HyperAI
Command Palette
Search for a command to run...
WenetSpeech-쓰촨-충칭 방언 음성 데이터셋
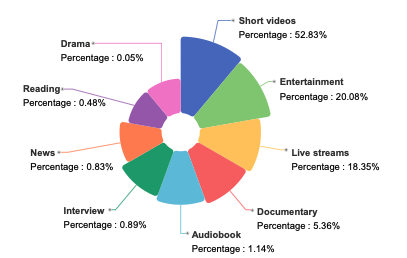
WenetSpeech-Chuan은 2025년 서북공업대학교가 Hillbeak, 중국통신 인공지능연구소 등과 협력하여 공개한 대규모 쓰촨-충칭 방언 음성 데이터셋입니다. 관련 연구 논문의 제목은 "WenetSpeech-Chuan: 방언 음성 처리를 위한 풍부한 주석이 포함된 대규모 쓰촨어 코퍼스". 이 데이터셋은 10,013시간 분량의 실제 쓰촨 및 충칭 방언 음성 데이터를 포함하며, 그중 3,714시간은 레이블링이 잘 된 데이터이고 6,299시간은 레이블링이 미흡한 데이터입니다. 데이터는 9가지 실제 시나리오를 포괄하며, 짧은 동영상이 52,831시간 분량이고 나머지는 엔터테인먼트, 라이브 스트리밍, 오디오북, 다큐멘터리, 인터뷰, 뉴스, 낭독, TV 드라마 등으로 구성되어 매우 다양하고 현실적인 음성 분포를 보여줍니다. 모든 음성 데이터에는 텍스트 내용, 신뢰도 수준, 음질 점수, 화자의 성별 및 연령, 감정 태그와 같은 풍부한 주석 정보가 함께 제공됩니다.
이 데이터셋은 커뮤니티 사용자가 기여한 것이며 교육 및 정보 제공 목적으로만 사용됩니다. 저작권 침해와 관련된 콘텐츠가 있는 경우 [email protected]로 문의하시면 신속하게 검토 및 삭제 처리하겠습니다.