Command Palette
Search for a command to run...
Déploiement En Un Clic Qwen2.5-VL-32B-Instruct-AWQ

1. Introduction au tutoriel
Qwen2.5-VL-32B-Instruct est un grand modèle multimodal open source par l'équipe Alibaba Tongyi Qianwen le 24 mars 2025 et publié sous le protocole Apache 2.0. Basé sur la série Qwen2.5-VL, ce modèle est optimisé grâce à la technologie d'apprentissage par renforcement et réalise une percée dans les capacités multimodales avec une échelle de paramètres de 32B.
🚀 Mise à niveau choquante du Qwen2.5-VL-32B ! Une IA visuelle plus puissante, un assistant multimodal plus intelligent ! 🌟
🔥 Mises à niveau des fonctionnalités principales
- Analyse visuelle à granularité fine : dans les domaines professionnels tels que l'analyse d'images médicales et la reconnaissance de dessins techniques, le modèle démontre des capacités de capture de contenu au niveau des pixels et prend en charge le raisonnement d'association multi-images et l'analyse des dimensions spatio-temporelles.
- Optimisation du style de sortie : le contenu de sortie du modèle est plus proche des habitudes d'expression humaine en termes de spécifications de format et de détails d'information, et peut générer des solutions avec une structure claire et une logique rigoureuse, en particulier dans des scénarios complexes.
- Avancée en matière de raisonnement mathématique : pour les problèmes mathématiques complexes, notamment les équations à plusieurs variables et les preuves géométriques, le modèle améliore la précision de la résolution des problèmes au niveau de pointe du secteur grâce à l'optimisation des algorithmes.
Ce tutoriel utilise Qwen2.5-VL-32B-AWQ comme démonstration et les ressources de calcul sont A6000.
2. Étapes de l'opération
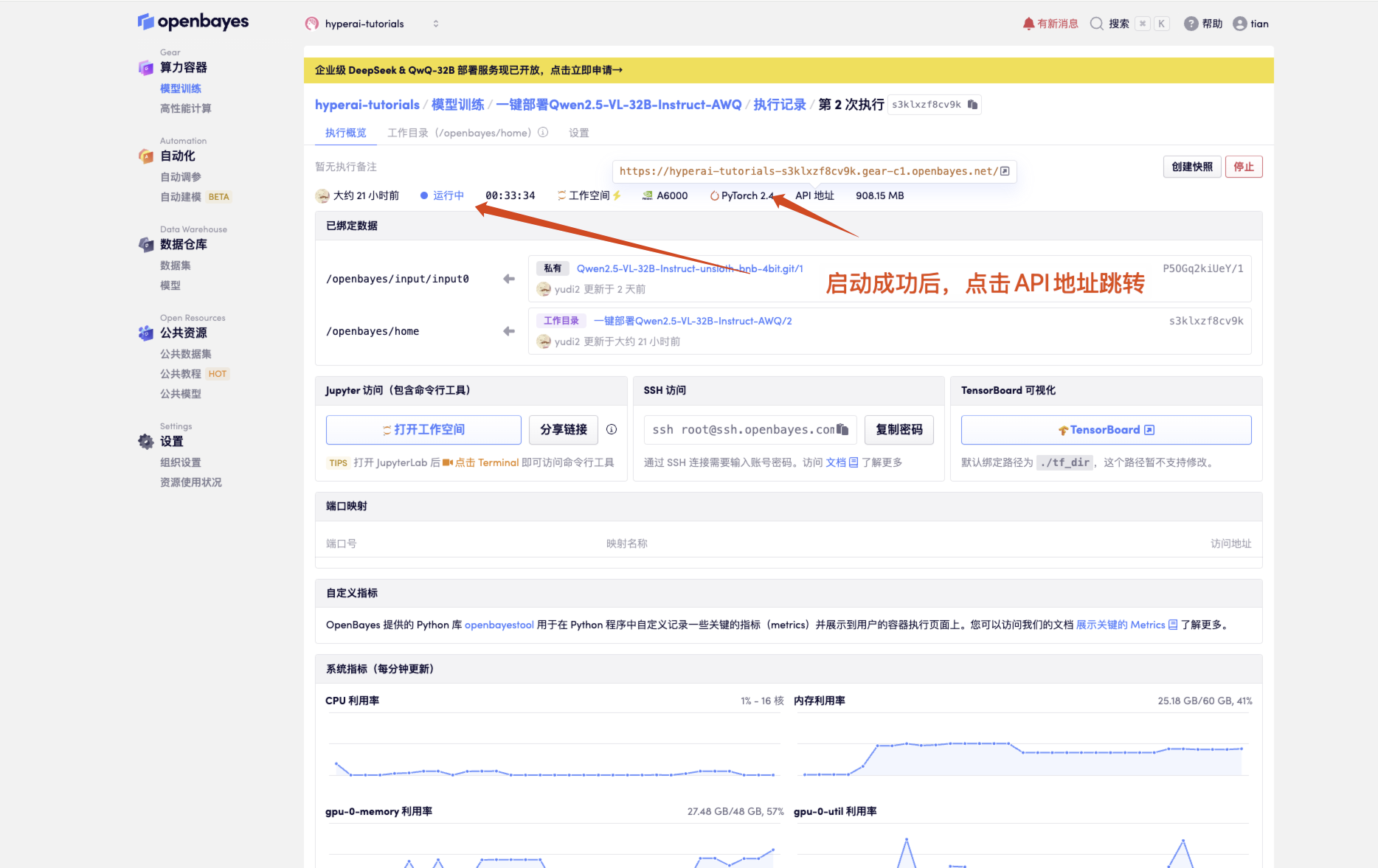
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
Si « bad Gateway » s'affiche, cela signifie que le modèle est en cours d'initialisation. Étant donné que le modèle est grand, veuillez patienter environ 1 à 2 minutes et actualiser la page.
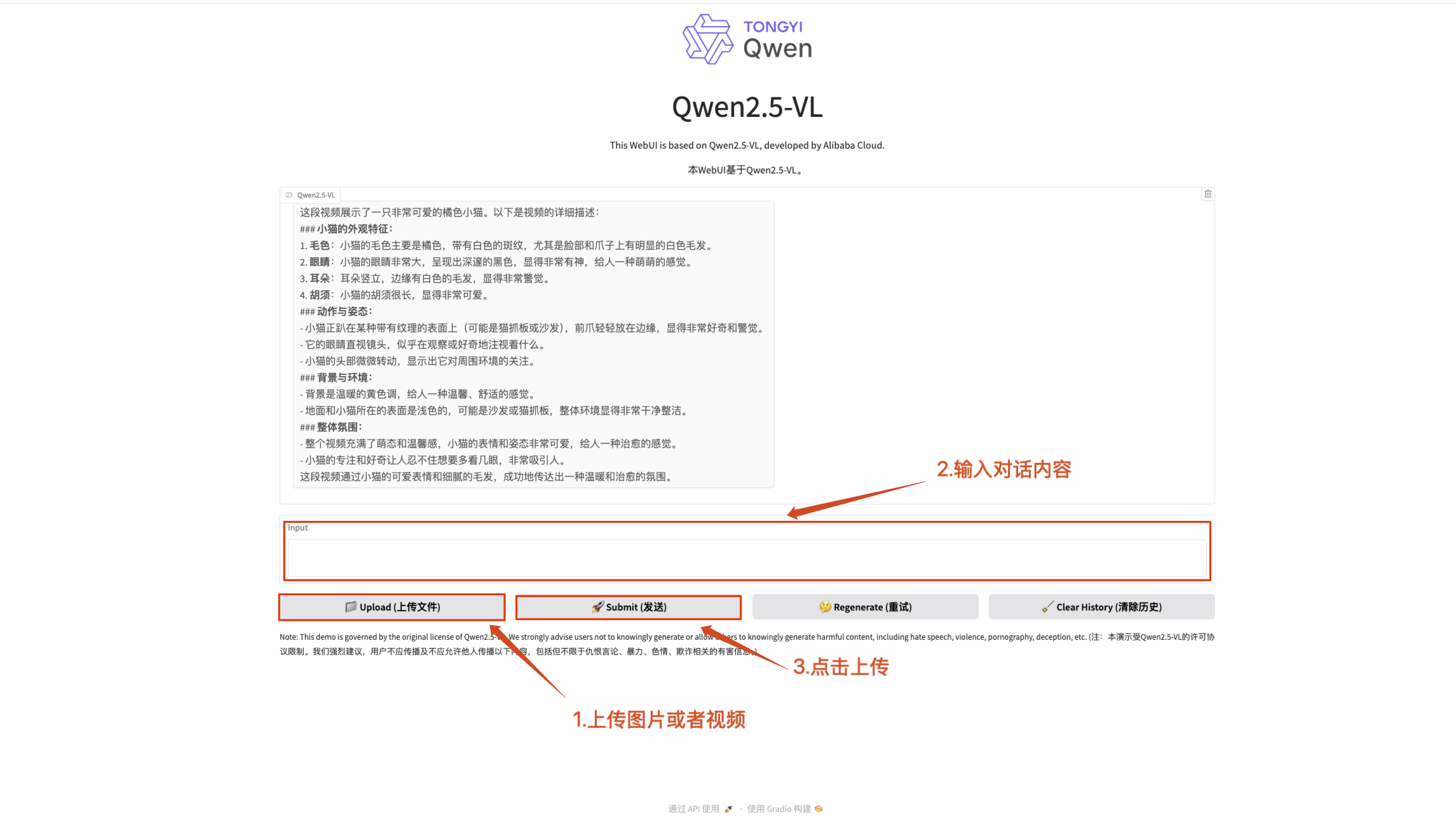
2. Après être entré sur la page Web, vous pouvez démarrer une conversation avec le modèle
Prend actuellement en charge la saisie de texte, la compréhension des images téléchargées, la compréhension des vidéos téléchargées (en raison des limitations de la mémoire vidéo, ne prend en charge que la saisie vidéo dans les 5 secondes, sinon une erreur sera signalée)
Échange et discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓ 
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.