Command Palette
Search for a command to run...
CPU展開NeuTTS-Air音声複製モデル
1. チュートリアルの概要

NeuTTS-Airは、Neuphonicが2025年10月にリリースしたエンドツーエンドの音声合成モデル(TTS)です。0.5B Qwen LLMバックボーンとNeuCodecオーディオコーデックをベースとし、オンデバイス展開とインスタントボイスクローニングにおける数ショット学習機能を実証しています。システム評価では、NeuTTS Airがオープンソースモデルの中で、特に超リアル合成とリアルタイム推論ベンチマークにおいてSOTAレベルに達していることが示されています。また、組み込みエージェントやスタイル転送などの新しいシナリオへの一般化、3秒オーディオクローニングのサポート、自然な会話コンテンツの生成も可能です。学習後にはGGML/ONNXサポートとウォーターマークメカニズムが導入され、オンデバイスTTSと電力最適化評価においてオープンソース分野をリードしており、一部のシナリオはクローズドソースモデルに匹敵します。
このチュートリアルはCPUリソースを消費し、モデルは英語のみをサポートしており、音声合成には30秒以上かかります。より高速な処理速度を体験したい場合は、シングルカードRTX 5090クローンチュートリアルをご利用ください。NeuTTS-Air: 軽量で効率的な音声複製モデル”。
2. プロジェクト例
3. 操作手順
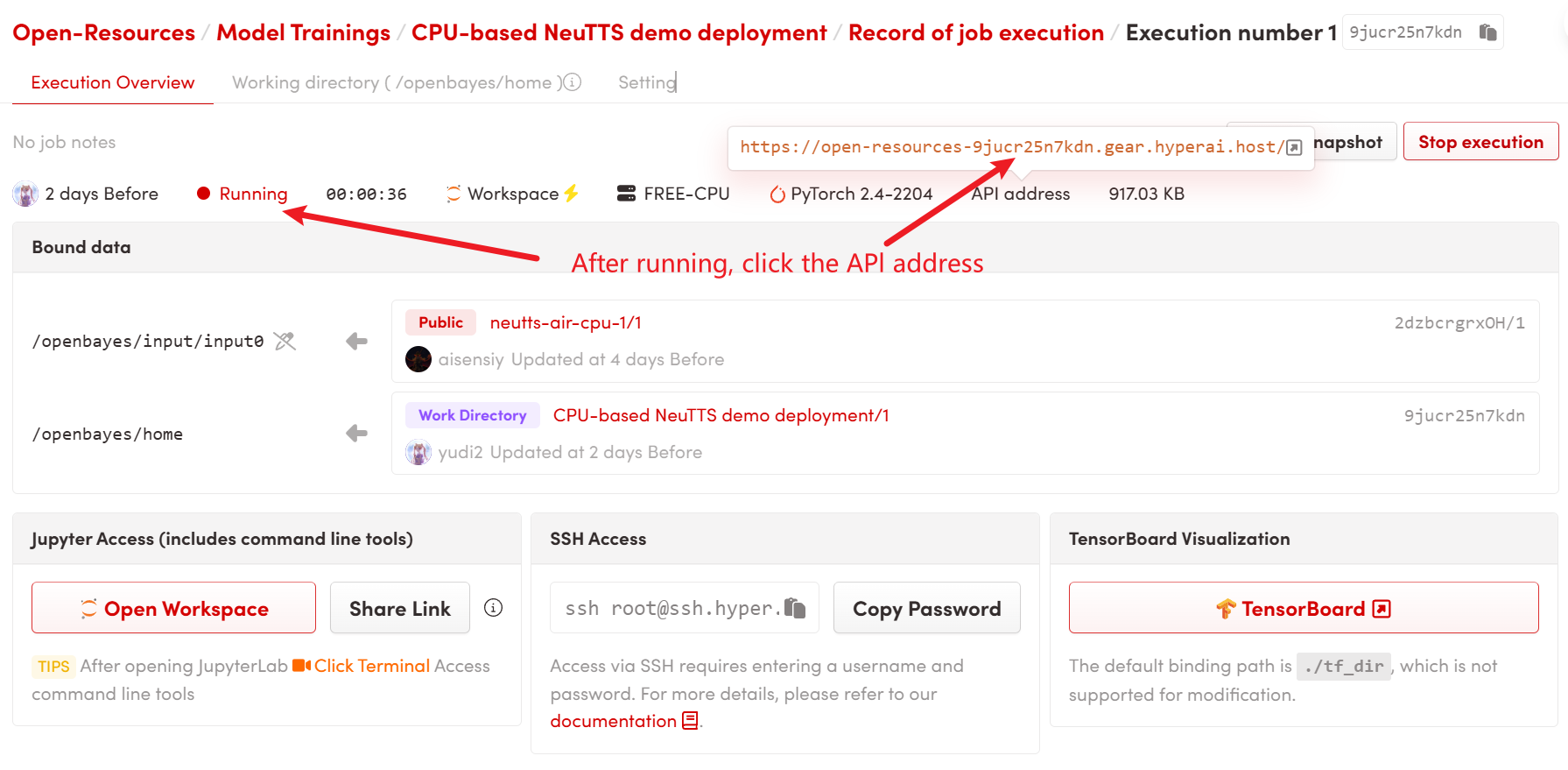
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
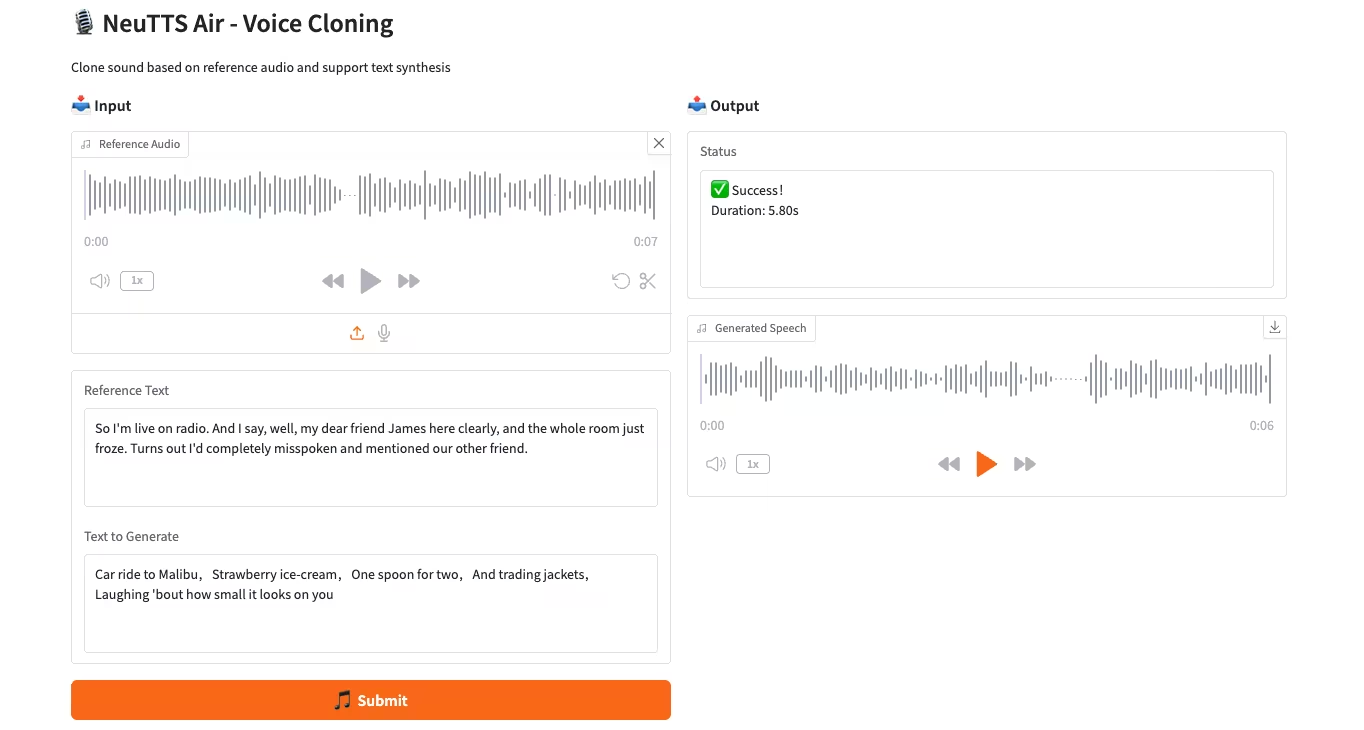
2. ウェブページに入ると、モデルを使用できます
「Bad Gateway」と表示される場合は、コードがバックグラウンドで実行されていることを意味します。2~3分ほどお待ちいただき、ページを更新してください。
Safari ブラウザを使用する場合、オーディオは直接再生されない場合があり、再生する前にダウンロードする必要があります。
利用手順
入力オーディオの最小の長さは 3 秒で、推奨される長さは 3 ~ 15 秒です。 出力オーディオの最大長は約30秒です