HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA

SciReasoner : Établir les fondements du raisonnement scientifique à travers les disciplines

MMR1 : Amélioration du raisonnement multimodal grâce à un échantillonnage conscient de la variance et à des ressources ouvertes

























SciReasoner : Établir les fondements du raisonnement scientifique à travers les disciplines
MMR1 : Amélioration du raisonnement multimodal grâce à un échantillonnage conscient de la variance et à des ressources ouvertes
VCRL : apprentissage par renforcement avec curriculum basé sur la variance pour les grands modèles linguistiques
MultiEdit : Progresser dans l'édition d'images basée sur les instructions sur des tâches diverses et exigeantes
BRISC : Jeu de données annoté pour la segmentation et la classification des tumeurs cérébrales avec Swin-HAFNet
EmoBench-M : Évaluation de l'intelligence émotionnelle des grands modèles linguistiques multimodaux
FDABench : un benchmark pour les agents de données sur les requêtes analytiques sur des données hétérogènes
Peindre plus facile que penser : les modèles texte-image peuvent-ils préparer la scène, mais pas diriger le spectacle ?
UniVerse-1 : Génération audiovisuelle unifiée par assemblage d'experts
Quelle est la qualité des modèles fondamentaux dans le raisonnement incarné étape par étape ?
Rapport technique SpikingBrain : Modèles grands inspirés du cerveau à déclenchement d'impulsions
SAGE : Un benchmark réaliste pour la compréhension sémantique
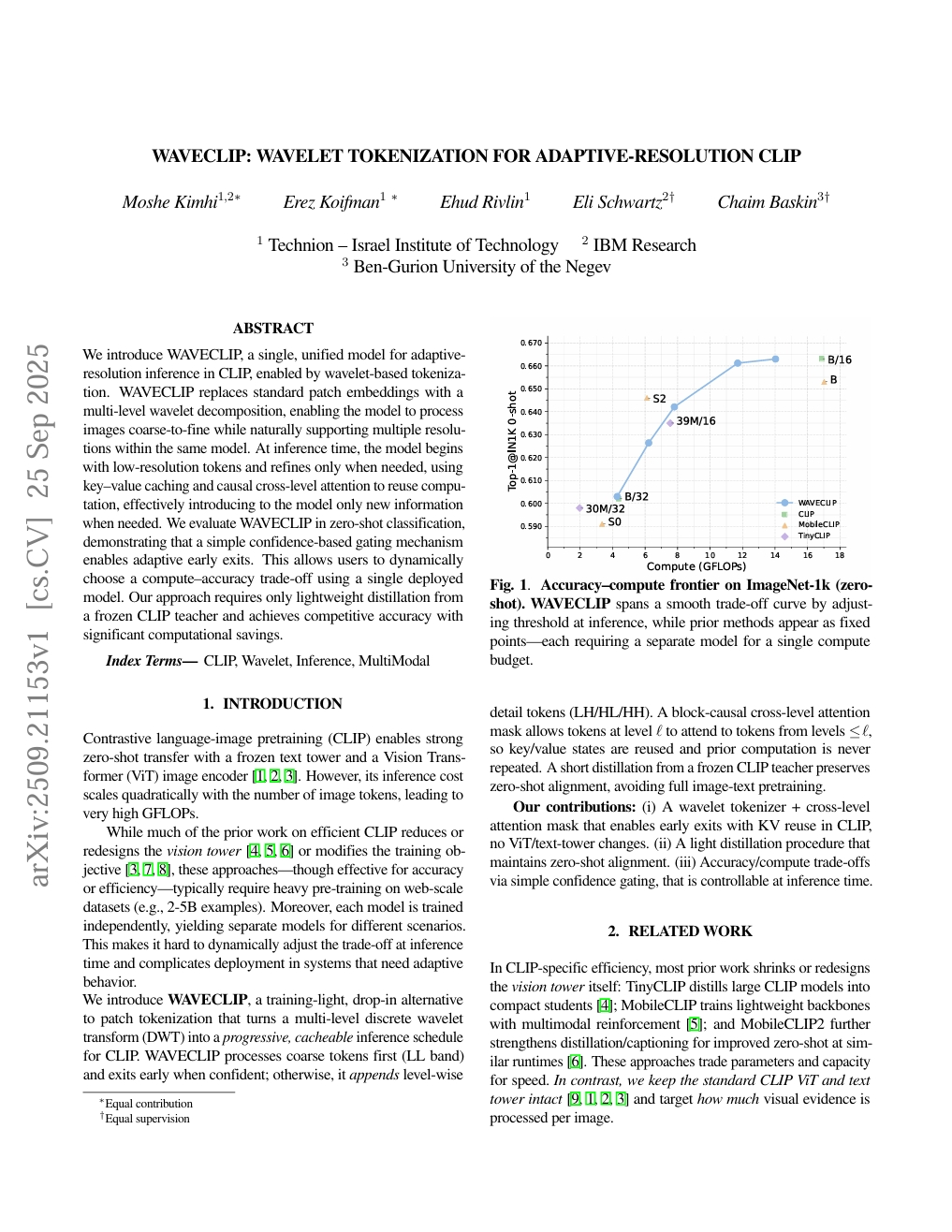
WAVECLIP : Tokenisation par ondelettes pour CLIP à résolution adaptative
EmbeddingGemma : Des représentations textuelles puissantes et légères
Avancement de la compréhension du discours dans les modèles linguistiques conscients du discours grâce au GRPO
À quel point les VLM sont-ils éloignés de l'intelligence visuo-spatiale ? Une perspective pilotée par un benchmark
SIM-CoT : Chaîne de raisonnement implicite supervisée
SWE-QA : Les modèles de langage peuvent-ils répondre à des questions sur le code au niveau du dépôt ?
Les modèles vidéo sont des apprenants et raisonneurs zéro-shot
Une agence GPT N-Plus-1 pour la résolution critique de problèmes d'analyse en génie mécanique
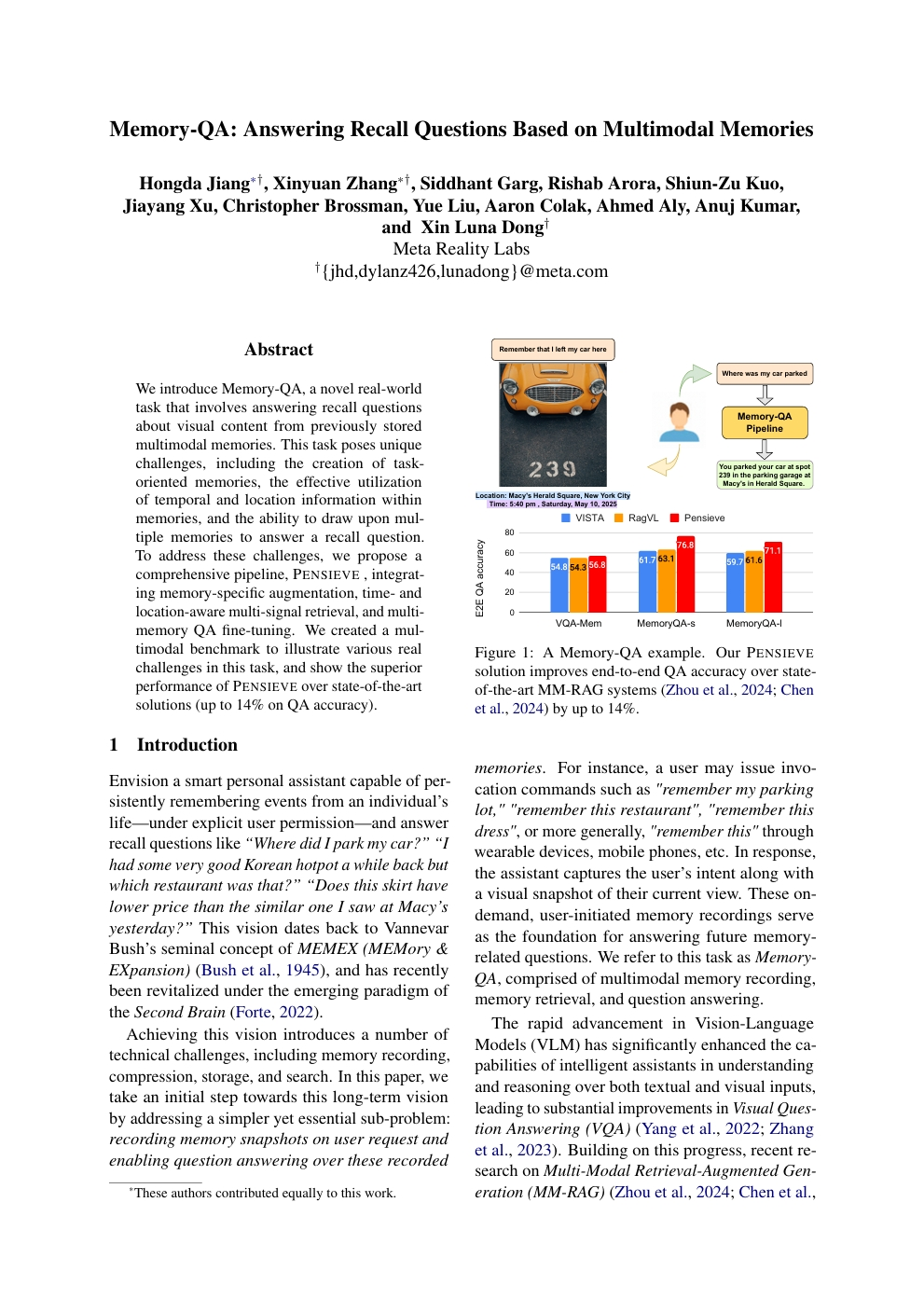
Memory-QA : réponse à des questions de rappel basée sur des mémoires multimodales
MAPO : Optimisation politique à avantages mixtes
Hyper-Bagel : un cadre unifié d'accélération pour la compréhension et la génération multimodales
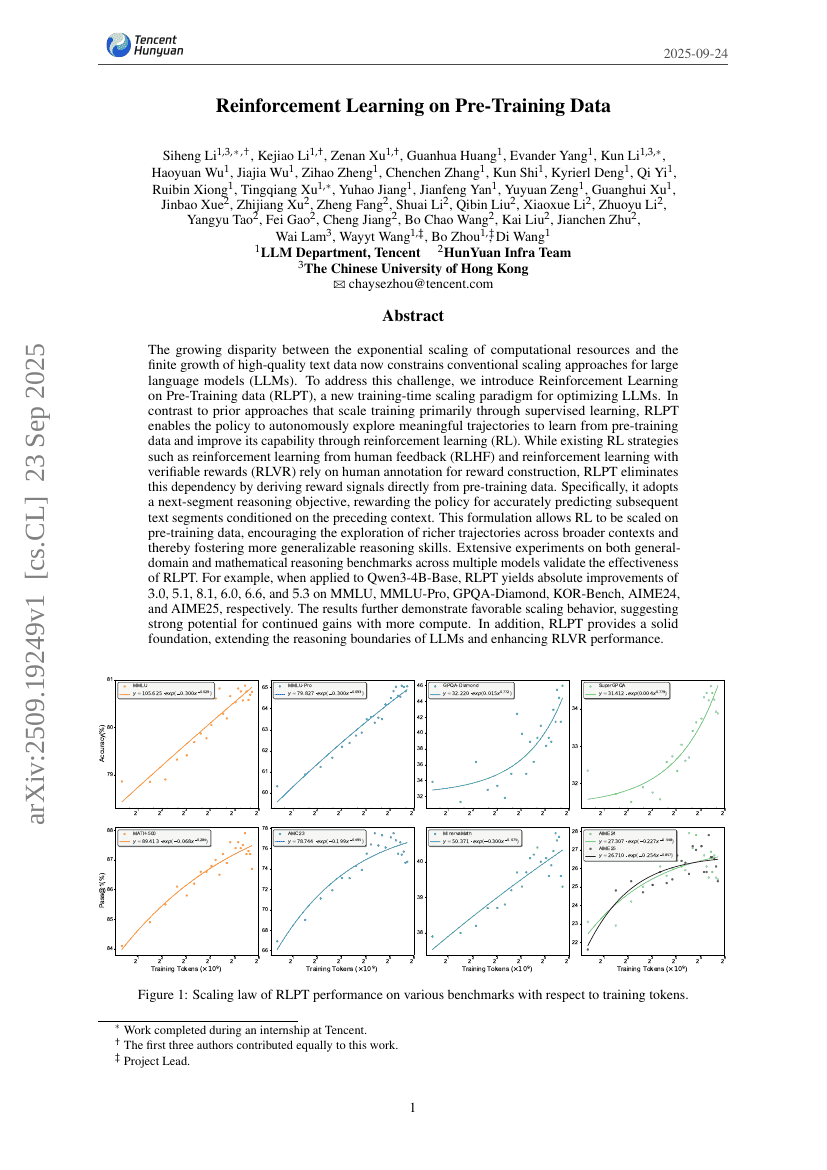
Apprentissage par renforcement sur les données d'entraînement préalable
Avez-vous besoin d’états proprioceptifs dans les politiques visuomotrices ?
Baseer : un modèle vision-langage pour la reconnaissance optique de caractères de documents arabes vers Markdown
GenExam : un examen multidisciplinaire texte-à-image
Nav-R1 : Raisonnement et navigation dans des scènes incarnées
Les MoE sont plus puissantes que vous ne le pensez : l'échelle d'inférence hyper-parallèle avec RoE
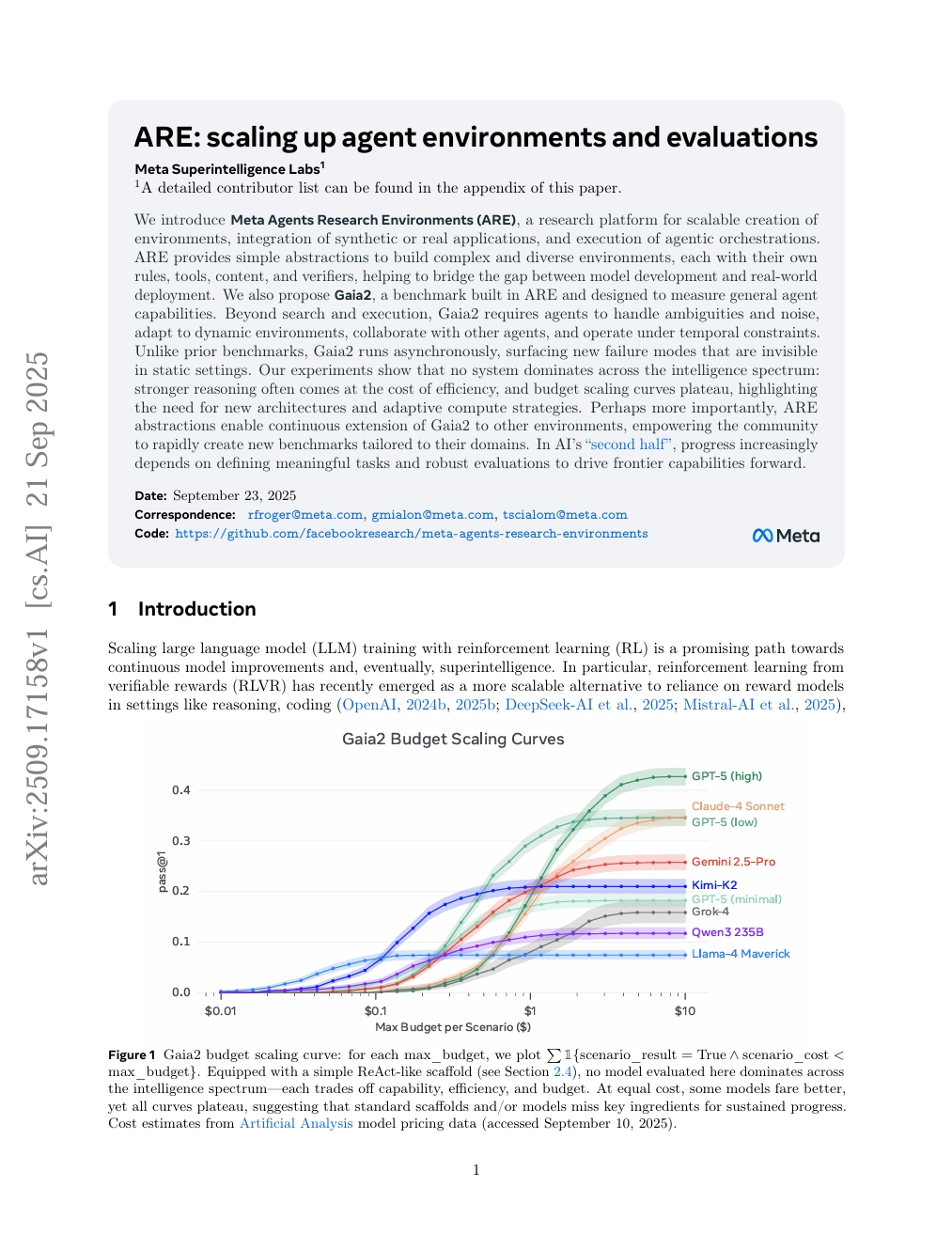
ARE : Agrandissement des environnements d'agents et des évaluations
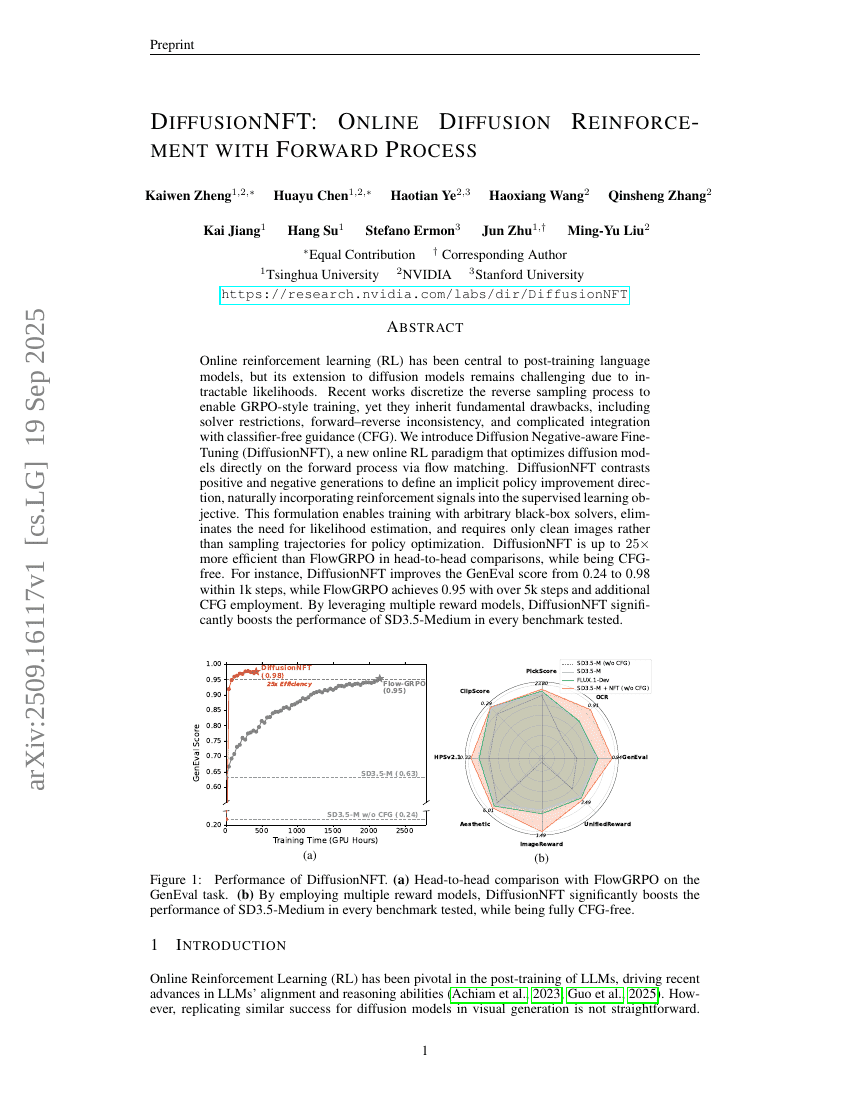
DiffusionNFT : Renforcement par diffusion en ligne avec processus avant
TempSamp-R1 : Échantillonnage temporel efficace avec une adaptation par renforcement pour les modèles linguistiques vidéo
VCRL : apprentissage par renforcement avec curriculum basé sur la variance pour les grands modèles linguistiques
MultiEdit : Progresser dans l'édition d'images basée sur les instructions sur des tâches diverses et exigeantes
BRISC : Jeu de données annoté pour la segmentation et la classification des tumeurs cérébrales avec Swin-HAFNet
EmoBench-M : Évaluation de l'intelligence émotionnelle des grands modèles linguistiques multimodaux
FDABench : un benchmark pour les agents de données sur les requêtes analytiques sur des données hétérogènes
Peindre plus facile que penser : les modèles texte-image peuvent-ils préparer la scène, mais pas diriger le spectacle ?
UniVerse-1 : Génération audiovisuelle unifiée par assemblage d'experts
Quelle est la qualité des modèles fondamentaux dans le raisonnement incarné étape par étape ?
Rapport technique SpikingBrain : Modèles grands inspirés du cerveau à déclenchement d'impulsions
SAGE : Un benchmark réaliste pour la compréhension sémantique
WAVECLIP : Tokenisation par ondelettes pour CLIP à résolution adaptative
EmbeddingGemma : Des représentations textuelles puissantes et légères
Avancement de la compréhension du discours dans les modèles linguistiques conscients du discours grâce au GRPO
À quel point les VLM sont-ils éloignés de l'intelligence visuo-spatiale ? Une perspective pilotée par un benchmark
SIM-CoT : Chaîne de raisonnement implicite supervisée
SWE-QA : Les modèles de langage peuvent-ils répondre à des questions sur le code au niveau du dépôt ?
Les modèles vidéo sont des apprenants et raisonneurs zéro-shot
Une agence GPT N-Plus-1 pour la résolution critique de problèmes d'analyse en génie mécanique
Memory-QA : réponse à des questions de rappel basée sur des mémoires multimodales
MAPO : Optimisation politique à avantages mixtes
Hyper-Bagel : un cadre unifié d'accélération pour la compréhension et la génération multimodales
Apprentissage par renforcement sur les données d'entraînement préalable
Avez-vous besoin d’états proprioceptifs dans les politiques visuomotrices ?
Baseer : un modèle vision-langage pour la reconnaissance optique de caractères de documents arabes vers Markdown
GenExam : un examen multidisciplinaire texte-à-image
Nav-R1 : Raisonnement et navigation dans des scènes incarnées
Les MoE sont plus puissantes que vous ne le pensez : l'échelle d'inférence hyper-parallèle avec RoE
ARE : Agrandissement des environnements d'agents et des évaluations
DiffusionNFT : Renforcement par diffusion en ligne avec processus avant
TempSamp-R1 : Échantillonnage temporel efficace avec une adaptation par renforcement pour les modèles linguistiques vidéo