Command Palette
Search for a command to run...
971 TP3T의 정확도를 자랑하는 MOFSeq-LMM은 프린스턴 대학교를 비롯한 연구진이 MOF 합성 가능 여부를 효율적으로 예측하는 알고리즘입니다.
금속-유기 골격체(MOF)는 고도로 조절 가능한 기공 구조와 풍부한 화학적 기능성 덕분에 가스 저장, 분리, 촉매 작용 및 약물 전달과 같은 응용 분야에서 큰 잠재력을 보여왔습니다. 그러나MOF는 수조 가지의 구성 요소 조합을 아우르는 방대한 설계 공간을 가지고 있어 실험적 탐색이 매우 비효율적입니다.
MOF 발견을 가속화하기 위해 새로운 MOF를 생성하고, 그 특성을 예측하며, 궁극적으로 합성을 달성하는 것을 목표로 하는 계산 파이프라인이 등장했습니다. 이 과정에서,주요 과제는 선별에서 합성으로의 전환율이 낮다는 점입니다.이는 주로 컴퓨터로 생성된 MOF를 합성하는 것의 실현 가능성에 대한 불확실성에서 비롯됩니다. 예를 들어, 현재까지 발표된 수천 건의 전산 MOF 스크리닝 중 MOF 합성이 동반된 경우는 12건 정도에 불과합니다.
자유 에너지는 MOF의 열역학적 안정성과 합성 가능성을 평가하는 중요한 지표이지만, 기존의 계산 방법은 대규모 MOF 데이터 세트에서 비용이 많이 들어 신속한 스크리닝이 어렵습니다. 이러한 문제를 해결하기 위해 프린스턴 대학교와 콜로라도 광산대학의 공동 연구팀은 머신러닝 기반의 효율적인 예측 방법을 제안했습니다.MOF의 구조적 순서로부터 자유 에너지를 직접 예측하기 위해 대규모 언어 모델(LLM)을 사용함으로써 계산 비용을 크게 줄일 수 있으며, 이를 통해 MOF의 열역학적 평가를 대량으로 확장 가능하게 수행할 수 있습니다.이 모델은 재학습 없이도 높은 다용성을 보여줍니다. MOF의 자유 에너지가 경험적 합성 가능성 임계값보다 높거나 낮은지 판단할 때 F1 점수가 97%에 달합니다.
"기계 학습을 통한 MOF 자유 에너지의 매우 정확하고 빠른 예측"이라는 제목의 관련 연구 결과가 ACS Publications에 게재되었습니다.
연구 하이라이트:
* 이 모델을 기반으로 연구자들은 높은 정확도로 자유 에너지를 예측하고 재학습 없이 완전한 분자 시뮬레이션 결과를 도출하여 MOF 합성의 타당성을 판단할 수 있습니다.
* 과거에는 실험실이나 분자 시뮬레이션을 통해 많은 시간을 필요로 했던 작업이 이제는 극히 짧은 시간 안에 완료될 수 있습니다.
이 방법은 성능 기반 전산 MOF 스크리닝에서 기계 학습 기반 자유 에너지 예측을 초기 또는 후기 스크리닝 도구로 활용할 수 있는 실현 가능한 접근 방식을 제공합니다.

서류 주소:
https://pubs.acs.org/doi/10.1021/jacs.5c13960
저희 공식 위챗 계정을 팔로우하고 백그라운드에서 "무료 에너지 예측"이라고 답장하시면 전체 PDF 파일을 받으실 수 있습니다.
더 많은 AI 프런티어 논문:
MOFMinE: 100만 개의 MOF 프로토타입을 다룹니다
모델 학습을 지원하기 위해,연구팀은 약 백만 개의 MOF 프로토타입을 포함하는 방대한 MOF 데이터 세트인 MOFMinE를 구축했습니다.다음 그림에서 보는 바와 같이, 구성 요소 선택 및 토폴로지 템플릿 매핑부터 기능 수정에 이르기까지 전체 프로세스에 대한 정보가 포함되어 있습니다.
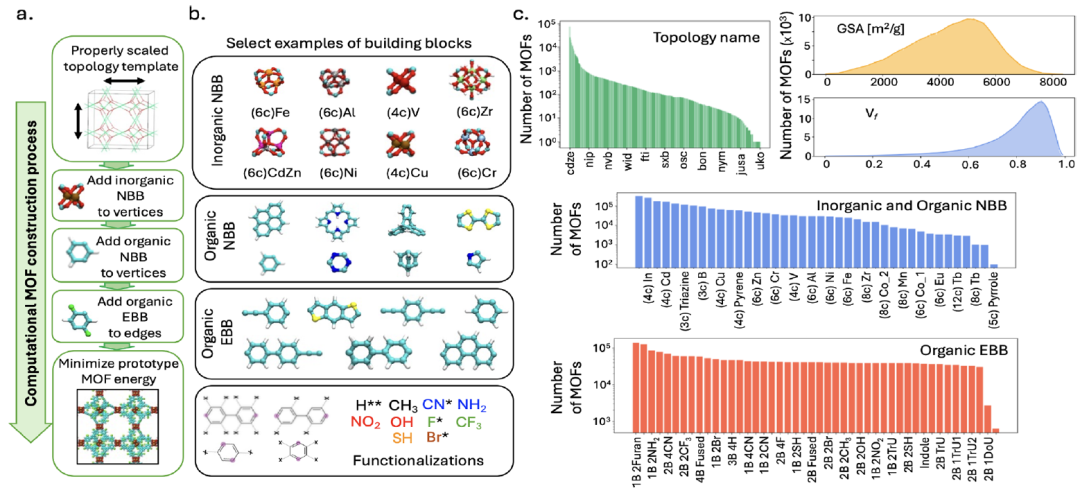
시공 방법
이 데이터 세트는 ToBaCCo-3.0 플랫폼을 기반으로 생성되었습니다. 각 MOF는 구성 빌딩 유닛을 적절한 크기(빌딩 유닛 크기에 맞게)로 조정된 위상 템플릿에 매핑하여 생성됩니다. 이 템플릿은 MOF 단위 셀 내에서 빌딩 유닛의 공간적 배열과 연결성을 안내합니다. ToBaCCo 빌딩 유닛은 매핑 위치에 따라 노드 빌딩 블록(NBB) 또는 에지 빌딩 블록(EBB)으로 분류됩니다. 노드 빌딩 유닛은 템플릿의 꼭짓점에 매핑되고, 에지 빌딩 유닛은 템플릿의 모서리에 매핑됩니다. NBB는 무기 또는 유기일 수 있으며, 무기 NBB는 소위 MOF 2차 빌딩 유닛(SBU)에 해당하고, 유기 NBB는 EBB와 결합하여 MOF 커넥터를 형성합니다.
데이터 규모 및 다양성
MOFMinE는 1,393개의 위상학적 템플릿, 27개의 무기 NBB, 14개의 유기 NBB 및 19개의 기본 EBB를 포함하고 있으며 13가지 기능적 변형을 포괄하여 화학적 및 위상학적 구조의 다양성을 보장합니다.이 데이터베이스는 0.01~0.99 범위의 공극률, 26~8382 m²/g 범위의 표면적(GSA), 2.6~127.7 Å 범위의 최대 기공 크기(LPD)를 포함하며, MOF의 구조적 공간을 완전히 포괄합니다.
자유 에너지 하위 집합
이 100만 개의 MOF 프로토타입 중 65,574개의 구조에 대해 자유 에너지 데이터를 수집했습니다.이 하위 집합에는 379개의 위상학적 템플릿, 6개의 무기 NBB, 11개의 유기 NBB, 그리고 13가지 기능화 변형이 적용된 12개의 기본 EBB가 포함되어 있습니다. 이 하위 집합의 다공성 특성은 Vf가 0.01에서 0.97, GSA가 38에서 7304 m²/g, LPD가 2.6에서 87.8 Å 범위에 있습니다. 이 데이터 세트는 자유 에너지 예측의 미세 조정 및 LLM 테스트에 사용되었습니다.
MOF 자유 에너지의 효율적인 예측을 위한 MOFSeq-LMM 모델
MOFMinE 데이터셋의 지원을 받아,연구팀은 MOF의 자유 에너지를 효율적으로 예측하고 구조에서 특성에 이르기까지 데이터 기반 설계를 실현하기 위해 MOFSeq-LMM 모델 프레임워크를 구축했습니다.이 프레임워크의 핵심 아이디어는 MOF의 구조 정보를 컴퓨터가 이해할 수 있는 순차 표현(MOFSeq)으로 변환하고 이를 학습 및 예측을 위한 대규모 언어 모델과 결합하여 물리화학적 정보를 보존하면서 계산 비용을 크게 줄이는 것입니다.
MOFSeq 특성화
기존 표현 전략의 한계를 극복하고 대규모 언어 모델을 최대한 활용하여 MOF 속성 예측을 광범위하게 수행하기 위해,연구진은 MOFSeq라는 새로운 문자열 기반 서열 표현 방법을 개발했습니다. 이 방법은 간결하면서도 정보량이 풍부하며, MOF의 국소적 및 전역적 구조적 특징을 최적화된 방식으로 인코딩합니다.이를 통해 언어 모델을 효율적이고 확장 가능하게 처리할 수 있습니다.
MOFSeq에서 로컬 정보는 주로 구성 요소의 원자 구성 및 내부 연결 정보를 포함하고, 글로벌 정보는 주로 MOF 구성 요소에 대한 고수준 설명과 구성 요소 간의 연결 패턴을 포함합니다. 로컬 정보는 MOFid 도구를 통해 얻고, 글로벌 정보는 아래 그림과 같이 ToBaCCo-3.0을 사용합니다.
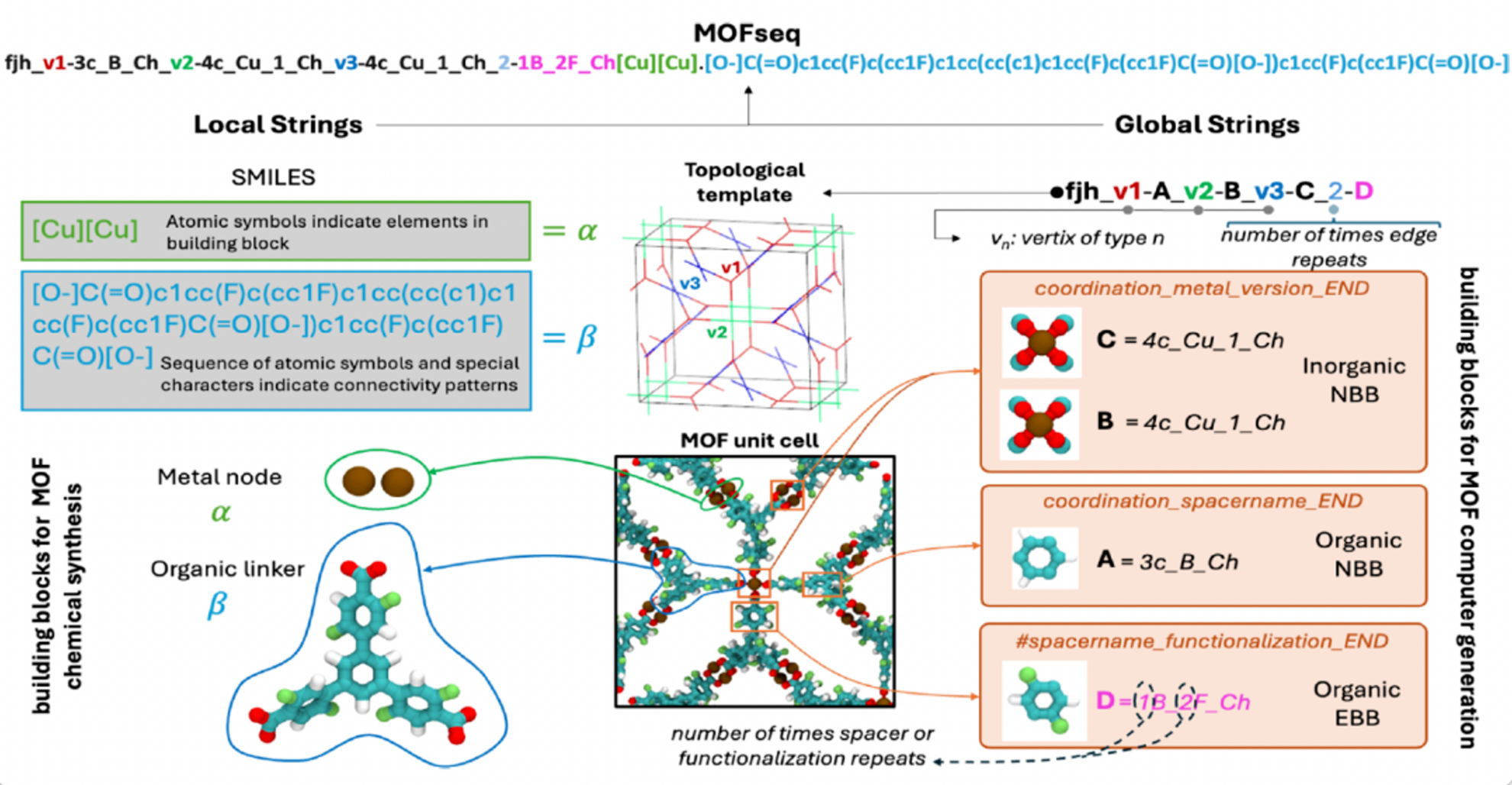
MOF 데이터베이스 구축 및 데이터 처리
위에서 설명한 방법을 기반으로 MOFMinE 데이터셋을 구축한 후, ToBaCCo로 생성된 모든 MOF 프로토타입을 LAMMPS(2020년 10월 29일 버전)의 UFF4MOF 힘장을 사용하여 최적화하여 최종 MOF 구조를 얻었습니다.
ToBaCCo-3.0을 사용하여 생성된 데이터 세트에는 각 MOF를 나타내는 MOF 이름과 해당 CIF 파일만 포함되어 있습니다. 그러나 MOFSeq에는 MOF 이름과 MOFid가 모두 필요합니다.MOFid를 얻기 위해 연구진은 Bucior 등이 개발한 MOFid 생성기를 사용했습니다.이 생성기는 MOF의 CIF 구조를 기반으로 MOFid와 MOFkey를 동시에 생성할 수 있습니다.
최종적으로, 793,079개의 MOFSeq 사전 학습 샘플은 634,463개의 샘플로 구성된 학습 세트, 79,308개의 샘플로 구성된 검증 세트, 그리고 79,308개의 샘플로 구성된 테스트 세트로 나뉘었습니다. 54,443개의 MOFSeq 미세 조정 데이터 포인트는 43,554개의 샘플로 구성된 학습 세트, 5,444개의 샘플로 구성된 검증 세트, 그리고 5,445개의 샘플로 구성된 테스트 세트로 나뉘었습니다.
LLM-소품 모형 디자인
MOFSeq 특성 분석을 기반으로, 연구팀은 재료 특성 예측을 위해 특별히 설계된 대규모 언어 모델인 LLM-Prop을 활용했습니다. LLM-Prop 모델은 약 3,500만 개의 파라미터를 가진 비교적 적당한 크기로, 학습 능력과 계산 효율성을 모두 확보합니다. 모델 입력 길이는 2,000개의 토큰으로 설정되어 있어 대부분의 MOF 구조 서열 정보를 수용할 수 있습니다. 어텐션 메커니즘을 통해, 이 모델은 서열 내에서 다양한 구성 요소와 토폴로지가 자유 에너지에 미치는 영향을 적응적으로 포착하여 전역적 및 지역적 특징에 대한 상호작용적인 표현을 형성합니다.
사전 훈련 및 미세 조정
* 사전 훈련 단계:
연구진은 MOFSeq 표현을 사용하여 MOF의 변형 에너지를 예측하도록 LLM-Prop 모델을 훈련시켰습니다. 변형 에너지는 계산 비용이 낮고 자유 에너지와 높은 상관관계를 가지기 때문에 선택되었습니다. 사전 훈련 과정에서 드롭아웃 비율을 0.2와 0.5로 설정하여 실험한 결과, 드롭아웃 비율 0.2가 사전 훈련 및 후속 작업 모두에서 더 나은 성능을 보였습니다. MOFSeq 입력 길이는 2000 토큰으로 설정했습니다.
미세 조정 단계:
설정은 사전 학습과 동일하지만, 모델 목표를 자유 에너지 예측으로 변경하고 학습 에포크 수를 200으로 늘렸습니다. LLM-Prop은 Llama 2의 약 1/2000 크기로 설계된 경량 모델로, 계산 효율성을 최우선으로 고려했습니다. 이러한 설계는 다음과 같은 장단점을 수반합니다. Llama 2나 GPT-2와 같은 대형 LLM을 미세 조정하는 것과 비교했을 때, LLM-Prop은 높은 성능을 달성하기 위해 더 많은 학습 에포크가 필요하지만, 작은 크기 덕분에 학습이 용이하고 효율적입니다.
MOF 합성 예측의 정확도는 97%에 달했습니다.
MOFSeq-LMM 모델을 학습시킨 후, 연구팀은 자유 에너지 예측, 합성 가능성 평가 및 다형성 MOF 스크리닝에서 모델의 성능을 체계적으로 평가했습니다. 실험 결과는 모델의 높은 정확도를 입증했을 뿐만 아니라 고처리량 MOF 설계 및 스크리닝 분야에서의 응용 가능성을 보여주었습니다.
자유 에너지 예측 성능
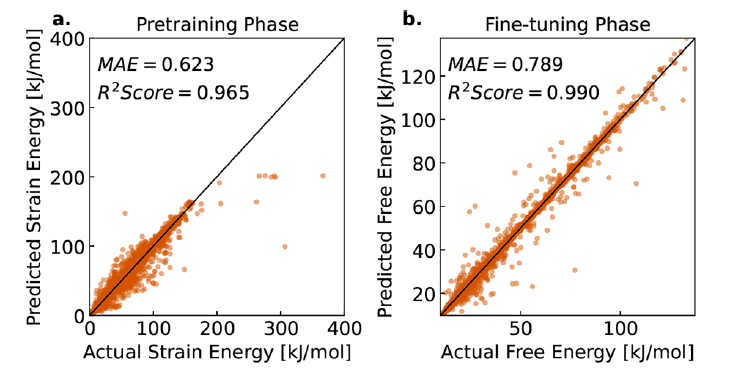
첫 번째,연구팀은 알려지지 않은 MOF 샘플에 대한 LLM-Prop의 자유 에너지 예측 성능을 평가했습니다.결과는 그림 b에서 볼 수 있듯이 모델이 평균 절대 오차(MAE) 0.789 kJ/mol MOFatom으로 자유 에너지를 정확하게 예측할 수 있으며 R² = 0.990의 높은 상관관계를 달성할 수 있음을 보여줍니다.이는 해당 모델이 대다수의 MOF 샘플에서 실제 값에 가까운 예측값을 제공할 수 있음을 의미합니다.
사전 학습 단계에서 모델은 변형 에너지 데이터를 사용하여 학습되었으며, 그림 a에서 볼 수 있듯이 MAE는 0.623 kJ/mol MOFatom, R² 값은 0.965를 달성했습니다. 이러한 높은 상관관계는 변형 에너지 데이터가 자유 에너지 예측을 위한 효과적인 예비 정보를 제공할 수 있음을 나타내며, 연구팀의 사전 학습 전략의 타당성을 입증합니다. 추가 분석 결과, 사전 학습된 변형 에너지와 미세 조정된 자유 에너지 사이에 높은 상관관계가 나타났으며, 이는 변형 에너지가 모델 학습에서 저비용의 대체 지표로서 유용함을 보여줍니다.
절제 실험 결과
모델 성능 저하의 원인을 더 깊이 이해하기 위해 연구팀은 체계적인 어블레이션 실험을 수행했습니다. 이 실험에서는 지역적 특징, 전역적 특징, 사전 학습이 자유 에너지 예측에 미치는 영향을 살펴보았습니다. 결과는 아래 표에 나와 있습니다.
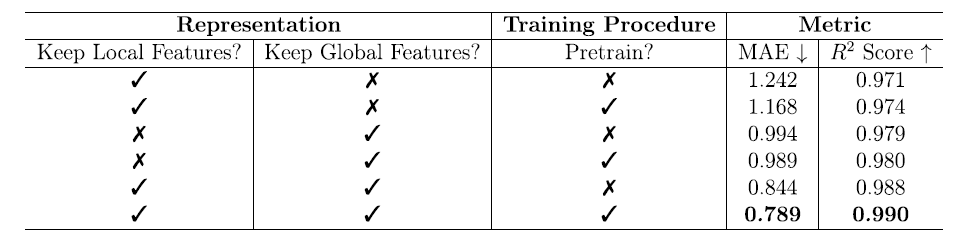
지역적 특징만 사용했을 때: 사전 학습을 통해 MAE는 1.242에서 1.168 kJ/mol MOFatom으로 감소했고, R²는 0.971에서 0.974로 증가했습니다. 이는 지역적 특징이 제한적일 때 사전 학습이 모델의 일반화 능력을 향상시킬 수 있음을 보여줍니다.
* 글로벌 기능에만 해당:
이 방법은 로컬 특징만을 사용하는 경우보다 성능이 현저히 우수하며, MAE는 1.0 kJ/mol MOFatom 미만으로 감소하고 R²는 약 0.980까지 증가합니다. 사전 학습은 이 경우 상대적으로 작은 영향을 미치는데(MAE는 0.994에서 0.989 kJ/mol MOFatom으로 감소하고 R²는 0.979에서 0.980으로 증가), 이는 전역 특징 자체가 더 많은 작업 정보를 포함하고 있으며 효과적인 학습을 달성하기 위해 사전 학습에 덜 의존해도 된다는 것을 나타냅니다.
* 지역적 특징과 글로벌 특징의 조합:
사전 학습을 통해 모델은 MAE 0.789 kJ/mol MOFatom 및 R² 0.990의 최적 성능을 달성했으며, 이는 두 가지 유형의 특징 간의 시너지 효과가 예측 정확도 향상에 매우 중요하다는 것을 보여줍니다.
이번 제거 실험은 MOFSeq의 전역 및 지역 특징 설계와 사전 학습 전략이 모델의 예측 능력을 향상시키는 핵심 요소임을 명확히 보여줍니다.
합성 타당성 평가
산업 응용 분야에서는 단순히 자유 에너지의 절대값에 집중하는 것보다 MOF의 합성 가능성을 판단하는 것이 더 중요한 과제입니다. 연구팀은 자유 에너지 보정 지표인 ΔL_MFFL을 4.4 kJ/mol MOF 원자의 임계값으로 설정하고 MOF의 합성 가능성을 이진 분류 방식으로 예측했습니다. 실험 결과는 아래 그림에 나와 있습니다.
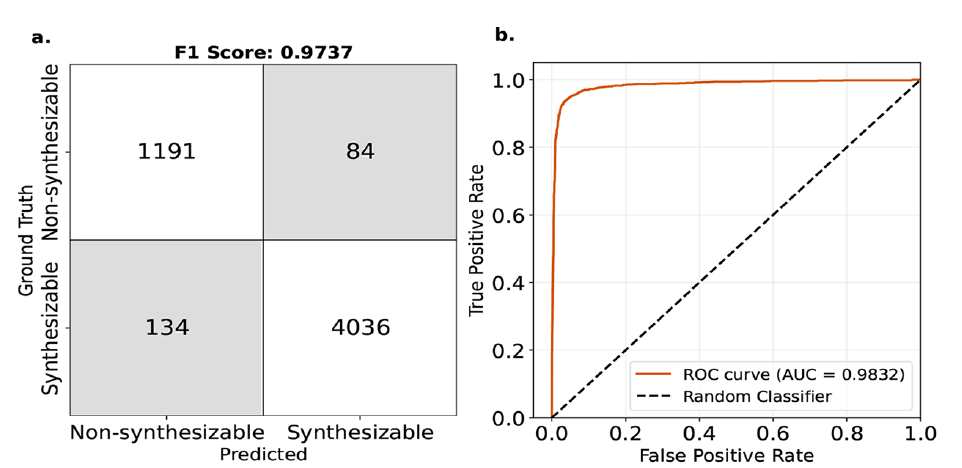
* 97%의 F1 점수는 모델의 우수한 일반화 능력을 보여줍니다.
* ROC 곡선 아래 면적(AUC)은 0.98에 달하는데, 이는 궁극적으로 모델이 특정 MOF를 합성할 수 있다고 판단할 때 잘못된 평가를 내릴 확률을 나타내며, 그 확률은 약 2%에 불과합니다.
다형성 MOF의 스크리닝
다형성을 갖는 MOF 시스템의 경우,이번 실험을 통해 모델이 가장 안정적인 다형체를 식별하는 능력이 더욱 검증되었다.2~50개의 다형체를 포함하는 7,490개의 다형체 패밀리 중에서, 이 모델은 자유 에너지 차이가 0.16 kJ/mol MOFatom에 불과한 경우에도 가장 안정적인 다형체를 정확하게 선택할 수 있으며, 성공률은 약 63%입니다. 자유 에너지 차이가 0.49 kJ/mol MOFatom으로 증가하면 성공률은 89%로 증가합니다.
전반적으로, 해당 모델은 다형성 인식 작업에서 평균 약 781 TP3T의 성공률을 달성했습니다.아래 그림에서 볼 수 있듯이, 이는 실험적 스크리닝 전에 대량 예측을 수행하는 데 매우 유용한 가치를 지닙니다.

실제 응용 관점에서, LLM이 열역학적 안정성과 다형성 경쟁 평가를 통해 특정 MOF 설계가 합성 가능하다고 판단할 경우, 그 정확성 확률은 대략 76%에서 98% 사이입니다. 확률이 높은 경우는 MOF에 경쟁하는 다형체가 없는 경우입니다.
인공지능은 MOF 및 재료 과학 연구의 패러다임을 재편하고 있습니다.
2025년 10월 8일스웨덴 왕립 과학 아카데미는 MOF 분야에 대한 연구 공헌을 인정하여 교토 대학의 기타가와 스스무 교수, 멜버른 대학의 리처드 롭슨 교수, 캘리포니아 대학 버클리 캠퍼스의 오마르 야기 교수에게 2025년 노벨 화학상을 수여하기로 결정했습니다.이 역사적인 순간을 되돌아보면, MOF 연구는 30년이 넘는 발전 과정을 거쳐 초기 구조 구축 및 합성 탐색에서 성능 조절, 응용 분야 확장, 그리고 산업화로 점진적으로 나아가고 있습니다. 이러한 중요한 이정표를 넘어, 재료과학은 새로운 변수, 즉 인공지능의 심층적인 참여를 맞이하고 있으며, 이는 MOF는 물론 재료과학 분야 전체의 연구 패러다임과 혁신 속도를 재편하고 있습니다.
표준화된 명명법이 부족한 방대하고 복잡한 MOF 세계의 과제에 대응하여 2025년 10월에토론토 대학과 캐나다 국립 연구 위원회 산하 청정 에너지 혁신 연구 센터의 연구팀은 구조화되고 확장 가능하며 확장 가능한 지식 그래프인 MOF-ChemUnity를 제안했습니다.이 방법은 LLM(Long-Term Modeling)을 활용하여 문헌상의 MOF 이름과 동의어, 그리고 CSD(Crystal Database of Data)에 등록된 결정 구조 간의 신뢰할 수 있는 일대일 대응 관계를 구축함으로써 MOF 이름과 동의어, 그리고 결정 구조 간의 모호성을 해소합니다. 현재 버전의 MOF-ChemUnity는 약 10,000편의 과학 논문과 15,000개 이상의 CSD 결정 구조 및 그 계산 화학적 특성을 기계가 처리 가능한 형식으로 통합하고 있습니다.
논문 제목: MOF-ChemUnity: 금속-유기 골격체 연구를 위한 문헌 기반 대규모 언어 모델
서류 주소:https://pubs.acs.org/doi/10.1021/jacs.5c11789
MOF 소재의 합리적인 설계에 있어, 합성 전 구조 예측은 효율적이고 목표 지향적인 합성을 달성하는 데 있어 항상 핵심적인 과제였습니다. 이러한 문제를 해결하기 위해,상하이 자오퉁 대학의 최용 교수와 공웨이 교수가 이끄는 연구팀은 MOF의 금속 노드 유형을 빠르고 정확하게 예측할 수 있는 데이터 기반 기계 학습 워크플로우를 개발했습니다.이 방법은 유기 리간드의 구조 정보를 입력으로 사용하여 머신러닝 모델을 통해 리간드 특징과 금속 노드 유형 간의 매핑 관계를 설정함으로써 합성 전에 형성될 수 있는 금속 노드 유형을 효과적으로 예측합니다. 학습 및 최적화된 머신러닝 예측 모델은 테스트 세트에서 91%의 예측 정확도, 89%의 정밀도, 85%의 재현율을 달성했습니다.
논문 제목: 데이터 기반 기계 학습을 활용한 금속-유기 골격체 내 금속 노드 유형 예측 및 링커 설계 지침, 그리고 역 C3H8/C3H6 분리 목표 설정
서류 주소:http://engine.scichina.com/doi/10.1007/s11426-025-2917-4
전통적인 MOF 연구는 흔히 구조나 물성에서 시작하여 국소 변수 제어와 광범위한 실험 또는 계산을 통해 목표 물질에 점진적으로 근접해 나가는 방식으로 진행되었습니다. 그러나 최근 연구에서는 출발점 자체가 바뀌고 있습니다. 연구자들은 먼저 계산적으로 실현 가능하고 타당한 물질 표현 시스템을 구축한 다음, 모델을 통해 어떤 구조적 조합이 물리적으로 타당하고, 열역학적으로 실현 가능하며, 합성적으로 가치 있는지 학습합니다. 모델이 수백만 개의 구조 공간에서 신뢰할 수 있는 열역학적 및 구조적 판단을 신속하게 제공할 수 있게 되면, 재료 연구의 초점은 "계산하고 측정하는 방법"에서 "문제를 정의하고, 표현을 구축하고, 결정 경계를 설정하는 방법"으로 옮겨갈 것입니다. 이는 30년 이상 축적된 구조적, 화학적 지식을 바탕으로 MOF 연구가 도약할 수 있는 차세대 방법론적 혁신일 것입니다.
참고문헌:
1.https://pubs.acs.org/doi/10.1021/jacs.5c13960
2.https://phys.org/news/2026-01-tool-narrows-ideal-metal-frameworks.html








