Les ressources informatiques utilisées dans ce tutoriel sont une seule carte A6000.
Kimi-Audio-7B-Instruct est un modèle de base audio open source publié par KimiTeam le 28 avril 2025. Ce modèle permet de gérer diverses tâches de traitement audio au sein d'un cadre unique et unifié. Parmi les articles de recherche associés, on peut citer… Rapport technique Kimi-Audio Les principales fonctions comprennent :
Capacités à usage général : gère une variété de tâches telles que la reconnaissance vocale automatique (ASR), les réponses aux questions audio (AQA), le sous-titrage audio automatique (AAC), la reconnaissance des émotions vocales (SER), la classification des événements/scènes sonores (SEC/ASC) et le dialogue vocal de bout en bout.
Performances de pointe : atteint les niveaux SOTA dans plusieurs benchmarks audio.
Pré-formation à grande échelle : Pré-formation sur plus de 13 millions d'heures de données audio diverses (parole, musique, son) et de données textuelles pour permettre un raisonnement audio puissant et une compréhension du langage.
Architecture innovante : en utilisant une entrée audio hybride (vecteur acoustique continu + balises sémantiques discrètes) et un noyau LLM avec des capacités de traitement parallèle, des balises texte et audio peuvent être générées simultanément.
Inférence efficace : démultiplexeur de streaming en morceaux avec correspondance de flux pour la génération audio à faible latence.
Open Source : publiez le code et les points de contrôle du modèle pour la pré-formation et le réglage fin des instructions, et publiez une boîte à outils d'évaluation complète pour promouvoir la recherche et le développement communautaires.
2. Étapes de l'opération
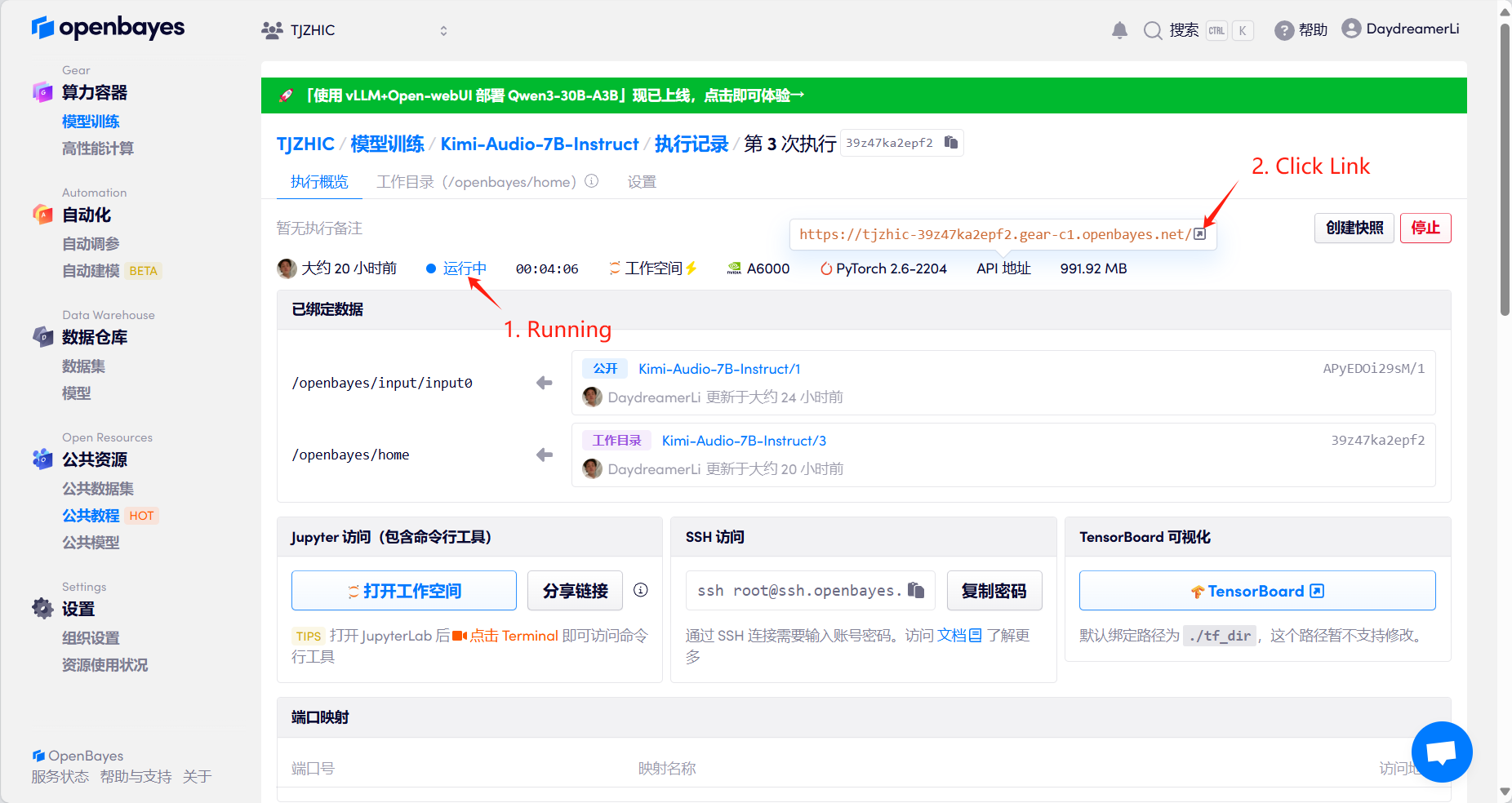
1. Démarrez le conteneur
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 3 à 5 minutes et actualiser la page.
2. Exemples d'utilisation
Directives d'utilisation
Lorsque vous utilisez le navigateur Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture.
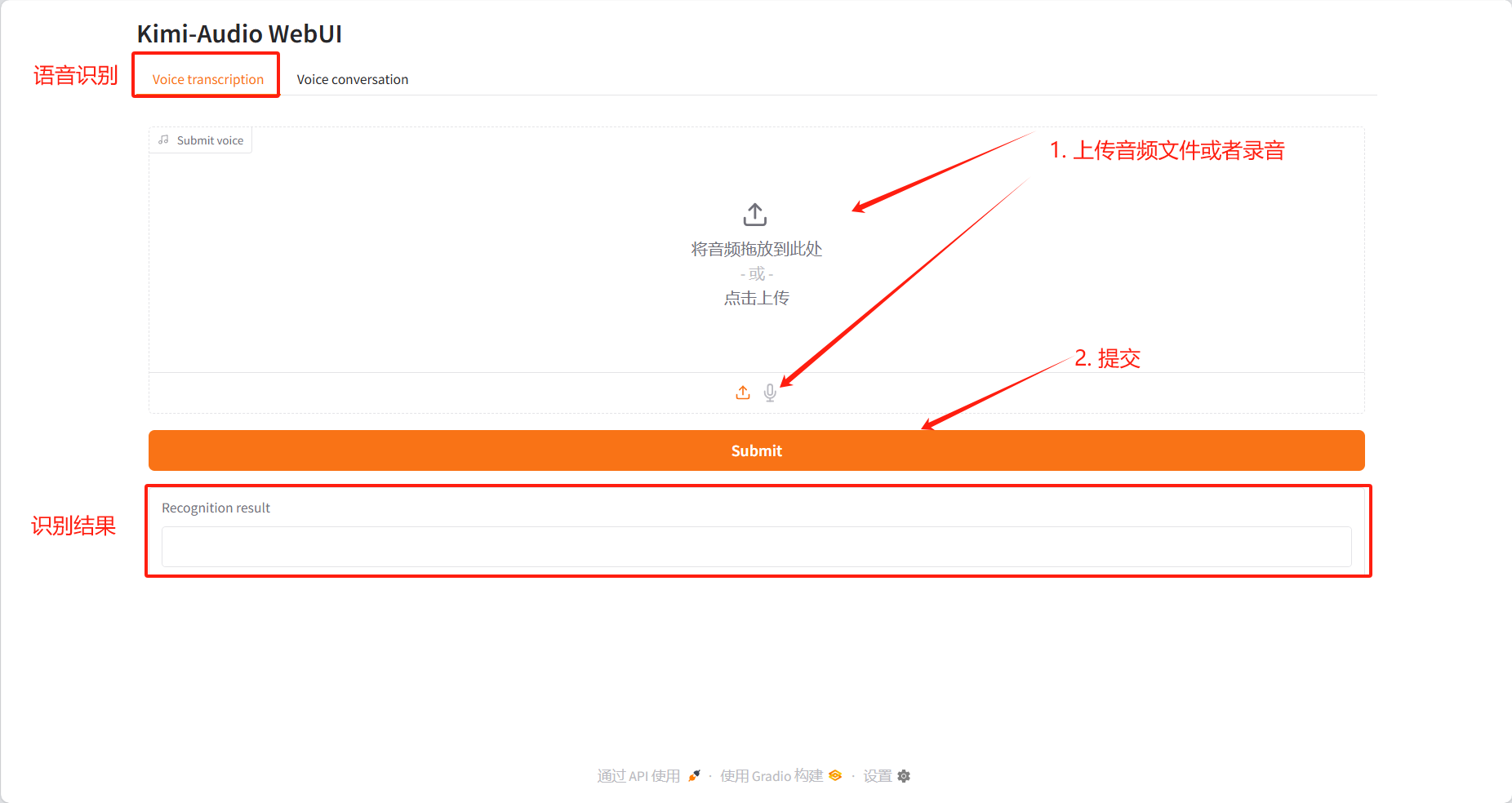
Ce tutoriel propose deux tests de module : Transcription vocale et Conversation vocale.
Les fonctions de chaque module sont les suivantes :
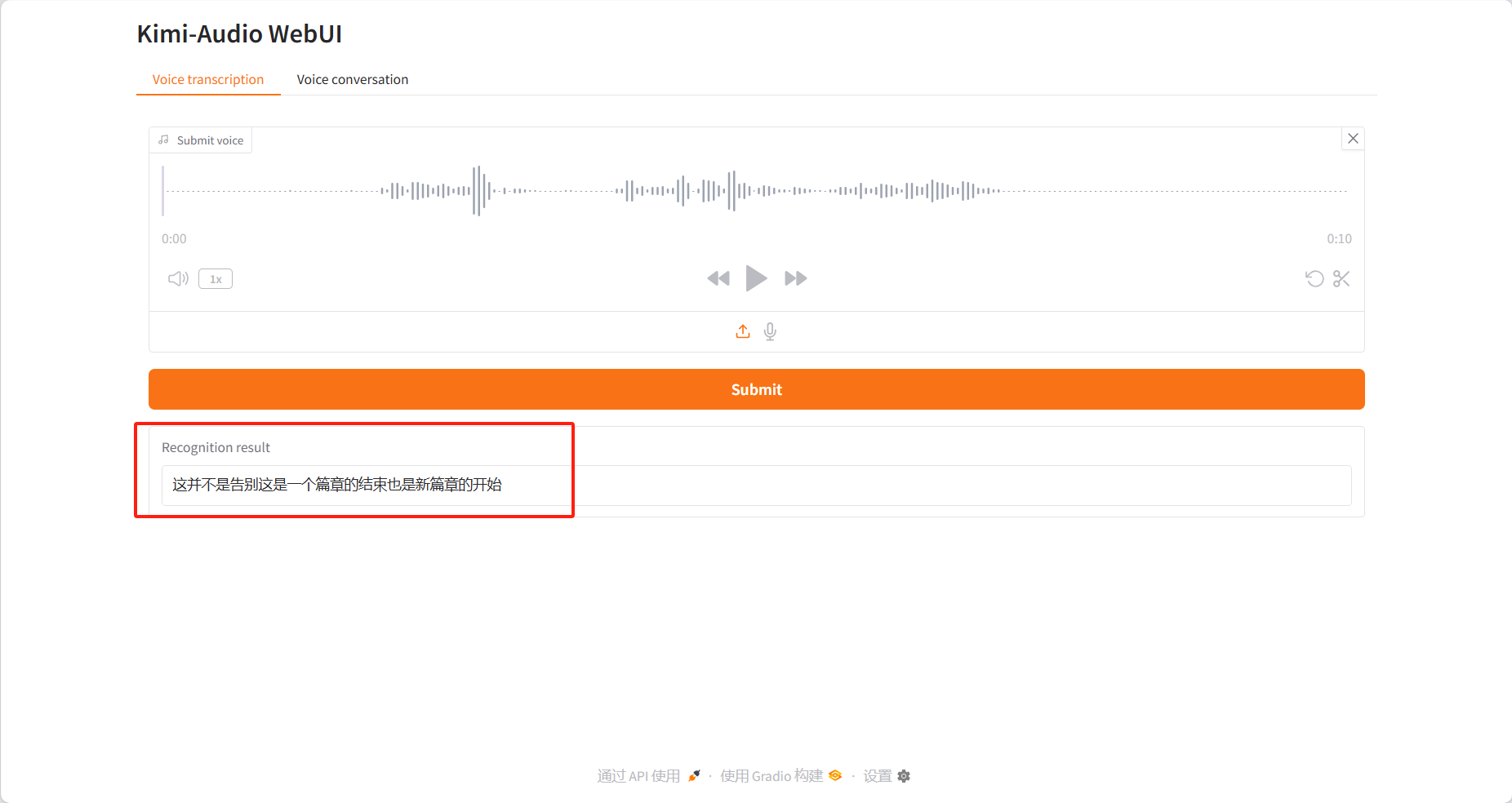
Transcription vocale
Résultats d'identification
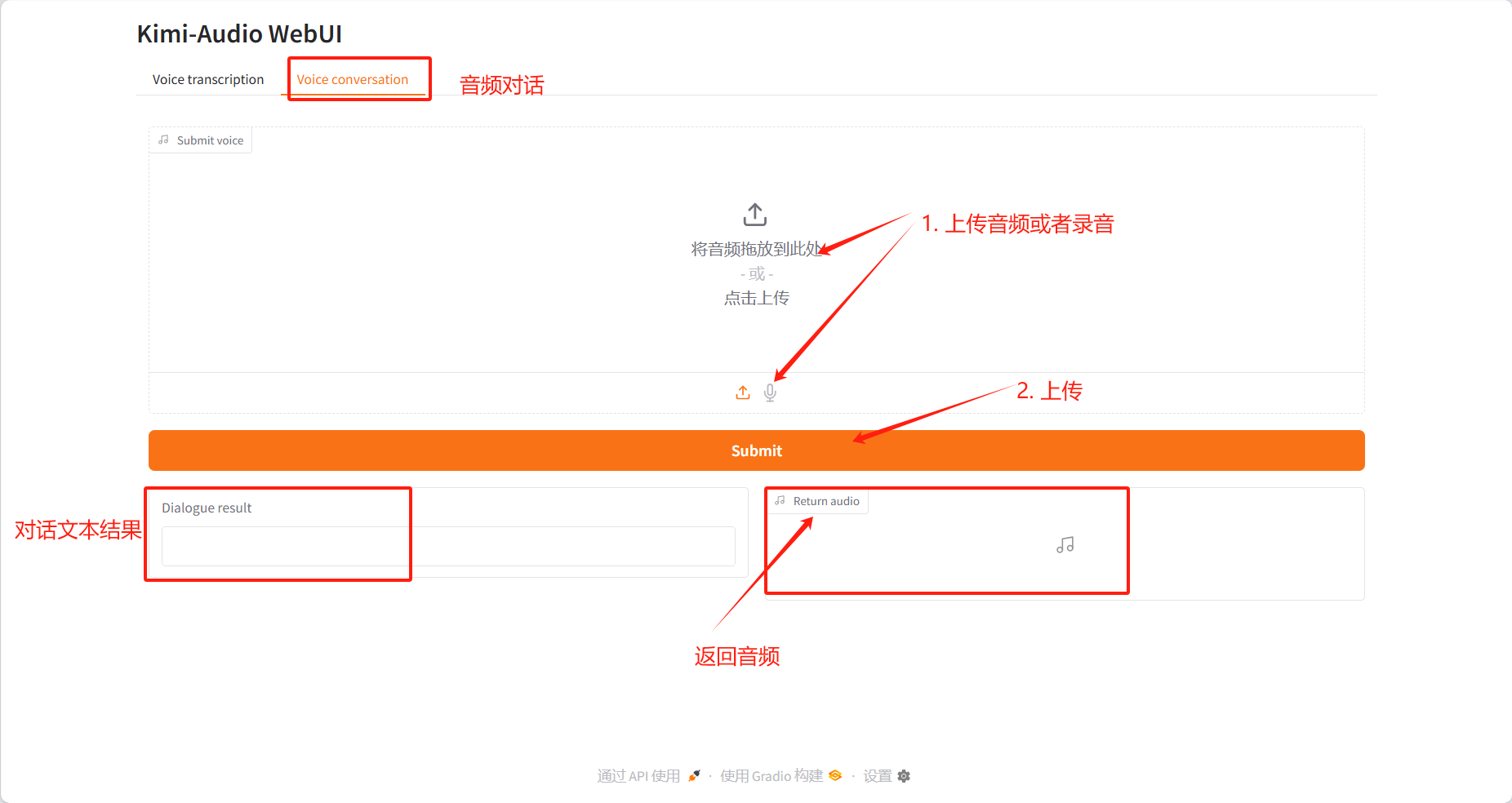
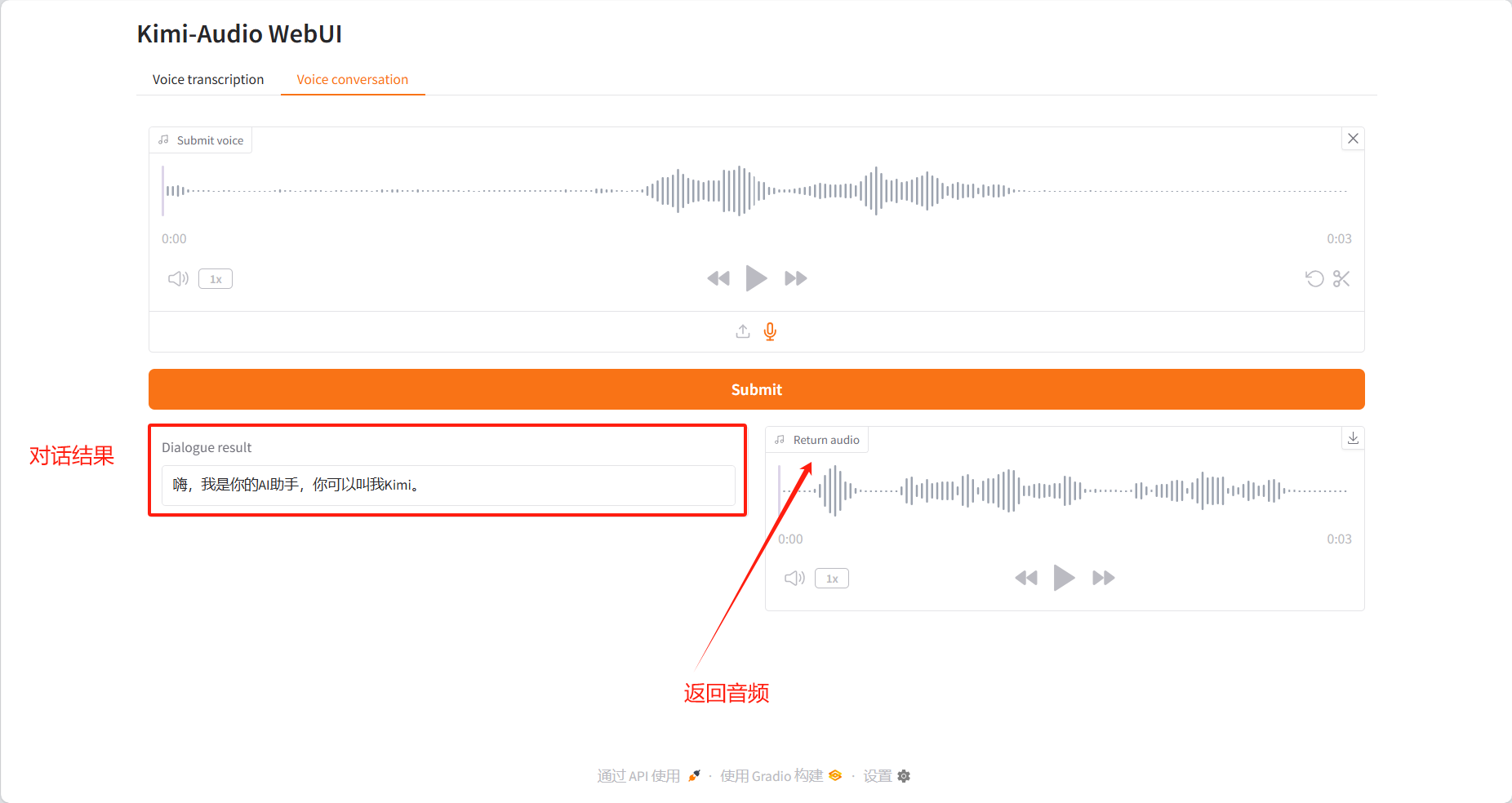
Conversation vocale
Résultats du dialogue
3. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓
Informations sur la citation
Merci à l'utilisateur Github SuperYang Déploiement de ce tutoriel. Les informations de citation pour ce projet sont les suivantes :
@misc{kimi_audio_2024,
title={Kimi-Audio Technical Report},
author={Kimi Team},
year={2024},
eprint={arXiv:placeholder},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kimiteam2025kimiaudiotechnicalreport,
title={Kimi-Audio Technical Report},
author={KimiTeam and Ding Ding and Zeqian Ju and Yichong Leng and Songxiang Liu and Tong Liu and Zeyu Shang and Kai Shen and Wei Song and Xu Tan and Heyi Tang and Zhengtao Wang and Chu Wei and Yifei Xin and Xinran Xu and Jianwei Yu and Yutao Zhang and Xinyu Zhou and Y. Charles and Jun Chen and Yanru Chen and Yulun Du and Weiran He and Zhenxing Hu and Guokun Lai and Qingcheng Li and Yangyang Liu and Weidong Sun and Jianzhou Wang and Yuzhi Wang and Yuefeng Wu and Yuxin Wu and Dongchao Yang and Hao Yang and Ying Yang and Zhilin Yang and Aoxiong Yin and Ruibin Yuan and Yutong Zhang and Zaida Zhou},
year={2025},
eprint={2504.18425},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2504.18425},
}
Ce notebook est fourni par des utilisateurs de la communauté et est destiné à des fins éducatives et informatives uniquement. Si un contenu enfreint des droits d'auteur, veuillez nous contacter à [email protected] pour un examen et un retrait rapides.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.
Les ressources informatiques utilisées dans ce tutoriel sont une seule carte A6000.
Kimi-Audio-7B-Instruct est un modèle de base audio open source publié par KimiTeam le 28 avril 2025. Ce modèle permet de gérer diverses tâches de traitement audio au sein d'un cadre unique et unifié. Parmi les articles de recherche associés, on peut citer… Rapport technique Kimi-Audio Les principales fonctions comprennent :
Capacités à usage général : gère une variété de tâches telles que la reconnaissance vocale automatique (ASR), les réponses aux questions audio (AQA), le sous-titrage audio automatique (AAC), la reconnaissance des émotions vocales (SER), la classification des événements/scènes sonores (SEC/ASC) et le dialogue vocal de bout en bout.
Performances de pointe : atteint les niveaux SOTA dans plusieurs benchmarks audio.
Pré-formation à grande échelle : Pré-formation sur plus de 13 millions d'heures de données audio diverses (parole, musique, son) et de données textuelles pour permettre un raisonnement audio puissant et une compréhension du langage.
Architecture innovante : en utilisant une entrée audio hybride (vecteur acoustique continu + balises sémantiques discrètes) et un noyau LLM avec des capacités de traitement parallèle, des balises texte et audio peuvent être générées simultanément.
Inférence efficace : démultiplexeur de streaming en morceaux avec correspondance de flux pour la génération audio à faible latence.
Open Source : publiez le code et les points de contrôle du modèle pour la pré-formation et le réglage fin des instructions, et publiez une boîte à outils d'évaluation complète pour promouvoir la recherche et le développement communautaires.
2. Étapes de l'opération
1. Démarrez le conteneur
Si « Bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 3 à 5 minutes et actualiser la page.
2. Exemples d'utilisation
Directives d'utilisation
Lorsque vous utilisez le navigateur Safari, l'audio peut ne pas être lu directement et doit être téléchargé avant la lecture.
Ce tutoriel propose deux tests de module : Transcription vocale et Conversation vocale.
Les fonctions de chaque module sont les suivantes :
Transcription vocale
Résultats d'identification
Conversation vocale
Résultats du dialogue
3. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓
Informations sur la citation
Merci à l'utilisateur Github SuperYang Déploiement de ce tutoriel. Les informations de citation pour ce projet sont les suivantes :
@misc{kimi_audio_2024,
title={Kimi-Audio Technical Report},
author={Kimi Team},
year={2024},
eprint={arXiv:placeholder},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kimiteam2025kimiaudiotechnicalreport,
title={Kimi-Audio Technical Report},
author={KimiTeam and Ding Ding and Zeqian Ju and Yichong Leng and Songxiang Liu and Tong Liu and Zeyu Shang and Kai Shen and Wei Song and Xu Tan and Heyi Tang and Zhengtao Wang and Chu Wei and Yifei Xin and Xinran Xu and Jianwei Yu and Yutao Zhang and Xinyu Zhou and Y. Charles and Jun Chen and Yanru Chen and Yulun Du and Weiran He and Zhenxing Hu and Guokun Lai and Qingcheng Li and Yangyang Liu and Weidong Sun and Jianzhou Wang and Yuzhi Wang and Yuefeng Wu and Yuxin Wu and Dongchao Yang and Hao Yang and Ying Yang and Zhilin Yang and Aoxiong Yin and Ruibin Yuan and Yutong Zhang and Zaida Zhou},
year={2025},
eprint={2504.18425},
archivePrefix={arXiv},
primaryClass={eess.AS},
url={https://arxiv.org/abs/2504.18425},
}
Ce notebook est fourni par des utilisateurs de la communauté et est destiné à des fins éducatives et informatives uniquement. Si un contenu enfreint des droits d'auteur, veuillez nous contacter à [email protected] pour un examen et un retrait rapides.
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.