HyperAI
Command Palette
Search for a command to run...
Papers
Articles de recherche en IA de pointe mis à jour quotidiennement pour vous aider à suivre les dernières tendances en IA
Voir le texte : De la tokenisation à la lecture visuelle
Injection de raisonnement directionnel pour le fine-tuning des MLLM

Les modèles de langage sont injectifs et par conséquent inversibles

























Voir le texte : De la tokenisation à la lecture visuelle
Injection de raisonnement directionnel pour le fine-tuning des MLLM
Les modèles de langage sont injectifs et par conséquent inversibles
Le Transformer libre
Prédiction du temps de traitement d'une unité de traitement quantique (QPU) par apprentissage automatique
Observation de l'interférence constructive au voisinage de l'ergodicité quantique
VideoAgentTrek : Pré-entraînement à l'utilisation de l'ordinateur à partir de vidéos non étiquetées
GigaBrain-0 : un modèle vision-langage-action alimenté par un monde modélisé
LoongRL : Apprentissage par renforcement pour un raisonnement avancé sur des contextes longs
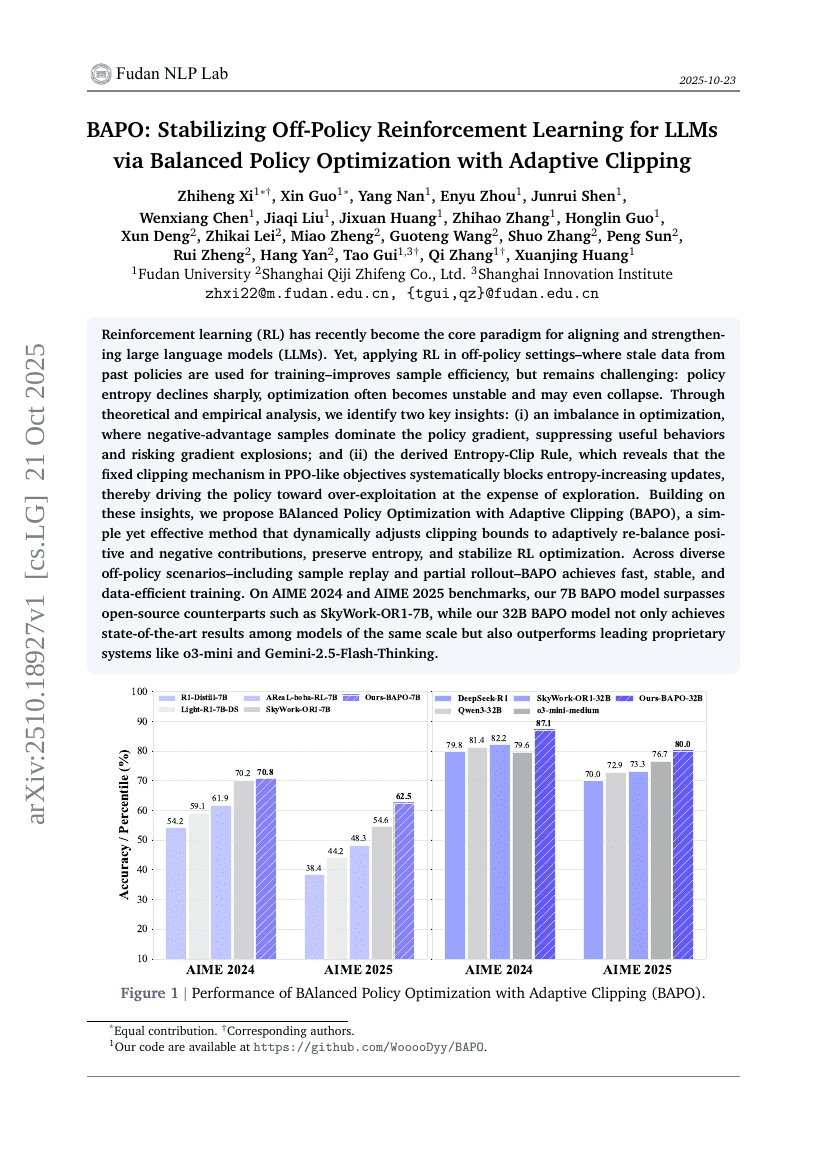
BAPO : Stabilisation de l'apprentissage par renforcement hors politique pour les modèles de langage grâce à l'optimisation de politique équilibrée avec découpage adaptatif
Chaque attention compte : une architecture hybride efficace pour le raisonnement à longue portée
Color Me Correctly : Rebrancher les espaces colorés perceptifs et les embeddings textuels pour une génération de diffusion améliorée
Raisonnement spatial avec des modèles vision-langage dans des scènes multi-vues en perspective subjective
LoFT : Une fine-tuning efficace en paramètres pour l'apprentissage semi-supervisé à longue queue dans des scénarios à monde ouvert
FLOWER : Démocratiser les politiques robotiques généralistes grâce à des politiques efficaces de flux vision-langage-action
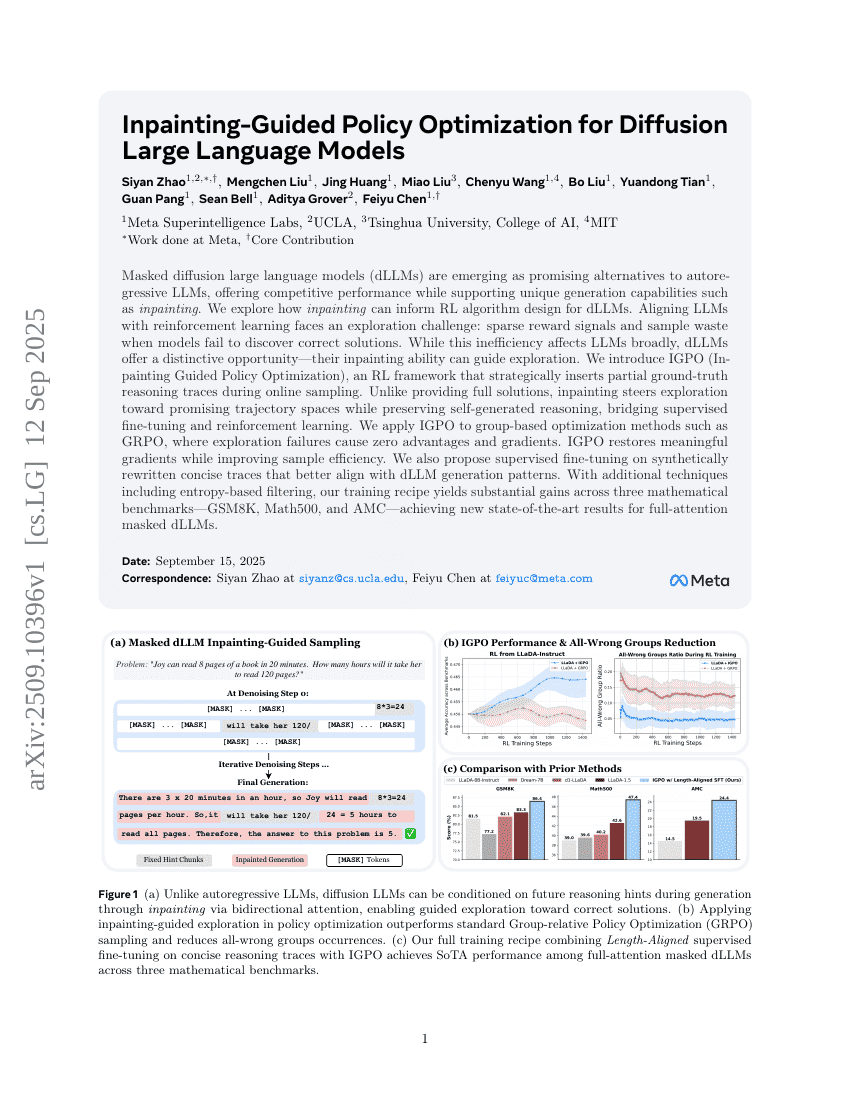
Optimisation de politique guidée par le remplissage pour les modèles de langage à grande échelle à diffusion
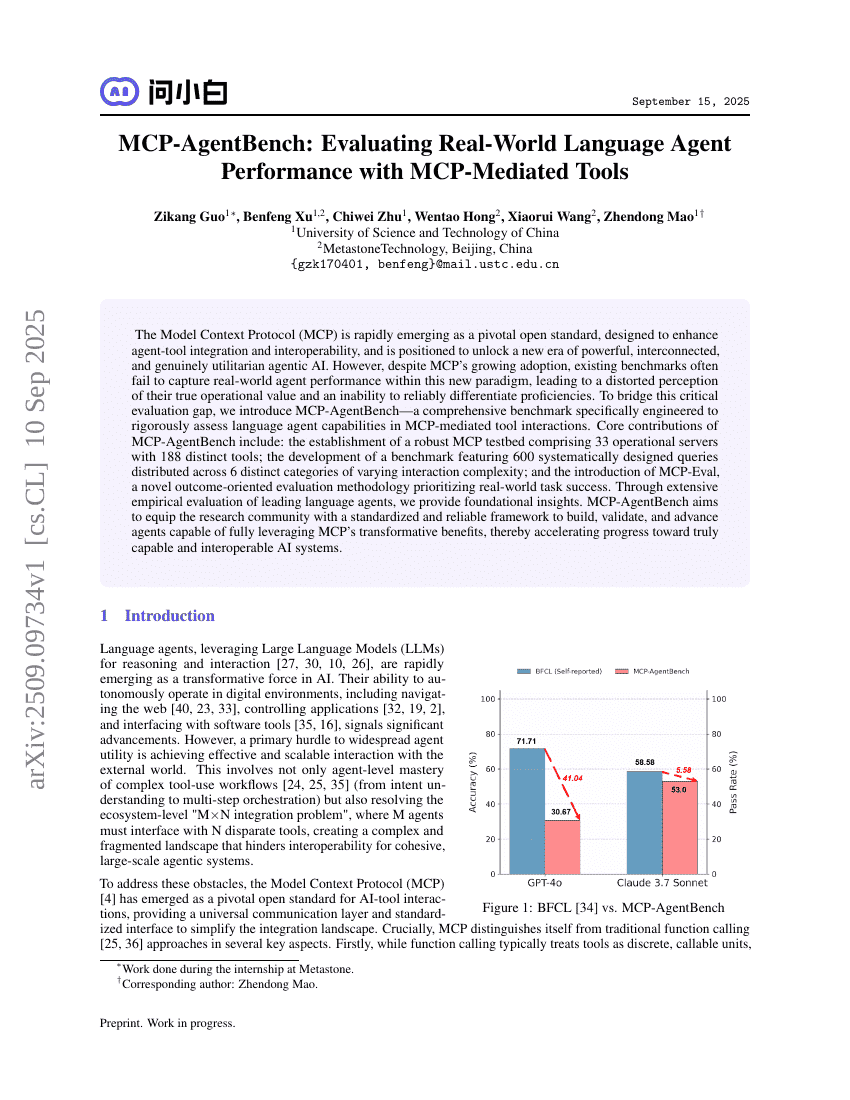
MCP-AgentBench : Évaluation des performances des agents linguistiques dans le monde réel à l'aide d'outils pilotés par MCP
Une revue des méthodes de mémoire cache dans les modèles de diffusion : vers une génération multi-modale efficace
Repenser le modèle du monde de conduite comme générateur de données synthétiques pour les tâches de perception
Autofocus à variation spatiale
Quand agréger : identification de points au niveau des jetons pour une agrégation de LLM stable et rapide
Vers une recherche mixte de modalités pour une génération augmentée par la recherche universelle
FineVision : Les données ouvertes, c'est tout ce dont vous avez besoin
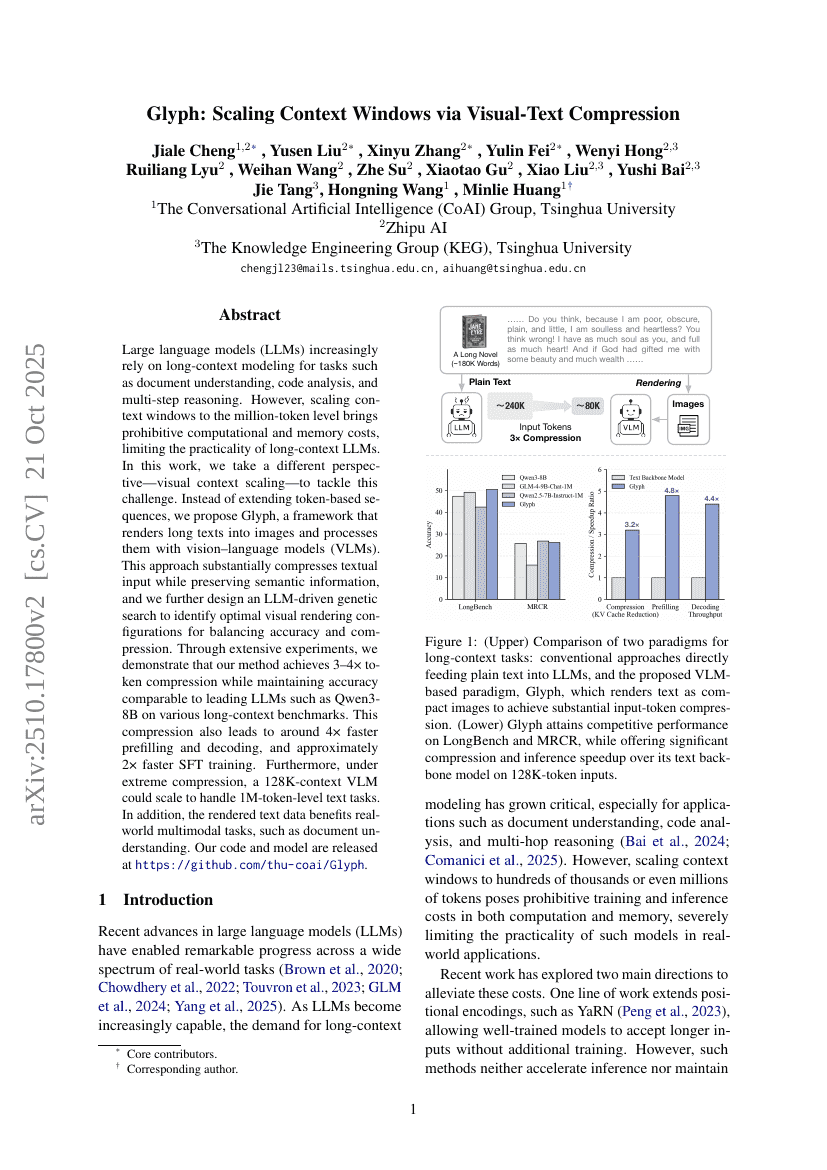
Glyph : Augmenter la taille des fenêtres contextuelles par compression visuelle et textuelle
PICABench : Où en sommes-nous en matière de modification d'images physiquement réaliste ?
DeepAnalyze : modèles de langage à grande échelle agents pour la science des données autonome
Attention auto-associative pour l'apprentissage des opérateurs dans la simulation thermique 3D-IC
Terre IA : Déverrouiller des informations géospatiales grâce aux modèles fondamentaux et au raisonnement multimodal
Repenser les écarts interlinguistiques du point de vue statistique
Libérer le raisonnement scientifique pour la génération de protocoles d'expérimentation biologique à l'aide d'un mécanisme de récompense structuré basé sur des composants
Skyfall-GS : Synthèse de scènes urbaines 3D immersives à partir d'images satellitaires
Désalignement émergent par apprentissage in-situ : des exemples in-situ restreints peuvent entraîner des LLM largement désalignés
Le Transformer libre
Prédiction du temps de traitement d'une unité de traitement quantique (QPU) par apprentissage automatique
Observation de l'interférence constructive au voisinage de l'ergodicité quantique
VideoAgentTrek : Pré-entraînement à l'utilisation de l'ordinateur à partir de vidéos non étiquetées
GigaBrain-0 : un modèle vision-langage-action alimenté par un monde modélisé
LoongRL : Apprentissage par renforcement pour un raisonnement avancé sur des contextes longs
BAPO : Stabilisation de l'apprentissage par renforcement hors politique pour les modèles de langage grâce à l'optimisation de politique équilibrée avec découpage adaptatif
Chaque attention compte : une architecture hybride efficace pour le raisonnement à longue portée
Color Me Correctly : Rebrancher les espaces colorés perceptifs et les embeddings textuels pour une génération de diffusion améliorée
Raisonnement spatial avec des modèles vision-langage dans des scènes multi-vues en perspective subjective
LoFT : Une fine-tuning efficace en paramètres pour l'apprentissage semi-supervisé à longue queue dans des scénarios à monde ouvert
FLOWER : Démocratiser les politiques robotiques généralistes grâce à des politiques efficaces de flux vision-langage-action
Optimisation de politique guidée par le remplissage pour les modèles de langage à grande échelle à diffusion
MCP-AgentBench : Évaluation des performances des agents linguistiques dans le monde réel à l'aide d'outils pilotés par MCP
Une revue des méthodes de mémoire cache dans les modèles de diffusion : vers une génération multi-modale efficace
Repenser le modèle du monde de conduite comme générateur de données synthétiques pour les tâches de perception
Autofocus à variation spatiale
Quand agréger : identification de points au niveau des jetons pour une agrégation de LLM stable et rapide
Vers une recherche mixte de modalités pour une génération augmentée par la recherche universelle
FineVision : Les données ouvertes, c'est tout ce dont vous avez besoin
Glyph : Augmenter la taille des fenêtres contextuelles par compression visuelle et textuelle
PICABench : Où en sommes-nous en matière de modification d'images physiquement réaliste ?
DeepAnalyze : modèles de langage à grande échelle agents pour la science des données autonome
Attention auto-associative pour l'apprentissage des opérateurs dans la simulation thermique 3D-IC
Terre IA : Déverrouiller des informations géospatiales grâce aux modèles fondamentaux et au raisonnement multimodal
Repenser les écarts interlinguistiques du point de vue statistique
Libérer le raisonnement scientifique pour la génération de protocoles d'expérimentation biologique à l'aide d'un mécanisme de récompense structuré basé sur des composants
Skyfall-GS : Synthèse de scènes urbaines 3D immersives à partir d'images satellitaires
Désalignement émergent par apprentissage in-situ : des exemples in-situ restreints peuvent entraîner des LLM largement désalignés