Command Palette
Search for a command to run...
150か国からのニュースを処理するGeminiを基盤として、Googleは260万件以上の過去の記録を網羅したオープンソースの洪水データセットGroundsourceを公開した。
世界中で発生するさまざまな自然災害の中で、洪水は発生頻度の高さと破壊力の大きさを兼ね備えた数少ない災害の一つであり、そのため水文学、気候科学、災害管理の分野では長年にわたり重要な課題となってきた。水文予測モデルの改善や気候変動が洪水の進化に与える影響の分析から、将来の洪水リスクの評価、災害予防・軽減システムの改善に至るまで、関連する研究のほぼすべてが、同じ基本的な条件、すなわち質の高い過去の洪水データに依存している。これらのデータは、モデルの信頼性を検証するための重要な参考資料として、またリスク評価や政策決定を支援するための重要な基礎として役立つ。
従来の水文・気象観測所はまばらに分布しており、データ品質もばらつきがあるため、大規模かつ高精度な洪水情報の収集は困難です。現在、真に包括的な洪水データセットはごくわずかしか存在しません。米国国立環境情報センターが管理する暴風雨事象データベースはその典型例ですが、このような体系的な記録は世界的に見ても依然として少なく、多くの国では長期的な洪水事象データベースがまだ確立されていません。そのため、既存のグローバル洪水データセットは、一般的に網羅性や記録の完全性に欠けるという問題を抱えています。
洪水に関する膨大な情報は、ニュース記事や政府文書といった非構造化テキストの中に長らく散在していたことは注目に値する。過去の研究ではこれらの情報源からデータを抽出しようと試みられてきたが、テキストの標準化の限界や手作業による処理コストの高さが、大規模な実装を阻んできた。近年、生成型人工知能の進歩により、この問題に対処するための新たな突破口が開かれた。
最近、Google Researchは、非構造化データから検証済みの地表情報を抽出する洪水データセット「Groundsource」をオープンソース化しました。これにより、過去の災害被害の範囲をかつてない精度でマッピングすることが可能になります。研究者たちは、150カ国以上から寄せられた500万件を超えるニュース記事の処理を自動化し、最終的に260万件を超える過去の洪水に関する記録をまとめた。これは、世界的な洪水研究のための、前例のない規模と網羅性を持つデータを提供する。
現在のところ、「Groundsource社のグローバル洪水イベントデータセットが、HyperAIのウェブサイト(hyper.ai)のデータセットセクションで公開されました。オンラインでの使用:

用紙のアドレス:
https://eartharxiv.org/repository/view/12083/
弊社の公式WeChatアカウントをフォローし、バックグラウンドで「Groundsource」と返信すると、PDF全文を入手できます。
500万件のニュース記事に基づき、260万件以上の洪水報告が精査された。
Groundsourceデータセットは、標準化された自動化プロセスに従って構築されました。グローバルなデータ収集および固有表現認識の段階では、研究チームはWebRef固有表現認識システムやRead Aloudツールなど、Googleのインフラストラクチャの一部を利用しました。しかし、データ抽出ロジック、大規模言語モデル提案フレームワーク、および時空間集約ルールはすべて公開文書化されています。そのため、オープンソースアルゴリズムや他の言語モデルに置き換えた後でも、このプロセスはさまざまな技術環境で再現可能です。
データ構築は、ニュース情報の収集から始まる。研究チームは、ウェブクローラーを用いて2000年以降に公開されたニュース記事を収集し、WebRefを用いて各記事の洪水関連度スコアを算出した。研究者たちは閾値を0.6に設定した。予備審査約950万のウェブページしかし、手作業によるサンプリングの結果、実際に洪水について報告していたのは約半数に過ぎず、残りは単に背景で言及されているだけだったことが明らかになった。
次に、テキスト抽出の段階に入ります。このシステムは、ウェブページから広告やナビゲーション要素を自動的に削除し、記事本文と公開日のみを残し、解析できない言語やアクセスできないウェブサイトを除外します。最終的に使用可能な記事数は約750万件だった。英語以外のテキストはすべて英語に翻訳され、地理的な場所の名前は固有表現認識によって抽出され、候補となる場所のデータベースが作成されます。
ニュース記事から特定の洪水イベントを特定することは、全プロセスの中で最も複雑な部分です。報道には、複数の場所や「昨日」や「先週」といった曖昧な時間表現が含まれていることがよくあります。そのため、研究チームは、Gemini大規模言語モデル向けに構造化された提案フレームワークを設計し、手動で注釈を付けた250件の記事を用いてテストを行った。このモデルは、Google Read Aloudを使用して80言語から生のテキストを抽出し、Cloud Translation APIを介して英語に正規化しました。その後、モデルは4つのタスクを順次実行しました。記事が実際の洪水事象を記述しているかどうかを判断すること、事象発生時刻を抽出して正規化すること、洪水の影響を受けた特定の場所を特定すること、そして地名を標準的な地理的識別子と照合することです。
このプロセスでは、750万件の記事のうち、約500万件が実際の洪水に関する記事であると特定された。手動でラベル付けされたサンプルに基づくと、イベント認識の精度は約75%、再現率は約90%です。日付と場所の抽出精度はやや低いものの、効果的な時空間的手がかりを提供します。
これらのイベントを地図上に表示するために、システムは位置情報をジオコーディングします。既存の地理的実体が一致する場合は、その空間境界が直接呼び出されます。一致する実体が見つからない場合は、ジオコーディングサービスによって地名が座標に変換され、空間分析に必要な場合は小さなバッファゾーンが生成されます。
最後に、地理的識別子と時間情報に基づいて、研究チームは連続して報告された記録を単一の洪水イベントに統合し、範囲が広すぎる記録や異常なタイミングの記録を除外する品質管理を実施しました。この一連のプロセスを経て、その結果、264万件を超える固有の記録が得られ、それぞれが特定の時間と場所で報道された洪水観測記録に対応していた。
データセットの評価:82%イベントは分析的価値があり、その街路レベルの精度は小規模災害記録の空白を埋めるものである。
Groundsourceデータセットの信頼性を評価するために、本研究では、データの正確性、時空間分布、外部データベースとの整合性という3つの側面からデータを分析する。これは、世界災害警報調整システム(GDACS)とダートマス洪水観測所(DFO)という2つの主要なデータベースと比較された。
正確性の評価において、研究者らは無作為に400件の記録を選択し、元のニュースソースまで遡って時間と場所の情報を検証した。その結果、厳密に「正確」であった記録は60%(信頼区間95%±5%)であった。わずかな偏りはあるものの分析価値のある記録を含めた場合、約82%のイベントが後続の分析に使用できる。残りの約18%エラーは、主に地名の曖昧さによる空間位置のエラーや、「昨日」や「先週」といった相対的な時間表現の読み間違いに起因しています。
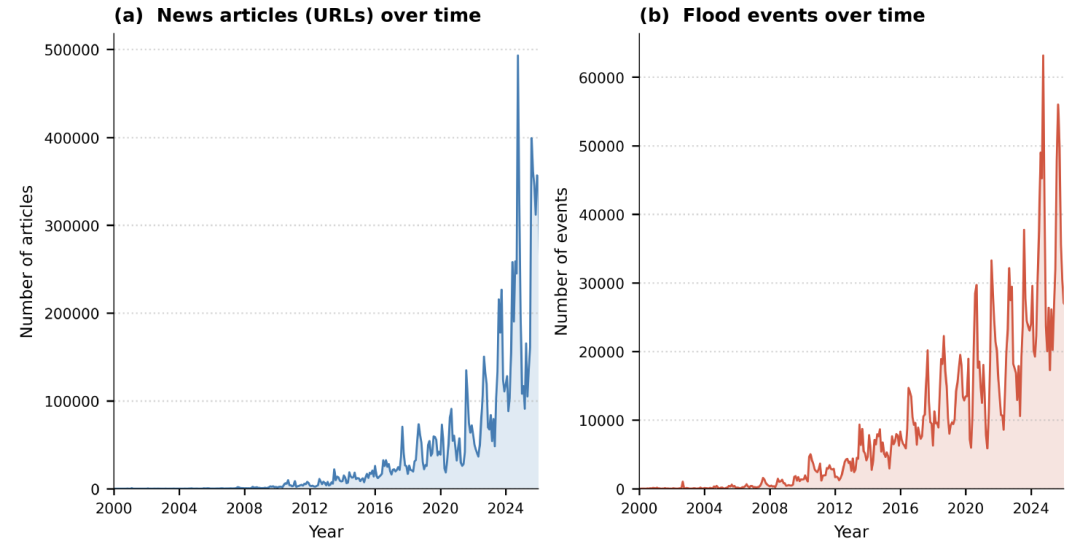
時空間分布の観点から見ると、このデータセットは明らかに「最近のデータに偏っている」ことを示している。下図に示すように、約641 TP3Tの記録が2020年から2025年の間に集中しており、2025年だけで151 TP3Tが記録されています。この傾向は、洪水発生件数の増加というよりも、デジタルニュースメディアの急速な成長を反映している可能性が高いと考えられます。
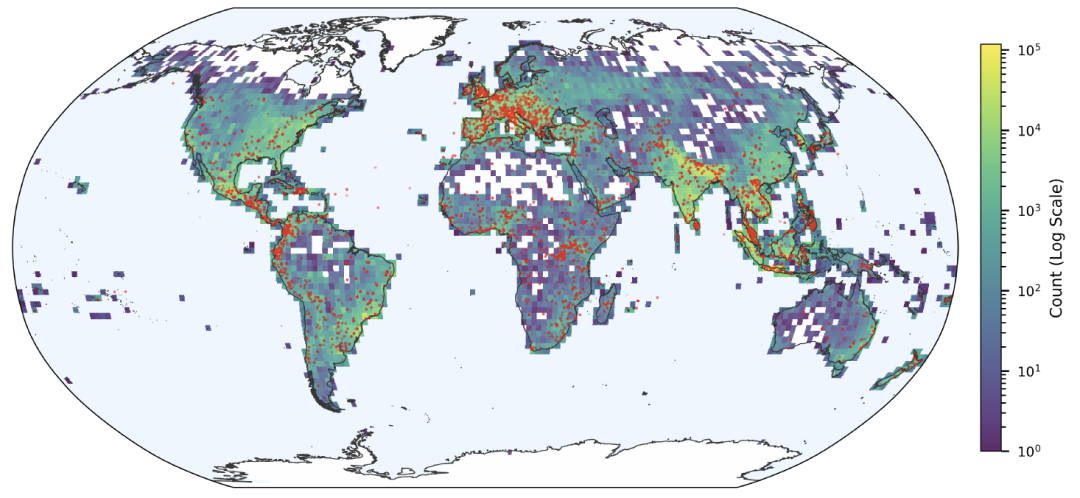
空間分布はメディアのエコシステムにも影響され、報道が集中している地域ではより多くの事象が記録され、デジタルニュースが少ない地域や言語サポートが不十分な地域では代表性が低くなる。しかし、データは依然として、ヨーロッパ、南アジア、東南アジアなど、洪水が発生しやすい地域を明確に示している。その空間分布は、GDACSが記録した主要な洪水発生場所と非常に一致している。
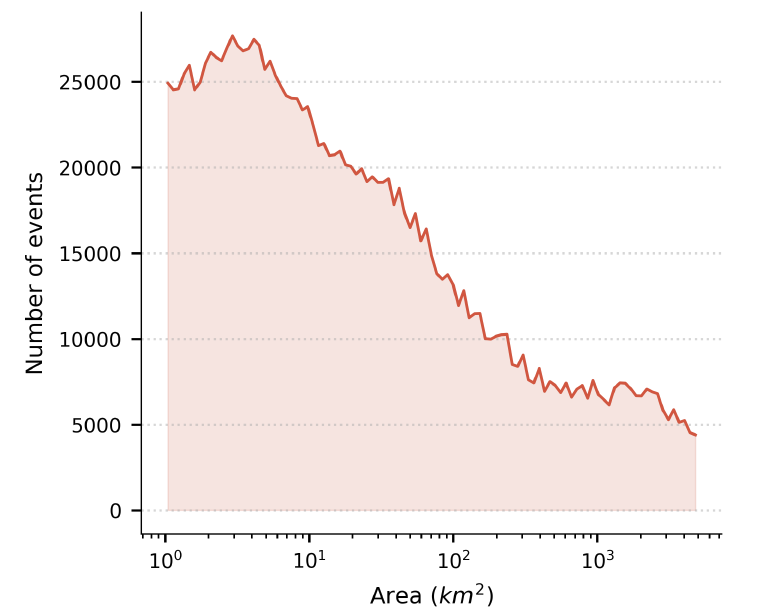
報告上の偏りはあるものの、Groundsourceは空間解像度の点で非常に優れた性能を発揮する。統計によると、抽出された事象の平均範囲は142平方キロメートルで、そのうち82%レコードは50平方キロメートル未満です。多くの事象はブロックまたはコミュニティ規模にまで絞り込むことができ、従来のグローバル災害データベースでは見落とされがちな局地的な洪水を捉えることができます。
完全性評価において、この研究では、時空間マッチングによってGroundsourceを世界災害警報調整システム(GDACS)およびダートマス洪水観測所(DFO)と比較した。結果によると、2020年以降、GDACSイベントのリコール率は851 TP3Tから1001 TP3Tの範囲であった。米国などメディアインフラが十分に発達している地域では、マッチング率はそれぞれ961 TP3T(GDACS)および911 TP3T(DFO)に達した。さらに、想起率は災害の影響の深刻さと有意に相関しており、大規模な洪水災害の想起率は90%に近いか、それを超えている。
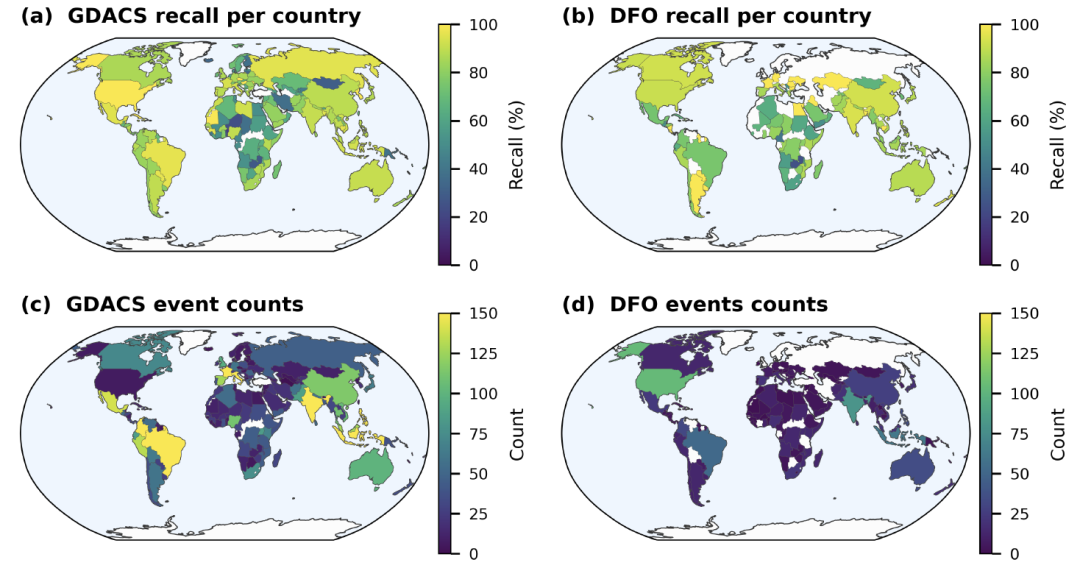
全体的に見て、Groundsourceは完全にバランスの取れたグローバルなカバレッジを提供することはできませんが、しかし、260万件を超える記録と高い空間解像度を備えているため、小規模で局地的な洪水事象を記録するという従来の災害データベースの欠点を補うことができる。これは、世界的な洪水研究のための新たなデータソースを提供する。
AIを活用した洪水データ研究
大規模言語モデルを用いて非構造化テキストから標準化された洪水イベント情報を抽出する手法は、洪水研究分野において徐々に重要な方法になりつつある。
学術界では、多くの研究チームがこの方向性を継続的に探求してきた。 MITの研究者らは、洪水事象の抽出において大規模言語モデルが一般的に遭遇する時間的曖昧性や地名曖昧性の問題に対処するため、改良された手がかり語戦略と文脈関連付け手法を提案した。研究チームは、過去の水文観測データを用いてモデルを微調整することで、洪水発生日の抽出精度を80%以上に向上させ、多言語対応モジュールを開発しました。これにより、モデルはさまざまな言語のニュース記事をより安定して処理できるようになり、複数の地域を網羅する洪水発生データセットが構築されました。
論文タイトル:気候可視化のための物理的に整合性のある衛星画像の生成
論文リンク:
https://ieeexplore.ieee.org/document/10758300
シンガポール国立大学の研究チームは、研究成果の応用範囲をさらに拡大した。研究チームは、AIを用いてニュース報道から抽出した過去の洪水事例と、都市排水網データ、高精度地形情報を組み合わせ、都市規模の洪水リスク評価モデルを構築した。研究者たちは、地域ごとの洪水発生頻度と規模、そして都市インフラとの関係を分析することで、潜在的なリスク地域をより明確に特定し、都市洪水対策計画のためのより的を絞った情報を提供できる。また、極端な気候条件下における将来の洪水リスクの変化傾向を評価することも試みている。
論文タイトル:データ不足地域における応用可能なAIを用いた激しい洪水の予測
論文リンク:
https://www.cell.com/the-innovation/fulltext/S2666-6758(24)00090-0
関連研究の進展は、産業界にも広がり始めている。マイクロソフトリサーチはNASAと提携し、AIを活用した洪水リスク予測プラットフォーム「ハイドロロジー・コパイロット」を開発した。このシステムは、ニュース報道、衛星リモートセンシング情報、リアルタイム水文監視データから抽出した洪水発生データを統合し、機械学習モデルを用いて洪水発生確率と潜在的な影響範囲を予測します。現在、このプラットフォームは米国およびその他いくつかの国で試験運用されており、地方の緊急事態管理部門による洪水警報および対応プロセスの改善を支援しています。
総じて、ニュース記事から洪水発生情報を自動的に抽出する手法は、従来の観測データを補完する重要な情報源となりつつある。モデルの性能向上とデータ規模の拡大に伴い、この種の手法は、世界の洪水リスク研究のための、より豊富で高解像度のデータ基盤を提供することが期待される。
参考リンク:
1.https://www.geekwire.com/2025/microsoft-nasa-ai-hydrology-copilot-floods








