاتجاهات أو النتائج التي تتجاوز النطاق المعروف الحالي
* مهمة فائقة الدقة: تشير إلى عملية ترقية الصور أو البيانات منخفضة الدقة إلى دقة عالية من خلال الخوارزميات
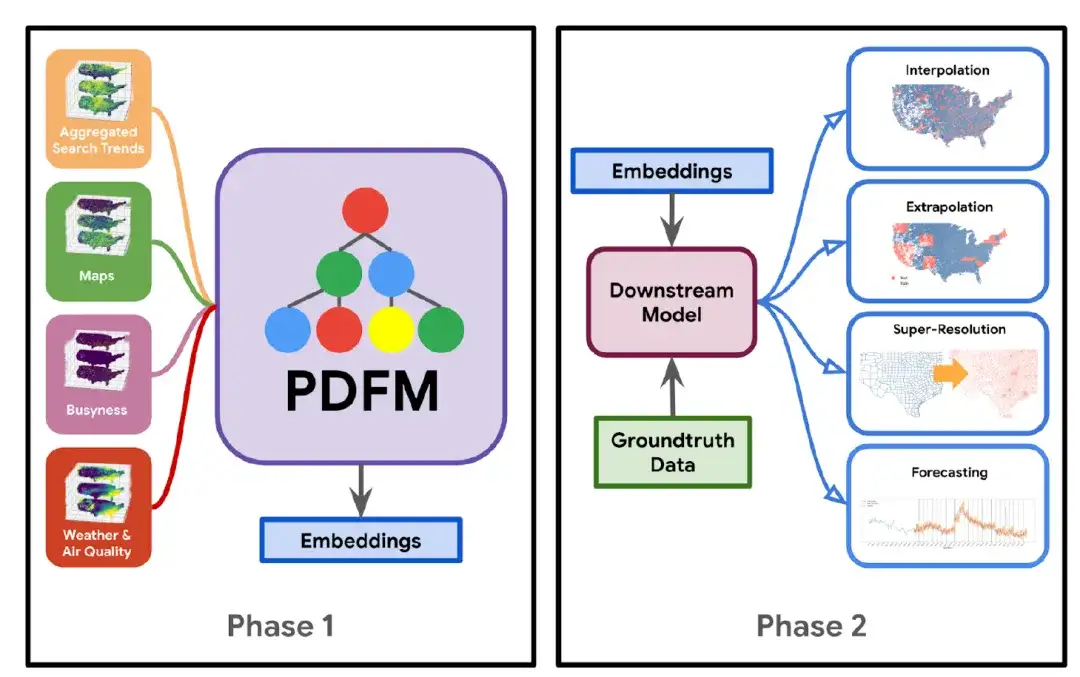
على وجه التحديد، فإن جوهر نموذج PDFM هو الشبكة العصبية الرسومية (GNN)، والتي تقوم بتشفير تضمينات المواضع في متجهات رقمية منخفضة الأبعاد غنية بالمعلومات. وهو يتكون بشكل أساسي من الأجزاء الخمسة التالية:
* بناء الرسم البياني:قام الباحثون ببناء رسم بياني جغرافي غير متجانس باستخدام المقاطعات والرموز البريدية كعقد وإنشاء حواف من خلال علاقات الجوار. يحتوي الرسم البياني الجغرافي المكاني الذي تم إنشاؤه على مجموعة متجانسة من العقد، مع التعامل مع عقد الرمز البريدي ومستوى المقاطعة على أنها نفس نوع مجموعة العقد، ومجموعة غير متجانسة من الحواف، مع أنواع مختلفة من الحواف التي تربط العقد.
* أخذ العينات من الصورة الفرعية:يتم إجراء أخذ العينات من الرسم البياني الفرعي لإنشاء رسوم بيانية فرعية لتدريب شبكات GNN واسعة النطاق وإضافة العشوائية إلى النموذج. يبدأ من عقدة بذرة، ويمر عبر كل مجموعة حواف بطريقة العرض أولاً، ويأخذ عينات من عدد ثابت من العقد بطريقة مرجحة، وينتهي عندما يصل إلى أربع قفزات.
على وجه التحديد، بدأ الباحثون من عقدة بذرة، ومروا بكل مجموعة حواف بطريقة العرض أولاً، وأخذوا عينات من عدد ثابت من العقد بطريقة مرجحة، وانتهوا عند الوصول إلى مسافة القفزات الأربع. يؤدي هذا النهج إلى إنشاء عدد من الرسوم البيانية الفرعية يساوي العدد الإجمالي لعقد الرمز البريدي ومستوى المقاطعة.
* المعالجة المسبقة:يتم تطبيق التطبيع على مستوى العمود على جميع الميزات، ويتم ضغط الأطراف القصوى لنطاق قيمة الميزة عن طريق القطع.
* تفاصيل النمذجة والتدريب:تم اعتماد GraphSAGE (طريقة استقرائية) لتعلم تضمينات العقد من خلال الاستفادة من معلومات ميزات العقدة. يتعلم GraphSAGE وظيفة لإنشاء تضمينات من معلومات التجميع المحلية. بالنسبة لهندسة التجميع، يتم استخدام هندسة التجميع المقترحة في GraphSAGE، حيث يتم تمرير حالات العقد من العقد المجاورة عبر طبقة متصلة بالكامل باستخدام تحويل ReLU، ويتم تجميع الحالات القديمة المحولة وحالات العقد المجاورة بشكل أكبر عن طريق الجمع حسب العنصر. استخدم الباحثون بنية GraphSAGE لتسهيل تمرير الرسائل دفعة واحدة، وذلك بإضافة طبقة خطية بحجم 330 بعد طبقة GNN لتشفير التمثيل على مستوى العقدة في تضمين مضغوط.
* ضبط المعلمات الفائقة:يتم أخذ عينات موحدة من مجموعة التحقق من صحة العقد من العقد البذرية لـ 20% (بما في ذلك المقاطعات والرموز البريدية) لتشكيل معلمات الضبط الفائقة، بما في ذلك معدل التسرب، وحجم تضمينات العقد، وعدد وحدات وطبقات GraphSAGE المخفية، وحجم التضمين، والتسوية، ومعدل التعلم.
نتائج البحث: أداء قوي في مهام الاستيفاء والاستقراء والدقة الفائقة والتنبؤ
PDFM هو إطار عمل مرن للنمذجة الأساسية يمكنه معالجة مجموعة متنوعة من التحديات الجغرافية المكانية داخل الولايات المتحدة القارية. من خلال دمج مجموعات البيانات المتنوعة، تم دمج PDFM في 27 مهمة صحية واجتماعية واقتصادية وبيئية، متجاوزًا بذلك طرق ترميز الموقع الحديثة (SoTA) الحالية مثل SatCLIP وGeoCLIP.
في مهام الاستيفاء، يعمل PDFM بشكل جيد في جميع المهام الـ 27؛ في مهام الاستقراء والدقة الفائقة، يتقدم في 25 مهمة. بالإضافة إلى ذلك، أظهر الباحثون كيف يمكن لعمليات تضمين PDFM تعزيز أداء نماذج التنبؤ مثل TimesFM، وبالتالي تحسين التنبؤات بالمؤشرات الاجتماعية والاقتصادية المهمة مثل معدلات البطالة على مستوى المقاطعة ومعدلات الفقر على مستوى الرمز البريدي.ويسلط هذا الضوء على إمكانات تطبيقه الواسعة في الأبحاث والرعاية الاجتماعية والصحة العامة والبيئية والأعمال التجارية.
النتائج التجريبية المحددة هي كما يلي:
① تجربة الاستيفاء
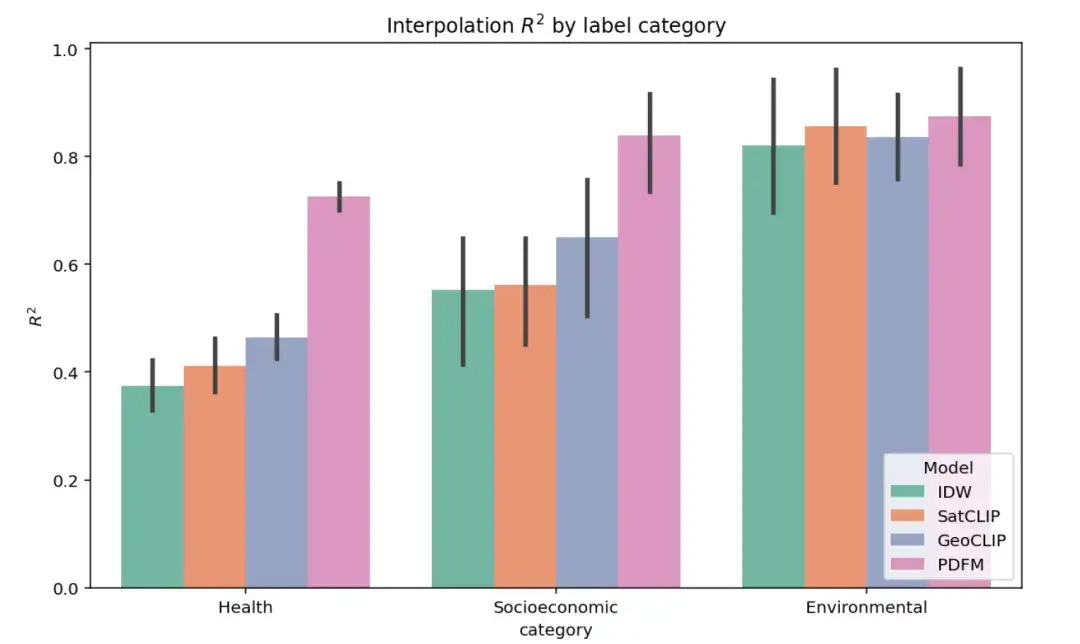
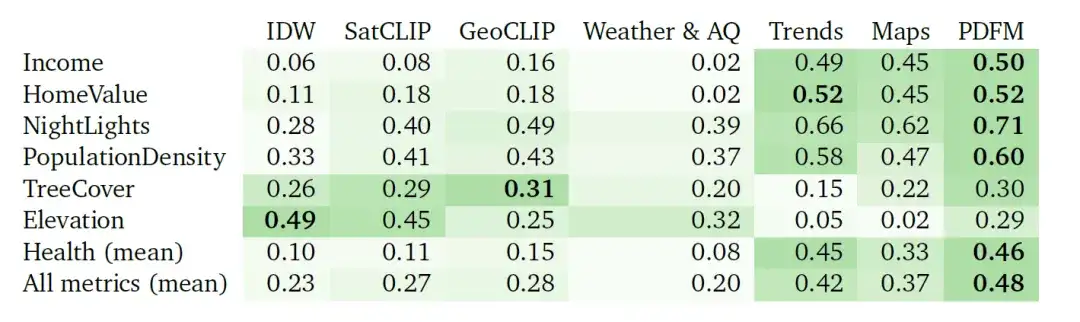
يوضح الشكل أدناه نتائج تجربة الاستيفاء الكاملة لـ 27 مهمة في ثلاث فئات: الصحة، والفئة الاجتماعية والاقتصادية، والبيئة. يتم تقييم أداء النماذج المختلفة باستخدام المؤشر ² (تشير القيمة الأعلى إلى أن النموذج يفسر بشكل أفضل تباين تسمية المتغير المستهدف). كما هو موضح في الشكل، يتفوق PDFM بشكل كبير على SatCLIP وGeoCLIP في فئات المهام الاجتماعية والاقتصادية والصحية.
يوضح الجدول أدناه مدى جودة استيفاء PDFM عبر 27 مهمة صحية واجتماعية واقتصادية وبيئية، مثل الدخل، وقيمة المنزل، والأضواء الليلية، وكثافة السكان، والغطاء الشجري، والارتفاع، والصحة (المتوسط). يتفوق PDFM باستمرار، بمتوسط 0.83 مربع عبر جميع المهام الـ 27، بما في ذلك متوسط 0.73 مربع لـ 21 مهمة متعلقة بالصحة.
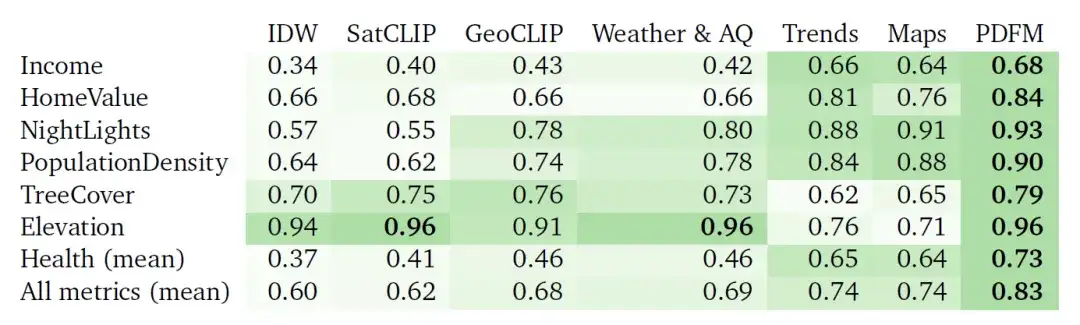
الجدول: نتائج الاستيفاء² (القيم الأعلى أفضل). تقوم التجارب بمقارنة أداء الاستيفاء القائم على المسافة العكسية المرجحة (IDW)، وتضمين SatCLIP، وتضمين GeoCLIP، وتضمين PDFM ومكوناتها الفرعية (الطقس وجودة الهواء، واتجاهات البحث المجمعة، والخرائط والانشغال)، باستخدام GBDT كنموذج لاحق.
② تجربة الاستقراء
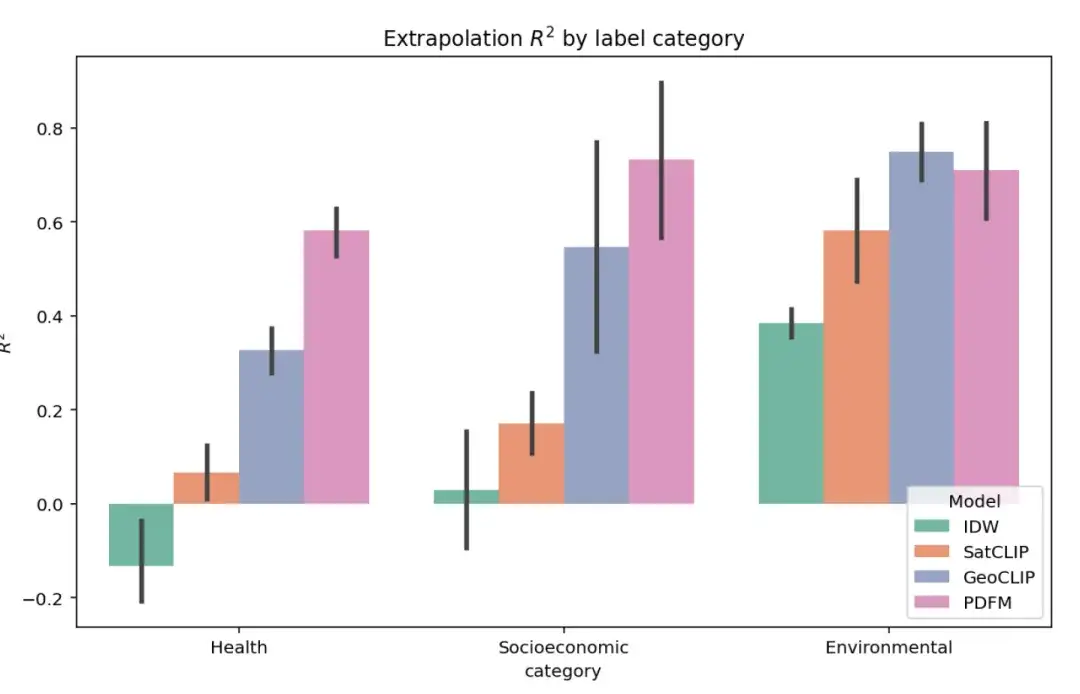
يوضح الشكل أدناه نتائج تجربة الاستقراء الكاملة لـ 27 مهمة في ثلاث فئات: الصحة، والفئة الاجتماعية والاقتصادية، والبيئة. يتم تقييم أداء النموذج أيضًا باستخدام المؤشر ². وكما هو موضح في الشكل، وعلى الرغم من أن GeoCLIP يتمتع بميزة طفيفة في التعامل مع المهمة البيئية، فإن PDFM يتفوق بشكل كبير على جميع النماذج الأساسية الأخرى في التنبؤ بالمتغيرات الصحية والاجتماعية والاقتصادية.
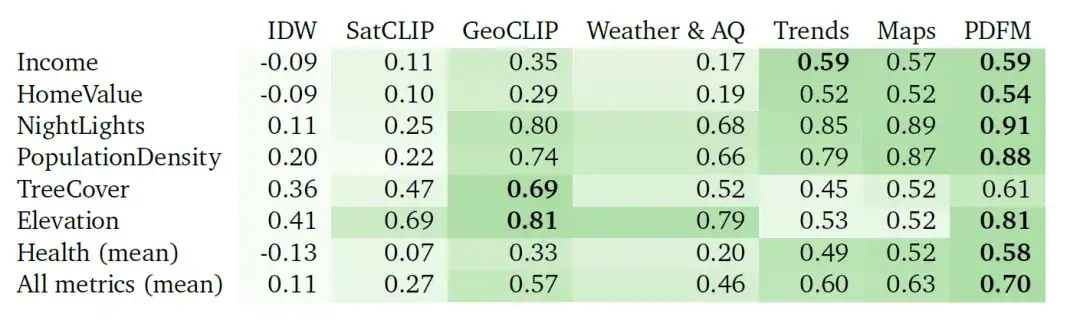
إن مهمة الاستقراء تشكل تحديًا كبيرًا بسبب النقص الكبير في البيانات المصنفة. في هذه الحالة، يظهر PDFM أداءً ممتازًا، كما هو موضح في الجدول أدناه، بمتوسط مربع قدره 0.70 على جميع المقاييس و0.58 على المقاييس المتعلقة بالصحة. باستخدام الصور ذات العلامات الجغرافية، يعمل GeoCLIP بشكل جيد في التنبؤ بغطاء الأشجار (TreeCover)، حيث يحقق ² =0.69، متجاوزًا PDFM وأي نمط فردي. ومع ذلك، بشكل عام، يتفوق نموذج PDFM على النموذج الأساسي في 25 مهمة من أصل 27 مهمة، مما يسلط الضوء على فعاليته في سيناريوهات الاستقراء.
③ تجربة فائقة الدقة
يوضح الشكل أدناه النتائج الكاملة للتجربة فائقة الدقة لـ 27 مهمة، مجمعة حسب الصحة والفئة الاجتماعية والاقتصادية والبيئة، باستخدام متوسط معامل ارتباط بيرسون (r) داخل المقاطعة كمقياس (تشير القيم الأعلى إلى أن تنبؤات النموذج أكثر ارتباطًا بالعلامات الحقيقية على مستوى الرمز البريدي).
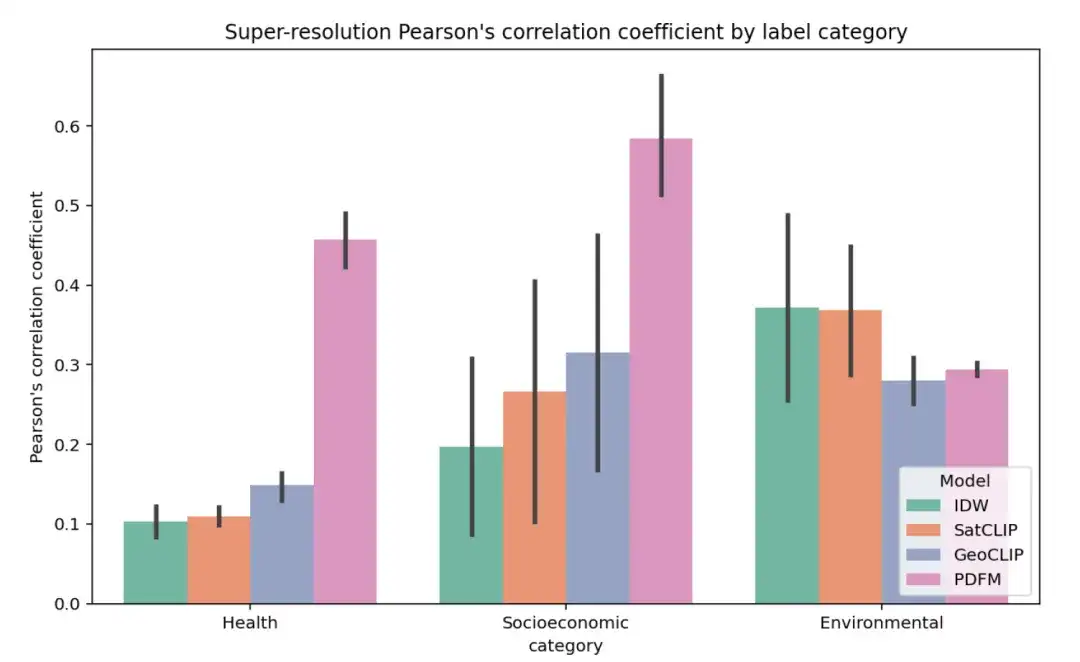
تعتبر مهمة الدقة الفائقة أكثر صعوبة. وقد تم تلخيص النتائج في الجدول أدناه. يحقق IDW أفضل أداء في مهمة الارتفاع، بينما يحقق GeoCLIP أفضل أداء في مهمة غطاء الأشجار. بشكل عام، تفوق PDFM في 25 من أصل 27 مهمة، بمتوسط معامل ارتباط بيرسون بلغ 0.48.
④ مهمة التنبؤ
قام الباحثون أيضًا بتقييم فعالية استخدام تضمينات PDFM لتصحيح أخطاء التنبؤ في TimesFM (نموذج أساسي للتنبؤ أحادي المتغير العام)، بهدف رئيسي يتمثل في تقييم تحسين هذه التضمينات في آفاق زمنية مستقبلية (توقعات معدل البطالة لمدة 6 أشهر وتوقعات معدل الفقر لمدة عامين). تظهر النتائج في الجدول أدناه أن النموذج المدمج مع تضمين PDFM يتجاوز الأداء الأساسي لـ TimesFM من حيث مقياس MAPE وهو أيضًا أفضل من ARIMA - وهذا يوضح أن تضمين PDFM يمكن أن يعزز بشكل كبير تأثير التنبؤ لـ TimesFM.
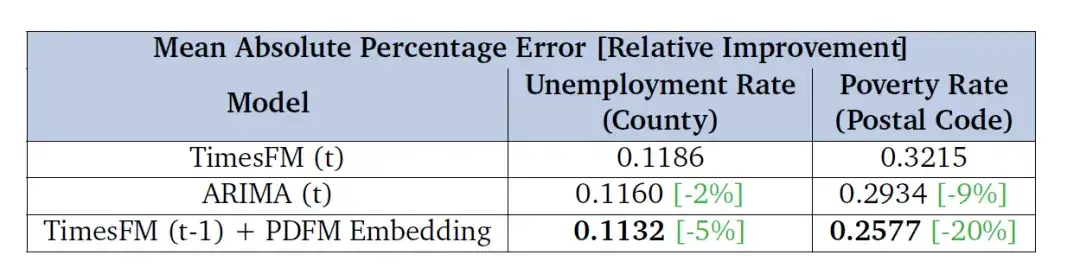
قام الباحثون بتقييم الأداء على أساس معدلات البطالة على مستوى المقاطعات ومعدلات الفقر على مستوى الرمز البريدي في الولايات المتحدة وعرضوا متوسط الخطأ المطلق النسبي (MAPE) في الجدول، حيث تشير القيم المنخفضة إلى أداء أفضل.
الذكاء الاصطناعي الجغرافي المكاني (GeoAI) يزدهر
يمكن اعتبار ميلاد نموذج PDFM بمثابة استكشاف آخر متعمق واستخدام للبيانات الجغرافية المكانية. تشير البيانات الجغرافية المكانية إلى كميات كبيرة من البيانات المكانية الزمنية التي تم جمعها من العديد من المصادر المختلفة بتنسيقات مختلفة. يمكن أن يشمل ذلك بيانات التعداد السكاني، وصور الأقمار الصناعية، وبيانات الطقس، وبيانات الهاتف المحمول، والصور المرسومة على الخرائط، وبيانات وسائل التواصل الاجتماعي. إن تبادل البيانات الجغرافية المكانية وتحليلها واستخدامها بطريقة علمية يمكن أن يوفر العديد من الأفكار المفيدة حول تطور المجتمع البشري، مثل التنبؤ بمعدلات البطالة، وأسعار المساكن، ومحاكاة تأثير دواء معين أو هجرة السكان بعد الكارثة.
ومع ذلك، فإن كيفية معالجة كميات هائلة من البيانات الجغرافية المكانية بشكل فعال تشكل تحديًا.مع ظهور نماذج الشبكات العصبية الاصطناعية، ظهر مفهوم الذكاء الاصطناعي الجغرافي المكاني (GeoAI)، كما قامت الصناعة أيضًا بالعديد من الاستكشافات في هذا الصدد.
على سبيل المثال، في أبريل 2024، من أجل تحسين قابلية تفسير نماذج التنبؤ بالتعدين وعدم الثبات المكاني الناجم عن العوامل الجيولوجية في عملية التعدين، اقترح فريق بحثي من جامعة تشجيانغ طريقة ذكاء اصطناعي جغرافية مكانية جديدة - الانحدار اللوجستي المرجح بالشبكة العصبية الجغرافية (GNNWLR). يدمج النموذج الأنماط المكانية والشبكات العصبية، وعند دمجه مع نظرية التفسير الإضافي لشابلي، فإنه لا يمكنه تحسين دقة التوقعات بشكل كبير فحسب، بل يمكنه أيضًا تحسين إمكانية تفسير التنبؤات المعدنية في السيناريوهات المكانية المعقدة.
في يونيو 2024، نشر باحثون من مختبر نظم المعلومات الجغرافية بجامعة تشجيانغ ورقة بحثية بعنوان "نموذج الشبكة العصبية لتحسين مقياس القرب المكاني في نهج الانحدار المرجح جغرافيًا: دراسة حالة حول أسعار المساكن في ووهان" في المجلة الدولية لعلوم المعلومات الجغرافية، وهي مجلة معروفة في مجال علوم المعلومات الجغرافية. لقد قدموا بطريقة مبتكرة طريقة الشبكة العصبية لربط مقاييس القرب المكاني المتعددة بشكل غير خطي (مثل المسافة الإقليدية، ووقت السفر، وما إلى ذلك) بين نقاط المراقبة للحصول على مقياس قرب مكاني محسن (OSP)، وبالتالي تحسين دقة تنبؤات النموذج بشأن أسعار المساكن. ومن خلال دراسة مجموعات البيانات المحاكاة والحالات التجريبية لأسعار المساكن في ووهان، ثبت أن النموذج المقترح في الورقة البحثية يتمتع بأداء عالمي أفضل ويمكنه وصف العمليات المكانية المعقدة والظواهر الجغرافية بدقة أكبر.
انقر هنا لمشاهدة التقرير المفصل: التنبؤ الدقيق بأسعار المساكن في ووهان! اقترح مختبر نظم المعلومات الجغرافية بجامعة تشجيانغ نموذج osp-GNNWR: وصف دقيق للعمليات المكانية المعقدة والظواهر الجغرافية
في المستقبل، مع التطوير المستمر لتكنولوجيا الذكاء الاصطناعي، ستتمتع صناعة المعلومات الجغرافية بأساس تقني أكثر صلابة وأدوات تطوير أكثر ملاءمة، وبالتالي دفع البشرية إلى عصر الذكاء المكاني الجغرافي.
مراجع:
1.https://arxiv.org/abs/2411.07207
2.https://research.google/blog/insights-into-population-dynamics-a-foundation-model-for-geospatial-inference/
3.https://www.ibm.com/cn-zh/topics/geospatial-data
4.https://mp.weixin.qq.com/s/eQz5N-cFTtGIkDk7IqMZxA
5.https://www.xinhuanet.com/science/2








