Command Palette
Search for a command to run...
تم تحسين الحساسية بواسطة 56%، واقترح CUHK/Fudan/Yale وآخرون بشكل مشترك طريقة جديدة للكشف عن نظائر البروتين

البروتين هو الأساس المادي للحياة والناقل الرئيسي للأنشطة الحيوية. في عصر ما بعد الجينوم، ومع تطور تكنولوجيا تحديد البروتين، ازداد حجم قواعد بيانات تسلسل البروتين بشكل كبير. من أجل الحصول على فهم أعمق لتنوع ووظائف البروتينات، فإن تحديد البروتين مهم بشكل خاص في علم الأحياء.
في عملية التعرف على البروتين، يعد تحديد تشابه تسلسل البروتين أحد أهم المهام.ويمكن أن يساعد العلماء على فهم العلاقات التطورية والخصائص البنيوية ووظائف البروتينات. على الرغم من أن طرق محاذاة تسلسل البروتين التقليدية تعمل بشكل جيد في العديد من الحالات، إلا أنها غير قادرة على التعامل مع نظائر بعيدة. غالبًا ما يتم تجاهل هذه المتماثلات البعيدة في المحاذاة الروتينية بسبب تشابه تسلسلها المنخفض، مما يحد من فهم الباحثين الشامل لتنوع البروتين وتعقيده.
ولحل نقاط الألم في أبحاث التشابه البروتيني البعيد، استنادًا إلى نماذج لغة البروتين وتكنولوجيا الاسترجاع الكثيف، اقترح لي يو من الجامعة الصينية في هونج كونج، بالتعاون مع صن سي تشي، وهو باحث شاب من مختبر الأنظمة المعقدة الذكية في جامعة فودان ومختبر الذكاء الاصطناعي في شنغهاي، ومارك جيرستين من جامعة ييل، إطار عمل للكشف عن التشابه فائق السرعة والحساسية - جهاز الاسترجاع الكثيف للتشابه (DHR).
يمكن لـ DHR تحديد نظائر بعيدة مخفية عميقًا في التسلسل دون الاعتماد على محاذاة التسلسل التقليدية، من خلال القدرات القوية لهيكل المشفر المزدوج ونموذج لغة البروتين، مما يوفر سرعة وحساسية غير مسبوقة لتحديد النظائر. نُشر البحث في المجلة العالمية الشهيرة Nature Biotechnology تحت عنوان "الكشف السريع والحساس عن نظائر البروتين باستخدام الاسترجاع الكثيف العميق".
أبرز الأبحاث:
* بالمقارنة مع الطرق السابقة، تعمل تقنية DHR على تحسين الحساسية بأكثر من 10% وتحسن الحساسية بأكثر من 56% على مستوى العائلة الفرعية للعينات التي يصعب تحديدها باستخدام الطرق القائمة على المحاذاة
* استعلامات كود DHR التسلسلية وقواعد البيانات أسرع بـ 22 مرة من الطرق التقليدية مثل PSI-BLAST وDIAMOND، وأسرع بـ 28700 مرة من HMMER

عنوان الورقة:
https://doi.org/10.1038/s41587-024-02353-6
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
إنشاء مجموعات البيانات في أبعاد متعددة لاستكشاف مجموعة أوسع من تسلسلات البروتين
تتضمن مجموعة التدريب التي تم إنشاؤها في هذه الدراسة 2 مليون تسلسل استعلام تم اختيارها بعناية من UR90.باستخدام خوارزمية JackHMMER، بحثت هذه الدراسة بشكل متكرر عن تسلسلات مرشحة في Uni-Clust30 وقامت بمحاذاة التسلسلات المرشحة مع محاذاة التسلسلات المتعددة (MSA). احتوى كل MSA على 1000 نظير، مما يضمن الاحتفاظ فقط بالتسلسلات الأكثر ارتباطًا. بعد الفحص الدقيق، تم إعادة نشر JackHMMER لمعالجة التسلسلات المختلفة التي تم الحصول عليها واستخدام نفس إعدادات المعلمات الفائقة مثل AF2 (AlphaFold 2) لتسهيل المقارنة العادلة.
في دراسة مجموعات البيانات الكبيرة، اختارت الدراسة مجموعة بيانات BFD/MGnify.إنها قاعدة بيانات ضخمة تحتوي على حوالي 300 مليون بروتين، مما يتيح استكشاف مجموعة أوسع من تسلسلات البروتين.
طريقة DHR: خط أنابيب بحث عن التشابه البروتيني فائق السرعة والحساسية
الفكرة الأساسية لطريقة DHR هي ترميز تسلسلات البروتين في متجهات تضمين كثيفة بحيث يمكن حساب التشابه بين التسلسلات بشكل فعال.على وجه التحديد، قامت هذه الدراسة بتدريب مشفر التسلسل بشكل فعال من خلال تهيئة ESM ودمج تقنيات التعلم التبايني، وبالتالي خلق الظروف لبناء نموذج لغة البروتين وتمكين استخدام DHR بشكل أكثر فعالية لاسترجاع المتماثلات.
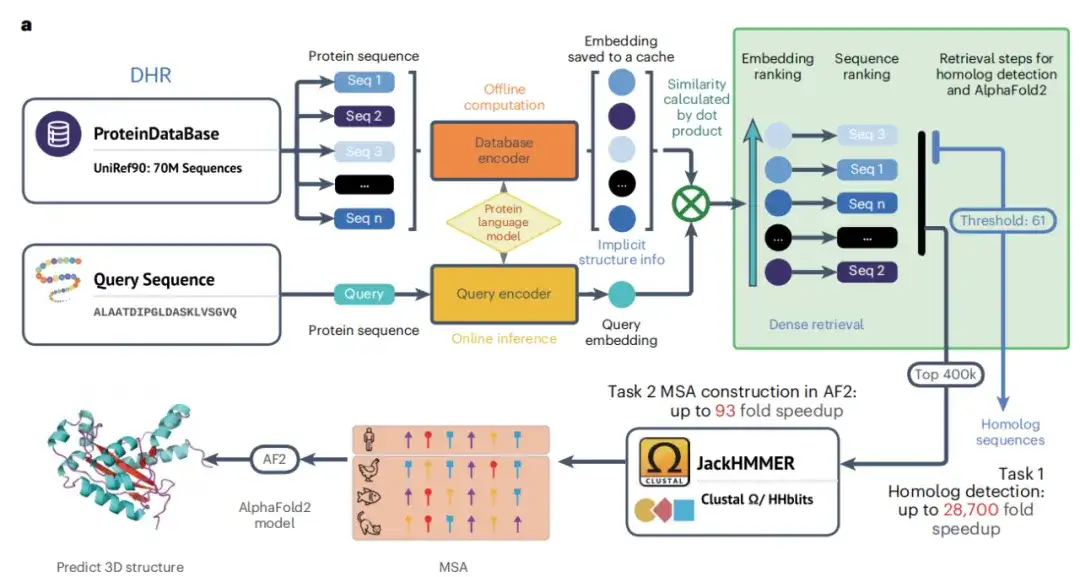
كما هو موضح في الشكل أ أدناه، مع اكتمال مرحلة تدريب المشفر المزدوج، أصبحت الدراسة قادرة على توليد تضمينات تسلسل بروتيني عالية الجودة غير متصلة بالإنترنت. ثم استخدمت الدراسة هذه التضمينات وخوارزميات البحث عن التشابه لاسترجاع نظائر لكل بروتين استعلام. من خلال تحديد التشابه كمقياس استرجاع، يمكن العثور على البروتينات المتشابهة بدقة أكبر من الطرق التقليدية، ويمكن استخدام التشابه بين بروتينين لمزيد من التحليل. أخيرًا، قام JackHMMER ببناء MSA للنظائر المسترجعة، وحصلت الدراسة على تقنية DHR التي يمكنها اكتشاف النظائر بسرعة وفعالية.
ولم يقتصر الأمر على ذلك فحسب، بل طورت الدراسة أيضًا نموذجًا هجينًا DHR-meta، والذي تفوق على خطوط الأنابيب الفردية على أهداف CASP13DM (تسلسل المجال) وCASP14DM من خلال الجمع بين DHR وAF2 الافتراضي.
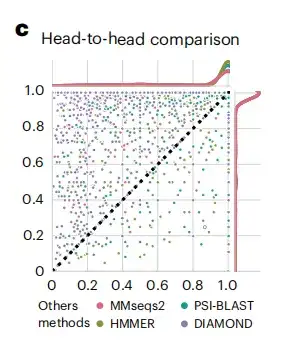
بعد الحصول على تضمينات البروتين الناتجة، قامت الدراسة بتقييم أداء DHR من خلال مقارنتها بالطرق الموجودة في مجموعة البيانات القياسية SCOPe (تصنيف بنية البروتينات).كما هو موضح في الشكل ج أدناه، فإن حساسية بيانات DHR أفضل من الطرق الأخرى.
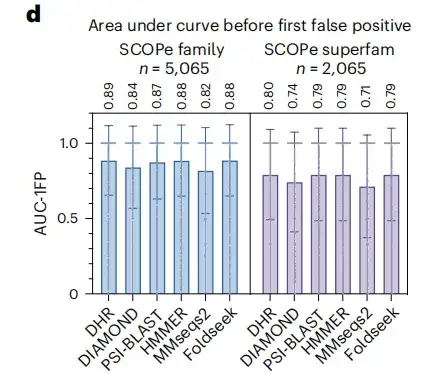
بالإضافة إلى ذلك، كما هو موضح في الشكل h أدناه، في المثال المحدد لاستعلام d1w0ha، لم يتطابق PSI-BLAST ولا MMseqs2 مع أي نتائج، لكن DHR استعاد 5 متماثلات، والتي تم تصنيفها أيضًا في نفس العائلة مثل d1w0ha في SCOPe. وهذا يعني أن DHR يمكنه التقاط المزيد من المعلومات الهيكلية. وبالمقارنة بالطرق التقليدية مثل PSI-BLAST، وMMseqs2، وDIAMOND، وHMMER، فقد اكتشف DHR أكبر عدد من المتماثلات (حساسية 93%).يوضح هذا أن DHR قادر على دمج المعلومات الهيكلية الغنية وتحقيق حساسية بنسبة 100% في العديد من الحالات.
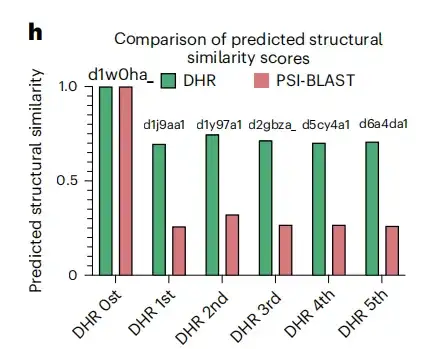
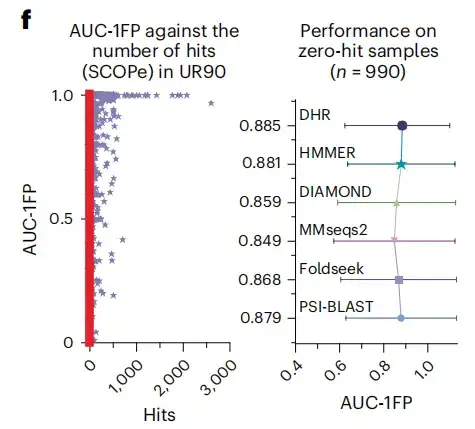
ولتعزيز مصداقية النتائج، تضمنت هذه الدراسة أيضًا مؤشرًا قياسيًا آخر، وهو المساحة تحت المنحنى قبل التخطيط الأسري الأول. وتظهر النتائج أنه كما هو موضح في الشكل (د) أدناه، فإن DHR يحقق درجة 89%.وفي الوقت نفسه، أظهرت طرق أخرى أيضًا أداءً مماثلاً لـ DHR، ولكن وقت تنفيذها كان أطول بشكل ملحوظ.عندما انتقلنا إلى مستوى العائلة الفائقة لتحليل مجموعة أكثر تحديًا من النظائر البعيدة، شهدت جميع الطرق انخفاضًا كبيرًا في الأداء، مع انخفاض إجمالي يبلغ حوالي 10%. وعلى الرغم من ذلك، لا يزال DHR يحافظ على أدائه الرائد بدرجة AUC-1FP تصل إلى 80%.
ووجدت الدراسة أيضًا أنه عند استخدام BLAST لمقارنة قاعدة بيانات SCOPe وUniRef90، أنتجت معظم العينات أقل من 100 تطابق، وحتى حوالي 500 عينة لم تحصل على أي تطابقات، مما يشير إلى أن هذه العينات كانت هياكل "غير مرئية" في مجموعة بيانات التدريب. وعلى النقيض من ذلك، لا يزال DHR يحقق تنبؤات عالية الجودة لهذه الهياكل، حيث يصل إلى درجة AUC-1FP البالغة 89%.ويوضح هذا قدرة إدارة الموارد البشرية على التعامل مع بيانات جديدة تمامًا.
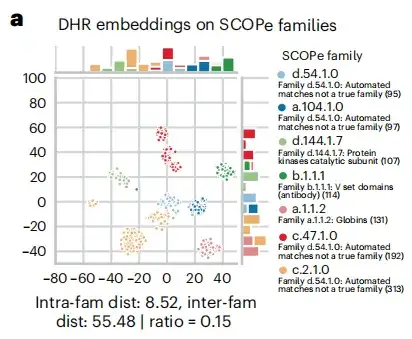
أثناء عملية البحث عن التماثل، كما هو موضح في الشكل أ أدناه، وجدت الدراسة أن تضمين تسلسل DHR يحتوي على كمية كبيرة من المعلومات البنيوية، وأن دقة DHR في استرجاع المواد المتجانسة تتجاوز دقة طرق المحاذاة القائمة على البنية. وبناء على هذه النتيجة،وكشفت هذه الدراسة أيضًا عن الارتباط بين ترتيب التشابه التسلسلي والتشابه الهيكلي لـ DHR.
نتائج البحث: تتمتع DHR بدقة وفعالية أفضل، ويمكنها بناء MSA عالية الجودة على مجموعات بيانات واسعة النطاق
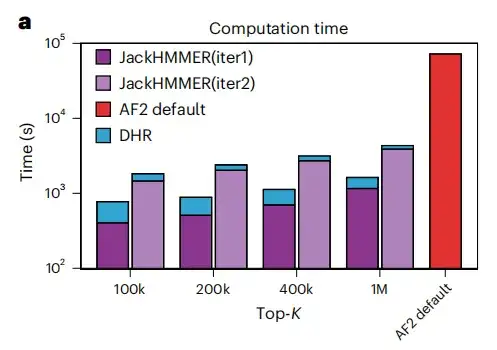
لقد قمنا بإنشاء MSAs من JackHMMER باستخدام نظائر مقدمة من DHR وقارناها بخط الأنابيب الافتراضي AF2. كما هو موضح في الشكل أ أدناه، فإن متوسط سرعة تشغيل جميع تكوينات DHR + JackHMMER أسرع من سرعة JackHMMER العادي من AF2. علاوة على ذلك، يتداخل DHR مع JackHMMER بحوالي 80% عند إنشاء MSA على UniRef90.ويشير هذا إلى أنه يمكن تنفيذ العديد من المهام اللاحقة المتعلقة بـ MSA باستخدام DHR، مما ينتج عنه نتائج مماثلة ولكن بشكل أسرع.
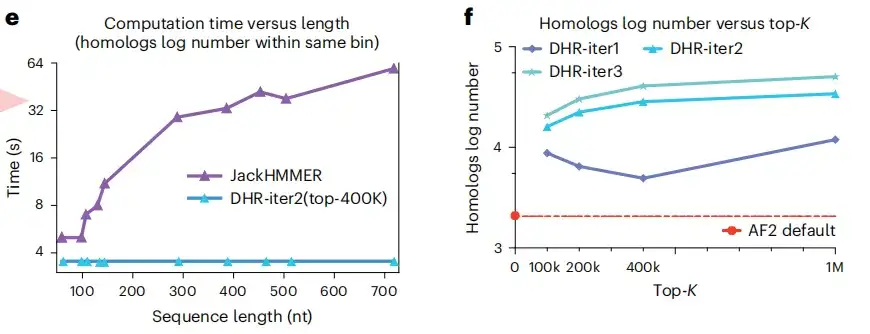
كما هو موضح في الشكلين e وf أدناه، فإن ميزة أخرى لـ DHR هي أنه يمكنه إنشاء نفس العدد من المتماثلات ذات الأطوال المختلفة في وقت ثابت، بينما يتدرج JackHMMER خطيًا. علاوة على ذلك، بالمقارنة مع AF2، يمكن لـ DHR توفير المزيد من المتماثلات وMSA لتضمين الاستعلام. وتشير هذه النتائج إلى أنيعد DHR نهجًا واعدًا لجميع فئات بناء MSA.
على الرغم من أن DHR قادر على إنتاج MSAs مختلفة، فقد قامت هذه الدراسة بتحليل ما إذا كان يمكن أن يعمل كمكمل لـ AF2 MSA الأساسي. تظهر نتائج البحث، كما هو موضح في الشكلين (أ) و(ب) أدناه، أن أداء الجمع بين جميع MSA وAF2 تحت إعدادات DHR المختلفة هو الأفضل.وهذا يعني أن DHR يمكنه تجديد خط أنابيب MSA الخاص بـ AF2 بسرعة ودقة.
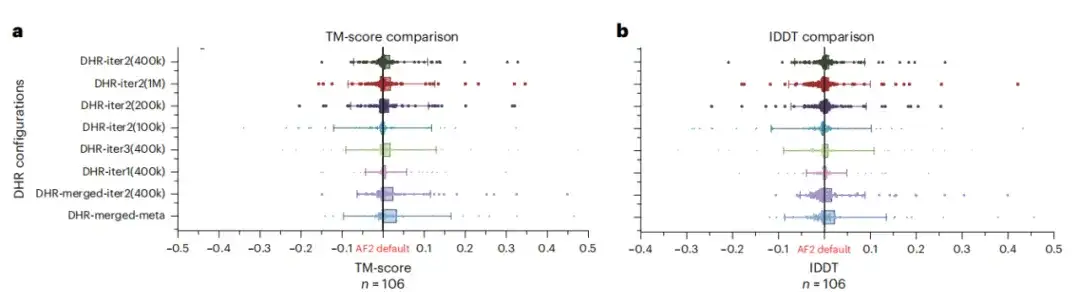
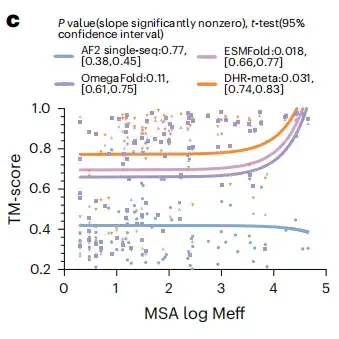
للتحقق من الفوائد المحتملة لنماذج اللغة الكبيرة للتنبؤ ببنية البروتين، قامت هذه الدراسة بتقييم ما إذا كان استبدال MSA بنموذج لغة كبير على جميع أهداف CASP14DM سيؤدي إلى نتائج أفضل. كما هو موضح في الشكل ج أدناه، في الحالة البسيطة التي تحتوي على عدد كبير من لغات البرمجة المتوسطة المتاحة، يمكن لنموذج اللغة أن ينقل نفس القدر من المعلومات مثل لغات البرمجة المتوسطة. ومع ذلك، مع زيادة طول التسلسل، يصبح أداء DHR-meta أفضل وأفضل، ويتفوق على ESMFold في جميع الحالات تقريبًا. وهذا يعني أنه بالمقارنة مع الأساليب القائمة على نموذج اللغة،يمكن للنموذج المبني على MSA تحسين دقة وفعالية التوقعات بشكل كبير.
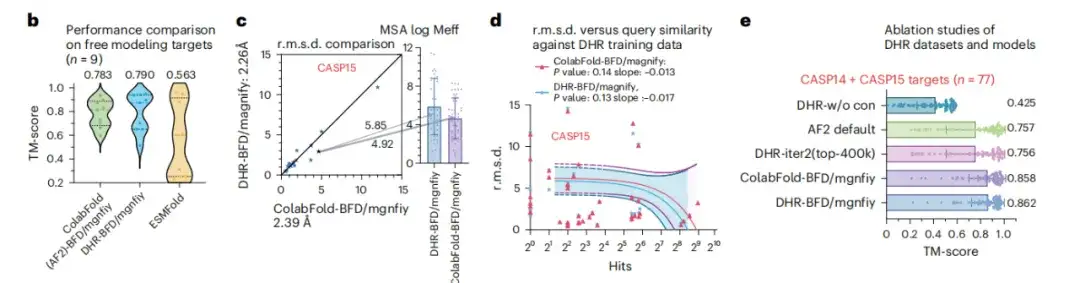
من أجل دراسة قابلية التوسع لـ DHR في مجموعات البيانات الكبيرة، أجرت هذه الدراسة تحليلًا متعمقًا لـ DHR استنادًا إلى BFM/MGnify. كما هو موضح في الشكل ب أدناه، في السيناريو المعقد للتنبؤ ببنية أهداف FM، يتمكن DHR من التميز من خلال توليد MSAs أكثر معنى، مع طريقة ColabFold باستخدام MMseqs2 لإنشاء MSAs متفوقة بـ 0.007 من درجات TM.
في الشكل 2ج، يظهر DHR تحسنًا طفيفًا في الأداء مقارنةً بـ ColabFold-MMseqs2. يوضح الشكل د أدناه أيضًا أنه بعد اختبار التشابه بين CASP14 وSCOPe، وجد أن DHR لم يتذكر نتائج الاستعلام أو الإصابة فحسب، بل أجرى تقييمًا شاملاً للتشابه بين جميع الأهداف. وتثبت هذه النتائج أنيتيح DHR إنشاء MSAs للبروتينات غير المنظمة على مجموعات بيانات البحث واسعة النطاق ذات التنوع العالي.
القوى الشابة في مجال التنبؤ ببنية البروتين
ليس هناك شك في أن التنبؤ ببنية البروتين يلعب دورًا مهمًا في التطبيقات مثل تطوير الأدوية وتصميم الأجسام المضادة. قد يصبح الذكاء الاصطناعي هو المفتاح لحل المشكلة التاريخية المتمثلة في الدقة المحدودة في التنبؤ ببنية البروتين. وفي هذا المجال الرئيسي، شكلت فرق البحث العلمي المحلية تدريجيا اتجاها يضم مائة مدرسة فكرية، وأصبح الباحثون الشباب الناشئون قوة لا يمكن تجاهلها. ويعد لي يو وسون سي تشي، اللذان قادا نتائج البحث المذكورة أعلاه، من بين الأفضل.

حصل لي يو على درجة البكالوريوس (مع مرتبة الشرف) في العلوم البيولوجية من فئة Bei Shizhang Elite بجامعة العلوم والتكنولوجيا في الصين في عام 2015، ودرجة الماجستير في علوم الكمبيوتر من جامعة الملك عبد الله للعلوم والتكنولوجيا (KAUST) في المملكة العربية السعودية في ديسمبر 2016، والدكتوراه في علوم الكمبيوتر من نفس الجامعة في عام 2020.
وفي ديسمبر من نفس العام، عاد إلى الصين وانضم إلى قسم علوم الكمبيوتر والهندسة في الجامعة الصينية في هونج كونج كأستاذ مساعد، وقاد مجموعة الذكاء الاصطناعي في الرعاية الصحية (AIH). أجرى أبحاثًا معمقة حول تقاطع التعلم الآلي والرعاية الصحية وعلم المعلومات الحيوية، وقاد الفريق لتطوير أساليب جديدة للتعلم الآلي لحل المشكلات الحسابية في علم الأحياء والرعاية الصحية، وخاصة مشكلات التعلم المنظم.
وفيما يتعلق بمجالات علم الأحياء والرعاية الصحية التي شارك فيها بشكل عميق، قال لي يو: "هدفي على المدى الطويل هو تحسين نظام الرعاية الصحية وتحقيق الفائدة المباشرة للمجتمع من خلال تحسين صحة الناس ورفاهتهم".ومن الجدير بالذكر أنه تم اختياره أيضًا ضمن قائمة "30 تحت 30" التي أعدتها مجلة فوربس آسيا لعام 2022 (الرعاية الصحية والعلوم).

حقق Sun Siqi نتائج ممتازة في مسابقة التنبؤ ببنية البروتين العالمية وهو يعمل حاليًا باحثًا شابًا في مختبر النظرية الأساسية وتكنولوجيا المفاتيح للأنظمة المعقدة الذكية ومختبر الذكاء الاصطناعي في شنغهاي بجامعة فودان.وهو ملتزم بأبحاث تطبيق التعلم العميق في المجالات متعددة التخصصات مثل علوم الحياة ومعالجة اللغة الطبيعية، ويركز على تحسين دقة وسرعة النماذج وحل مشاكل محددة في تنفيذ النماذج.
وفيما يتعلق بالتنبؤ بالبروتين، يركز على التنبؤ ببنية وتسلسل البروتينات من خلال نماذج التعلم العميق، ونماذج التدريب لتحديد الأنماط والانتظامات في التسلسلات للتنبؤ بتسلسل البروتينات وطيها، وبالتالي تحسين دقة وكفاءة تسلسل البروتين الجديد والتنبؤ بالبنية، وخلق إمكانيات جديدة لتصميم الأدوية وعلاج الأمراض.
في مجال AI4S المحلي، ينشط عدد متزايد من القوى الشابة. ومن المتوقع أن تلعب تقنية الذكاء الاصطناعي دورًا أكثر أهمية في مجال التنبؤ ببنية البروتين، ولكن الطريق أمامها طويل وشاق. ومن دواعي السرور أن فريق البحث العلمي المحلي أظهر روحًا مثابرة في الاستكشاف والقدرة على الابتكار. ولم يعملوا بجد على تحسين الخوارزميات وبناء النماذج فحسب، بل أجروا أيضًا أبحاثًا متعمقة في معالجة البيانات والتحقق التجريبي وما إلى ذلك لضمان علمية وواقعية نتائج البحث. وتتحول هذه الجهود تدريجيا إلى تطبيقات عملية، مما يجلب حيوية جديدة وأملاً لمجالات مثل البحث والتطوير الطبي والتكنولوجيا الحيوية.
وأخيرًا، أوصي بنشاط المشاركة الأكاديمية!
تمت دعوة تشو زيي، باحث ما بعد الدكتوراه في معهد العلوم الطبيعية بجامعة شنغهاي جياو تونغ والمركز الوطني شنغهاي للرياضيات التطبيقية، إلى البث المباشر الثالث لـ Meet AI4S. انقر هنا لتحديد موعد لمشاهدة البث المباشر!
https://hdxu.cn/6Bjomhdxu.cn/6Bjom









