Command Palette
Search for a command to run...
まだ最終試験を受けていませんが、アルゴリズムによれば物理は間違いなく不合格になると予想されています。
大学の物理学は理工系の学生にとって必須の基礎科目ですが、その難しさゆえに多くの学生にとっても困難を感じています。研究者らは、教師がより適切に指導指導を提供し、教育リソースの配分を調整できるように、AI アルゴリズムを使用して物理の授業に失敗するリスクのある生徒を予測することを提案しました。
カップルが喧嘩するかどうかの予測から、地震や洪水がいつ発生するかの予測に至るまで、アルゴリズムの予測能力はますます強化されていると言わざるを得ません。
今では、アルゴリズムによって物理の授業に不合格になるかどうかも予測できるようになりました。
これは、ウェストバージニア大学とカリフォルニア工科大学の学者によって arxiv.org で発表された最近の研究です。

彼らは興味深い論文を発表しました。「機械学習を使用して物理の授業で最も危険にさらされている生徒を特定する」 (「機械学習を使用して物理の授業で最も危険にさらされている生徒を特定する」)。
論文では、機械学習アルゴリズムを通じて、物理基礎コースの学生の卒業成績を予測モデルでA、B、C、D、F、W(退学)に分類できるとしている。
注: 米国のほとんどの大学で採用されている成績とパーセンタイル スコアの対応するルールは次のとおりです: A: 90+; B: 70+; F: 不合格;コースを退会する(退会の略)。
予測される結果: 警報を鳴らしても、自分自身を救うことはできます
大学の物理学に支配されてパニックになったことを覚えていますか?
多くの理工系学生にとって、大学の物理学は高度な数学と同じくらい難しく、最も困難な科目の 1 つです。
海外の調査によると、かつては工学と科学(総称して STEM と呼ばれます)を専攻していたが、最終的に専攻を変更したり、学位を取得できなかった学生の間では、物理や数学などの主要科目が難しすぎるため、そうする学生は半数未満です。

STEM 学生、特に基礎科目の減少率は年々増加していますが、同時に社会の彼らに対する需要は依然として高く、人材には大きな格差が残っています。
そこで、ウェストバージニア大学とカリフォルニア工科大学の研究者らは、次のように提案しました。AI アルゴリズムを使用してこれらの生徒を救いましょう。
彼らは、機械学習アルゴリズムを使用して、コースを落第するリスクのある学生を特定できると信じています。これにより、教師は予測結果に基づいて的を絞った指導を行うことができ、生徒の合格率の向上と習熟状況の把握につながります。
アルゴリズム: 過去のパフォーマンスを参照して将来の結果を予測する
サンプル抽出
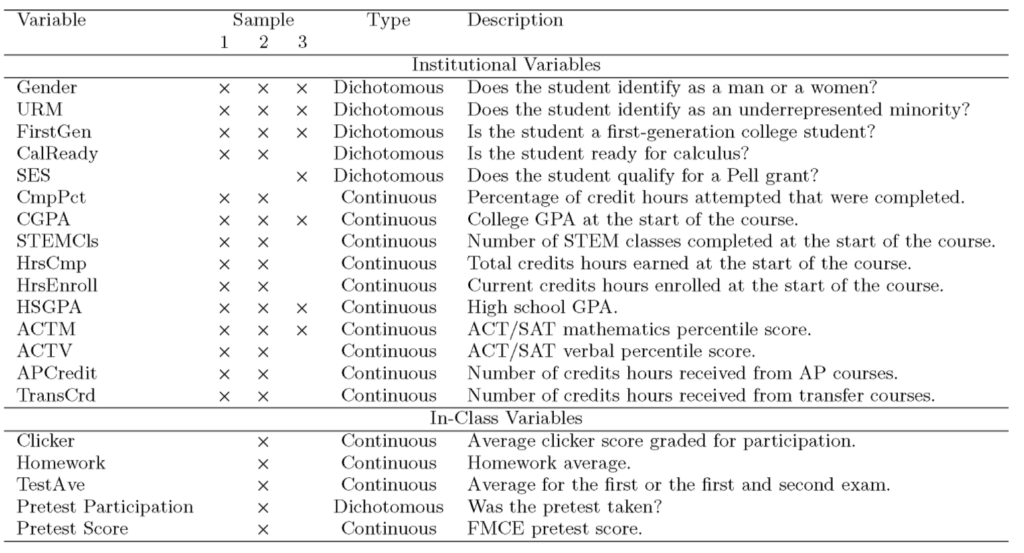
研究者らは、学生の成績を予測する人工知能アルゴリズムをトレーニングするために、2 つの大学から 3 つのサンプルを採取しました。
これらのサンプル データには次のものが含まれます。学生の ACT (米国大学入学試験) のスコア、大学の GPA、および物理の授業で収集されたデータ (宿題のスコアやテストのスコアなど)。
このうち、サンプル 1 とサンプル 2 は、米国東部の大学の物理科学と工学の学生からのものでした。
サンプル 1:2000 年から 2018 年までに大学の物理 1 コースを修了したすべての学生を含めると、サンプルサイズは 7184 人になります。
サンプル 2: 2016年秋学期から2019年春学期までのデータ、サンプルサイズは1,683人です。サンプルには、平均解答数、授業後の課題の平均成績、学期試験の得点などの教室のパフォーマンス データが含まれています。
サンプル 3:データは、2017 学年度を通じて力学入門コースから取得したものです。サンプル 3 は、米国西部にある別の大学で収集されました。
変数
この研究で使用される変数は、大学およびクラス内からのものです。同時に、性別、民族、その他の情報などの人口統計情報も含まれます。
ランダムフォレストアルゴリズム予測
研究では、ランダム フォレスト機械学習アルゴリズムは、物理学入門コースにおける学生の最終成績を予測するために使用されます。アルゴリズムは最終的に、生徒を、A、B、または C の成績を獲得した生徒 (ABC の生徒として分類) と、D、F または W の成績を獲得した生徒 (DFW クラスで不合格になる可能性のある生徒として分類) に分類します。
アルゴリズムのパフォーマンスを理解するために、データセットをテスト データセットとトレーニング データセットに分割しました。トレーニング データセットは、分類器をトレーニングするための分類モデルを開発するために使用されます。
テスト データ セットは、モデルのパフォーマンスを特徴付けるために使用されます。
分類モデルがテスト データ セット内の各生徒のテスト結果を予測した後、予測結果が実際の結果と比較されます。
結果:恥ずかしいけど精度57 %
モデルの調整と検証の後、研究者らは予測結果を得ましたが、精度はあまり楽観的ではありません...
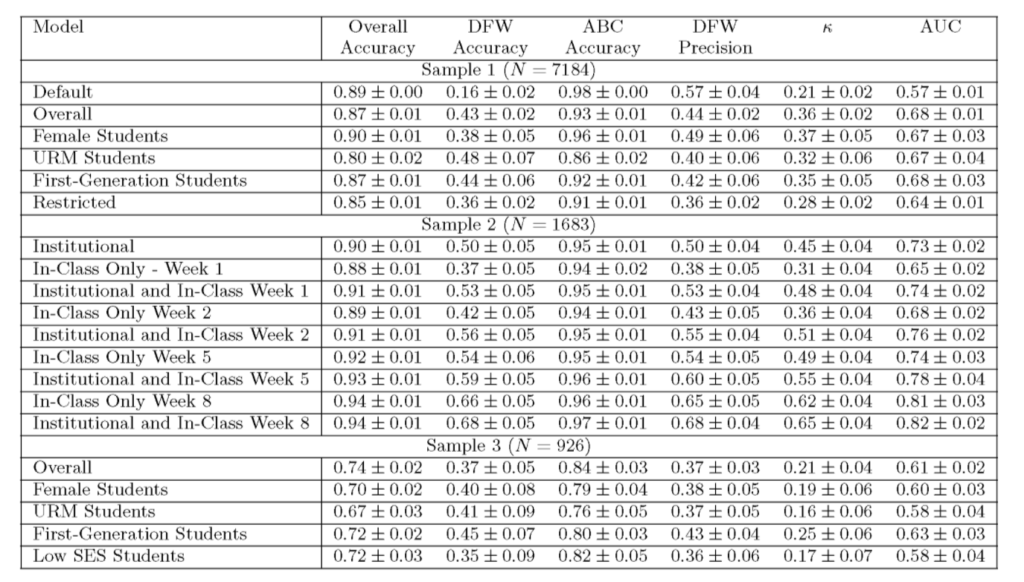
彼らは、サンプル全体の予測結果において、女性やマイノリティの生徒が多いサンプルでは DFW の精度が低く、彼らは、これには人口動態に合わせたモデルの調整が必要になると指摘した。
最初のサンプルでトレーニングされたアルゴリズムによる「DFW 学生」の予測精度はわずか 16% です。研究者らは、これはトレーニングセット内で DFW スコアを持つ生徒の割合が低い (12%) ためである可能性があると分析しました。
サンプル 1 では、モデルの最高のパフォーマンス精度は 57% に達するだけで、これはランダムな確率よりわずかに優れているだけです。
結果の精度は低く、モデルは物議を醸している
この結果に直面して、彼らは、このような機械学習分類モデルが、学習に苦労している教育者や学生にとって強力なツールになる可能性があると考えています。教育的介入と教育リソースの配分をより適切に導くことができます。
ネチズン:でも…57%ってちょっと低くないですか?
しかし、一部の批評家は次のように考えています。このようなテクノロジーは、偏った予測や誤解を招く予測を行うことで、生徒に害を及ぼす可能性があります。
研究によると、人工知能は大規模なコーパスでトレーニングされた場合でも、複雑な結果を予測する際にバイアスの問題が依然として存在します。
以前、Amazon の社内 AI 採用ツールは、女性に対する偏見を示していたため、無効化されました。
したがって、人々は、この成績予測アルゴリズムが STEM 学生の定着率を改善できないだけでなく、むしろ不平等を悪化させるのではないかと懸念しています。
もちろん、すべての結果は単なる予測にすぎません。試験では、3 点は性質、7 点は努力、残りの 90 点は教師の気分によって決まります。
- 以上 -

