Command Palette
Search for a command to run...
Pusa-VidGen ビデオ生成モデルのデモ
1. チュートリアルの概要

2025年7月25日にYaofang-Liuチームが提案したPusa V1は、高効率のマルチモーダル動画生成モデルです。ベクトル化時間適応(VTA)技術を基盤とし、従来の動画生成モデルにおける高いトレーニングコスト、低い推論効率、時間的一貫性の低さといった中核問題を解決します。大規模データと計算能力に依存する従来の手法とは異なり、Pusa V1はWan2.1-T2V-14Bに基づく軽量な微調整戦略により、画期的な最適化を実現します。トレーニングコストはわずか500ドル(類似モデルの200分の1)、データセットはわずか4Kサンプル(類似モデルの2500分の1)で済み、8基の80GB GPUでトレーニングを完了できるため、動画生成技術の応用ハードルを大幅に下げます。同時に、強力なマルチタスク機能を備え、テキスト駆動型ビデオ(T2V)や画像誘導型ビデオ(I2V)だけでなく、ビデオ補完、最初と最後のフレーム生成、シーン間遷移といったゼロショットタスクもサポートし、特定シーン向けの追加トレーニングは不要です。さらに重要なのは、その生成性能が特に優れていることです。ショートステップ推論戦略(わずか10ステップでベースモデルを上回る)を採用し、VBench-I2Vプラットフォームで合計87.32%というスコアを達成し、手足の動きや照明の変化といった動的ディテールの再現と時間的コヒーレンスにおいて優れた性能を示しました。さらに、VTA技術による非破壊適応メカニズムは、ベースモデルに時間的ダイナミック機能を注入しながら、元のモデルの画像生成品質を維持し、「1+1>2」効果を実現します。導入レベルでは、推論の低レイテンシにより、迅速なプレビューから高解像度出力まで、多様なニーズに対応し、クリエイティブデザイン、短編動画制作などのシナリオに適しています。関連論文の結果は… PUSA V1.0: ベクトル化されたタイムステップ適応により、$500 のトレーニングコストで Wan-I2V を上回る 。
このチュートリアルでは、デュアルカード RTX A6000 リソースを使用します。
2. プロジェクト例
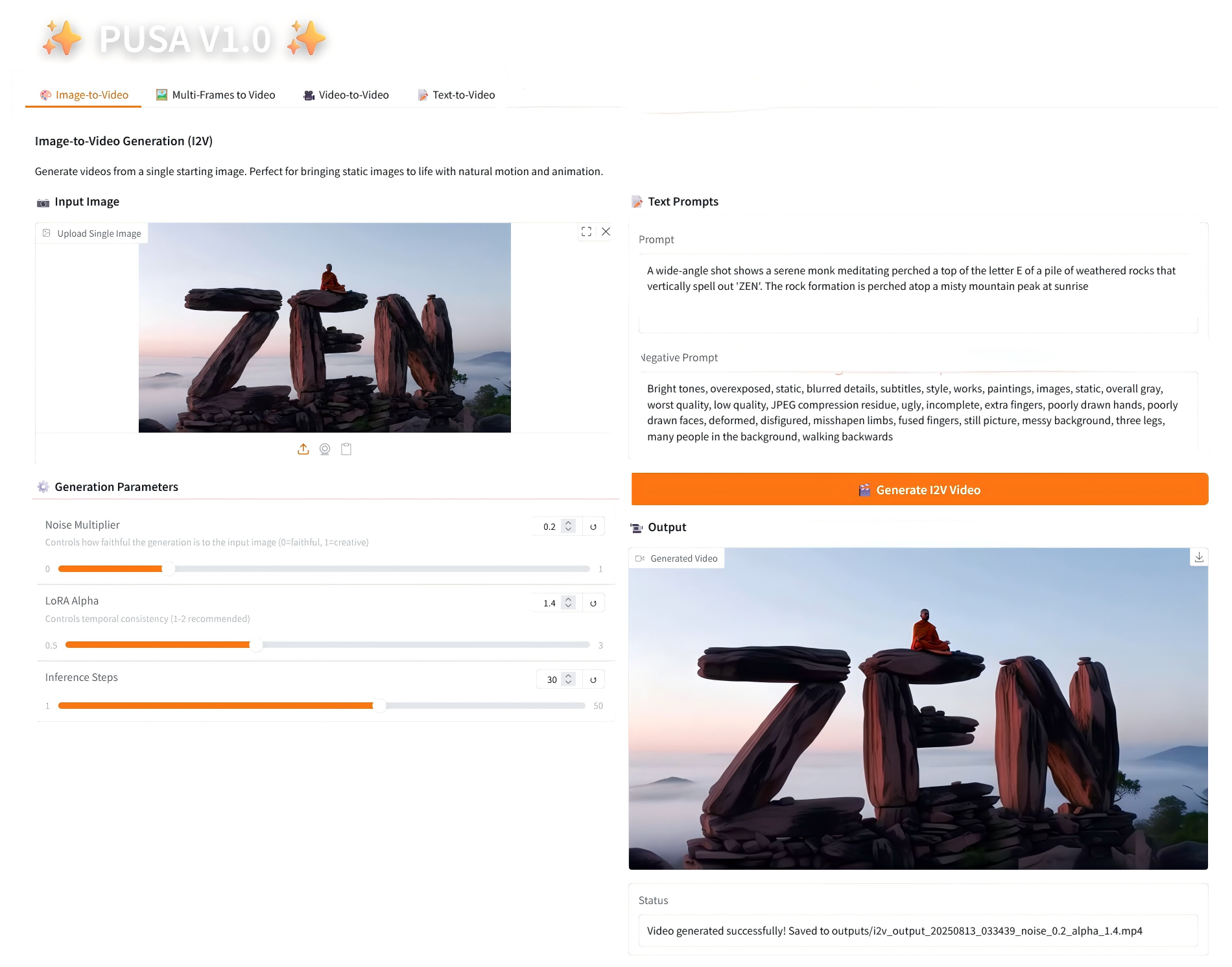
1. 画像から動画へ
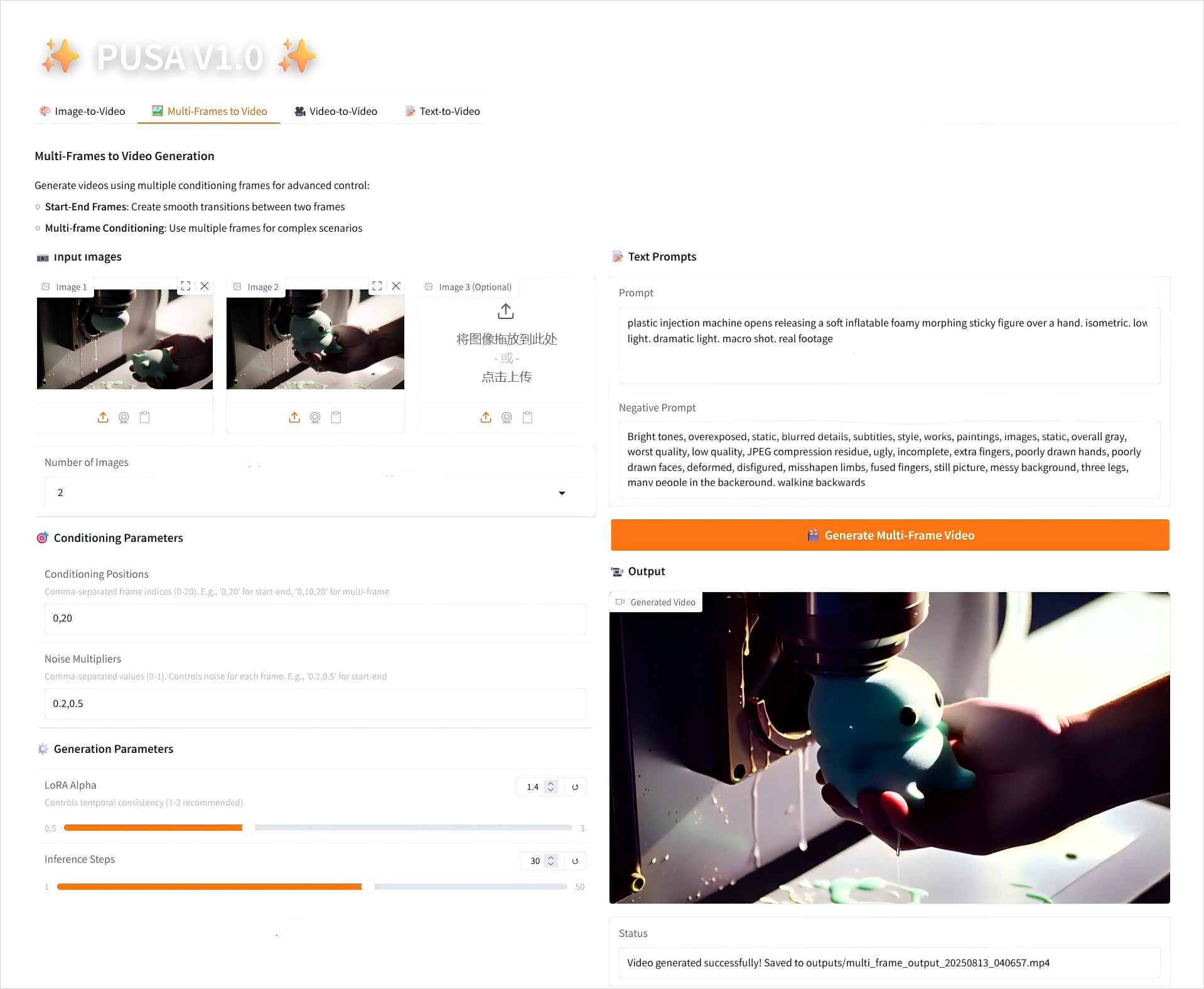
2. マルチフレームからビデオへ
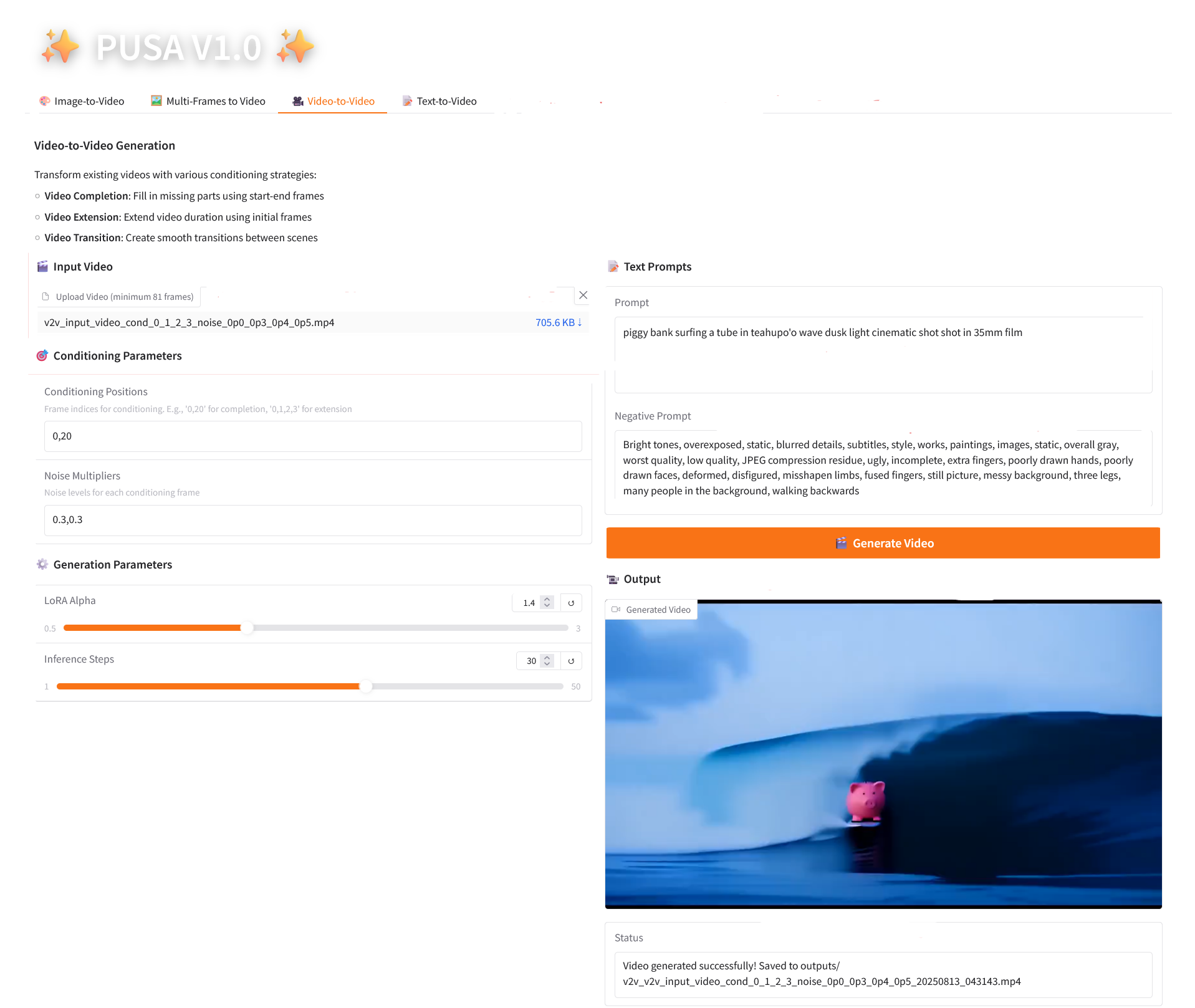
3. ビデオからビデオへ
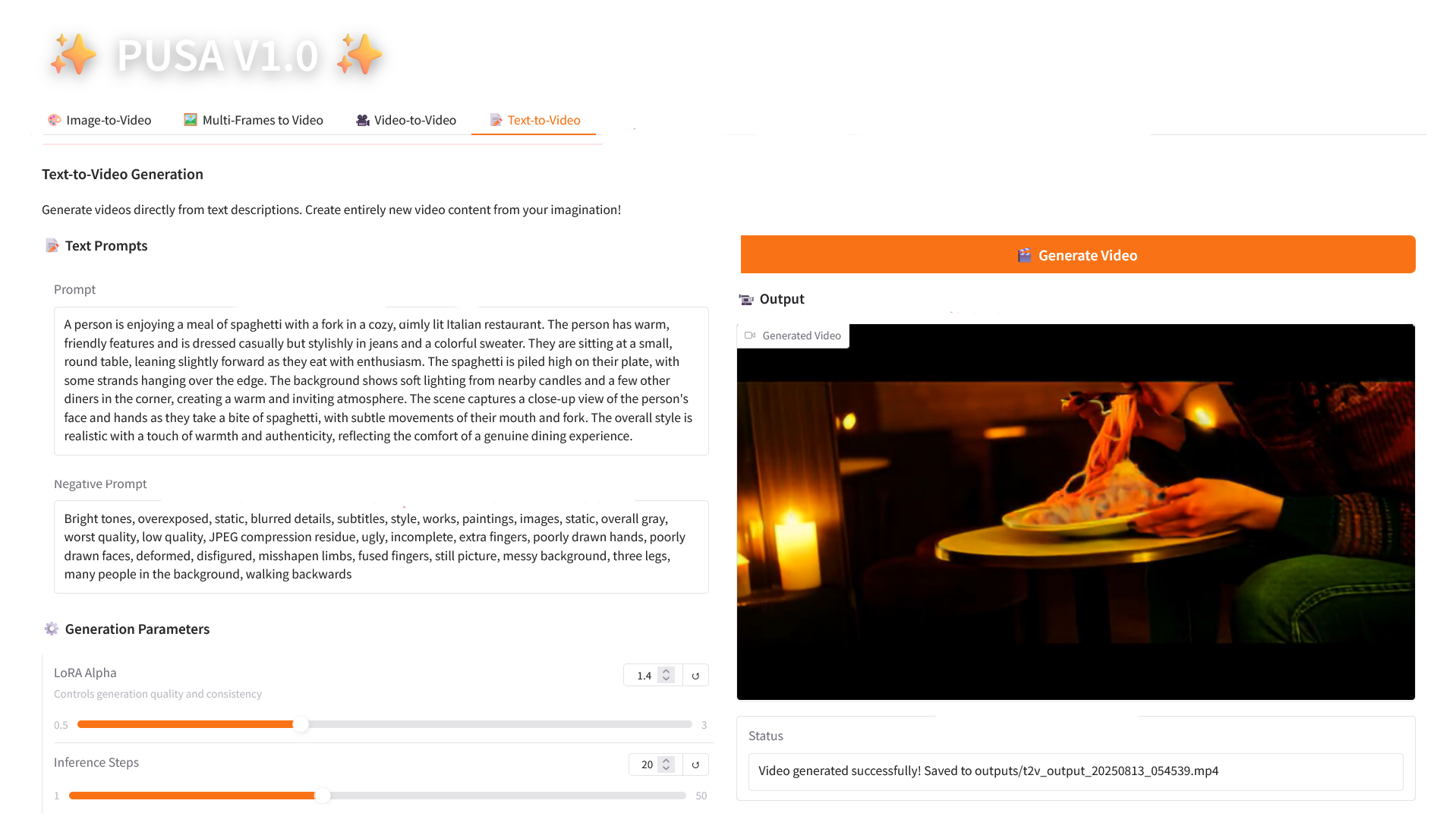
4. テキストからビデオへ
3. 操作手順
1. コンテナを起動した後、API アドレスをクリックして Web インターフェイスに入ります
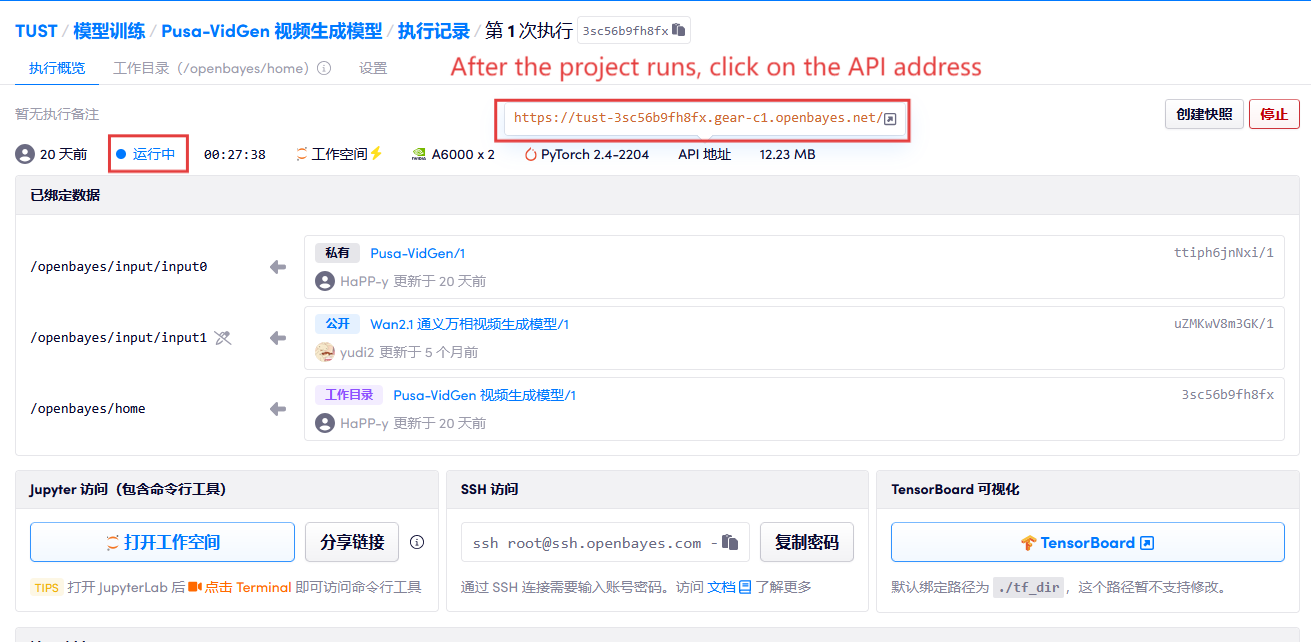
2. 使用手順
「Bad Gateway」と表示される場合、モデルが初期化中であることを意味します。モデルが大きいため、2〜3分ほど待ってページを更新してください。
2.1 画像からビデオへの変換
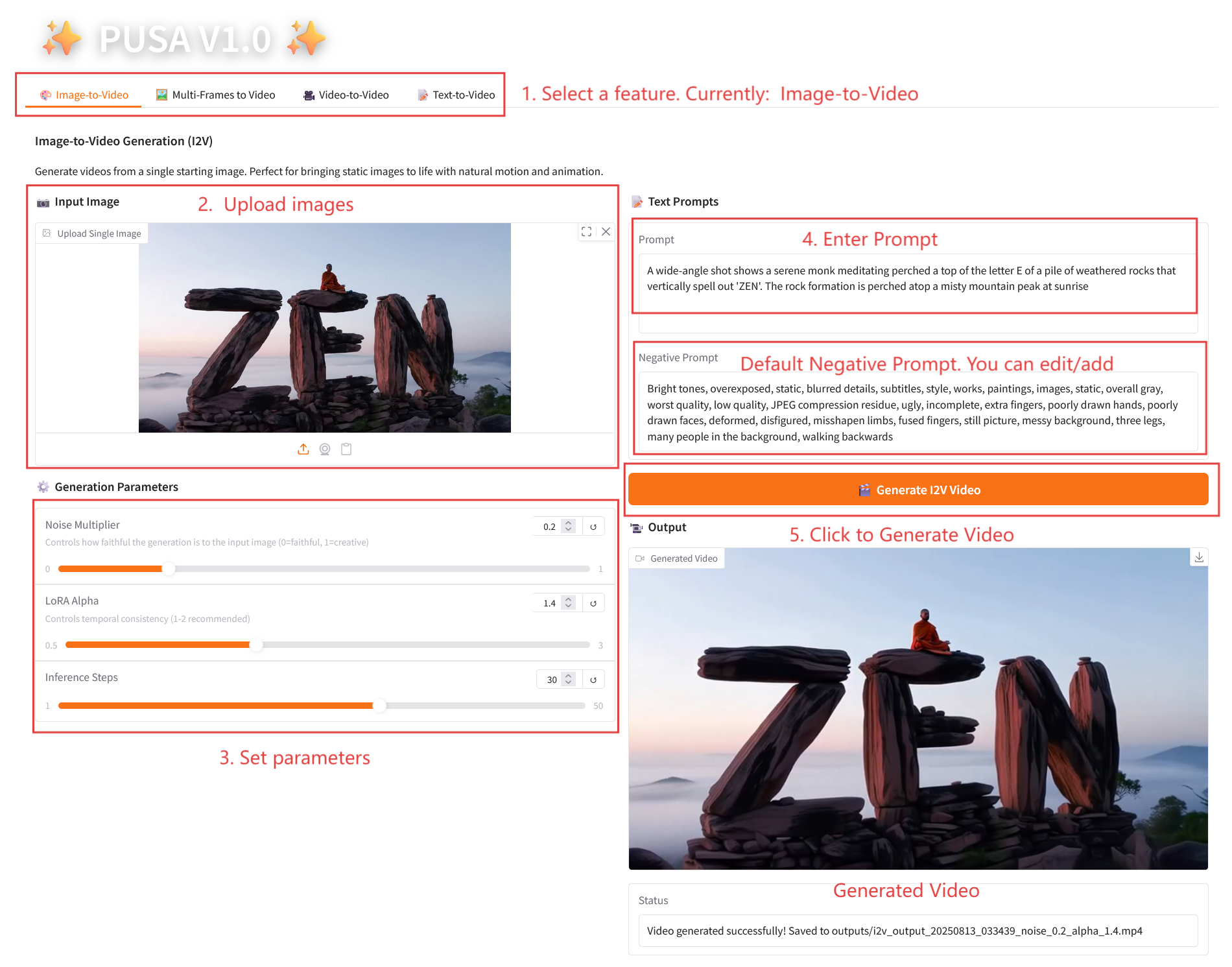
パラメータの説明
- 生成パラメータ
- ノイズ乗数: 0.0 から 1.0 まで調整可能、デフォルトは 0.2 (値が低いほど入力画像に忠実になり、値が高いほどクリエイティブになります)。
- LoRA Alpha: 0.1 ~ 5.0 で調整可能、デフォルトは 1.4 (スタイルの一貫性を制御します。高すぎると硬くなり、低すぎると一貫性が失われます)。
- 推論ステップ: 1 から 50 まで調整可能、デフォルトは 10 です (ステップ数が多いほど詳細度は高くなりますが、時間の消費量も直線的に増加します)。
2.2 マルチフレームからビデオへ
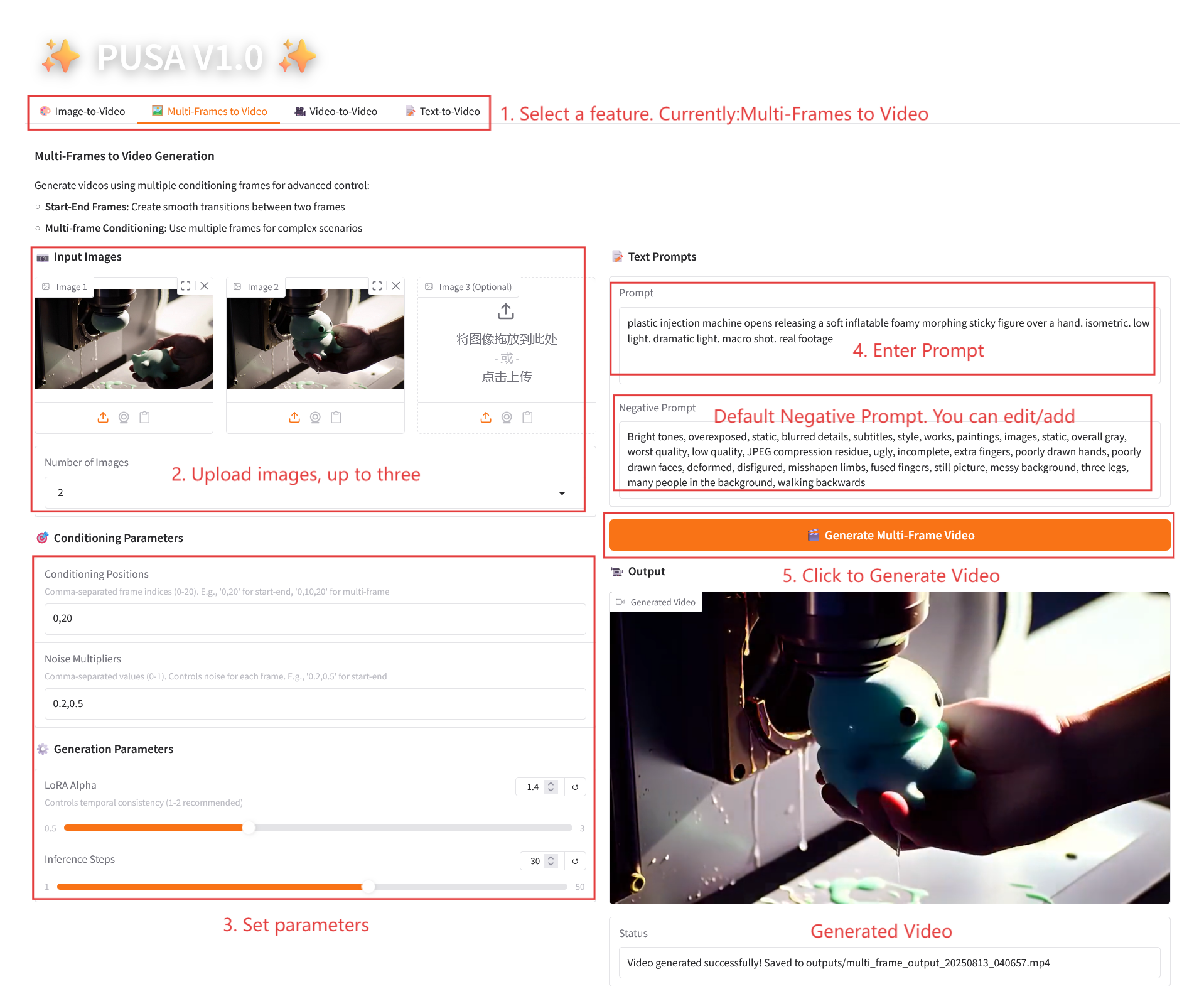
パラメータの説明
- コンディショニングパラメータ
- 条件付け位置: コンマ区切りのフレーム インデックス (例: "0,20" はビデオ内のキーフレームの時間ポイントを定義します)。
- ノイズ乗数: カンマで区切られた 0.0 ~ 1.0 の値 (例: 「0.2,0.5」は各キーフレームのクリエイティブの自由度に対応し、値が低いほどフレームに忠実になり、値が高いほど変化が大きくなります)。
- 生成パラメータ
- LoRA Alpha: 0.1 ~ 5.0 で調整可能、デフォルトは 1.4 (スタイルの一貫性を制御します。高すぎると硬くなり、低すぎると一貫性が失われます)。
- 推論ステップ: 1 から 50 まで調整可能、デフォルトは 10 です (ステップ数が多いほど詳細度は高くなりますが、時間の消費量も直線的に増加します)。
2.3 ビデオからビデオ
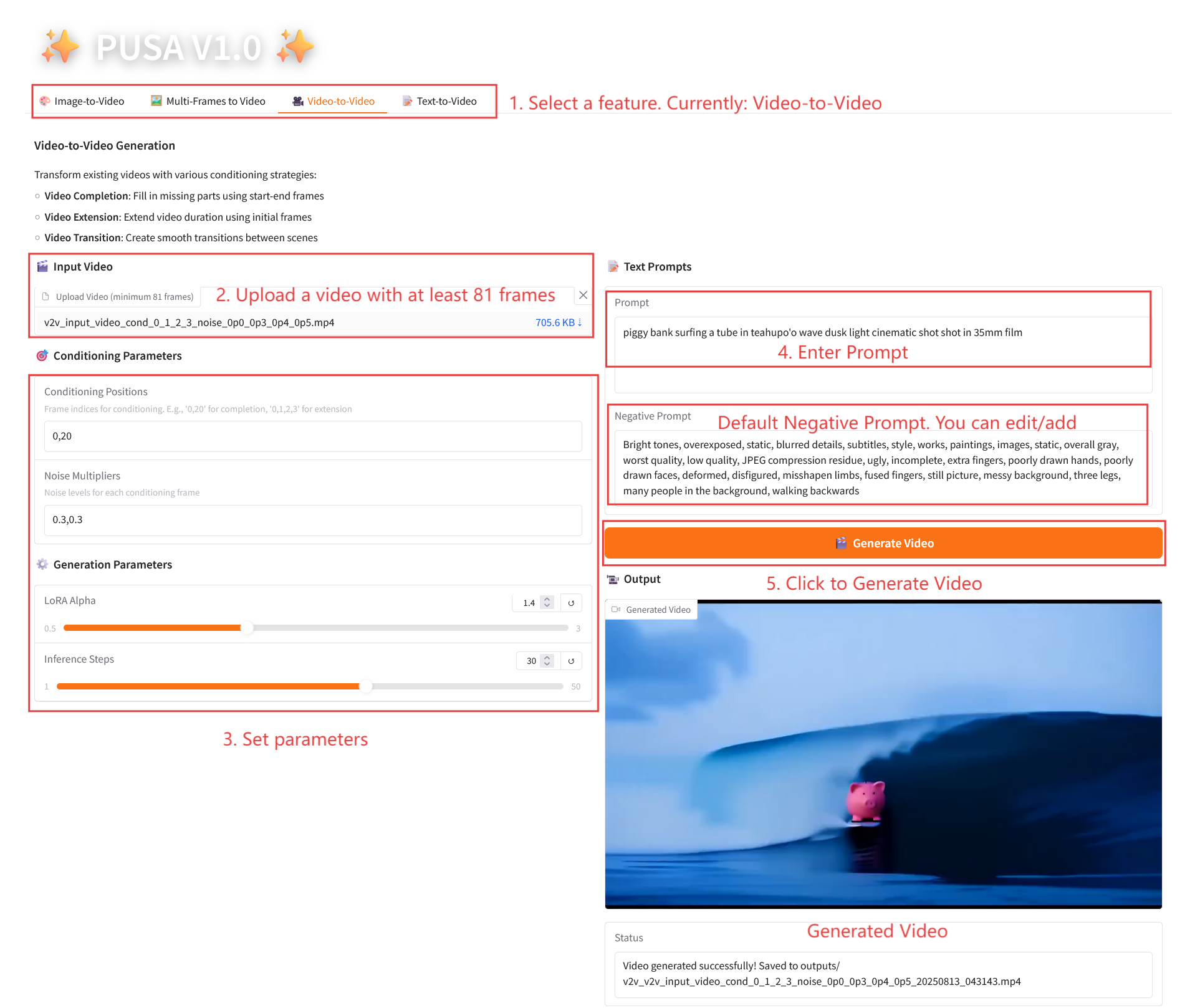
パラメータの説明
- コンディショニングパラメータ
- 条件付け位置: コンマ区切りのフレーム インデックス (例: 「0,1,2,3」、制約生成に使用される元のビデオ内のキーフレームの位置を指定、必須)。
- ノイズ乗数: カンマで区切られた 0.0 ~ 1.0 の値 (例: 「0.0,0.3」は各条件フレームの影響度に対応し、値が低いほど元のフレームに近くなり、値が高いほど柔軟になります)。
- 生成パラメータ
- LoRA Alpha: 0.1 ~ 5.0 で調整可能、デフォルトは 1.4 (スタイルの一貫性を制御します。高すぎると硬くなり、低すぎると一貫性が失われます)。
- 推論ステップ: 1 から 50 まで調整可能、デフォルトは 10 です (ステップ数が多いほど詳細度は高くなりますが、時間の消費量も直線的に増加します)。
2.4 テキストからビデオへの変換
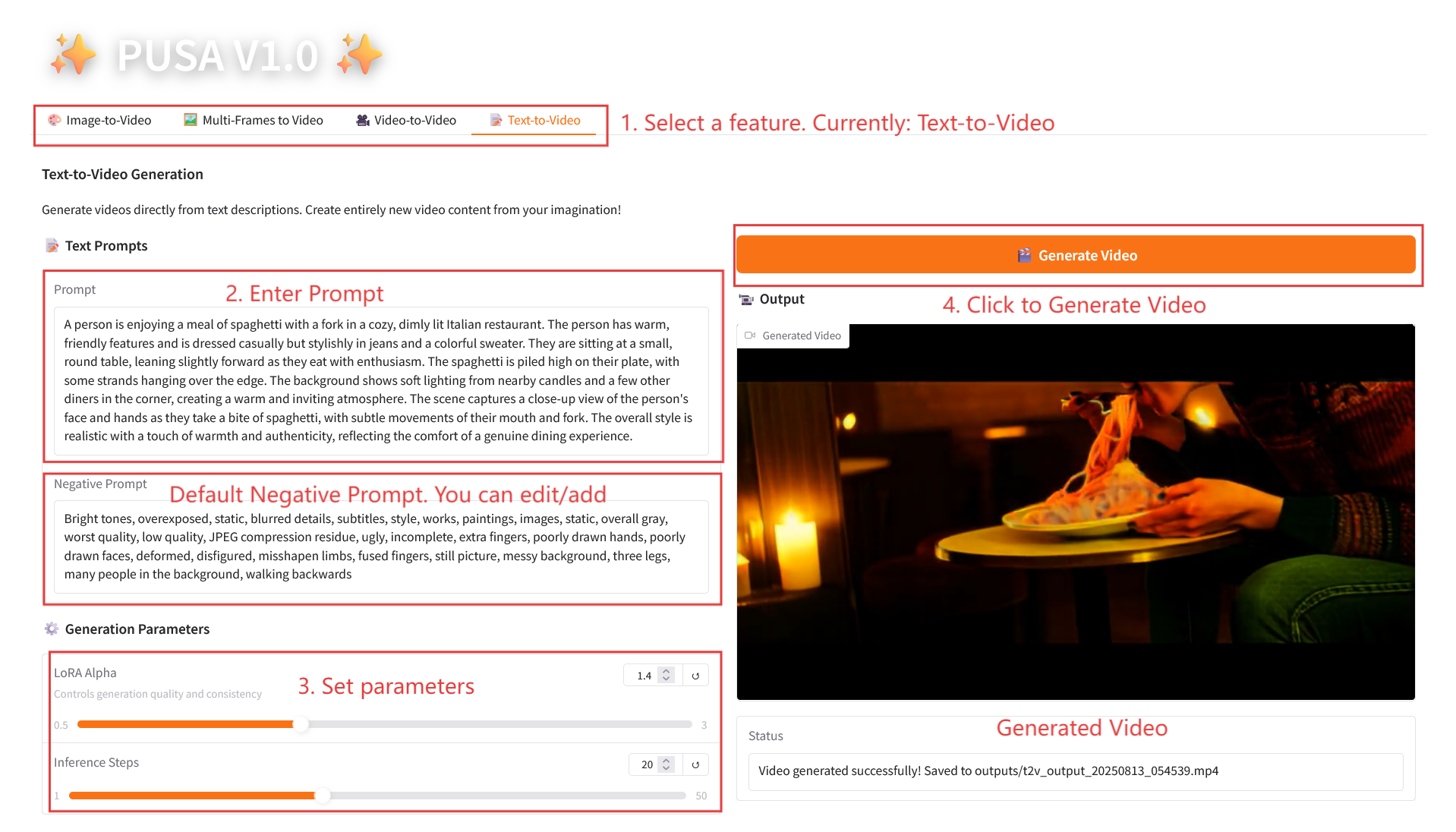
パラメータの説明
- 生成パラメータ
- LoRA Alpha: 0.1 ~ 5.0 で調整可能、デフォルトは 1.4 (スタイルの一貫性を制御します。高すぎると硬くなり、低すぎると一貫性が失われます)。
- 推論ステップ: 1 から 50 まで調整可能、デフォルトは 10 です (ステップ数が多いほど詳細度は高くなりますが、時間の消費量も直線的に増加します)。
4. 議論
🖌️ 高品質のプロジェクトを見つけたら、メッセージを残してバックグラウンドで推奨してください。さらに、チュートリアル交換グループも設立しました。お友達はコードをスキャンして [SD チュートリアル] に参加し、さまざまな技術的な問題について話し合ったり、アプリケーションの効果を共有したりできます。

引用情報
このプロジェクトの引用情報は次のとおりです。
@article{liu2025pusa,
title={PUSA V1. 0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation},
author={Liu, Yaofang and Ren, Yumeng and Artola, Aitor and Hu, Yuxuan and Cun, Xiaodong and Zhao, Xiaotong and Zhao, Alan and Chan, Raymond H and Zhang, Suiyun and Liu, Rui and others},
journal={arXiv preprint arXiv:2507.16116},
year={2025}
}
@misc{Liu2025pusa,
title={Pusa: Thousands Timesteps Video Diffusion Model},
author={Yaofang Liu and Rui Liu},
year={2025},
url={https://github.com/Yaofang-Liu/Pusa-VidGen},
}
@article{liu2024redefining,
title={Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach},
author={Liu, Yaofang and Ren, Yumeng and Cun, Xiaodong and Artola, Aitor and Liu, Yang and Zeng, Tieyong and Chan, Raymond H and Morel, Jean-michel},
journal={arXiv preprint arXiv:2410.03160},
year={2024}
}Notebook の概要
レベル
トピック