Command Palette
Search for a command to run...
ByteDance는 이해, 생성 및 편집을 포괄하는 3B 모델인 Lance를 오픈 소스로 공개했으며, 싱가포르 국립대학교는 588개의 비디오와 비언어적 질문 답변을 포함하는 ViMU 데이터셋을 제안했습니다.

2026년 ByteDance에서 출시한 Lance는 네이티브 통합 멀티모달 모델입니다. 3B 활동 파라미터 설계를 채택하여 단일 프레임워크 내에서 이미지와 비디오의 이해, 생성, 편집을 동시에 수행할 수 있습니다. 이 모델은 통합 멀티모달 표현과 다중 작업 협업 학습을 통해 텍스트, 이미지, 비디오 작업 전반에 걸쳐 기능을 공유합니다. 핵심은 투 스트림 하이브리드 전문가(MoE) 아키텍처와 모달리티 인식 회전 위치 인코딩(MaPE)을 활용하여 공유된 인터리브드 멀티모달 시퀀스에서 통합 컨텍스트 학습을 구현하는 동시에 이해와 생성의 기능 경로를 효과적으로 분리합니다. 단계별 다중 작업 학습 전략과 결합하여 Lance는 뛰어난 멀티모달 의미 이해 기능을 유지하면서 이미지 및 비디오 생성 품질 측면에서 기존 오픈 소스 통합 모델을 크게 능가합니다.
HyperAI 웹사이트에서 "Lance: 멀티모달 이해, 생성 및 편집 모델 통합"을 새롭게 선보입니다. 지금 바로 체험해 보세요!
온라인 사용:https://go.hyper.ai/Okkmw
더 자세한 정보를 원하시면 저희 공식 웹사이트를 방문해 주세요.
5월 23일부터 5월 29일까지 hyper.ai 공식 웹사이트의 주요 업데이트 사항을 간략하게 살펴보겠습니다.
* 고품질 공개 데이터 세트: 3개
* 고품질 튜토리얼 선택: 3개
* 커뮤니티 기사 해석 : 3개 기사
* 인기 백과사전 항목: 5개
공식 웹사이트를 방문하세요:하이퍼.AI
선택된 공개 데이터 세트
1. ViMU 비디오 은유 이해 데이터셋
ViMU는 싱가포르 국립대학교에서 2026년에 발표한 비디오 은유 이해 벤치마크 데이터셋입니다. 이 데이터셋은 멀티모달 대규모 모델이 비디오 은유의 심층적인 의미를 이해하는 능력을 평가하는 것을 목표로 합니다.
온라인 사용:https://go.hyper.ai/0DIpe
2. 벼 잎 질병 데이터 세트
벼 잎 질병 탐지 데이터셋은 정밀 농업 목표 탐지 작업을 위해 특별히 설계된 벼 잎 이미지 데이터셋입니다. YOLO 모델 학습, 농작물 질병 탐지, 엣지 비전 구현, 지능형 벼 재배 관리 등 다양한 분야에서 널리 활용되고 있습니다. 이 데이터셋은 건강한 벼 잎과 세균성 잎마름병, 갈반점병, 벼잎말이병, 도열병, 잎마름병, 잎깜부기병, 좁은갈반점병, 목도열병 등 8가지 일반적인 질병을 포함한 총 9개 범주의 벼 잎 이미지 8,665장으로 구성되어 있습니다.
온라인 사용:https://go.hyper.ai/IXOlY

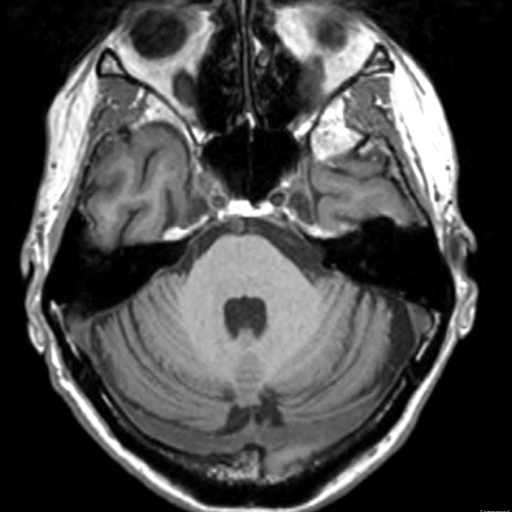
3. MRI 뇌 신경퇴행성 질환 데이터 세트
MRI 뇌신경퇴행성질환 데이터셋은 뇌신경퇴행성질환의 연구 및 의료영상 분석을 위해 설계된 MRI 데이터셋입니다. 질병 분류, 의료영상 인식, 딥러닝 모델 학습 등 다양한 연구 분야에서 널리 활용되고 있습니다. 이 데이터셋은 512 × 512 해상도의 뇌 MRI 영상 2,846개로 구성되어 있으며, 두 가지 영상 가중치와 네 가지 주요 범주로 분류되어 있습니다.
온라인 사용:https://go.hyper.ai/VpFoh
선택된 공개 튜토리얼
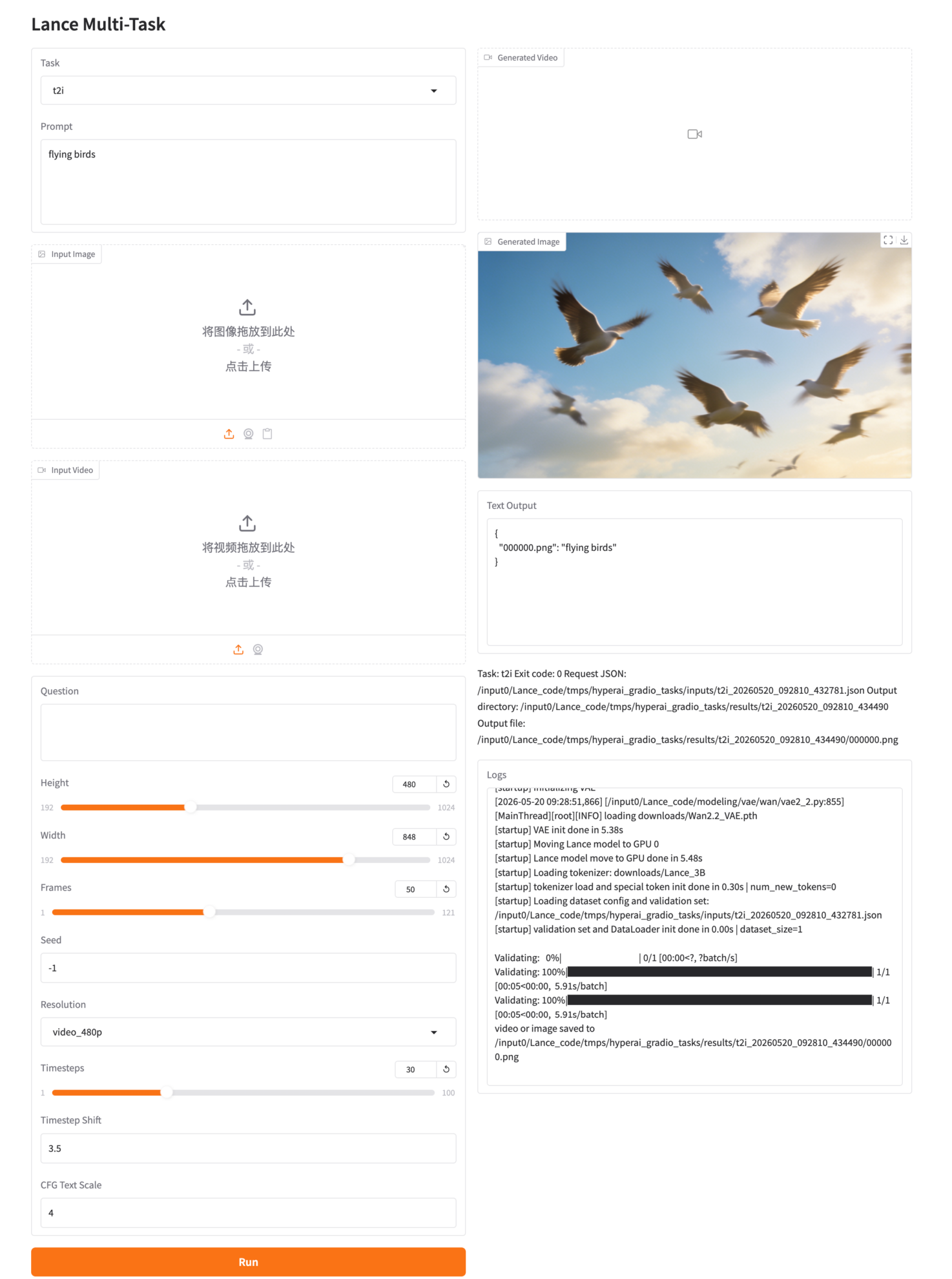
1. Lance: 멀티모달 데이터의 이해, 생성 및 편집을 위한 통합 모델.
2026년 바이트댄스에서 출시된 랜스(Lance)는 이미지 이해, 비디오 이해, 텍스트 이미지 생성, 텍스트 비디오 생성, 이미지 편집, 비디오 편집 등의 작업을 위해 설계된 30억 규모의 네이티브 통합 멀티모달 모델입니다. 랜스의 핵심 특징은 동일한 모델 프레임워크 내에서 이해, 생성, 편집을 처리하여 텍스트, 이미지, 비디오 작업이 통합된 멀티모달 표현을 공유할 수 있도록 한다는 점입니다. 랜스는 텍스트로부터 이미지나 비디오를 생성하고, 입력 이미지, 입력 비디오, 텍스트 명령어를 조합하여 시각적 편집을 수행하며, 이미지와 비디오에 대한 질의응답, 설명, 추론을 수행할 수 있습니다.
온라인으로 실행:https://go.hyper.ai/Okkmw
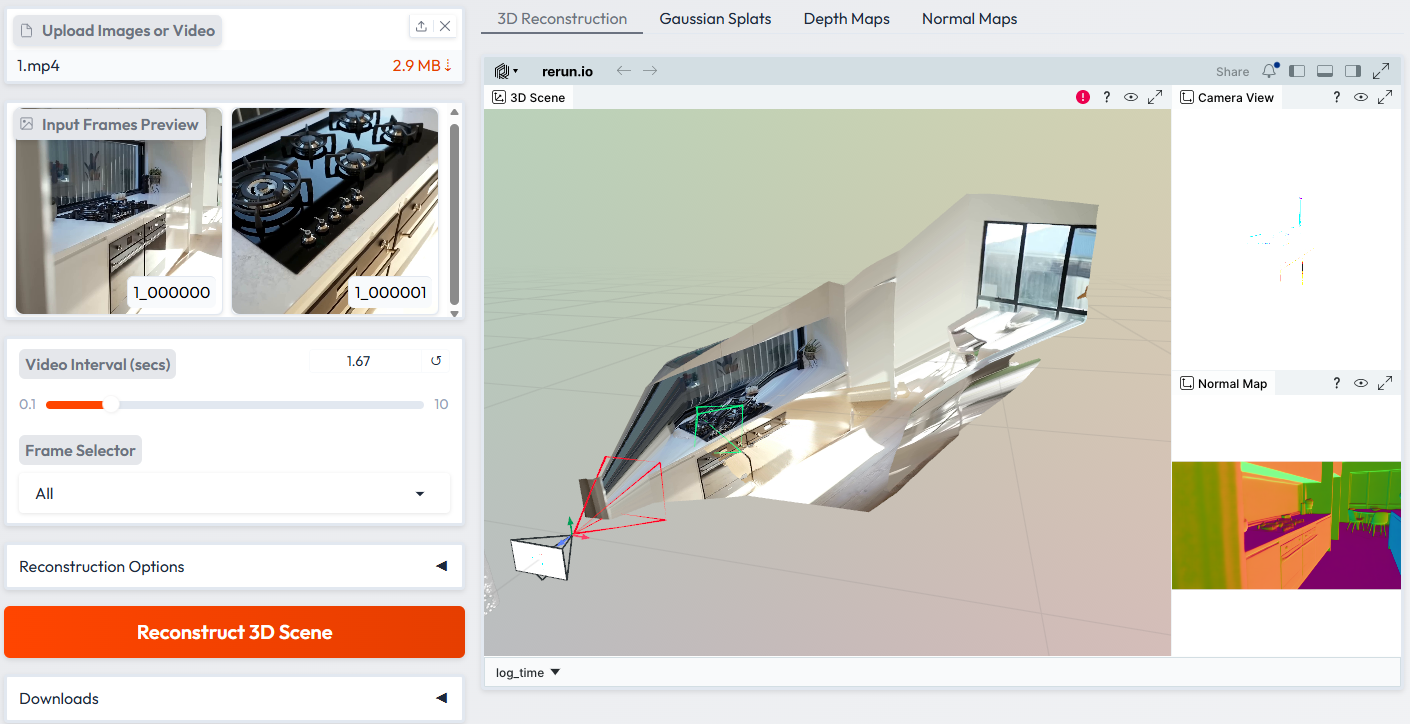
2. HY-World-2.0 세계 모델
HY-World-2.0은 텐센트가 2026년에 출시한 멀티모달 월드 모델 프레임워크입니다. 픽셀 비디오만 생성하는 월드 모델(예: Genie 3 및 Cosmos)과 달리, HY-World-2.0은 편집 가능하고 영구적인 사실적인 3D 에셋(메시/3DGS)을 직접 생성하며, 생성된 에셋은 Blender, Unity, Unreal Engine과 같은 게임 엔진으로 직접 불러올 수 있습니다.
온라인으로 실행:https://go.hyper.ai/ZQpHM
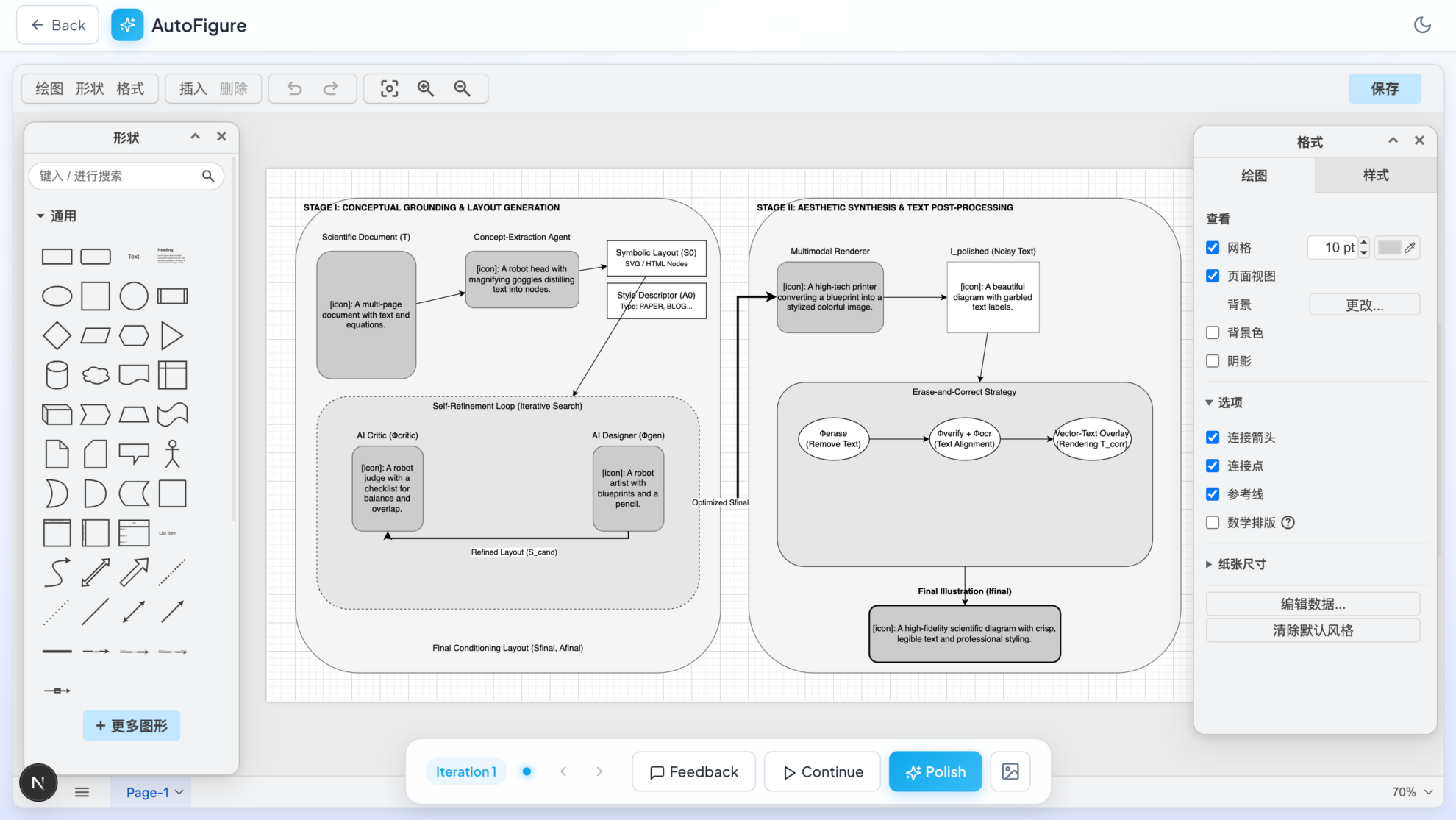
3. AutoFigure: 학술 논문용 삽화를 자동으로 생성하는 LLM 기반 시스템.
AutoFigure는 웨스트레이크 대학교 ResearchAI 팀에서 개발하고 ICLR 2026에서 발표한 지능형 학술 일러스트레이션 생성 시스템입니다. 이 시스템은 대규모 언어 모델(LM)을 활용하여 반복적인 최적화 메커니즘을 통해 텍스트 설명이나 연구 논문으로부터 출판 기준을 충족하는 고품질 과학 일러스트레이션을 자동으로 생성합니다. SVG 벡터 그래픽과 mxGraph XML(draw.io와 완벽하게 호환) 출력 형식을 모두 지원합니다.
온라인으로 실행:https://go.hyper.ai/ZrWS4
커뮤니티 기사 해석
1. 아르곤 국립 연구소에서 제안한 제로 코드, 자체 발견 기능을 갖춘 과학 이미지 처리 알고리즘인 CVEvolve는 코딩, 결과 자체 검증 및 전략 최적화를 포함한 풀 스택 기능을 보유하고 있습니다.
미국 아르곤 국립 연구소(ANL)의 연구팀이 기존 AI 기반 자동화 작업을 체계적으로 분석한 결과, 코드 작성 없이 작동하는 자율 에이전트 프레임워크인 CVEvolve를 개발했습니다. 이 프레임워크는 과학 데이터 처리에 필요한 알고리즘을 발견하도록 설계되었으며, 사전 정의된 문제 구조나 고정된 프로세스 템플릿 없이도 뛰어난 유연성을 제공합니다. 코드, 데이터, 평가 지표, 검색 기록, 시각화 결과 등 다양한 요소를 폐쇄 루프 방식으로 연결하여 컴퓨터 비전, 이미지 처리 등 다양한 분야에서 실행 가능한 알고리즘 개발을 지원합니다.
전체 보고서 보기:https://go.hyper.ai/UBS5q
2. 생물학적 다중 에이전트 로빈은 단 30분 만에 550편의 연구 논문을 성공적으로 통합하여 자율적인 연구 루프를 구축하고 dAMD 치료 후보 물질을 식별했습니다.
샌프란시스코의 퓨처하우스, 옥스퍼드 대학교, 포드햄 대학교의 공동 연구팀이 로빈(Robin) 생물학적 다중 에이전트 시스템을 제안했습니다. 이 시스템은 과학적 가설 생성과 실험 데이터 분석 기능을 동시에 통합하여 지속적인 폐쇄 루프 워크플로우를 구현하는 최초의 생의학 지능형 시스템입니다.
전체 보고서 보기:https://go.hyper.ai/KnYpQ
3. 과학자들은 베이지안 최적화 프레임워크를 사용하여 갈륨 함유 물질을 역설계함으로써 독자적으로 새로운 물질을 만들어냈습니다. 최적화 결과는 독창성과 참신성을 보여줍니다.
플린더스 대학교와 아랍에미리트 칼리파 대학교가 공동으로 진행한 연구팀은 화학적 합리성을 유지하면서 미리 정해진 전자적 특성을 갖는 갈륨 기반 조성물을 역설계할 수 있는 머신러닝 기반 베이지안 최적화(BO) 프레임워크를 제안했습니다. 최적화 후 분석 결과에 따르면, 생성된 물질은 훈련 데이터에 비해 100%의 고유성과 참신성을 가지며, 1.5~2.5 eV 밴드갭 범위에서 SMACT 효율이 크게 향상된 것으로 나타났습니다.
전체 보고서 보기:https://go.hyper.ai/kXS7f
인기 백과사전 기사
1. 하이퍼네트워크
2. 혼동 행렬
3. 신속 엔지니어링
4. 배포 과정에서의 학습
5. 상호 랭크 융합
다음은 "인공지능"을 이해하는 데 도움이 되는 수백 가지 AI 관련 용어입니다.
위에 적힌 내용은 이번 주 편집자 추천 기사의 전체 내용입니다. hyper.ai 공식 웹사이트에 포함시키고 싶은 리소스가 있다면, 메시지를 남기거나 기사를 제출해 알려주세요!
다음주에 뵙겠습니다!
HyperAI 소개
HyperAI(hyper.ai)는 중국을 선도하는 인공지능 및 고성능 컴퓨팅 커뮤니티입니다.우리는 중국 데이터 과학 분야의 인프라가 되고 국내 개발자들에게 풍부하고 고품질의 공공 리소스를 제공하기 위해 최선을 다하고 있습니다. 지금까지 우리는 다음과 같습니다.
* 2100개 이상의 공개 데이터 세트에 대한 국내 가속 다운로드 노드를 제공합니다.
* 700개 이상의 고전 및 인기 온라인 강좌가 포함되어 있습니다.
* 300개 이상의 AI4Science 논문 사례 분석
* 700개 이상의 관련 용어 검색을 지원합니다.
* 중국에서 최초의 완전한 Apache TVM 중국어 문서 호스팅
학습 여정을 시작하려면 공식 웹사이트를 방문하세요.








