HyperAI
Command Palette
Search for a command to run...
MonkeyOCR: 構造認識関係のトリプルパラダイムに基づく文書解析
1. チュートリアルの概要

MonkeyOCRは、華中科技大学がKingsoft Officeと共同で2025年6月5日にオープンソース化した文書解析モデルです。このモデルは、非構造化文書の内容を効率的に構造化情報に変換します。正確なレイアウト分析、コンテンツ認識、論理ソートに基づいて、文書解析の精度と効率を大幅に向上させます。従来の方法と比較して、MonkeyOCRは複雑な文書(数式や表を含む文書など)の処理において非常に優れたパフォーマンスを発揮し、平均5.11 TP3Tのパフォーマンス向上を達成し、数式解析と表解析ではそれぞれ15.01 TP3Tと8.61 TP3Tの向上を達成しました。このモデルは複数ページの文書の処理に優れており、1秒あたり0.84ページを達成し、他の同様のツールをはるかに上回っています。MonkeyOCRは、学術論文、教科書、新聞など、さまざまな文書タイプをサポートし、複数の言語と互換性があり、文書のデジタル化と自動処理を強力にサポートします。関連する研究論文も入手可能です。 MonkeyOCR: 構造・認識・関係のトリプレットパラダイムによる文書解析 。
主な機能:
- ドキュメントの解析と構造化: さまざまな形式 (PDF、画像など) のドキュメント内の非構造化コンテンツ (テキスト、表、数式、画像など) を、構造化された機械可読情報に変換します。
- 多言語サポート:中国語や英語を含む複数の言語をサポートします。
- 複雑なドキュメントを効率的に処理: 複雑なドキュメント (数式、表、複数列のレイアウトなどを含むドキュメントなど) を処理するときに優れたパフォーマンスを発揮します。
- 高速な複数ページ ドキュメント処理: 0.84 ページ/秒の処理速度で複数ページ ドキュメントを効率的に処理します。これは、他のツール (MinerU 0.65 ページ/秒、Qwen2.5-VL-7B 0.12 ページ/秒など) よりも大幅に優れています。
- 柔軟な導入と拡張: さまざまな規模のニーズを満たすために、単一の NVIDIA 3090 GPU 上での効率的な導入をサポートします。
技術原理:
- 構造認識関係(SRR)トリプレットパラダイム:YOLOに基づく文書レイアウト検出器。文書内の主要要素(テキストブロック、表、数式、画像など)の位置とカテゴリを識別します。検出された各領域に対してコンテンツ認識を実行し、大規模マルチモーフィックモデル(LMM)を用いてエンドツーエンドの認識を実行することで、高い精度を確保します。ブロックレベルの読み順予測メカニズムに基づいて、検出された要素間の論理関係を決定し、文書の意味構造を再構築します。
- MonkeyDocデータセット:MonkeyDocは、390万件のインスタンスを収録し、中国語と英語の10種類以上の文書を網羅する、これまでで最も包括的な文書解析データセットです。このデータセットは、慎重な手動アノテーション、プログラムによる合成、そしてモデル駆動型の自動アノテーションを統合した多段階パイプラインに基づいて構築されています。MonkeyOCRモデルの学習と評価に使用され、多様で複雑な文書シナリオにおける強力な汎化能力を確保しています。
- モデルの最適化と展開:AdamWオプティマイザーとコサイン学習率スケジューリングを大規模データセットと組み合わせて学習することで、モデルの精度と効率性のバランスを確保します。LMDeplovツールをベースにしたMonkeyOCRは、単一のNVIDIA 3090 GPUで効率的に実行でき、高速な推論と大規模な展開をサポートします。
このチュートリアルでは、コンピューティング リソースとして単一の RTX 5090 グラフィック カードを使用します。
2. エフェクト表示
数式ドキュメントの例

表文書の例

新聞の例

財務報告書の例


3. 操作手順
1. コンテナを起動します
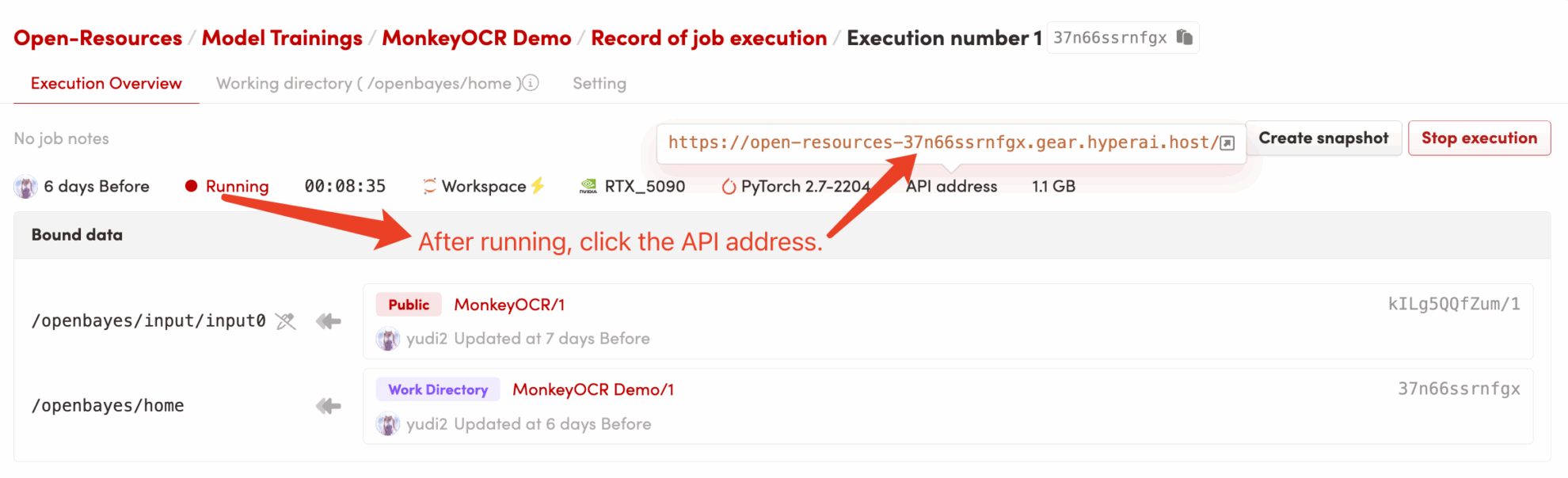
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。

引用情報
このプロジェクトの引用情報は次のとおりです。
@misc{li2025monkeyocrdocumentparsingstructurerecognitionrelation,
title={MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm},
author={Zhang Li and Yuliang Liu and Qiang Liu and Zhiyin Ma and Ziyang Zhang and Shuo Zhang and Zidun Guo and Jiarui Zhang and Xinyu Wang and Xiang Bai},
year={2025},
eprint={2506.05218},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.05218},
}
このノートブックはコミュニティユーザーによって提供されたものであり、教育および情報提供のみを目的としています。コンテンツに著作権侵害が含まれる場合は、[email protected]までご連絡ください。速やかに確認し、削除いたします。