Command Palette
Search for a command to run...
オンラインチュートリアル | WeChat AIチームが、ARモデルの展開においてvLLMと比較して推論速度を3倍向上させる拡散言語モデルWeDLMを提案

大規模展開や商用アプリケーションにおいては、推論速度の重要性がますます高まっており、多くの場合、モデルパラメータの数を凌駕するほどであり、エンジニアリングの価値を決定づける重要な要素となっています。自己回帰(AR)生成パラダイムは、その安定性と成熟したエコシステムにより、依然として主流のデコード手法となっていますが、ただし、トークンごとの生成という固有のメカニズムにより、モデルが推論フェーズ中に並列コンピューティング リソースを完全に活用することはほぼ不可能です。この制限は、長いテキスト生成、複雑な推論、高同時実行サービスを含むシナリオで特に顕著になり、推論の待ち時間とコンピューティング コストが直接的に増加します。
このボトルネックを克服するために、研究コミュニティは近年、並列デコードパスを継続的に研究してきました。その中で、拡散言語モデル (DLM) は、「ステップごとに複数のトークンを生成する」という特性により、最も有望な代替手段の 1 つと考えられています。しかし、理想と現実の間には依然として大きなギャップが存在します。実際の導入環境では、多くのDLLMが期待された速度優位性を発揮できず、高度に最適化されたAR推論エンジン(vLLMなど)を上回るパフォーマンスを得るのに苦労しています。この問題は並列処理自体に起因するものではなく、モデル構造とシステムレベルに潜むより深い矛盾に起因しています。既存の拡散法の多くは双方向アテンション メカニズムに依存していますが、これは現代の推論システムの効率の基礎であるプレフィックス キー値キャッシュを損ない、モデルにコンテキストを繰り返し再計算させるため、並列処理の潜在的な利点が無効になります。
この文脈では、TencentのWeChat AIチームはWeDLM(WeChat拡散言語モデル)を提案しました。これは、産業グレード推論エンジン(vLLM)最適化下で、同等のARモデルを推論速度で凌駕する初の拡散言語モデルです。その核となるアイデアは、因果マスキングを厳密に保ちながら、各マスク位置を現在観測されているすべてのトークンに条件付けすることです。この目的のために、研究者らは位相的な並べ替え手法を導入し、観測トークンを論理的な位置を変えずに物理的なプレフィックス領域に移動しました。
実験結果によると、WeDLMは強力な自己回帰バックボーン生成の品質を維持しながら、推論を大幅に高速化することが示されています。具体的には、数学的推論などのタスクにおいて、vLLMによって展開されたARモデルの3倍以上の高速化を達成し、低エントロピーシナリオにおける推論効率は10倍以上向上しています。
現在、「WeDLM 高効率大規模言語モデルデコードフレームワーク」は、HyperAIウェブサイトの「チュートリアル」セクションで公開されています。以下のリンクからオンラインチュートリアルを体験できます⬇️
オンラインチュートリアル:
オープンソースのアドレス:
https://github.com/tencent/WeDLM
誰もがオンライン チュートリアルをより快適に体験できるように、HyperAI はコンピューティング パワーの特典も提供しています。新規ユーザーは、登録後に引き換えコード「WeDLM」を使用することで、NVIDIA GeForce RTX 5090 の使用時間を 2 時間取得できます (リソースの有効期限は 1 か月です)。数量限定ですので、今すぐお買い求めください!
デモの実行
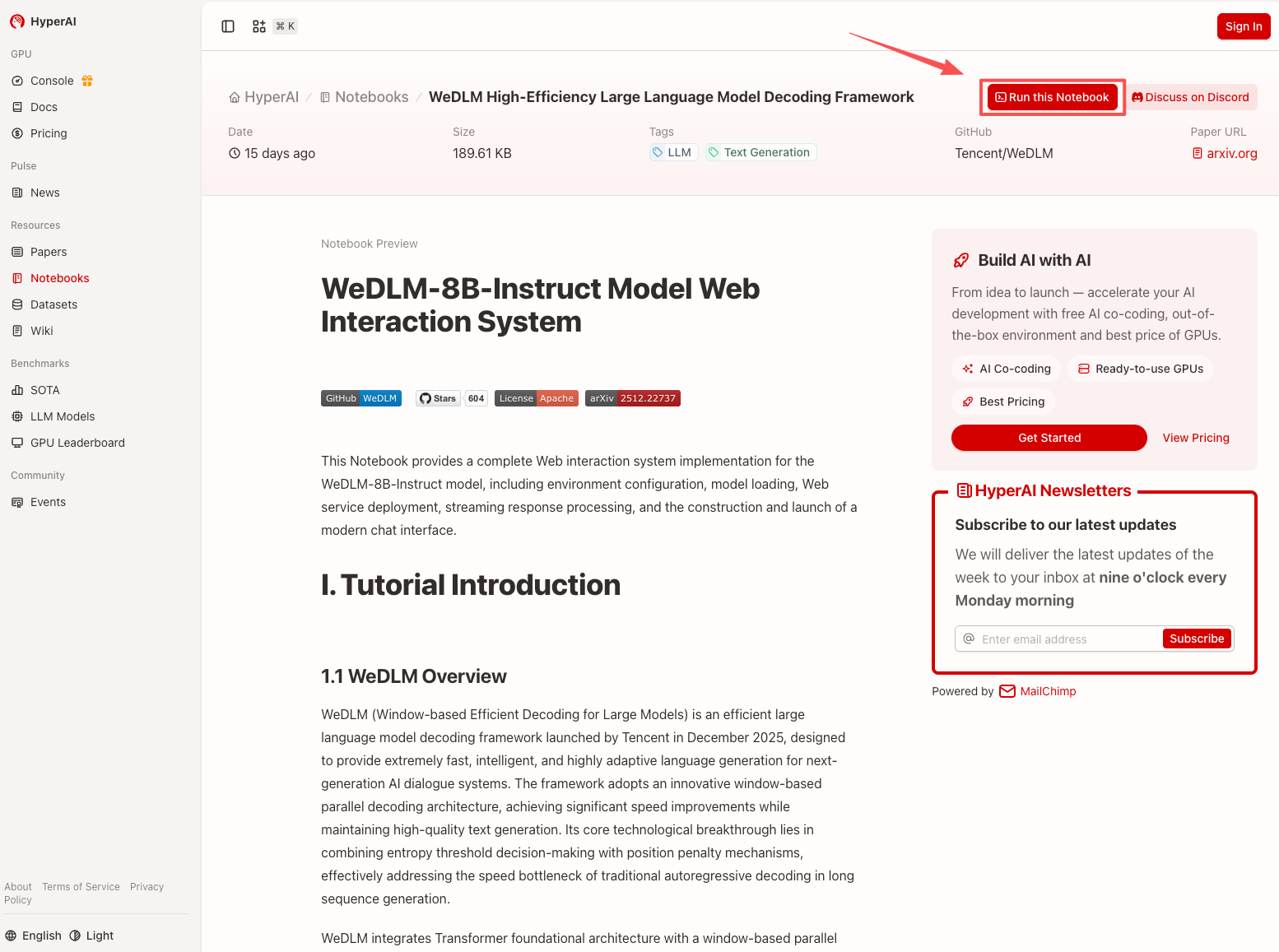
1. hyper.ai ホームページにアクセスした後、「チュートリアル」ページを選択するか、「その他のチュートリアルを表示」をクリックし、「WeDLM 高効率大規模言語モデル デコード フレームワーク」を選択して、「このチュートリアルをオンラインで実行」をクリックします。
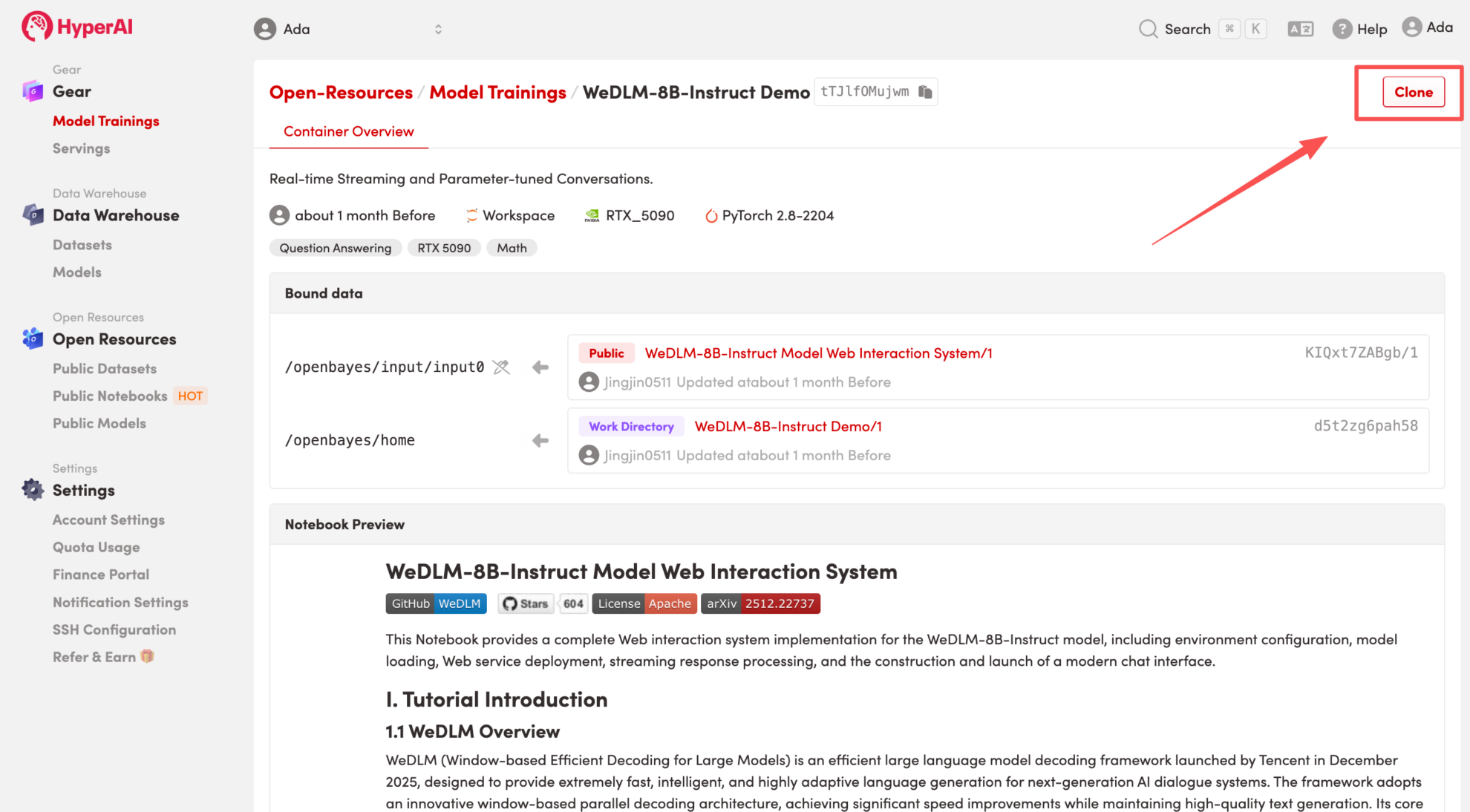
2. ページがリダイレクトされたら、右上隅の「複製」をクリックして、チュートリアルを独自のコンテナーに複製します。
注:ページの右上で言語を切り替えることができます。現在、中国語と英語が利用可能です。このチュートリアルでは英語で手順を説明します。
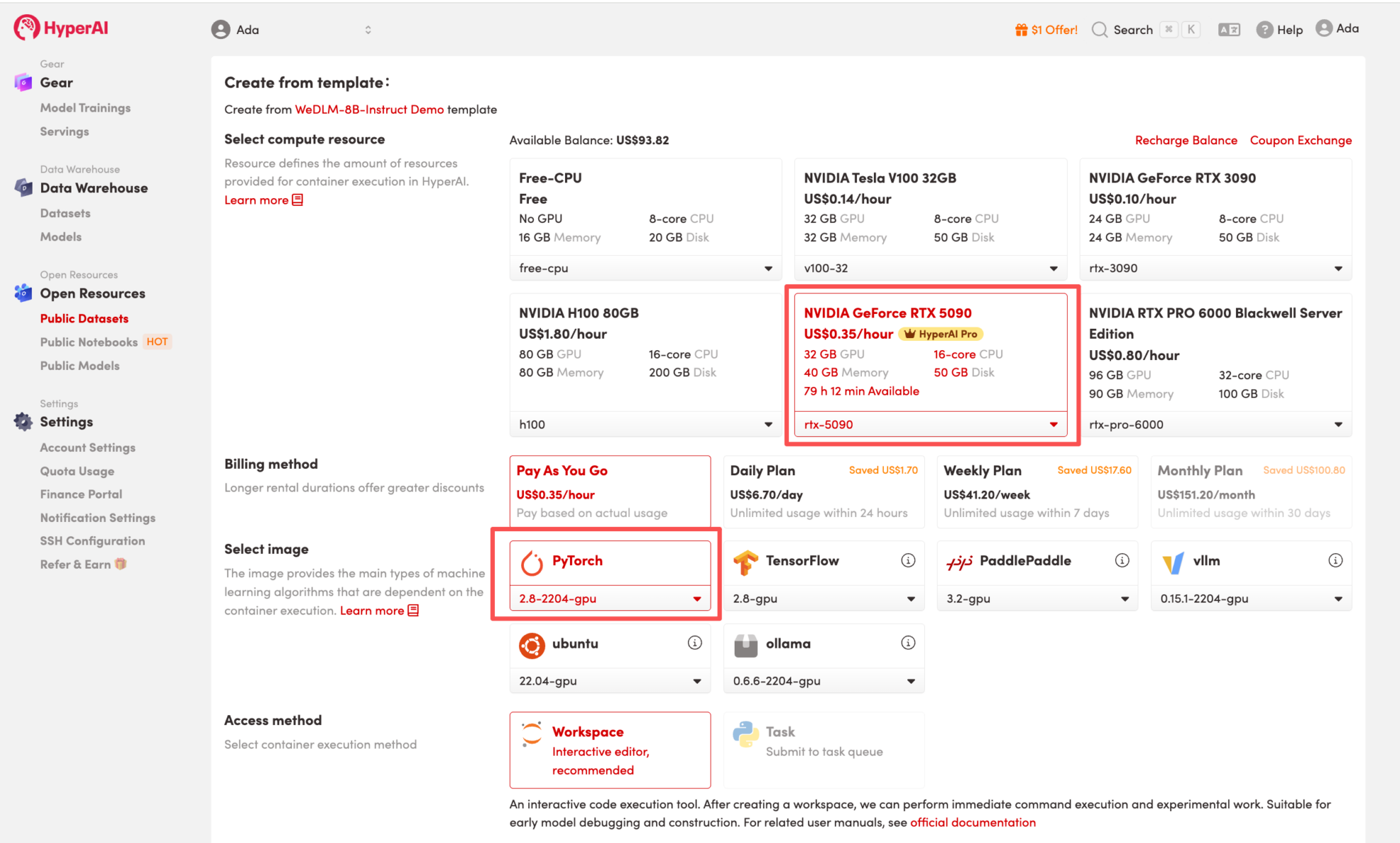
3. 「NVIDIA GeForce RTX 5090」と「PyTorch」のイメージを選択し、必要に応じて「Pay As You Go」または「Daily Plan/Weekly Plan/Monthly Plan」を選択し、「ジョブ実行を続行」をクリックします。
HyperAI は新規ユーザーに登録特典を提供しています。わずか $1 で、RTX 5090 のコンピューティング パワーを 20 時間利用できます (元の価格は $7)。リソースは永続的に有効です。
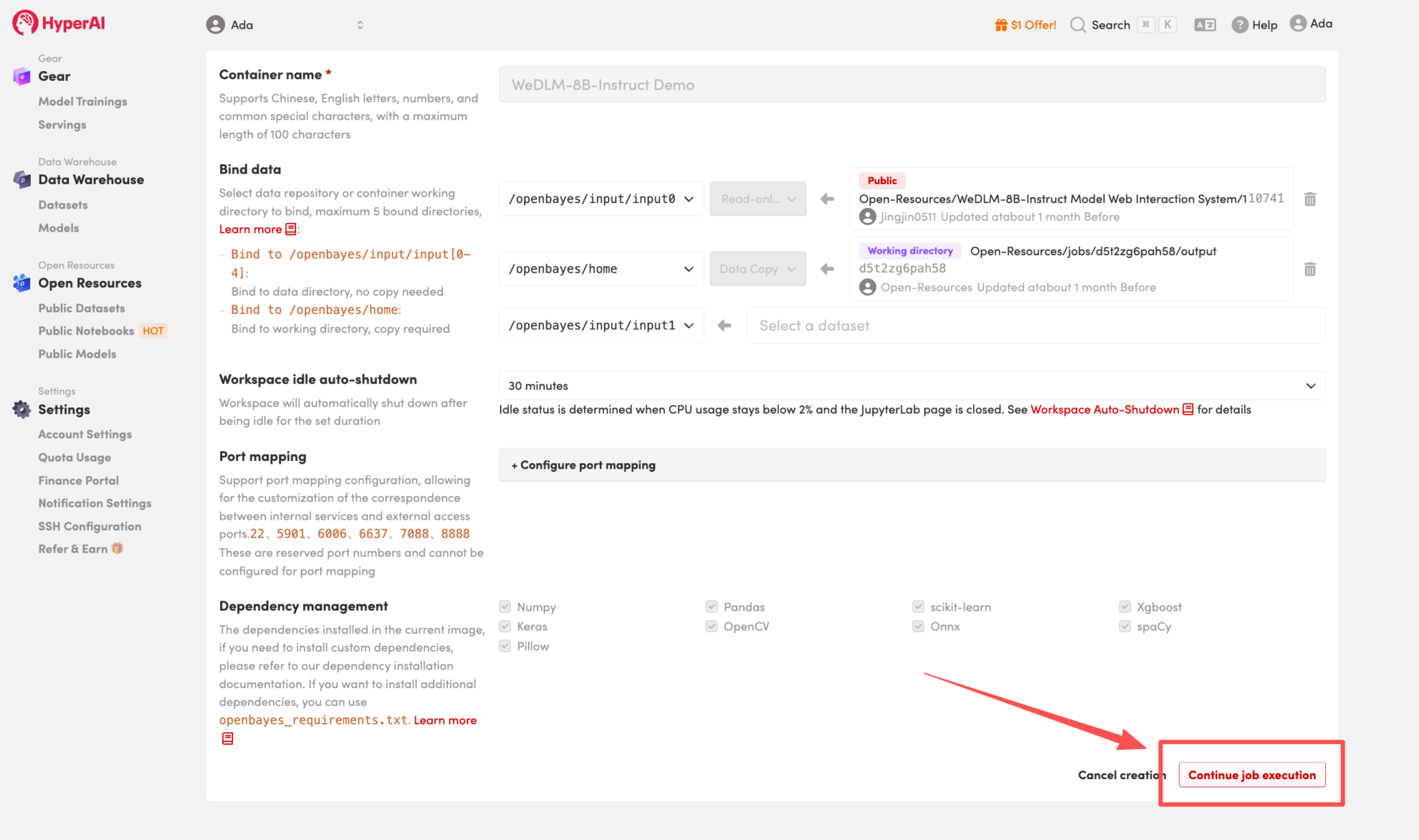
4. リソースが割り当てられるのを待ちます。ステータスが「実行中」に変わったら、「ワークスペースを開く」をクリックしてJupyterワークスペースに入ります。
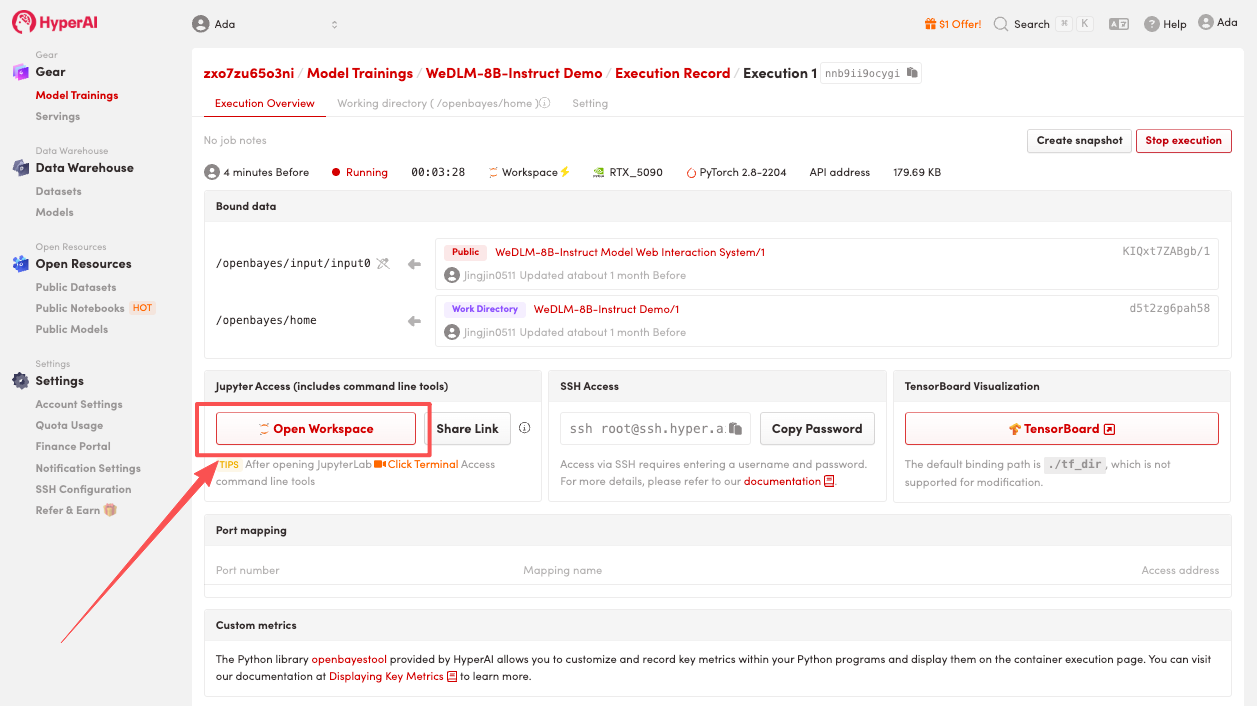
効果実証
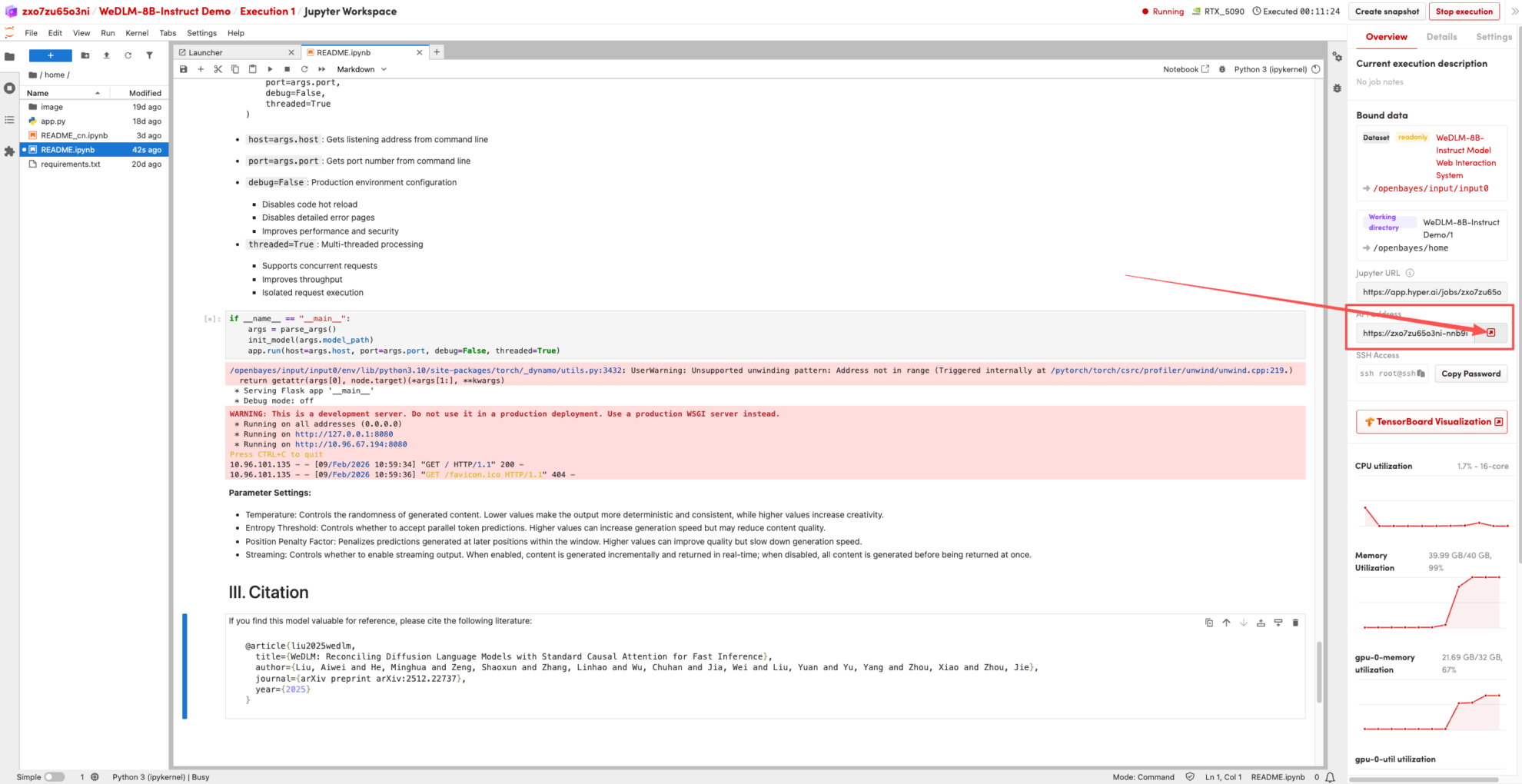
1. ページがリダイレクトされたら、左側の README ページをクリックし、上部の [実行] をクリックします。
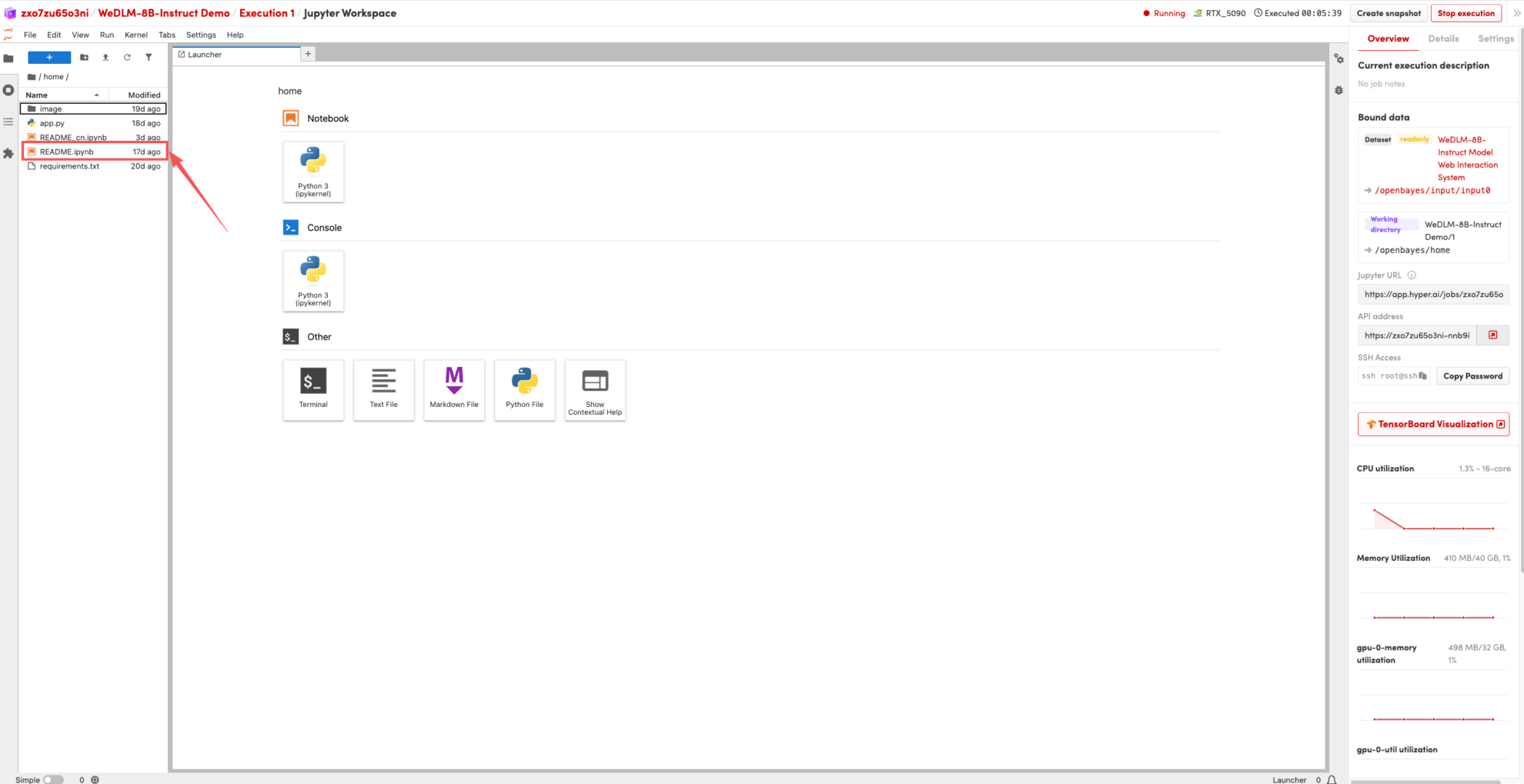
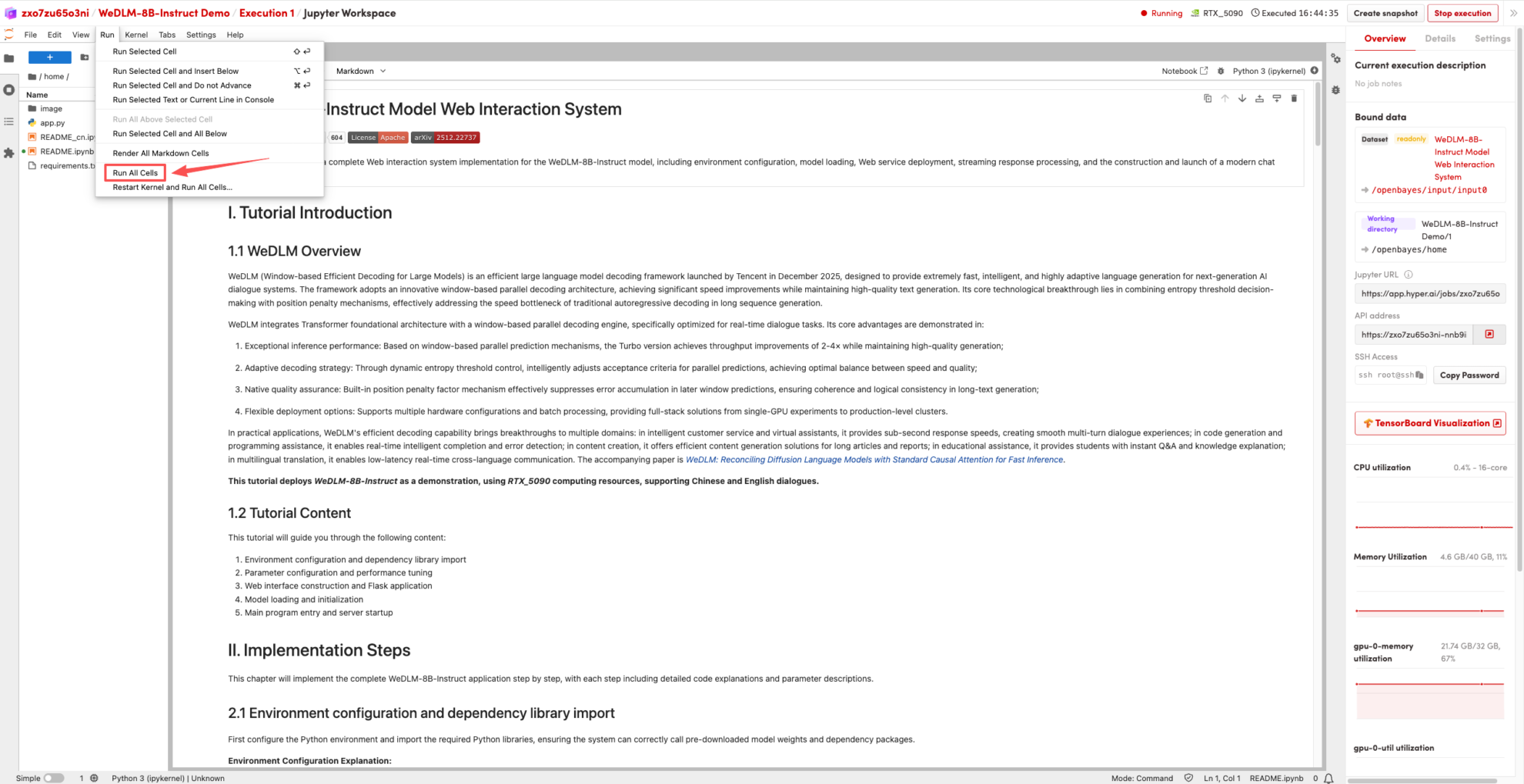
2. プロセスが完了したら、右側の API アドレスをクリックしてデモ ページに移動します。
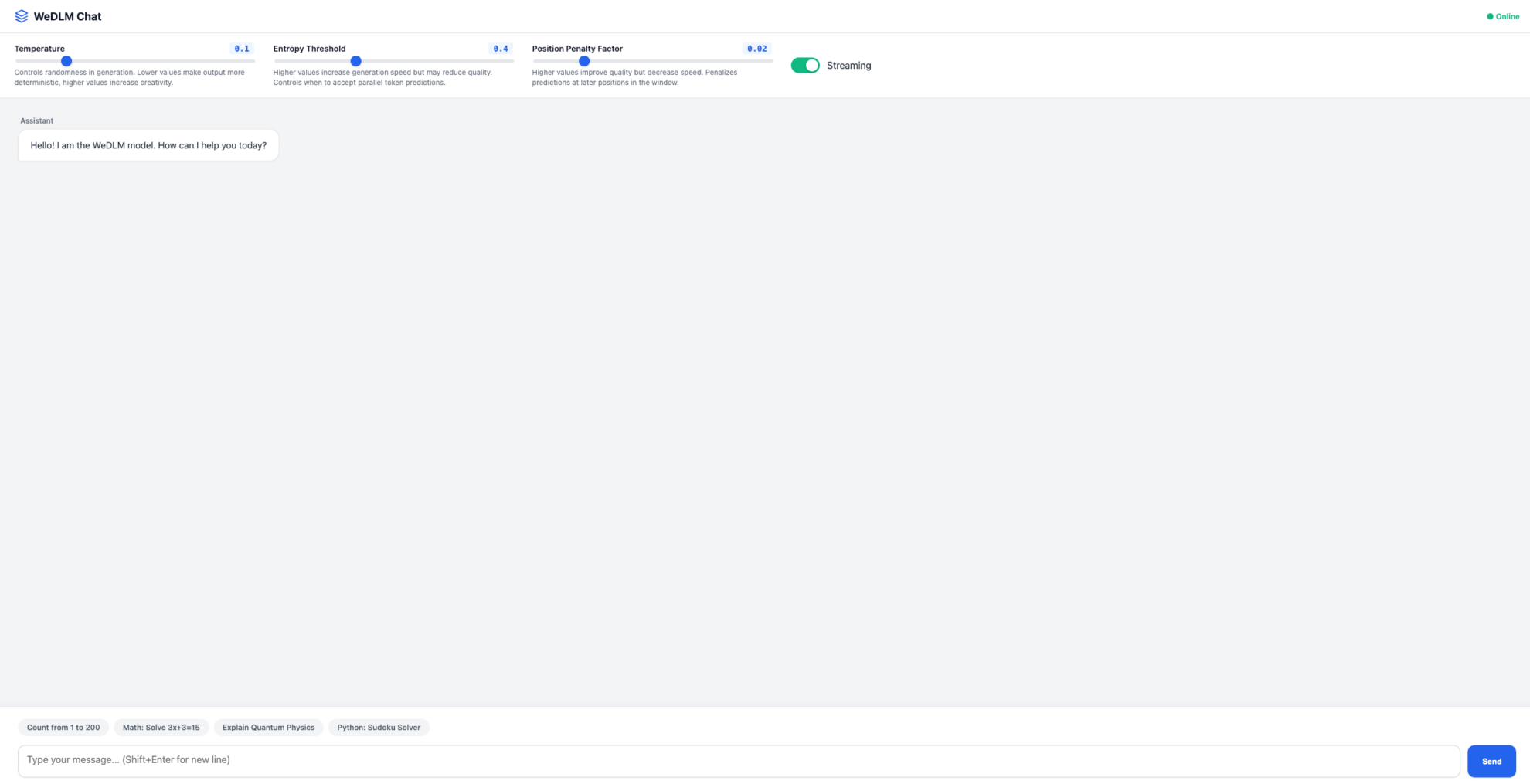
以上が今回HyperAIがおすすめするチュートリアルです。ぜひ皆さんも体験してみてください!
チュートリアルのリンク:https://go.hyper.ai/qf0Y6








