Command Palette
Search for a command to run...
JMED 中国の実際の医療データデータセット
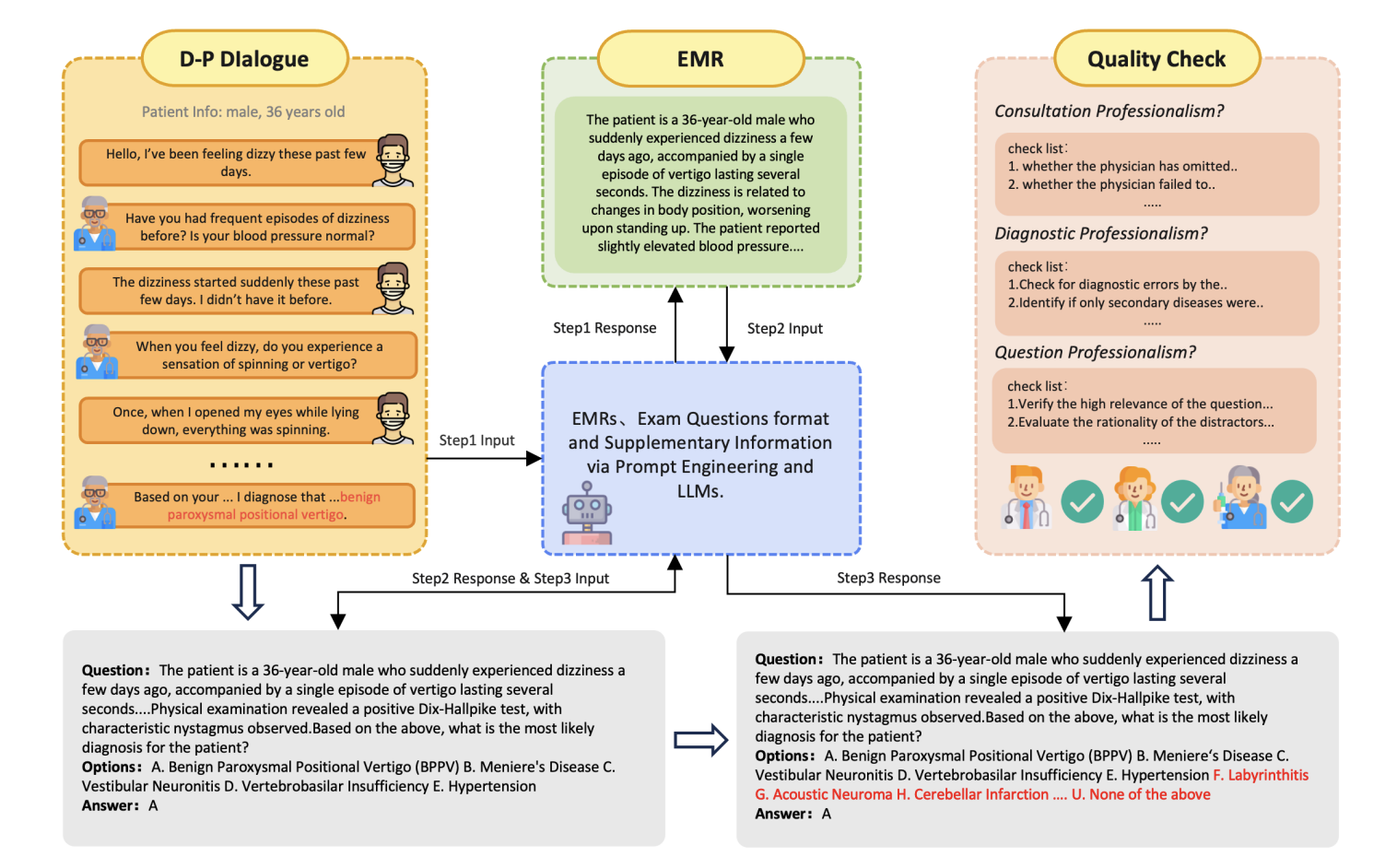
JMEDデータセットは、現実世界の医療データの分布に基づいた新しいデータセットです。2025年にCitrusチームによって構築されました。関連する論文の結果は次のとおりです。Citrus: 高度な医療意思決定支援のための医療言語モデルにおける専門家の認知経路の活用”。 このデータセットは、JD Health Internet Hospital における匿名の医師と患者の会話から抽出され、標準化された診断ワークフローに従った診察が保持されるようにフィルタリングされています。最初のリリースには、すべての年齢層 (0 ~ 90 歳) と複数の専門分野をカバーする 1,000 件の高品質の臨床記録が含まれています。各質問には、「上記のいずれでもない」という選択肢を含む 21 の回答オプションが含まれます。この設計により、正解を区別する複雑さと困難さが大幅に増加し、より厳密な評価フレームワークが提供されます。既存のデータセットとは異なり、JMED は実際の臨床データを厳密にシミュレートしながら、効率的なモデルトレーニングを容易にします。実際の診察データに基づいていますが、実際の医療データから直接得られたものではないため、研究チームはモデルのトレーニングに必要な主要な要素を統合することができます。 既存の医療 QA データセットと比較して、JMED には 3 つの主な利点があります。第 1 に、患者の症状の説明の曖昧さと実際のシナリオにおける臨床診断の動的な性質をより正確に反映します。第二に、拡張された回答オプションでは、多数の誤答の中から正しい答えを特定するために、高度な推論スキルが必要になります。さらに、JDの主要病院の膨大な診察データを活用することで、実際の患者分布特性に即したデータを継続的に生成することができます。