Command Palette
Search for a command to run...
Meta の最大のビデオ セグメンテーション データ セットがリリースされました。これは、9,000 個のスターを収集した同様のデータ セットの 50 倍の大きさです。 Kuaishou Digital Human Demo はワンクリックで開始できます!

AI はどのようにして静止したポートレートに命を吹き込み、笑顔、瞬き、さらには微妙な表情に命を吹き込むことができるのでしょうか?最近、Kuaishou チームは、静止した写真をアップロードするだけで、豊かな表現を備えた動的なポートレートに変換できる LivePortrait をオープンソース化し、GitHub で 9,000 個のスターを獲得しました。このチュートリアルは HyperAI 上でオンラインで公開されています。すぐに体験してみてください。
ライブポートレート チュートリアルのリンク:
7 月 29 日から 8 月 2 日までの hyper.ai 公式 Web サイトの更新の概要:
* 高品質の公開データセット: 11
* 高品質なチュートリアルのセレクション: 3
* コミュニティ記事選択: 4 記事
* 人気のある百科事典のエントリ: 5
※8月締切:4日
公式ウェブサイトにアクセスしてください:ハイパーアイ
公開データセットの選択
SA-V データセットは、2024 年に Meta によって構築された大規模なビデオ セグメンテーション データセットです。Meta Segment Anything Model 2 のトレーニングと評価に使用されます。これには、約 51,000 の実世界ビデオと 643K の時空間マスク アノテーションが含まれています。他の同様のデータセットよりも 50 倍大きい。
直接使用します:https://go.hyper.ai/X4DGI
2. LAB Bench 生物学ベンチマーク データ セット丨 8 つの主要なタスクと 2.4K を超える多肢選択問題をカバー
生物学分野における AI システムの効果的な開発を促進するために、FutureHouse Inc. の研究者は、文献検索と推論、グラフ解釈、DNA およびパフォーマンスにおける AI システムの評価に使用される言語エージェント生物学ベンチマーク データセット LAB-Bench を立ち上げました。タンパク質配列の理解と処理などの実際の生物学的研究の成果が、トップカンファレンスNeurlPS 2024に提出されました。
直接使用します:https://go.hyper.ai/UznkS
3. NuminaMath-CoT 数学コンテスト問題データセット
このデータセットには 860,000 を超える数学コンテストの質問と回答のペアが含まれており、それぞれのペアが思考連鎖 (CoT) 推論テンプレートを使用しています。データセットのソースには、中国の高校数学の練習問題、アメリカおよび国際数学オリンピックの問題が含まれます。データは主にオンラインの試験問題 PDF と数学ディスカッション フォーラムから収集されました。
直接使用します:https://go.hyper.ai/svElx
このデータ セットには、モバイル ゲーム アプリ TapTap 上の約 300 ゲームのタグ付きレビューが含まれており、合計 4,888 のデータ例があり、感情分析タスクに使用できます。このうち、ユーザーレビューが星3つ未満(最大星5つ)を0(不満)、それ以外を1(満足)としています。 2 つのカテゴリ間の比率は約 1:1 です。
直接使用します:https://go.hyper.ai/ISf7c
5. CCPD データセット 中国ナンバー プレート検出データセット
CCPD データセットは、大規模で多様な、慎重に注釈が付けられたナンバー プレート認識データセットです。このデータセットは主に中国の合肥市の駐車場で収集されたもので、ぼやけ、傾き、雨や雪の日など、さまざまな複雑な環境でのナンバー プレートの写真が含まれており、ナンバー プレートのデータ セットはより困難なものになっています。認識タスク。
直接使用します:https://go.hyper.ai/gZ37Y
このデータセットは GPT-3.5 および GPT-4 によって生成された短編小説の合成データセットであり、3 ~ 4 歳の子供が理解できる範囲に限定された語彙が含まれています。このデータセットを使用してモデルをトレーニングし、滑らかで一貫性があり、多様性があり、文法がほぼ完璧な短編小説を生成できます。
直接使用します:https://go.hyper.ai/m9ouS
このデータセットは、AI for Mankind と HPWREN によって 2019 年に共同リリースされました。これには、516 枚のトレーニング画像、147 枚の検証画像、74 枚のテスト画像を含む、合計 737 枚の画像が含まれています。アノテーション形式は COCO です。これは、雲/霧と煙を区別するモデルの能力を向上させ、エンドツーエンドのフィードバック ループを確立することを目的としています。
直接使用します:https://go.hyper.ai/ofGHZ
これは、1 人の話者が 7 冊のノンフィクション書籍の一節を朗読する 13,100 の短いオーディオ クリップを含むパブリック ドメインの音声データセットです。セグメントごとに文字起こしが提供されます。クリップの長さは 1 ~ 10 秒で、合計の長さは約 24 時間になります。
直接使用します:https://go.hyper.ai/Eo1bK
このデータセットには、12 の干支カテゴリが含まれており、合計 8,508 枚の画像が含まれています。データセットは、事前に 85:7.5:7.5 の比率でトレーニング、検証、テストに分割されています。
直接使用します:https://go.hyper.ai/ps2es
10. DISC-Law-SFT 高品質の中国法的監督微調整データセット
このデータセットには約 300,000 件のトレーニング データが含まれており、中国の法律分野向けに特別に設計されており、法的文章の処理、法的推論の思考、司法分野の知識の検索とコンプライアンスにおけるモデルの機能を向上させることを目的としています。
直接使用します:https://go.hyper.ai/zh9Ij
11. Free Spoken Digit Dataset (FSDD) デジタル認識音声データ セット
Free Spoken Digit Dataset (FSDD) は、サンプリング レート 8kHz の wav ファイル内のデジタル音声録音で構成される音声データセットです。録音は、最初と最後の無音の時間を最小限に抑えるためにトリミングされました。
直接使用します:https://go.hyper.ai/HZ00d
その他の公開データセットについては、以下をご覧ください。
選択された公開チュートリアル
1. 新しいチュートリアル | 描画、描画、画像修復のための 3 つが 1 つになったツール、HiDiffusion のワンクリックで開始できるチュートリアルがオンラインになりました。
HiDiffusion は Questyle Technology が開発したオープンソースの高解像度フレームワークで、Vincentian 画像や Tu で生成された画像をサポートするだけでなく、画像修復機能も備えています。 HyperAI Super Neural では、コマンドを入力する必要がなく、ワンクリックでクローン作成を開始できる「HiDiffusion で高品質の 8K 画像をすぐに生成できる」チュートリアルを開始しました。
オンラインで実行:https://go.hyper.ai/yZ5K5
2. LivePortrait Kuaishou オープンソース Tusheng ビデオ デジタル ヒューマン デモ
LivePortrait は、ポートレート ビデオ生成フレームワークです。その主な機能には、単一の画像からの鮮やかなアニメーションの生成、目と唇の動きの正確な制御、複数のポートレートのシームレスなスプライシングの処理、マルチ スタイルのポートレートのサポート、高解像度アニメーションの生成などが含まれます。このチュートリアルは、LivePortrait のワンクリック実行デモです。関連する環境と依存関係がインストールされており、クローンを作成してワンクリックで開始できます。
オンラインで実行:https://go.hyper.ai/oTs66
AuraSR は、ディープラーニングに基づいた高精細画像復元モデルであり、画像内の詳細情報をインテリジェントに識別し、画像を拡大しながら欠落している細部を自動的に補完できます。従来の画像拡大方法と比較して、AuraSR は効果が優れているだけでなく、操作も簡単で、専門的なスキルがなくても簡単に使用できます。ワンクリックでモデルを複製して体験できます。
オンラインで実行:https://go.hyper.ai/y2wIU
注目のコミュニティ記事
1. Meta/東京エレクトロニクス/FPTソフトウェアなどの共同貢献により、Aitomaticは企業の技術的自律性を「ロックイン」する半導体業界初のオープンソース大規模モデルをリリース
産業分野における AI イノベーションのリーダーである Aitomatic は、半導体業界向けに特別に設計された世界初のオープンソース AI 大規模言語モデルである SemiKong の発売を発表しました。同社は以前、aiKOと呼ばれるAIエージェントを立ち上げており、企業ユーザーの専門知識とデータに基づいて専用のエージェントを構築しており、企業はエージェントの「完全な所有権」を持っています。
レポート全体を表示します。https://go.hyper.ai/A7eCi
2. ハイライト: ファン・ジェンシュンとザッカーバーグの「世紀の会話」
7 月 30 日の早朝、第 51 回 SIGGRAPH グラフィックス カンファレンスで、NVIDIA の創設者兼 CEO のジェンセン フアン氏と Meta の創設者兼 CEO のマーク ザッカーバーグ氏が「炉辺談笑」をしました。 HyperAI は、最高のクリップと中国語字幕付きの完全なビデオを編集しました。
レポート全体を表示します。https://go.hyper.ai/rbU2u
3. ICMLに選出されました! MITチームがAlphaFoldに基づいて新たなブレークスルーを達成、タンパク質の動的な多様性を明らかに
MIT 研究チームは、AlphaFold や ESMFold などの高精度一重項予測子を再利用し、カスタム フロー マッチング (フロー マッチング) フレームワークの下で微調整して、AlphaFLOW および ESMFLOW と呼ばれる配列条件付きタンパク質構造生成モデルを取得しました。この記事は、関連する論文を詳細に解釈して共有するものです。
レポート全体を表示します。https://go.hyper.ai/qupG9
4.上級病理医にも負けないレベル!清華大学チームが神経膠腫の正確な診断を実現するAI基本モデルROAMを提案
清華大学オートメーション学部の生命基本モデル研究室は、中南大学祥雅病院と協力し、地域の大きな利益に基づいた正確な病理診断AI基本モデルROAMと、臨床レベルの診断と神経膠腫の分子マーカーのためのピラミッドトランスフォーマーを提案しました。他の種類の腫瘍の病理学的診断にも拡張できます。
レポート全体を表示します。https://go.hyper.ai/w4tsr
人気のある百科事典の項目を厳選
1. 神経放射線場 NeRF
2. グループクエリアテンションGQA
3. データの拡張
4. 大規模マルチタスク言語理解MMLU
5. 長期短期記憶長期短期記憶
ここには何百もの AI 関連の用語がまとめられており、ここで「人工知能」を理解することができます。
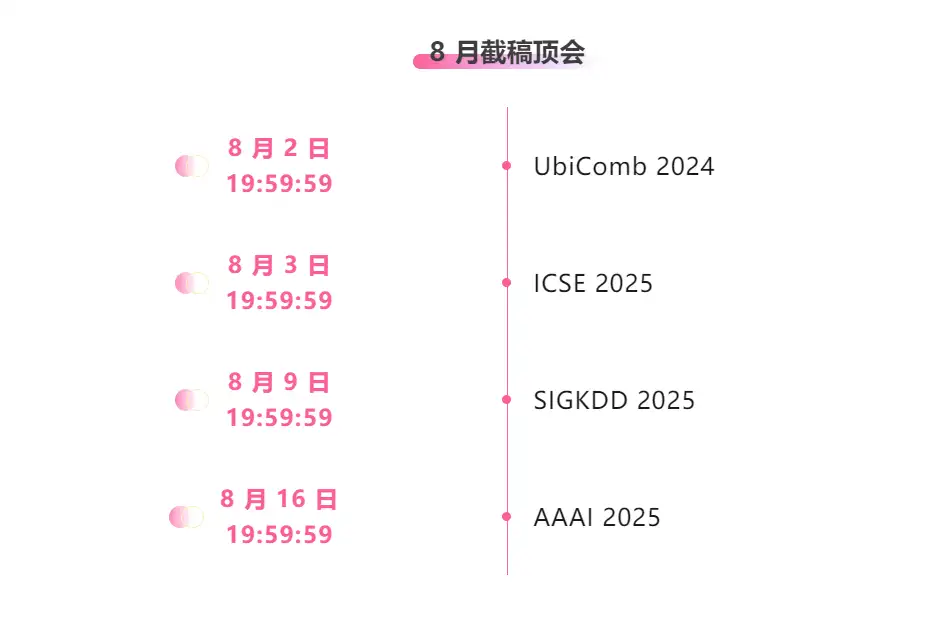
主要な人工知能学会をワンストップで追跡:https://go.hyper.ai/event
上記は、今週編集者が選択したすべてのコンテンツです。hyper.ai 公式 Web サイトに掲載したいリソースがある場合は、お気軽にメッセージを残すか、投稿してお知らせください。
また来週お会いしましょう!
HyperAIについて Hyper.ai
HyperAI(hyper.ai)は、中国をリードする人工知能とハイパフォーマンス・コンピューティングのコミュニティである。国内データサイエンス分野のインフラとなり、国内開発者に豊富で質の高い公共リソースを提供することに注力しています。
* 1,300 を超える公開データセットに対して国内の高速ダウンロード ノードを提供
* 400 以上の古典的で人気のあるオンライン チュートリアルが含まれています
* 100 以上の AI4Science 論文ケースを解釈
* 500 以上の関連用語クエリをサポート
*Apache TVM の最初の完全な中国語ドキュメントを中国でホストします
学習の旅を始めるには、公式 Web サイトにアクセスしてください。








