HyperAI
Command Palette
Search for a command to run...
MOSS: テキスト音声対話生成
1. チュートリアルの概要

このチュートリアルでは、リソースとして単一の RTX 5090 カードを使用します。
2. プロジェクト例
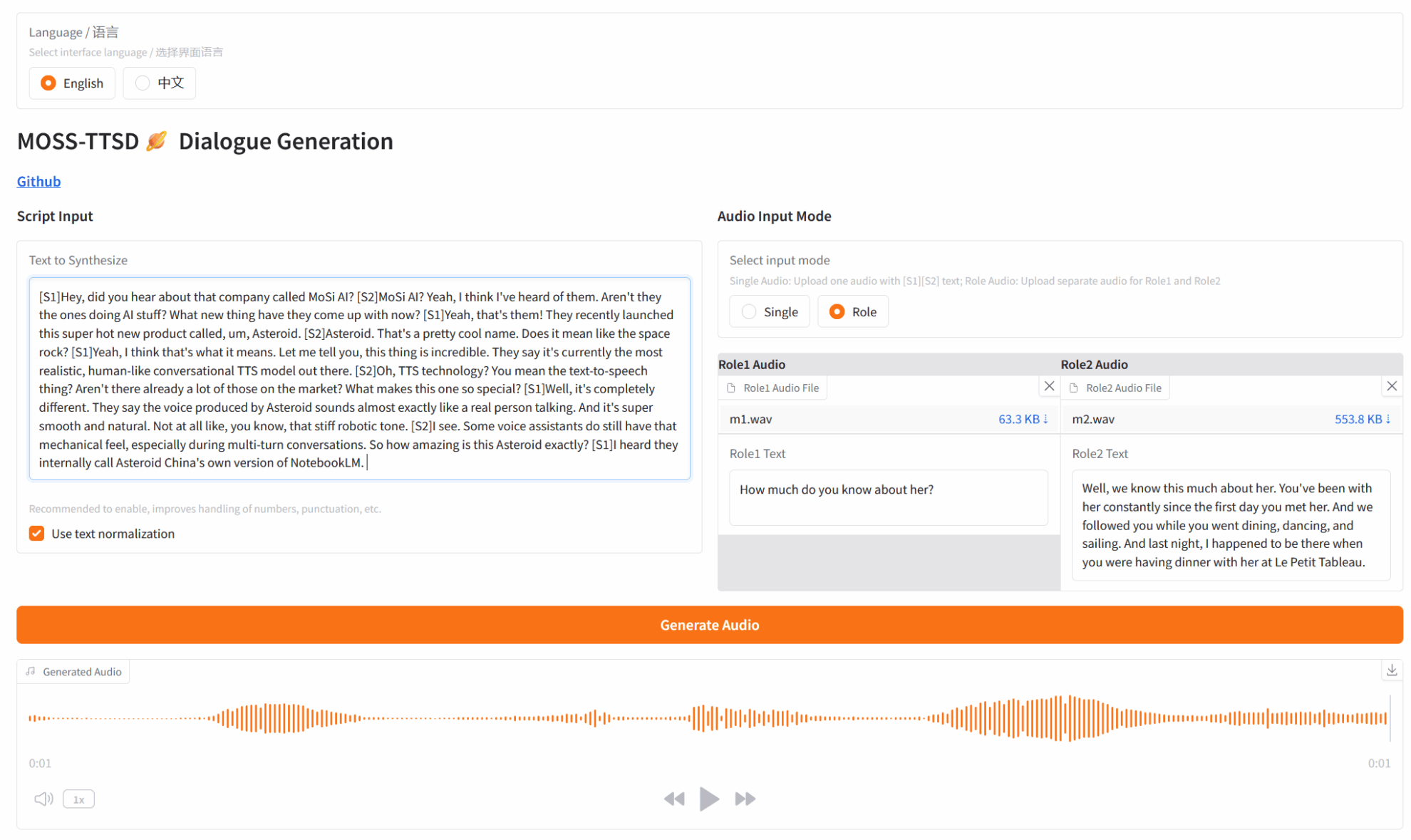
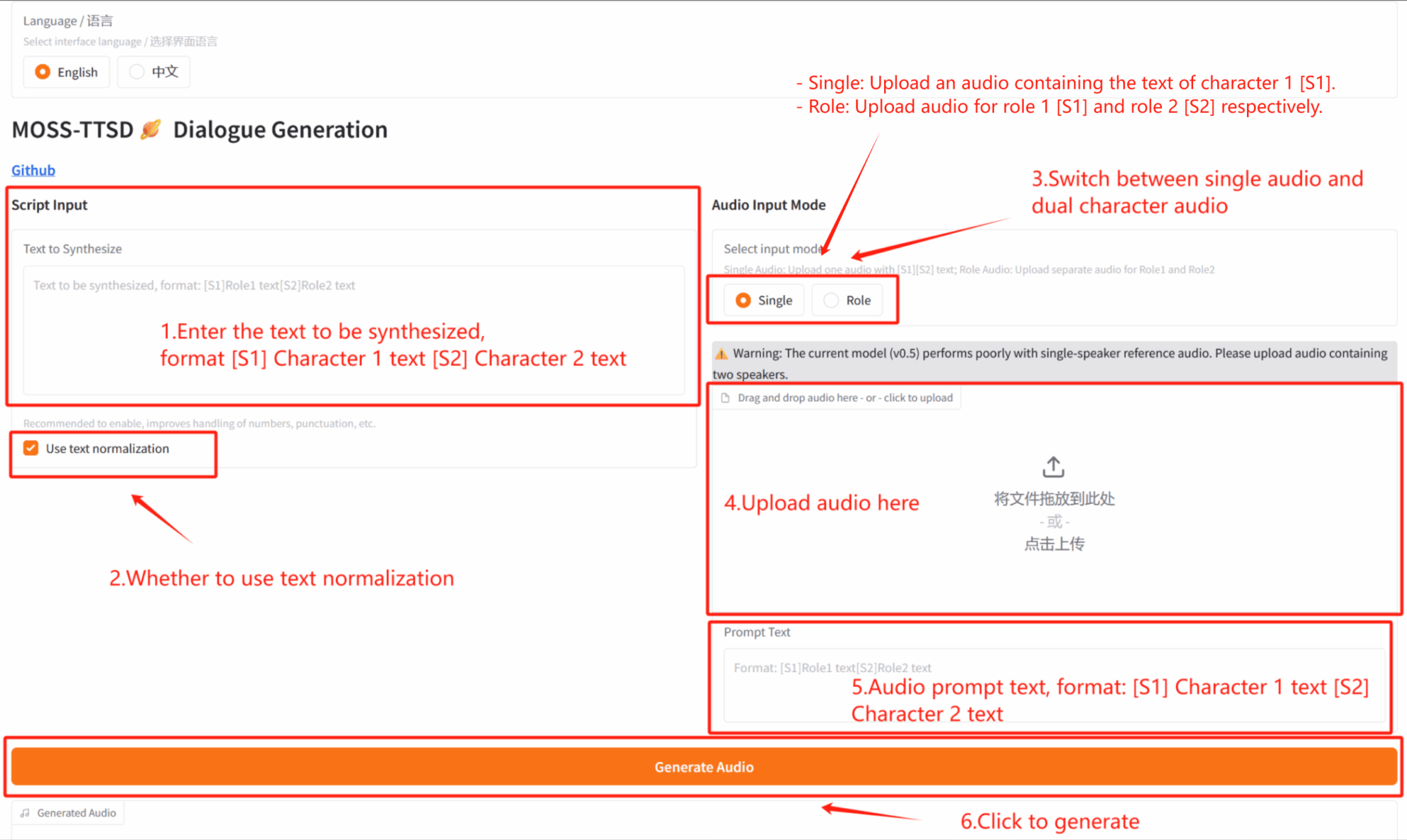
3. 操作手順
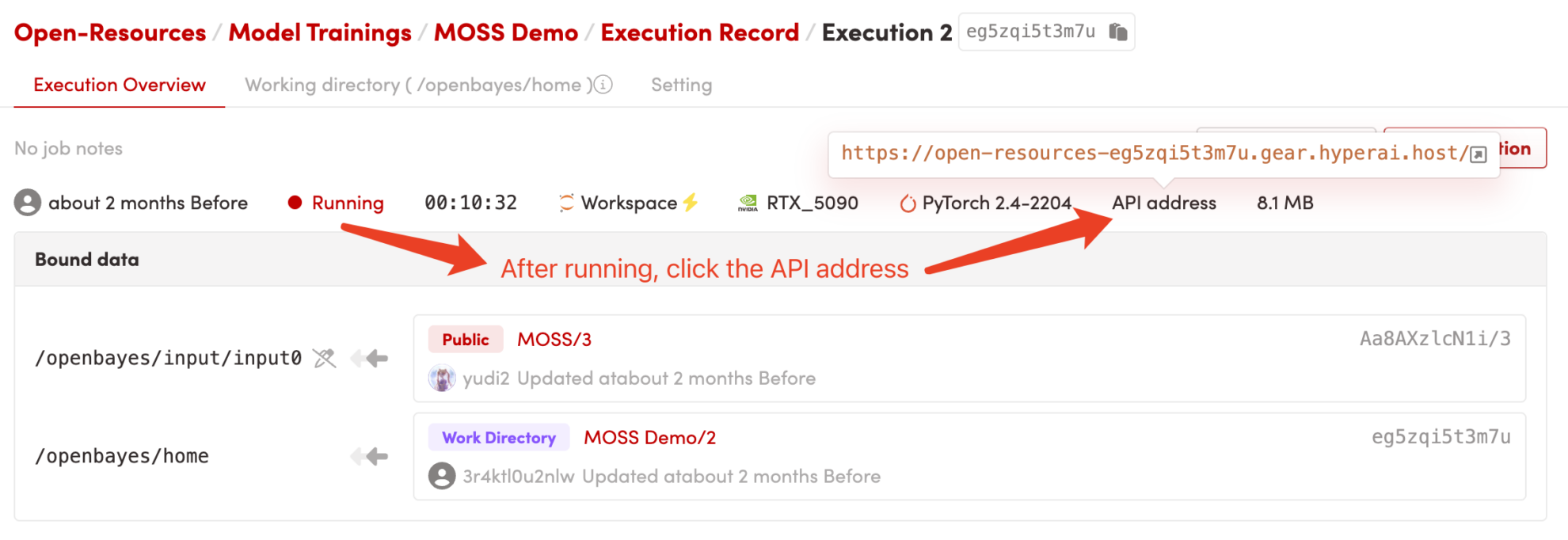
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
2. 使用手順
「Bad Gateway」と表示される場合は、モデルが初期化中です。モデルのサイズが大きいため、2~3分ほどお待ちいただき、ページを更新してください。Safariブラウザをご利用の場合、音声が直接再生されない場合がありますので、再生前にダウンロードしてください。
※このチュートリアルでは、「オーディオ入力モード」でシングルプレイヤーオーディオ生成(シングル)と2プレイヤーダイアログオーディオ生成(ロール)を選択できます。
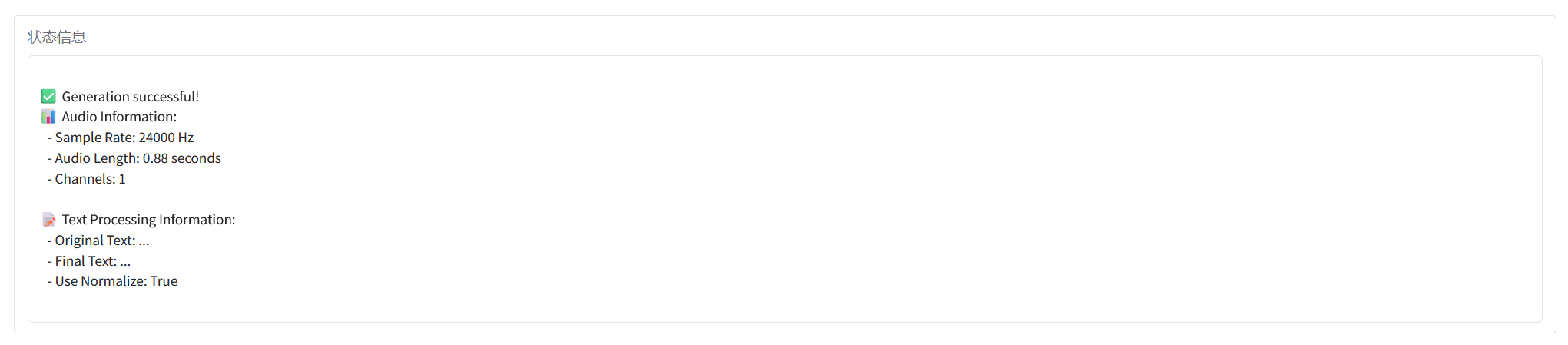
引用情報
このプロジェクトの引用情報は次のとおりです。
@article{moss2025ttsd,
title={Text to Spoken Dialogue Generation},
author={OpenMOSS Team},
year={2025}
}このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。