Command Palette
Search for a command to run...
Déploiement En Un Clic Du Modèle SmolLM3-3B
Date
URL du document
Licence
Apache 2.0
GitHub
1. Introduction au tutoriel

Le SmolLM3-3B a été mis à disposition en open source et publié en juillet 2025 par l'équipe Hugging Face TB (Transformer Big), se positionnant comme la limite des performances en périphérie de réseau. Parmi les articles de recherche associés, on peut citer… SmolLM3 : petit, multilingue, raisonneur à contexte long Il s'agit d'un modèle de langage open source révolutionnaire doté de 3 milliards de paramètres, conçu pour dépasser les limites de performance des petits modèles dans un format compact de 3 milliards de paramètres.
Ce tutoriel utilise une carte graphique RTX 5090 (32 Go) et un environnement d'installation PyTorch 2.8 + CUDA 12.8. Le temps de chargement estimé pour l'application Gradio est de 2 à 3 minutes.
2. Exemples de projets
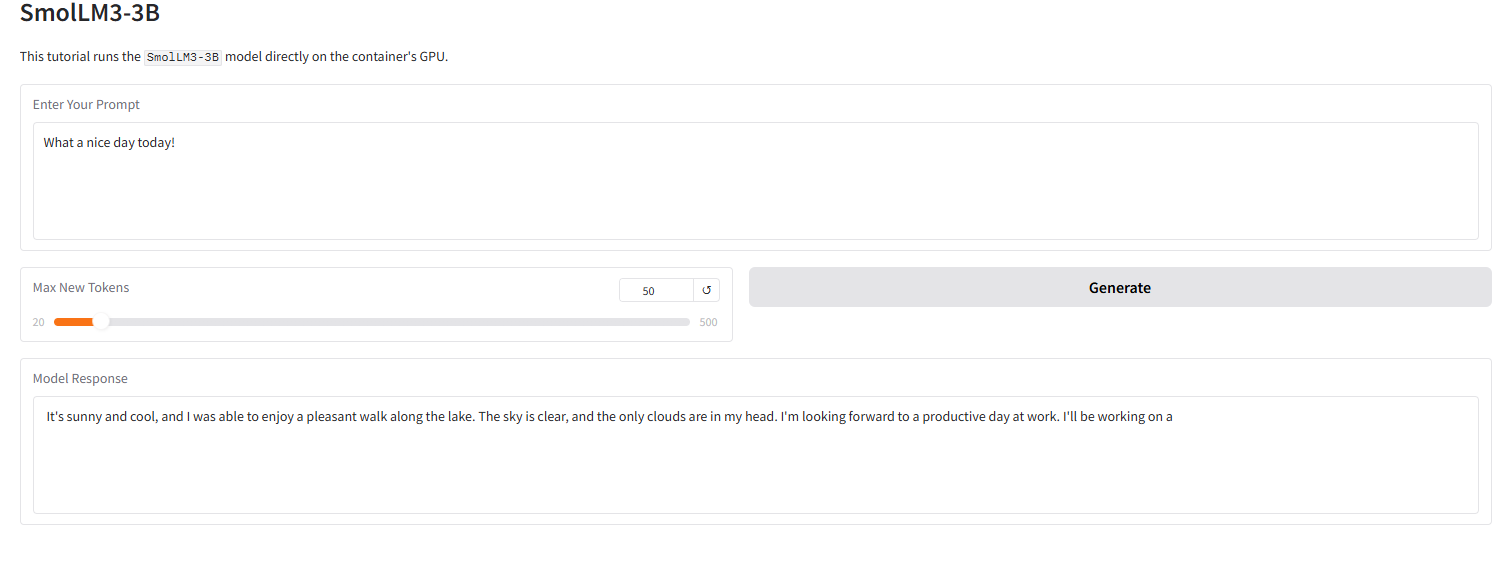
L'image ci-dessous illustre l'effet de l'interface Grado dans ce tutoriel. Nous avons saisi un mot-clé, et le modèle a correctement fourni une réponse quantifiée sur 4 bits.
3. Étapes de l'opération
Cette section comprend les instructions pour le démarrage en un clic, la structure du répertoire de code et les questions fréquemment posées.
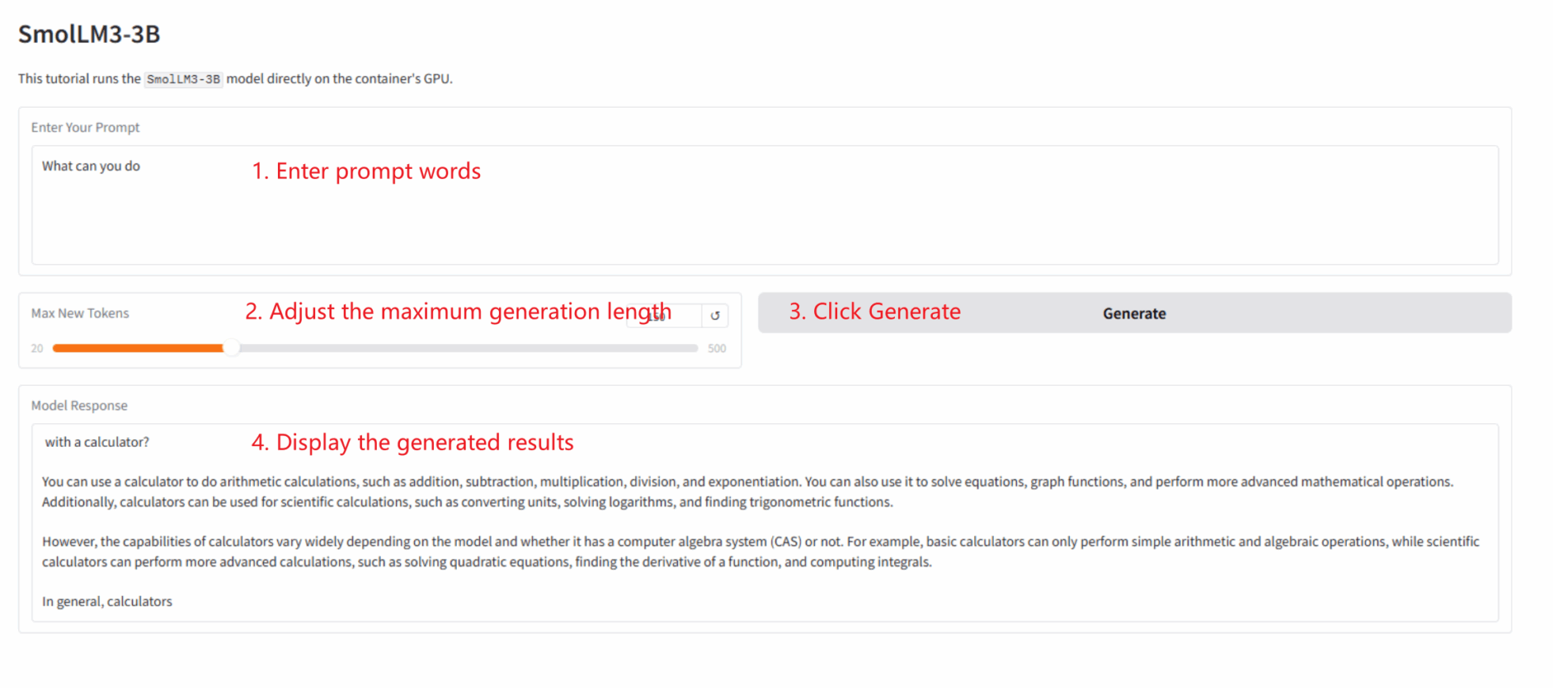
Ce tutoriel explique comment déployer une application Gradio en un seul clic. Aucun code n'est requis ; il suffit de suivre ces étapes :
1. Tutoriel de clonage : Cliquez sur « Cloner » en haut à droite de cette page pour créer votre conteneur personnel.
2. Démarrez le conteneur et attendez : Le système démarrera automatiquement le conteneur pour vous (recommandé). RTX 5090). dependencies.sh Le script s'exécutera automatiquement en arrière-plan, chargeant le modèle de quantification 4 bits.Ce processus prend environ 2 à 3 minutes.
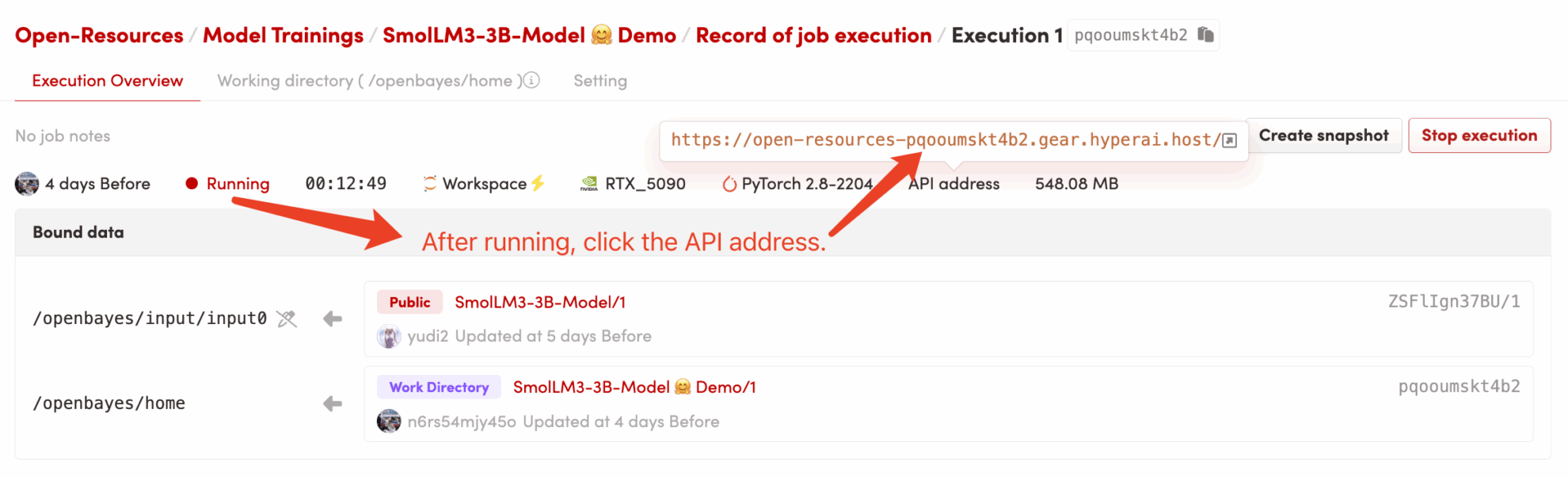
3. Accédez à l'application : Une fois que l'état du conteneur passe à « En cours d'exécution », cliquez sur « Adresse API » sur la page de détails du conteneur pour ouvrir l'interface Grado.
structure du répertoire de code
/openbayes/home |-- app.py \# Gradio 应用的启动脚本 |-- requirements.txt \# 锁定的 Python 依赖包 (已预装) |-- dependencies.sh \# 平台自动化执行脚本 (仅启动 app) |-- README\_cn.md \# 本教程说明文档 (中文) \`-- README\_en.md \# 本教程说明文档 (英文) /openbayes/input/input0 # 只读绑定的 SmolLM3-3B 模型文件
Questions fréquemment posées
- Q : Après avoir cliqué sur « Adresse API », la page ne se charge pas ou affiche « 502 » ? A : C'est parce que le modèle est en cours de chargement.
SmolLM3-3BIl s'agit d'un modèle volumineux ; même la version quantifiée 4 bits prend 2 à 3 minutes à se charger complètement sur le GPU. Veuillez patienter quelques minutes avant d'actualiser la page. - Q : Le journal affiche
OSError: Cannot find empty port 8080? R : Cela est dû au fait que vous (ou votre système) avez tenté de démarrer l'application à plusieurs reprises, ce qui a entraîné l'occupation du port 8080 par un processus zombie. Il vous suffit de l'exécuter dans un terminal de conteneur.pkill -f "python /openbayes/home/app.py"Nettoyez les anciens processus puis relancez-les.bash /openbayes/home/dependencies.shC'est tout.
Informations sur la citation
@misc{bakouch2025smollm3,
title={{SmolLM3: smol, multilingual, long-context reasoner}},
author={Bakouch, Elie and Ben Allal, Loubna and Lozhkov, Anton and Tazi, Nouamane and Tunstall, Lewis and Patiño, Carlos Miguel and Beeching, Edward and Roucher, Aymeric and Reedi, Aksel Joonas and Gallouédec, Quentin and Rasul, Kashif and Habib, Nathan and Fourrier, Clémentine and Kydlicek, Hynek and Penedo, Guilherme and Larcher, Hugo and Morlon, Mathieu and Srivastav, Vaibhav and Lochner, Joshua and Nguyen, Xuan-Son and Raffel, Colin and von Werra, Leandro and Wolf, Thomas},
year={2025},
howpublished={\url{[https://huggingface.co/blog/smollm3](https://huggingface.co/blog/smollm3)}}
}Vue d’ensemble de Notebook
Niveau
Rubrique
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.