Command Palette
Search for a command to run...
上海交通大学のZhou Bingxin博士: 希少な生物学的データの課題を解決し、グラフニューラルネットワークがタンパク質の理解と生成を再構築する

8月12日、上海交通大学AIバイオエンジニアリングサマースクールが正式に開校し、国内外の30以上の大学と27社から100人以上の業界関係者が集まった。 3日間の学習と交流の間に、多くの業界専門家、ビジネス代表者、優れた若手学者が集まりました。これにより、AI とバイオエンジニアリングの統合と革新的な開発に関する詳細な共有がもたらされました。
12日午前、上海交通大学自然科学院および上海国立応用数学センター(上海交通大学分校)の助研究員、周炳新氏は「人間の過去と現在の生活」というテーマで講演した。人工知能"。 AIの発展の歴史を生き生きとまとめ、マイルストーンモデルの特徴をまとめています。
午後には、「人工知能の最前線の進歩」に関する招待専門家レポートの中で、周炳新博士も「グラフニューラルネットワークとタンパク質の構造特性評価」について講演を行いました。 彼は、タンパク質の予測と生成におけるグラフ ニューラル ネットワークの定義、利点、最先端のアプリケーションについて全員と共有しました。 HyperAI は、当初の意図に違反することなく、このトピックに関する周秉新博士の共有内容を編集および要約しました。以下は講演の書き起こしです。
数十年にわたる急速な発展を経て、畳み込みニューラル ネットワーク、リカレント ニューラル ネットワーク、さまざまな特性を持つデータの処理に使用できるトランスフォーマーなど、さまざまなモデルを備えたディープ ラーニングが登場しました。その中でも、グラフ ニューラル ネットワークは、構造データを入力して処理できるため、ソーシャル ネットワーク、軌道予測、分子モデリングなどのシナリオで広く使用されています。
しかし、多くの人は、グラフ ニューラル ネットワークはグラフ畳み込みネットワーク (GCN) であり、複雑な関数を適合させることができず、複数の層を積み重ねると過剰平滑化の問題が発生するため、多くの制限があると考えています。さらに、Transformer に基づく大規模なモデルは大規模なデータセットに対する強力な学習機能を備えているため、では、なぜグラフ ニューラル ネットワークの研究と開発を続けるのでしょうか?
これらの質問に対して、私は答えを「セクシーです」と要約します。
最初の「S」は、グラフニューラルネットワークに基づく研究が健全で持続可能であるということです。 以下の図に示すように、人間のさまざまな行動による炭素消費量を比較すると、大型モデルの強力な機能の前提条件は膨大なエネルギー消費であることがわかります。さらに、コンピューティング リソースや大規模モデルへの研究の集中が過度に集中すると、長期的には、コンピューティング リソースや音声を独占する大企業のみが人工知能の研究開発を維持できるようになります。大企業以外の研究者が科学研究を行う場合、スペースは非常に限られます。
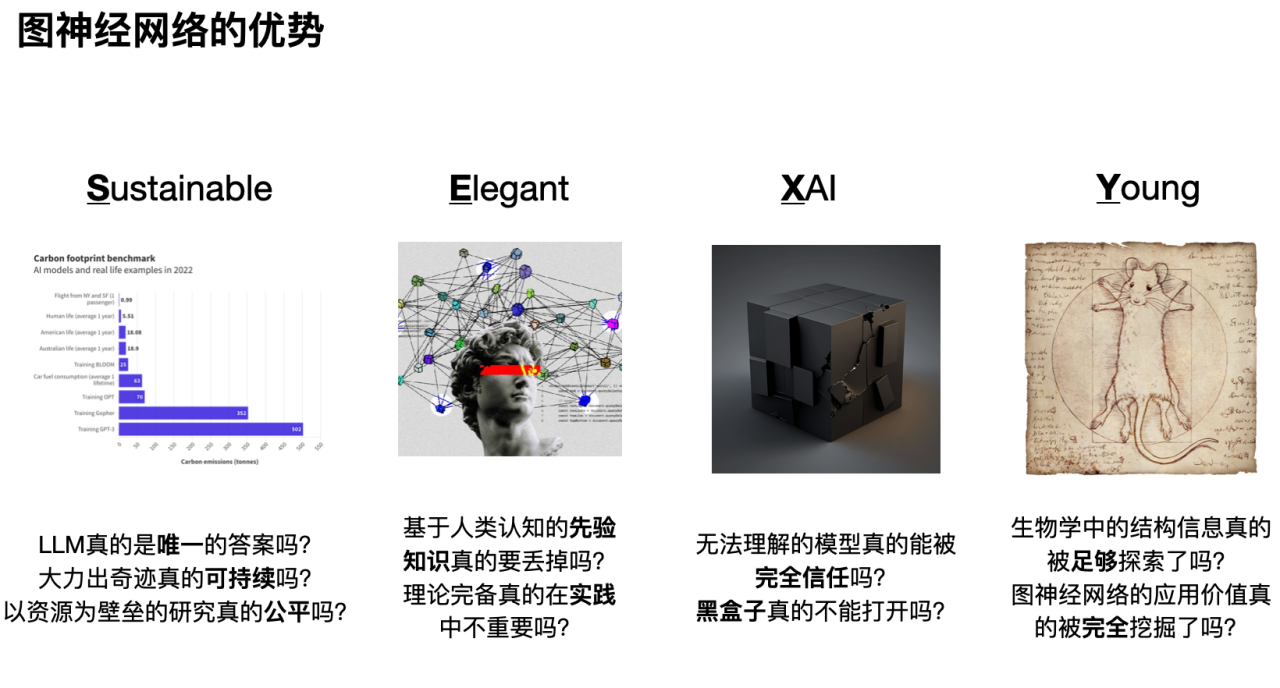
2 番目の「E」は、人工知能の急速な発展によって数百年にわたる自然科学の蓄積が無視されるべきではないということです。グラフ ニューラル ネットワークは、特徴表現を学習するだけでなく、人間からの事前知識をエレガントに追加することもできます (帰納的バイアス)。 さらに、他のデータ駆動型モデルと比較して、グラフ ニューラル ネットワークには、信号処理、社会力学などの理論的なサポートがより多くあります。
3 番目の「X」、グラフ ニューラル ネットワークは、ディープ ラーニング ネットワークの解釈可能性を促進します。 人工知能の発展に伴い、人々はモデル結果の重要性と合理性にますます注目するようになり、グラフ ニューラル ネットワークの解釈可能性を徹底的に研究することで、モデルの意思決定の背後にあるロジックと根拠をよりよく理解できるようになります。モデルの信頼性と信頼性を向上させます。
4 番目の「Y」は、グラフ ニューラル ネットワークは、新しく急速に発展している分野であるため、未解決の問題や課題がまだ多くあり、研究者に広い探索の余地を提供していることを意味します。 さらに、画像処理の畳み込みニューラル ネットワークや自然言語処理のセルフ アテンション メカニズムと同様に、グラフ ニューラル ネットワークも生物学の多くの問題 (特にデータが不十分で重要な事前知識がある問題) に対して優れた解決策を提供します。
次に、分子データとグラフ表現、古典的なグラフ ニューラル ネットワークの紹介、グラフ ニューラル ネットワーク、およびその他の生物学的問題の 3 つの側面から、グラフ ニューラル ネットワークの具体的な応用価値を共有します。
分子データとグラフ表示: 生物学的データの 3 要素のグラフ表示
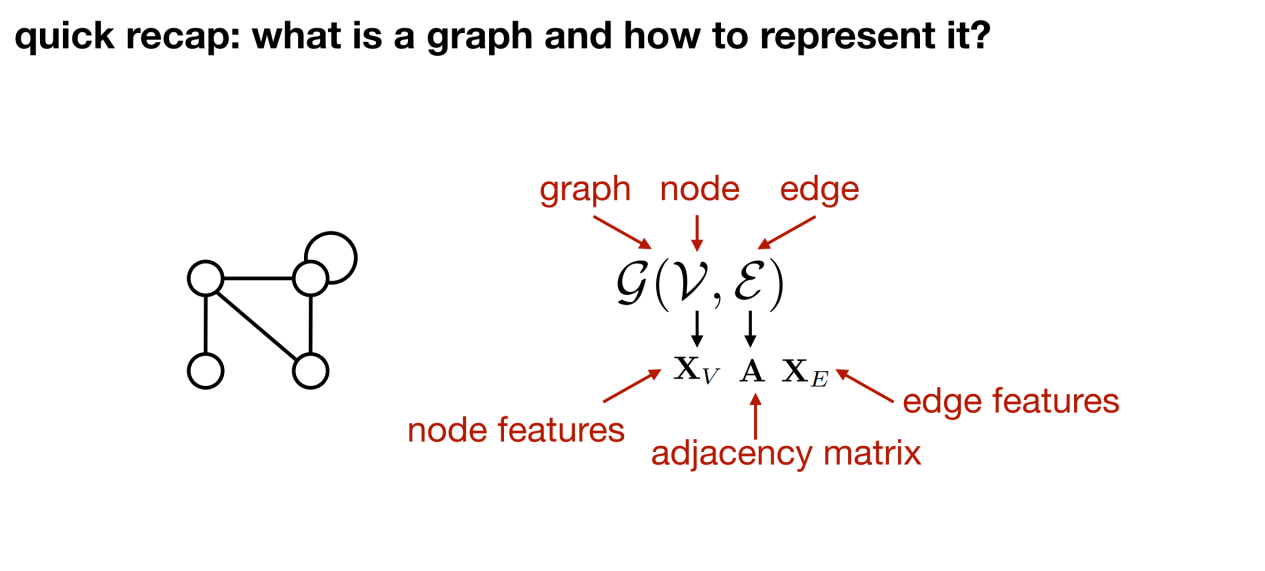
生物学的データをグラフ表現に変換したい場合は、まずグラフとは何なのか、グラフはどのような基本要素で構成されているのかを答えなければなりません。一般的に言えば、グラフには、ノード、エッジ (ノード間の接続)、グラフ (ノードとエッジで構成される全体) の 3 つの要素が含まれます。
これら 3 つの要素を使用して生物学の研究対象を定義するにはどうすればよいでしょうか?以下の図には 4 つのケースがあります。

小さな分子(図)の場合、 各原子をノードとして定義し、原子間の距離関係や化学結合関係をエッジで表すことができます。
たんぱく質をアミノ酸レベルで見ると、 タンパク質全体は、各アミノ酸がグラフのノードとして機能するグラフとして表示できます。異なるアミノ酸が空間的に近い位置にある場合、それらの間には何らかの相関関係があり、これらの空間的に類似したアミノ酸ノードはエッジを介して接続されていると考えられます。
同様に、タンパク質を二次構造を基本単位として見ると、 次に、各二次構造をタンパク質グラフのノードとして使用することができ、その隣接または空間的に近い二次構造がエッジを介して接続されます。
最後に、疾患知識グラフについては、 さまざまな病気、遺伝子、薬、患者などの要素をノードとみなすことができ、ノード間の接続は、たとえば、特定の薬が特定の疾患を治療できる、または特定の遺伝子が特定の疾患を引き起こすなど、それらの間の複雑な関係を表します。 、など。
グラフを定義した後、次のステップは、ノードやエッジの特徴などのグラフ上の情報をどのように記述するかを検討することです。
以下の図に示すように、4 つのノード間には特定の相互関係があり、これらの関係を正確に表すために、隣接行列 A を定義できます。 さまざまな生物学的データを処理する場合、隣接行列を使用して、原子間に共有結合があるかどうかを特徴付けたり、特定のアミノ酸の k 次の近傍を決定したりできます。

さらに、各ノードとエッジには一連のプロパティを付けることができます。 アミノ酸ノードを例にとると、ノードの属性には、その種類、物理的および化学的特性などの特性情報を含めることができます。ノードを接続するブリッジとして、エッジは、2 つのアミノ酸間の距離 (配列距離と空間距離を含む) をカバーする各エッジの特徴ベクトルなどの特徴情報、エッジを確立するための基礎 (空間構造または空間構造に基づく) も運ぶことができます。原子の化学結合など)、これらのエッジの特徴は、ノード間の関係を理解するためのより詳細かつ詳細な視点を提供します。
総括する、あらゆる構造化された対象 (タンパク質など) はグラフとして表現できます。 以下の図に示すように、G はグラフを表すために使用できます。v はノードを表し、ε はエッジを表します。Xv はノード上の特性を表します。隣接行列 A はノードの接続を表し、Xe はエッジの特性を表します。
グラフの 3 つの基本要素 (ノード、エッジ、グラフ) に基づいて、グラフ上のベクトル表現と予測タスクは次のように分類できます。
- ノード予測 (ノードレベルの予測)。 例えば、タンパク質の配列設計とは、タンパク質のグラフがわかっている場合に、グラフ内の各ノードが表すアミノ酸の種類を予測することです。
- リンク予想。 グラフとすべてのノードが与えられた場合、遺伝子制御ネットワーク、薬物知識グラフ、その他の予測タスクなどのノード間に関係があるかどうかを推測します。
- グラフレベルの予測。 ノードとエッジが決定されると、複数のグラフが同時に学習および分析され、各グラフのラベルが予測されます。
グラフ ニューラル ネットワークとは: GCN だけでなく、GAT、GraphSAGE、EGNN など
グラフ ニューラル ネットワークは、与えられたノード間の接続関係に基づいて各ノードの隠れ層表現を検索し、各ノードのベクトル表現を見つけます。他の種類のデータと比較して、グラフの最大の特徴は、どのノードが互いに直接関係しているか、および異なるノード間の関係がどの程度緊密であるかを明確に示すことができることです。したがって、グラフ ニューラル ネットワークの本質は、これらの誘導バイアスを使用して、接続されたノード間でメッセージを送信することです。隣接ノードが近ければ近いほど、中央ノードに対する影響が大きくなります。
次に、いくつかの古典的なグラフ畳み込みニューラル ネットワークを紹介します。
1つ目はグラフ畳み込みニューラルネットワークGCNです。 以下の図に示すように、GCN の各層が中央ノードへの 1 次隣接情報を平均的に集約し、集約された情報を中央ノードの新しい表現として使用することが中心となります。
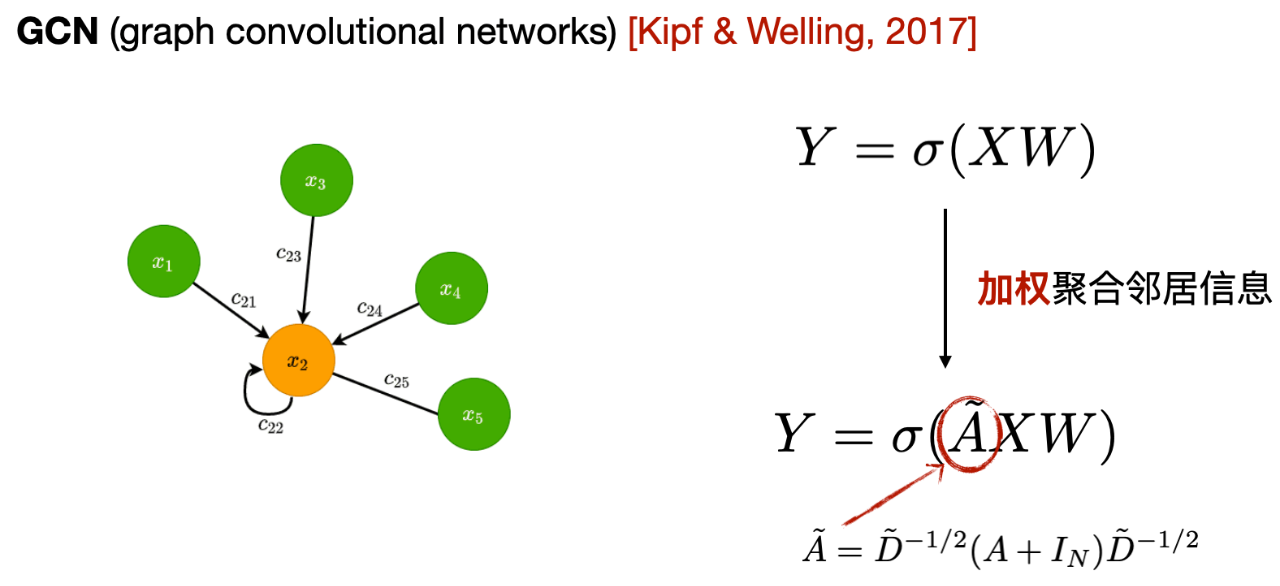
式からわかるように、GCN と MLP の違いは、GCN が隣接行列に結合し、一次近傍情報を使用してノード表現を更新することです。さらに、情報を集約するときに自己ループを追加して自身の情報を強化し、各隣接ノードの隣接ノードの数に基づいて加重平均を実行します。
- 1 次ネイバー: 中央ノードは他のノードに直接接続されています。つまり、1 つのエッジを介して到達できるポイントは 1 次ネイバーと呼ばれます。
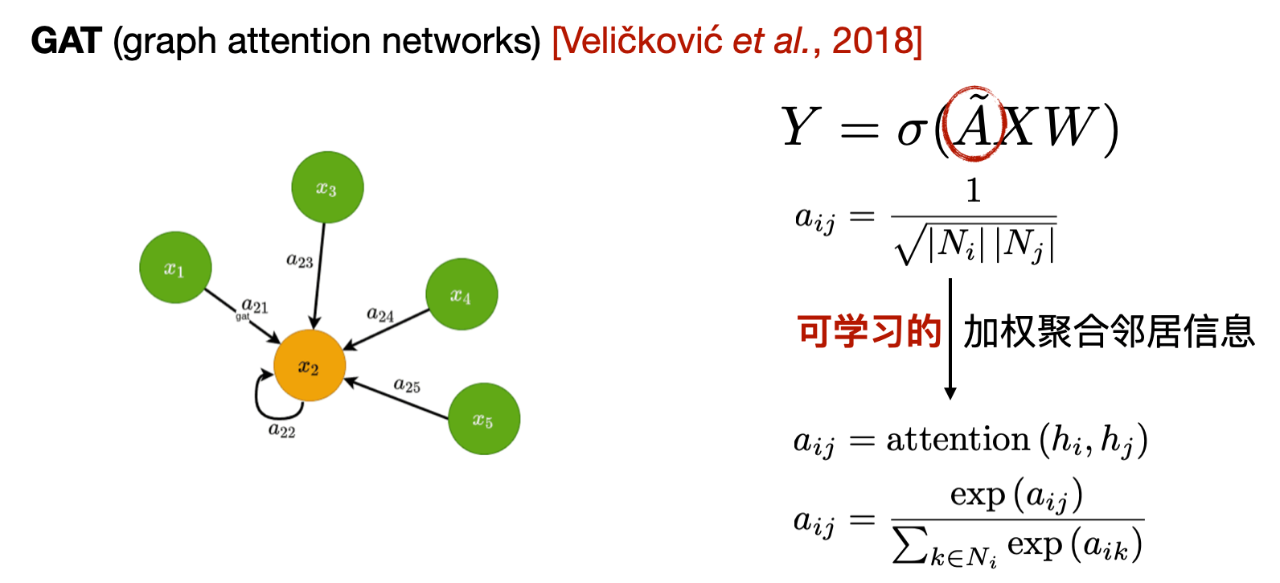
2 つ目はグラフ アテンション ネットワーク GAT です。 GAT の主な変更点は、GCN と比較して、近隣情報を集約する際の重みの計算方法です。 GCN は隣接行列に基づいて計算された重みを使用しますが、GAT は隣接ノードの特性に基づいて学習可能な重みを計算します。
上記の 2 つの方法は、入力時に完全なグラフを提供する必要があるため、計算量が増加します。この点に関して、GraphSAGE は帰納的手法を提案しています。 各情報送信では、中央ノードの 1 次隣接ノードのみを知る必要があり、隣接ノードの情報の一部のみが集約のためにランダムに選択されます。
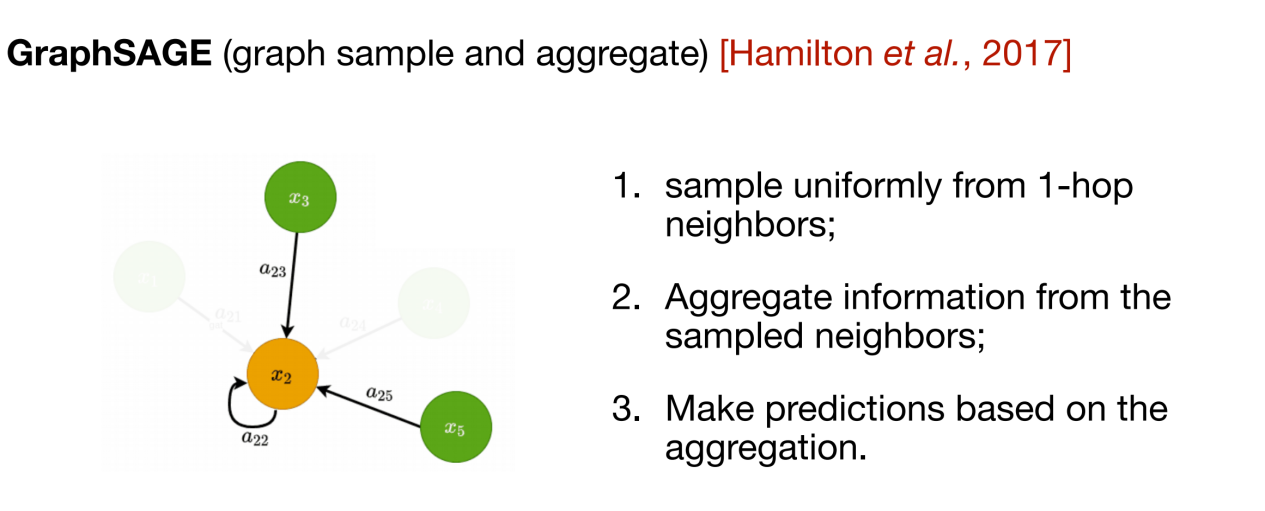
上記の 3 つの方法は、2 次元トポロジ構造グラフのノード上の表現を更新するものであり、後続のメッセージ パッシング ネットワーク (MPNN) は、このタイプの情報集約方法をフレームワークに統合します。ただし、多くの生物学的データ (分子など) では、3 次元空間構造も考慮する必要があります。空間情報を統合するには、等変グラフ ニューラル ネットワーク (EGNN) を使用できます。 以下の図に示すように、この手法の核心は、ノード自体の特徴情報に加えて、ノード間の相対的な位置関係も導入して、学習表現の回転等変性と並進不変性を保証することです。

さらに、高度なグラフ ニューラル ネットワーク設計が数多くあり、一部の設計では、モデルの予測パフォーマンスを向上させるだけでなく、連続メッセージの導入により、効率の向上、過度の平滑化の削減、マルチスケール表現の追加などに重点を置くことができます。パッシングおよびスペクトル グラフ畳み込み手法など、特定の問題に対してより強力な表現機能を備えたグラフ ニューラル ネットワークを提供することもできます。
グラフ ニューラル ネットワークの重要な用途: タンパク質の特性予測と配列生成を例に挙げる
次に、タンパク質表現学習におけるグラフ ニューラル ネットワークの応用について説明します。ここでは、予測モデルと生成モデルの 2 つのカテゴリに分けます。
タンパク質の特徴エンコードと属性予測
予測タスクについては、変異特性予測、溶解度予測、サブグラフ マッチングの 3 種類のタスクを検討します。具体的なタスクは 4 つあります。
最初の研究は、突然変異タスクの予測に関するもので、 以下の図に示すように、等変グラフ ニューラル ネットワークを使用して、タンパク質アミノ酸の内部空間関係を記述しました。各ノードはアミノ酸を表し、点はアミノ酸の種類、物理的および化学的性質を表します。グラフ上のエッジは接続されており、共進化ポテンシャルや相互作用力などのアミノ酸間の相互関係を反映しています。
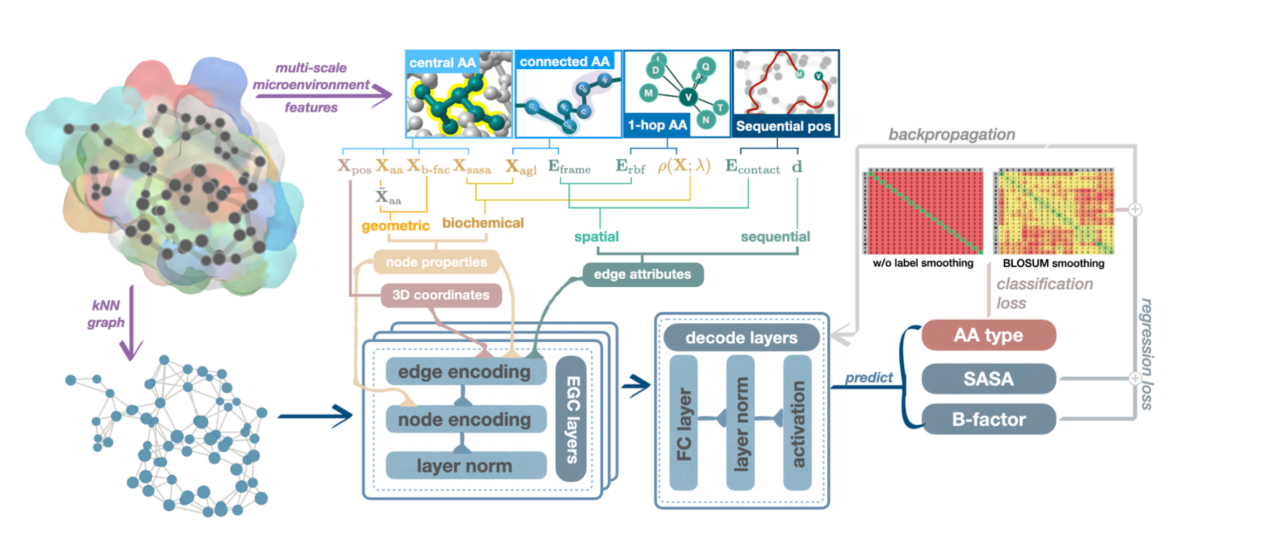
次に、予測モデルを使用してさまざまな変異体をスコア化し、タンパク質の特性を最適化する可能性が最も高い変異の組み合わせを特定します。この軽量のグラフ ニューラル ネットワークは、アミノ酸とアミノ酸コストとデータ コスト間の関係を統合することで、トレーニングを大幅に削減できます。 、高性能を維持しながら、小さくて美しいモデルです。さらに、タンパク質のさまざまな特性に関する湿式実験による検証により、このモデルが指向性進化の効果と成功率を大幅に向上できることが証明できます。この研究は「軽量グラフノイズ除去ニューラルネットワークによるタンパク質工学」というタイトルで、ACS JCIMに掲載されました。
用紙のアドレス:
https://pubs.acs.org/doi/10.1021/acs.jcim.4c00036
2 番目の研究では、構造コーディングに基づいてタンパク質配列コーディングをさらに追加します。 これは、構造情報では、近くのアミノ酸間の相互作用がより強いが、離れたアミノ酸間の相互作用は非常に弱いと仮定されているため、この仮定は完全に現実的ではないため、長距離の相互作用の考慮を補うために配列情報が必要です。さらに、さまざまな生物学的特性に関する情報は、結合エネルギーや熱安定性については構造情報が優先されますが、触媒活性などの特性に関しては、アミノ酸の種類の情報がより重要です。
以下の図に示すように、ProteinGym で 200 以上のアッセイについて実験テストを実施し、非 MSA メソッドの最高のパフォーマンスが得られました。この研究は「生物活性と熱安定性の強化に向けた意味的および幾何学的タンパク質エンコーディング」と題され、eLife に掲載されました。
用紙のアドレス:
https://elifesciences.org/reviewed-preprints/98033
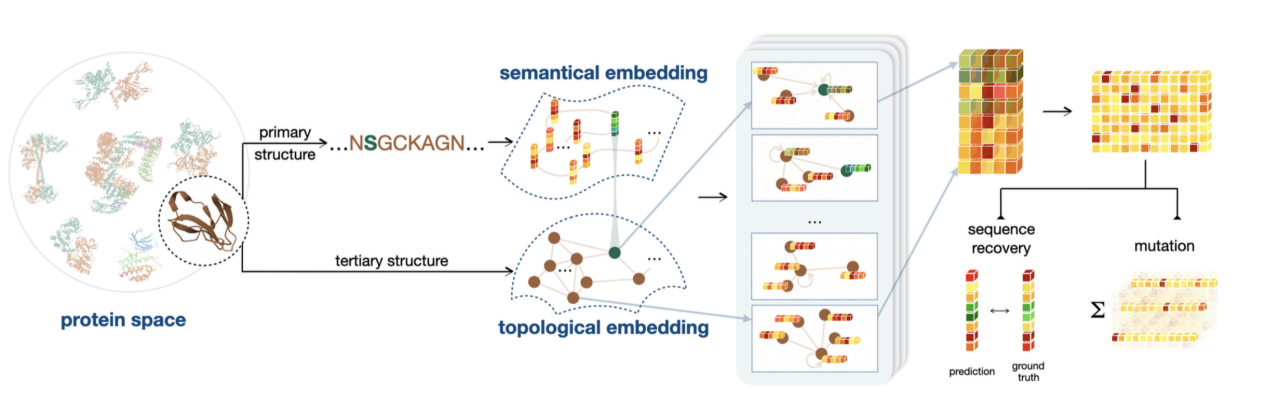
3番目の作品のアミノ酸レベルのコーディングモジュールは2番目の作品と一致しており、 情報の統合はタンパク質の配列と構造に基づいていますが、タンパク質の長さや20個のアミノ酸の割合分布など、事前の知識に基づいたさまざまなタンパク質レベルの情報も統合する点が異なります。
以下の図に示すように、タンパク質の溶解度に対するモデルの予測効果をテストし、計算と実験に基づいた数千のテストデータで SOTA 結果を達成しました。この研究は「ProtSolM: マルチモーダル機能によるタンパク質溶解度予測」と題され、IEEE BIBM2024 (CCF カテゴリ B 会議) に採択されました。
論文アドレスのプレプリント版:
https://www.arxiv.org/abs/2406.19744
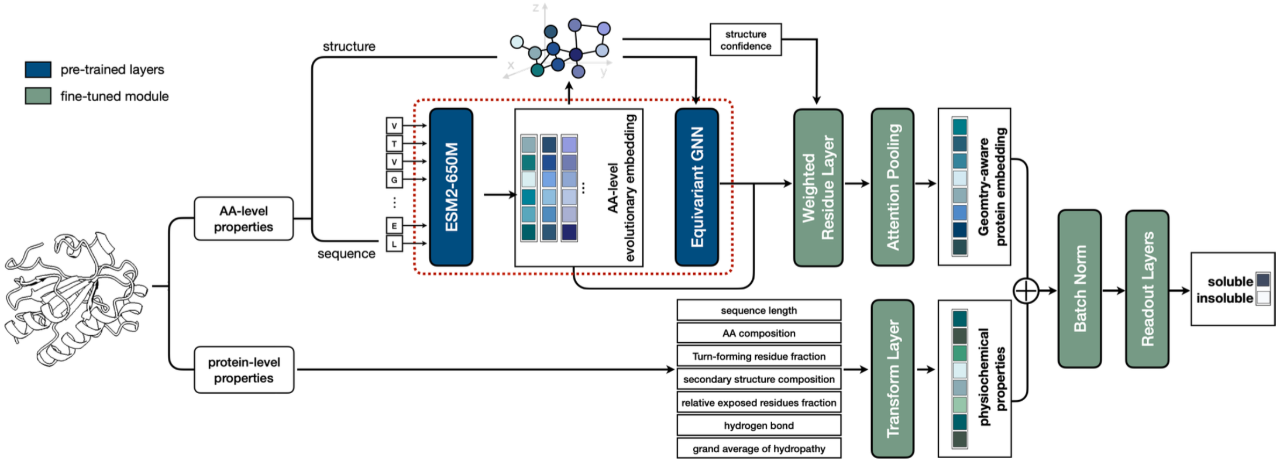
4 番目の取り組みは、タンパク質構造の局所的な類似性を調査することです。 下の図に示すように、タンパク質全体は巨大ですが、その核心は特定の局所的な構造的特徴にある可能性があります。さらに、マクロ的な観点から見ると、2 つのタンパク質は配列および構造レベルで完全に異なっていても、類似または均一である可能性があります。同一のコア機能モジュール。
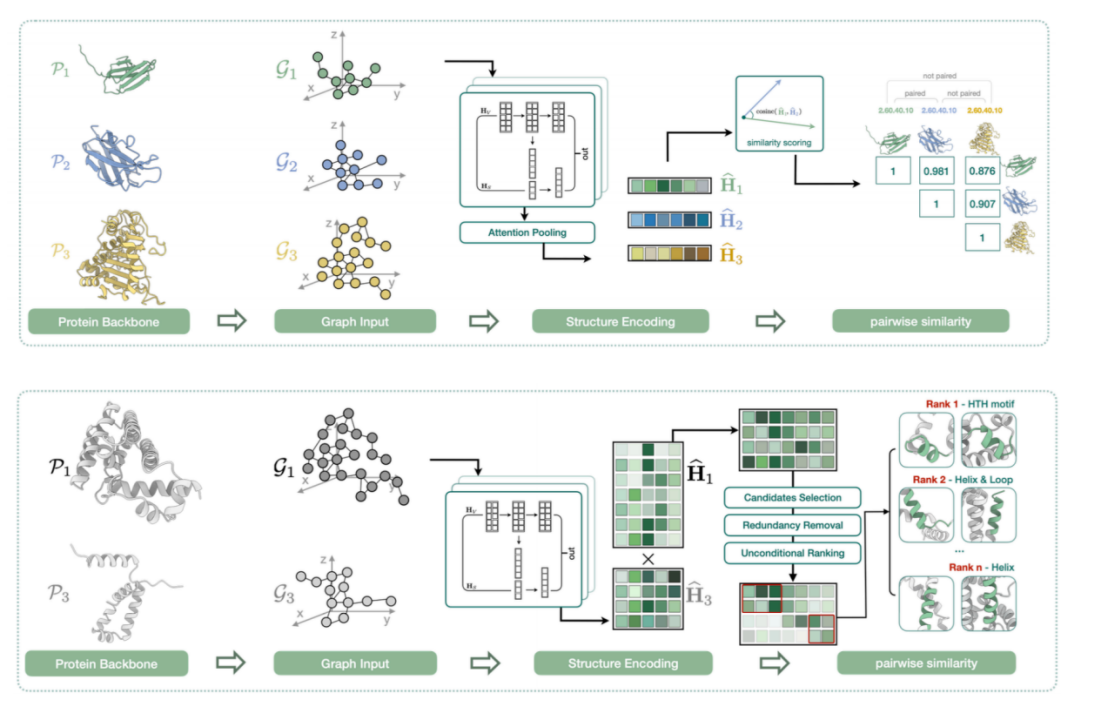
したがって、各タンパク質の局所構造の暗黙の式を見つけ、これらのベクトル間の類似性を計算します。構造間の 1 対 1 の類似関係を比較することに加えて、2 つの完全な構造の間に整列性があるかどうかも評価します。タンパク質の局所構造断片。この研究は「配列情報埋め込みによるタンパク質表現学習: 常に優れたパフォーマンスにつながりますか?」というタイトルで、IEEE BIBM2024 に採択されました。
論文アドレスのプレプリント版:
https://arxiv.org/abs/2406.19755
シーケンスの生成
次に、タンパク質構造に適切なアミノ酸配列を設計するという 2 つのタスクについて説明します。これら 2 つのタスクの中核となるモデルは拡散確率モデル (Diffusion) です。
最初の仕事は、タンパク質の性能を向上させるために、既知のアミノ酸骨格に基づいて完全なタンパク質配列を設計することです。 モデルの枠組みを以下の図に示します。方向性進化とは異なり、私たちは一度に何百ものアミノ酸を改変して、より多様性の高いタンパク質配列を取得します。一方で、この方法は進化の新たな出発点を見つけ、指向性進化における局所的最適性や負のエピスタティック効果などの一般的な問題を回避できる可能性がある一方で、より多くのアミノを修飾することで配列類似性は低くても同じ機能を得ることができる。酸、タンパク質により特許の封鎖を打ち破ることが可能になります。
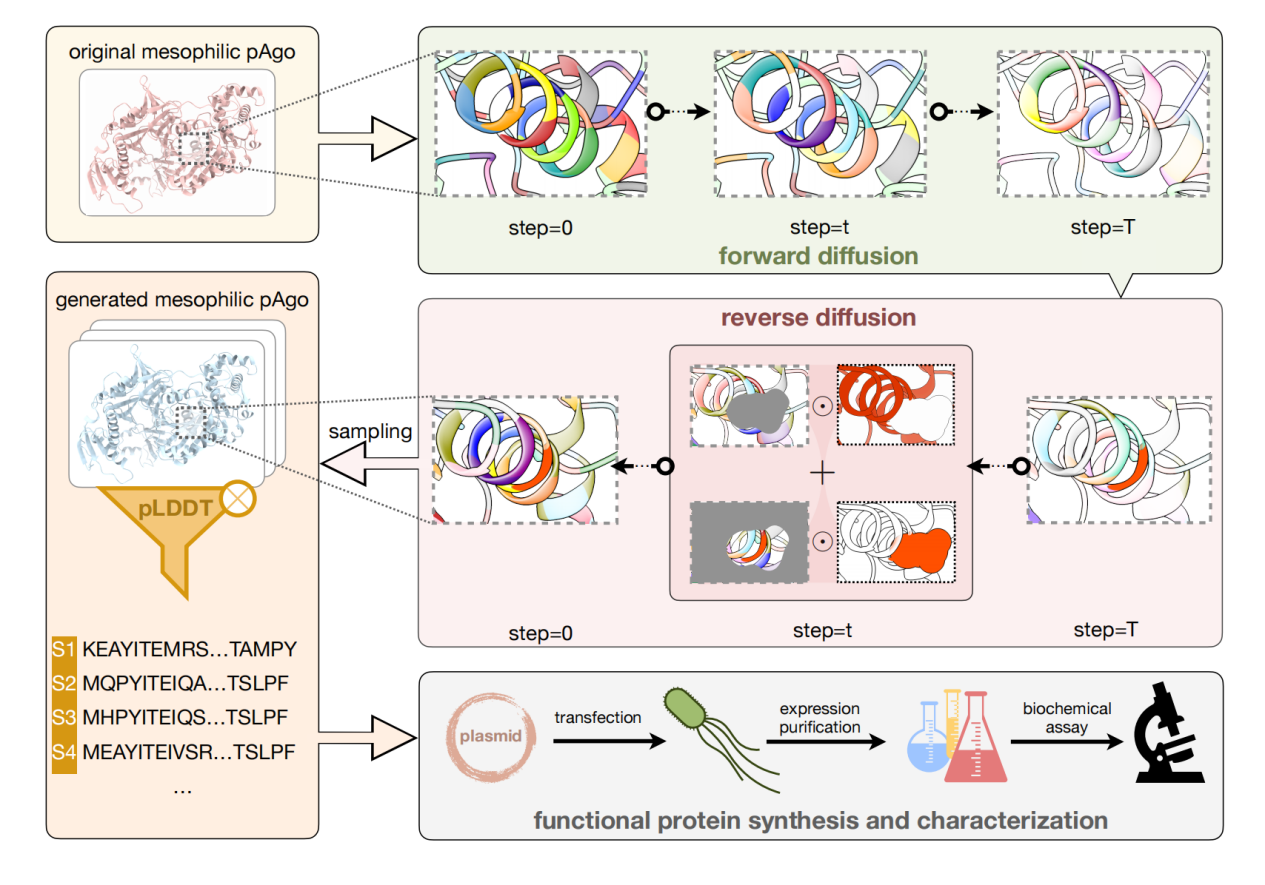
2 つの Argonaute タンパク質 (それぞれ中温と超高温で機能する) を設計テンプレートとして使用しました。生成された 40 種類を超えるタンパク質のほとんどは、室温で DNA 切断を実行できます。その中で、最良の設計では切断が 10% 向上しました。野生型と比較して、熱安定性も大幅に向上しています。この研究は「条件付きタンパク質のノイズ除去拡散がプログラム可能なエンドヌクレアーゼを生成する」と題され、Cell Discovery に掲載されました。
論文アドレスのプレプリント版:
https://www.biorxiv.org/content/10.1101/2023.08.10.552783v1
2 番目の研究では、下図に示すように、アミノ酸の主鎖構造を厳密に制限することなく、二次構造に基づいてアミノ酸の充填数と位置を独自に決定します。 スケルトンベースの生成方法と比較して、このより粗い生成条件は、生成される配列に配列の多様性を導入することができ、改変されたタンパク質や新たに設計されたタンパク質の特定のニーズにも応えることができます(たとえば、膜貫通タンパク質の場合、膜貫通部分のみ)拘束されている螺旋構造ですが、この部分の長さや具体的な骨格は厳密には制限されません。 「潜在グラフ拡散による二次構造誘導型新規タンパク質配列生成」と題されたこの研究は、ICML AI4Science に受理され、全文が審査中です。
論文アドレスのプレプリント版:
https://arxiv.org/html/2407.07443v1
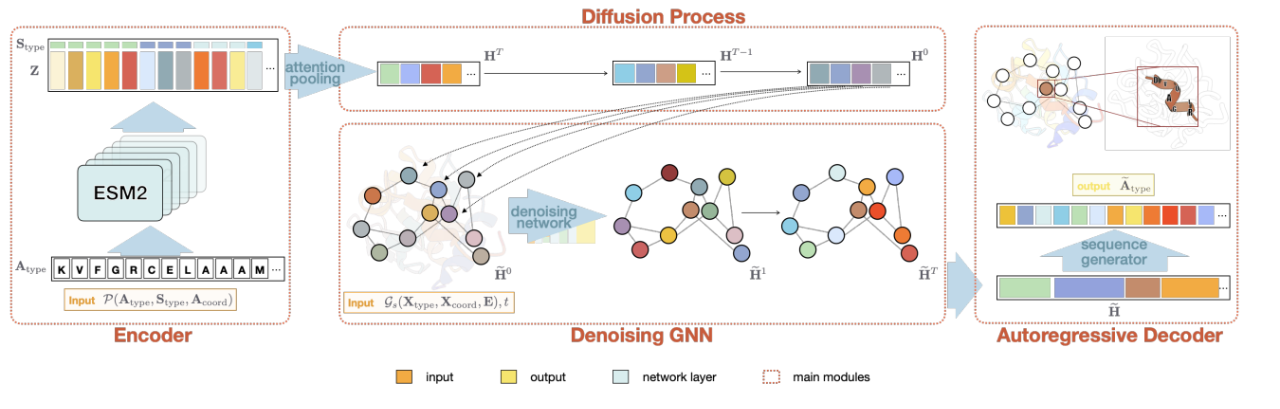
拡散に基づく上記 2 つのタンパク質配列設計タスクは、タンパク質骨格に基づいて全体の配列を生成するだけでなく、重要なアミノ酸と骨格構造の一部を固定し、これを生成条件として使用して、タンパク質の未固定部分を埋めることができます。アミノ酸配列。
より生物学的な問題におけるグラフ ニューラル ネットワークの応用
従来の分子グラフ モデリングに加えて、グラフ ニューラル ネットワークを他のタイプのデータや問題に適用して、より生物学的な問題の研究を促進することもできます。次に 2 つの例を紹介します。
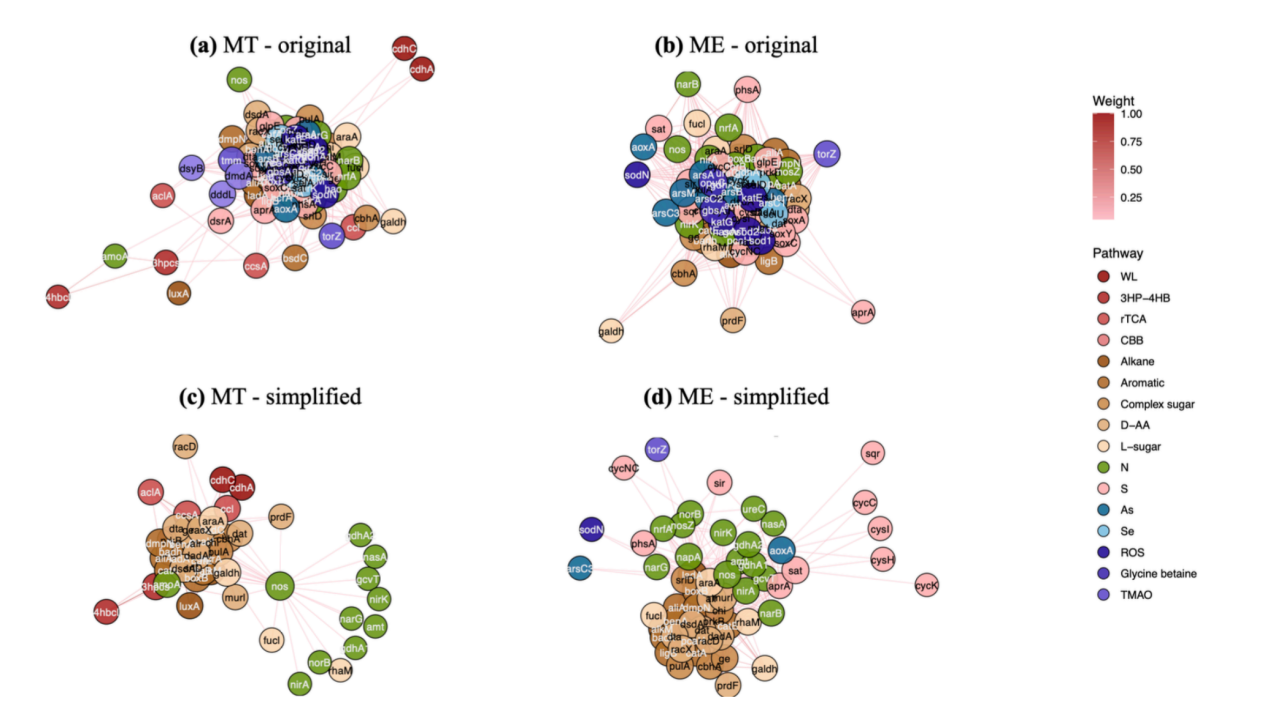
最初の例は、生物学的なソーシャルネットワークの分析と単純化です。 人間のソーシャル ネットワークの複雑な関係と同様に、さまざまなレベルの生物学的ソーシャル ネットワーク (微生物ネットワーク、遺伝子ネットワークなど) には、探索する価値のある内容が数多くあります。
私たちは遺伝子共起ネットワークを利用してソーシャルネットワークの単純化研究を行ってきました。下図に示すように、図aと図bはそれぞれ深海と山地に存在する同じ遺伝子の異なるネットワークであり、その本来の形は人間のソーシャルネットワークと同様のグラフニューラルネットワークを構築することで単純化して識別します。 2 つのネットワークで絶対的に優勢な位置を占める遺伝子を特定し、どの遺伝子が相互に密接な関係を持っているか、どの遺伝子が相互に弱い関係を持っているかを区別します。簡素化されたネットワークは、生物学者が専門知識を利用してネットワークと生物学的群集を分析するのに役立ちます。研究の暫定版は「ソーシャルネットワークの意見力学を伴うニューラルメッセージパッシングに関する統一見解」と題されている。
論文アドレスのプレプリント版:
https://arxiv.org/abs/2310.01272
2番目の例は、グラフニューラルネットワークに基づく解釈可能性の研究です。 直観的な例としては、グラフ ニューラル ネットワークが分子内の重要な局所構造の特定に役立つことが挙げられます。一方で、この結果はモデルの合理性をテストするために使用できます。たとえば、タンパク質の機能を予測する場合、モデルが活性中心の近くに重要な原子またはアミノ酸をある程度配置できれば、そのモデルが適切であることを示します。逆に、モデルの注意がタンパク質表面の複数のアミノ酸にランダムかつ離散的に分布している場合、モデルに問題がある可能性があります。一方、理想的な状況下では、機能予測における各ノードの役割を分析することにより、合理的で強力な説明モデルが得られ、将来的には新しいタンパク質のポケット領域を特定するのに役立つ可能性もあります。
大規模なモデルは多くのアプリケーション シナリオで豊富な成功体験を提供してきましたが、さまざまな構造データが自然に存在する分野として、グラフ ニューラル ネットワークは生物学における多くの問題の解決の可能性を提供できます。分子、複合体、遺伝子、微生物ネットワーク、またはより大規模で複雑なシステムのいずれであっても、グラフ ニューラル ネットワークは、帰納的バイアスを埋め込むことで、少量のデータであっても人間の事前知識を最大限に活用することで、簡潔な解決策を提供できます。
周炳信について

Zhou Bingxin は現在、上海交通大学および国立応用数学センター (上海交通大学分校) で助研究員を務めています。彼女は 2022 年にオーストラリアのシドニー大学で博士号を取得し、その後客員研究員として英国のケンブリッジ大学を訪問しました。彼の研究は、酵素工学、代謝遺伝子ネットワーク、タンパク質構造グループ進化解析などの生物学の課題を解決するために深層学習 (特に幾何学的深層学習) を使用することに焦点を当てています。開発された深層学習アルゴリズムは、静的グラフ、動的グラフ、異種グラフ、ノイズ グラフなどの処理に使用され、その一部は IEEE TPAMI、JMLR、ICML、NeurIPS などの主要な国際ジャーナルや会議で発表されています。このフレームワークは、複雑なタンパク質の活性を効果的に設計し、大幅に改善することができ、一部の結果は eLife、Chem Sci.、ACS JCIM およびその他のジャーナルに掲載されています。
個人ホームページ:
https://ins.sjtu.edu.cn/peoples/ZhouBingxin
Google Scholar:








