Command Palette
Search for a command to run...
가상 임상 환경 내 진화하는 인터랙티브 진단 Agent 연구
가상 임상 환경 내 진화하는 인터랙티브 진단 Agent 연구
DiagGym 진단제
초록
본 논문에서는 강화 학습을 통해 대규모 언어 모델(LLM)을 진단 에이전트(diagnostic agent)로 학습시키는 프레임워크를 제안합니다. 이 프레임워크를 통해 LLM은 다회차(multi-turn) 상호작용 진단 프로세스를 관리하고, 적응적으로 검사를 선택하며, 최종 진단을 내릴 수 있습니다. 정적인 사례 요약(case summaries)을 바탕으로 학습된 instruction-tuned 모델과 달리, 본 연구의 방법론은 동적 탐색(dynamic exploration)과 결과 기반 피드백을 통해 진단 전략을 습득하며, 변화하는 환자 상태를 다음 최적의 검사 및 후속 진단으로 매핑합니다.본 연구의 주요 기여는 다음과 같습니다:(i) 전자 건강 기록(EHR)을 통해 학습된 진단 월드 모델(diagnostics world model)인 DiagGym을 제시합니다. DiagGym은 환자의 병력과 권장 검사를 조건으로 검사 결과를 생성할 수 있어, 상호작용 진단을 위한 폐쇄 루프(closed-loop) 방식의 in-silico 학습 및 평가를 지원하는 가상 임상 환경 역할을 합니다.(ii) 환경 내에서 end-to-end 방식의 다회차 강화 학습을 통해 상호작용 진단 에이전트인 DiagAgent를 학습시킵니다. 이를 통해 상호작용의 효율성과 최종 정확도를 모두 최적화하는 동적 진단 정책(diagnostic policies)을 학습합니다.(iii) 다회차 진단 상호작용 궤적(interaction trajectories)을 평가하기 위해 설계된 포괄적인 다기관 진단 벤치마크인 DiagBench를 도입합니다. 이 벤치마크는 네 가지 서로 다른 분포에서 수집된 2,200개의 의사 검증 사례와, 세밀한 프로세스 중심 평가를 위한 3,300개의 의사 작성 루브릭(rubrics)으로 구성됩니다.(iv) 광범위한 평가를 통해 DiagAgent가 인도메인(in-domain) 및 아웃오브도메인(OOD) 설정 모두에서 탁월한 성능을 보임을 입증했습니다. DiagAgent는 11개의 최첨단(SOTA) LLM(DeepSeek-v3 및 Claude-4-Sonnet 포함)과 2개의 prompt-engineered agent를 크게 앞질렀습니다. end-to-end 설정에서 DiagAgent는 진단 정확도를 11.20% 향상시켰으며, 검사 권장 F1 score를 17.58% 높였을 뿐만 아니라, 3개의 외부 OOD 센터 모두에서 일관되게 최첨단 성능을 유지했습니다. 또한, 루브릭 기반 평가에서 가중치 적용 루브릭 점수(weighted rubric score) 기준 차순위 모델보다 7.1% 높은 성능을 기록했습니다.이러한 결과는 상호작용적인 임상 환경에서 정책을 학습하는 것이, 수동적인(passive) 학습만으로는 달성할 수 없는 역동적이고 임상적으로 유의미한 장기적 진단 관리 능력을 부여한다는 것을 시사합니다.
One-sentence Summary
By training the DiagAgent through multi-turn reinforcement learning within DiagGym, a virtual clinical environment built from electronic health records, the authors enable dynamic exploration of interactive diagnostic processes that significantly outperforms state-of-the-art models in diagnostic accuracy and examination recommendation F1 scores across both in-domain and out-of-domain settings on the DiagBench benchmark.
Key Contributions
- The paper introduces DiagGym, a diagnostics world model trained on electronic health records that functions as a virtual clinical environment by emitting examination outcomes conditioned on patient history and recommended tests.
- This work presents DiagAgent, an interactive diagnostic agent trained via end-to-end, multi-turn reinforcement learning to develop dynamic diagnostic policies that optimize both examination recommendation and final diagnostic accuracy.
- A comprehensive multi-center benchmark named DiagBench is introduced, consisting of 2.2K physician-validated cases and 3.3K physician-written rubrics to evaluate multi-turn diagnostic interaction trajectories across various distributions.
Introduction
Clinical diagnosis is an interactive, long-term decision-making process that requires clinicians to manage uncertainty by selecting appropriate examinations and synthesizing evolving patient data. Most current large language models are limited by training on static, instruction-style corpora that assume complete patient records, preventing them from mastering the dynamic reasoning required to order tests or manage trajectories in real-time. The authors address this by introducing DiagGym, a diagnostics world model trained on electronic health records that serves as a virtual clinical environment for closed-loop training. They leverage this environment to train DiagAgent, an interactive diagnostic agent optimized through multi-turn reinforcement learning to improve both examination recommendation accuracy and final diagnostic outcomes.
Dataset

Dataset Description
The authors developed two primary datasets: DiagGym, a large-scale training corpus for a clinical world model, and DiagBench, a multi-center benchmark for evaluating diagnostic agents.
1. DiagGym (Training Dataset)
- Composition and Sources: The dataset is derived from MIMIC-IV electronic health records (EHR), comprising 118,478 patient cases covering 4,897 distinct diseases.
- Processing and Filtering:
- The authors extracted patient profiles (chief complaint, medical history, and final diagnosis) using heuristic string matching on discharge notes.
- A two-step filtering process was applied: cases lacking physical examination records were excluded, and an LLM (DeepSeek-V3) was used to remove cases where the diagnosis was already present in the patient's history to ensure diagnostic relevance.
- Examination sets were constructed by combining physical exams, laboratory results, microbiology, and radiology records from within one day prior to admission.
- To maintain clinical accuracy, the authors prioritized the earliest records for repeated examinations and used the MIMIC-CDM mapping table to standardize examination names.
- Usage:
- World Model Training: 114,239 EHRs are used to train the model to autoregressively reconstruct examination results.
- Diagnostic Agent Training: A reformatted version of the training data was converted into 15,324 interactive multi-turn diagnostic trajectories. These trajectories include an initial inquiry, a sequence of recommended examinations with rationales, and a final diagnosis. A two-stage LLM filter was used to prevent information leakage of the final diagnosis into the initial inquiry.
- Evaluation: 4,239 cases were reserved for testing, with a disease-wise sampling strategy used to create a balanced test set of 863 unique diseases.
2. DiagBench (Evaluation Benchmark)
- Composition and Sources: The benchmark consists of 2,257 physician-validated cases categorized into two subsets:
- In-Domain (ID): 750 cases from MIMIC-IV representing critical care and emergency medicine.
- Out-of-Domain (OOD): 1,507 cases aggregated from PMC-OA (complex biomedical case reports), MTSamples (outpatient and specialty clinic records), and DDXPlus (structured differential diagnosis cases).
- Processing and Metadata:
- Profile and Trajectory Synthesis: For OOD sources lacking structure, the authors used an LLM to synthesize patient profiles and multi-turn diagnostic trajectories. To prevent outlier cases, recommendations were constrained to standard laboratory, microbiology, and radiology modalities.
- Validation: All cases underwent a rigorous pipeline involving automated logical consistency checks and senior physician reviews to ensure clinical plausibility.
- Rubric Construction: To enable fine-grained evaluation, the authors constructed 3,318 physician-authored rubrics. These rubrics focus on the reasoning process, such as history taking and test ordering, and are assigned importance weights by medical experts.
- Usage: The benchmark is used to assess multi-turn diagnostic capabilities through both single-turn and end-to-end evaluation scenarios.
Method
The authors propose a reinforcement learning (RL) based framework designed to transform Large Language Models (LLMs) into interactive diagnostic agents. Unlike traditional models that treat diagnosis as a single-shot task, this approach enables agents to manage multi-turn diagnostic trajectories by dynamically recommending examinations and refining hypotheses as new evidence accumulates.
The framework is built upon two primary components: a diagnostics world model called DiagGym and an interactive diagnostic agent named DiagAgent. As shown in the framework diagram:
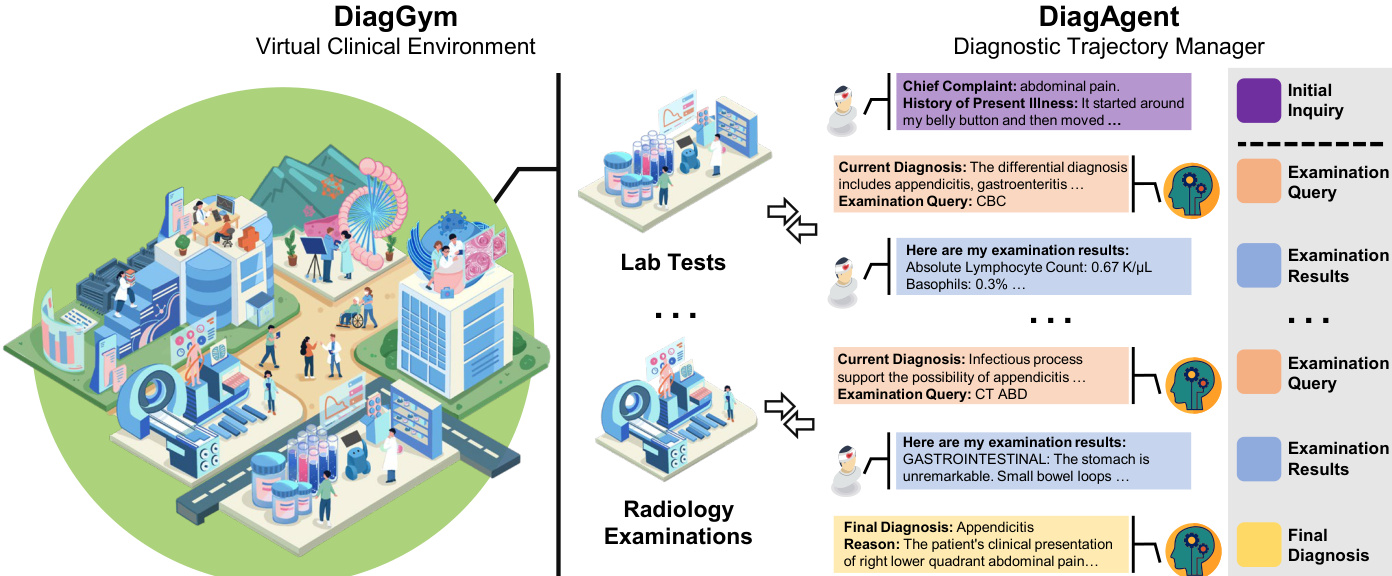
The authors leverage DiagGym to serve as a virtual clinical environment. DiagGym is implemented as a conditional textual Electronic Health Record (EHR) generator, denoted as Φenv. It takes a patient's background profile B and the history of past examinations Et as input to simulate the results of a new examination query at+1. The generation process is formulated as:
et+1=Φenv(at+1∣Et,B)
To ensure the fidelity of the simulated environment, DiagGym is trained using an auto-regressive text generation objective that minimizes the negative log-likelihood of ground-truth examination results. This allows the model to capture complex dependencies between diseases, medical histories, and prior test results, providing a safe and repeatable closed-loop simulation for agent training.
The diagnostic agent, DiagAgent, is trained within this virtual environment through end-to-end multi-turn RL. At each time step t, the agent observes a state st consisting of the initial patient inquiry I and the accumulated examination records Et. The agent's policy, πθ, is parameterized by an LLM Φdiag and selects an action at+1 from the action space A, which includes both clinical examination recommendations and the final diagnosis.
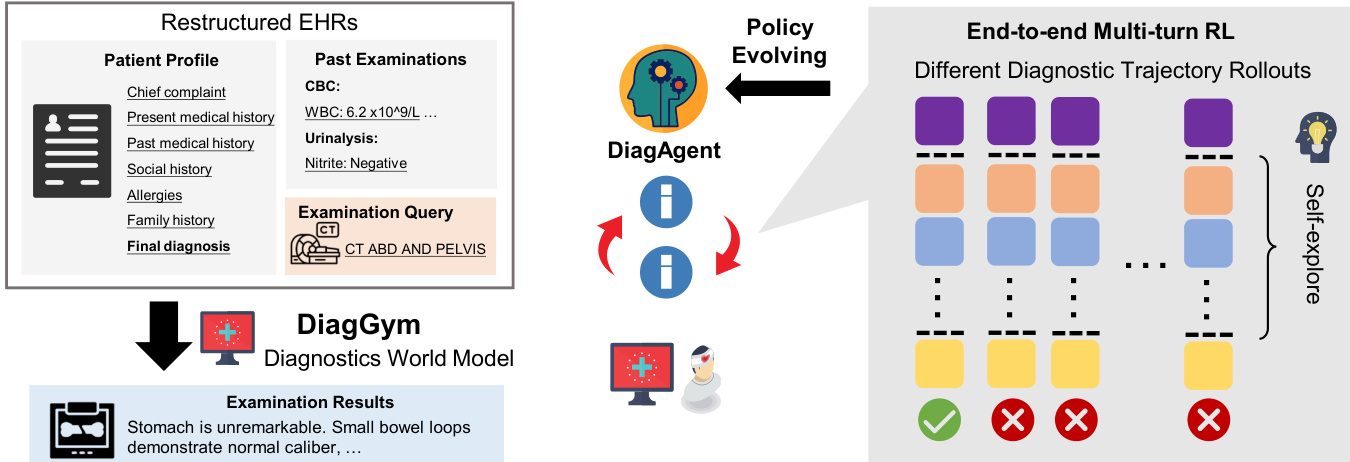
The training process follows a two-stage paradigm. First, a cold-start phase uses standard instruction tuning to ensure the model produces well-formatted and contextually appropriate responses. Second, the main RL phase employs the Group Relative Policy Optimization (GRPO) algorithm to optimize the policy for long-term diagnostic success. The agent's objective is to maximize the expected cumulative reward:
maxΦdiagEΦdiag[∑t=1TγtR(st,at)]
The reward function R is a weighted sum of three components: diagnostic accuracy rdiag, examination relevance rexam, and efficiency rturn. This multi-faceted reward structure encourages the agent to reach the correct diagnosis while minimizing unnecessary testing and dialogue turns.
Experiment
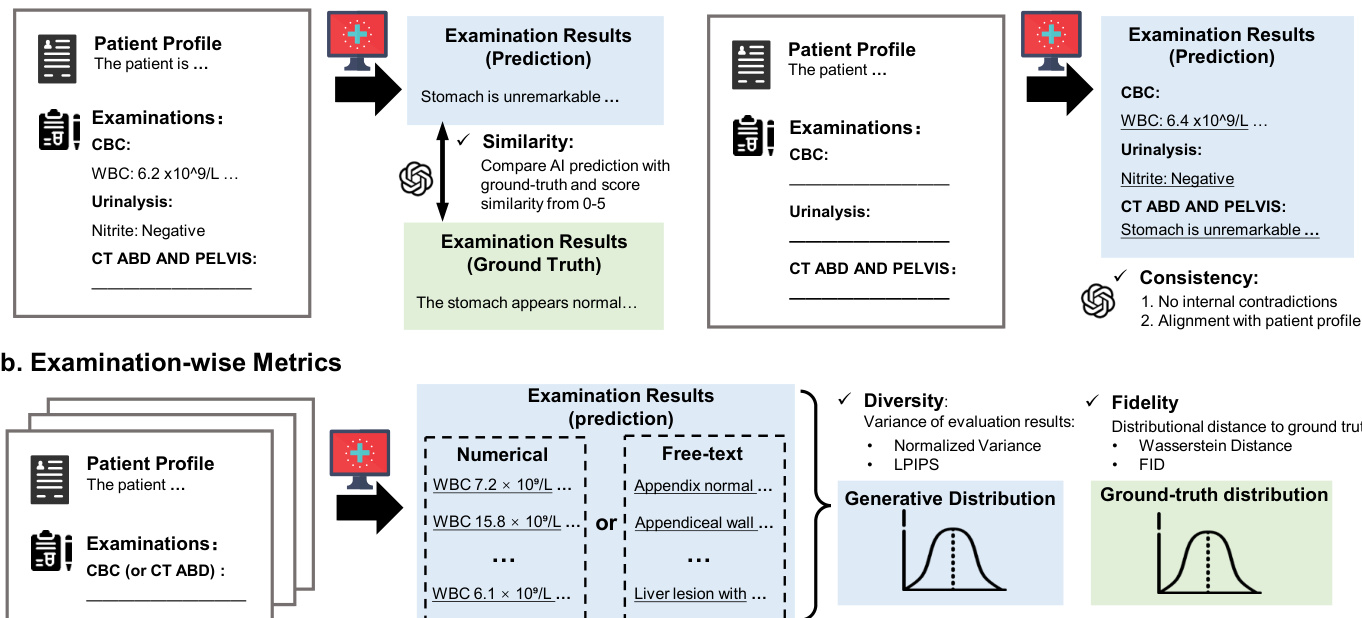
The evaluation assesses the fidelity of the DiagGym world model and the reasoning capabilities of the DiagAgent diagnostic agent through instance-wise, examination-wise, and end-to-end clinical simulations. DiagGym demonstrates superior performance by generating clinically consistent and diverse examination results that closely match real-world distributions, outperforming large-scale language models in both reliability and computational efficiency. DiagAgent exhibits significantly enhanced diagnostic accuracy and procedural reasoning compared to supervised fine-tuning and existing agentic systems, maintaining robust performance even in out-of-domain scenarios. Overall, the results indicate that reinforcement learning within a high-fidelity virtual environment enables models to master complex, multi-turn interactive diagnostic trajectories.
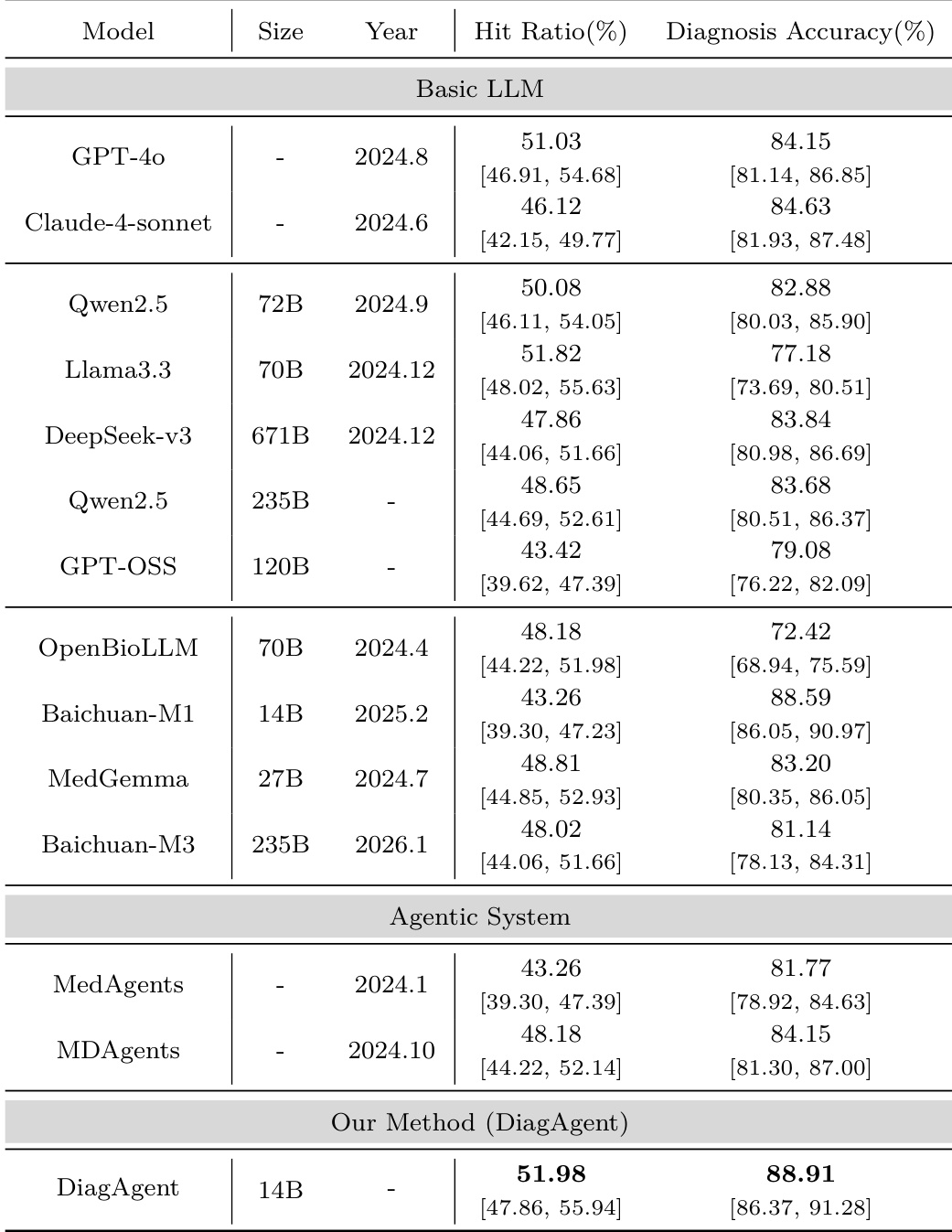
The authors compare the performance of their proposed DiagAgent against various basic large language models and agentic systems in a single-turn evaluation setting. Results demonstrate that DiagAgent achieves superior performance in both examination recommendation hit ratio and final diagnosis accuracy. DiagAgent achieves higher diagnosis accuracy and examination recommendation hit ratios compared to all evaluated basic LLMs and agentic systems. The proposed method outperforms specialized medical models and large-scale general-purpose models in both key diagnostic metrics. Agentic systems based on existing frameworks do not surpass the performance of the specialized DiagAgent approach.
The authors conduct a human validation study to compare the reliability of an LLM-as-a-judge against the consensus of three independent physicians. The results demonstrate high alignment between the automated evaluator and human experts across multiple clinical assessment metrics. The LLM judge achieves high agreement with the physician consensus for binary tasks such as diagnosis accuracy and rubric hit ratio. For numerical tasks like examination recommendation counting, the LLM maintains a low mean absolute error relative to the human median. Automated evaluation shows strong consistency with expert judgment, suggesting it can serve as a reliable and standardized clinical evaluator.
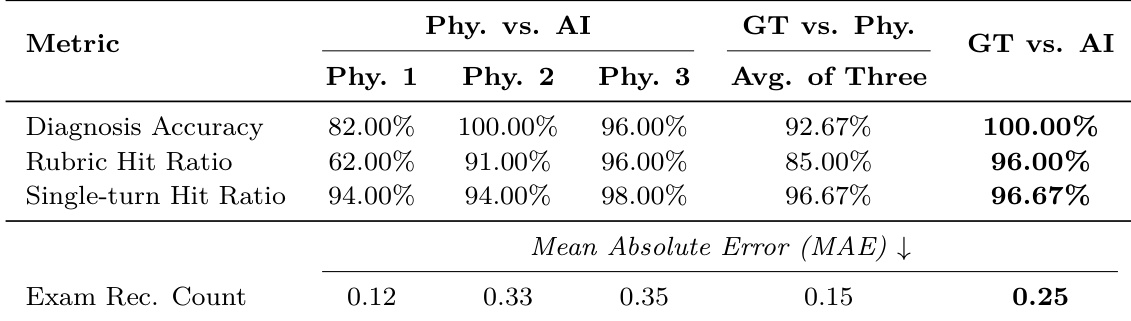
The authors compare their DiagAgent model against various basic LLMs and agentic systems in an end-to-end diagnostic evaluation. Results show that the proposed method achieves higher diagnostic accuracy and superior examination recommendation performance compared to the evaluated baselines. DiagAgent demonstrates higher diagnostic accuracy than both large-scale general LLMs and specialized medical models. The proposed method achieves significantly better recall and F1-score for examination recommendations compared to all baseline models. DiagAgent engages in longer diagnostic dialogues, suggesting more thorough evidence gathering during the interactive process.
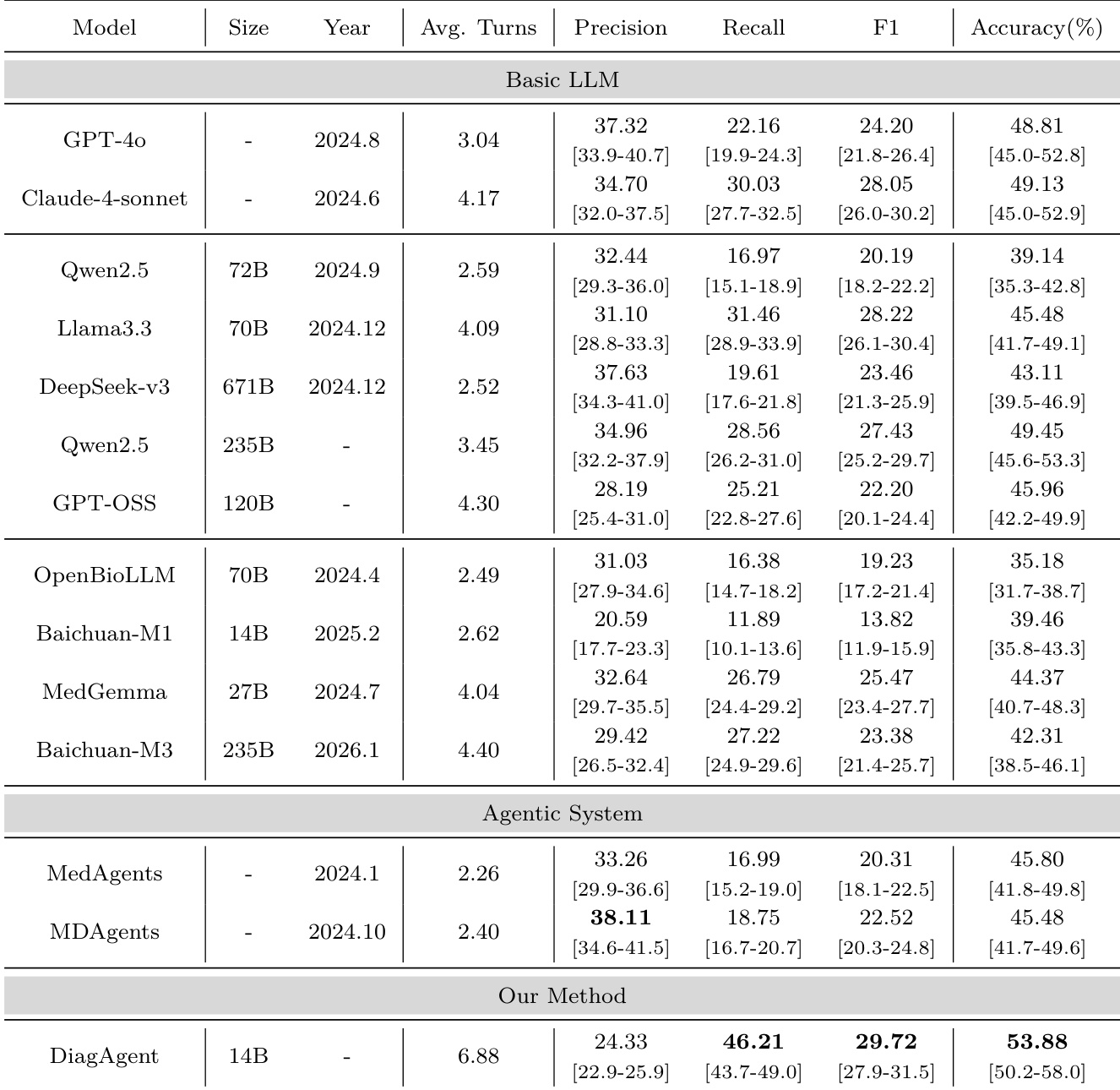
The authors evaluate the DiagAgent model in a single-turn setting by comparing its examination recommendation hit ratio and diagnostic accuracy against various basic LLMs and agentic systems. Results show that DiagAgent variants, particularly the larger versions, achieve higher performance in both recommendation precision and final diagnostic correctness. DiagAgent variants outperform both general-purpose LLMs and medical-specialized models in examination recommendation hit ratio. The 14B version of DiagAgent achieves the highest diagnostic accuracy among all tested models. DiagAgent demonstrates superior performance in both recommendation and diagnosis compared to existing agentic frameworks.

The authors compare the DiagAgent model against various basic large language models and agentic systems using single-turn evaluation metrics. Results show that DiagAgent achieves higher hit ratios for examination recommendations and superior diagnosis accuracy compared to the evaluated baselines. DiagAgent outperforms both proprietary models like GPT-4o and large open-source models like DeepSeek-v3 in both hit ratio and diagnostic accuracy. The DiagAgent method demonstrates higher performance than existing agentic frameworks such as MedAgents and MDAgents. The model shows improved capability in both selecting appropriate examinations and reaching correct diagnostic decisions.
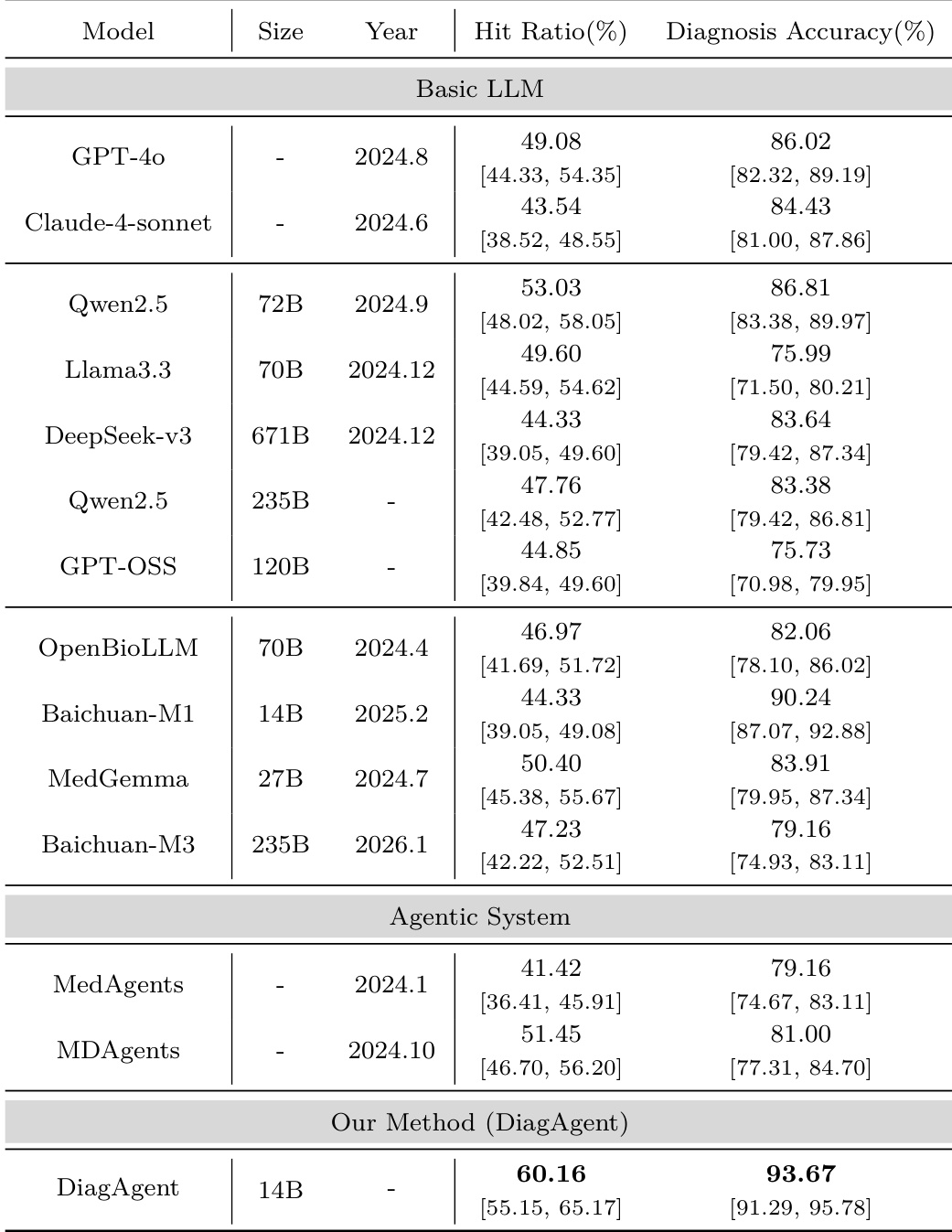
The authors evaluate DiagAgent through single-turn and end-to-end diagnostic comparisons against various general-purpose LLMs, specialized medical models, and existing agentic frameworks. The results demonstrate that DiagAgent consistently outperforms these baselines in both examination recommendation accuracy and final diagnostic correctness, often engaging in more thorough evidence gathering. Additionally, a human validation study confirms that an LLM-as-a-judge aligns closely with physician consensus, establishing the automated evaluator as a reliable and standardized tool for clinical assessment.