Command Palette
Search for a command to run...
Génération Vidéo En Temps Réel Auto-forcée
Date
URL du document
GitHub
1. Introduction au tutoriel

Self Forcing, proposé par l'équipe de Xun Huang le 9 juin 2025, est un nouveau paradigme d'entraînement pour les modèles de diffusion vidéo autorégressifs. Il résout le problème persistant du biais d'exposition, où les modèles entraînés sur un contexte réel doivent générer des séquences à partir de leurs propres sorties imparfaites lors de l'inférence. Contrairement aux méthodes précédentes qui débruitent les images futures à partir d'images du contexte réel, Self Forcing définit les conditions de génération de chaque image sur la sortie précédemment générée en effectuant un déploiement autorégressif avec mise en cache des paires clé-valeur (KV) pendant l'entraînement. Cette stratégie est supervisée par une fonction de perte globale au niveau vidéo qui évalue directement la qualité de la séquence générée entière, plutôt que de s'appuyer uniquement sur une fonction objectif traditionnelle image par image. Pour garantir l'efficacité de l'entraînement, un modèle de diffusion à quelques étapes et une stratégie de troncature du gradient stochastique sont utilisés, équilibrant efficacement le coût de calcul et les performances. Un mécanisme de mise en cache des paires clé-valeur est également introduit pour obtenir une extrapolation vidéo autorégressive efficace. Des expériences approfondies démontrent que leur méthode permet de générer du contenu vidéo en temps réel avec une latence inférieure à la seconde sur un seul GPU, tout en atteignant, voire en surpassant, la qualité de génération de modèles de diffusion non causaux et nettement plus lents. Les résultats de l'article associé sont les suivants : Auto-forçage : combler l'écart entre la formation et les tests dans la diffusion vidéo autorégressive .
Ce tutoriel utilise des ressources pour une seule carte RTX 4090.
2. Exemples de projets
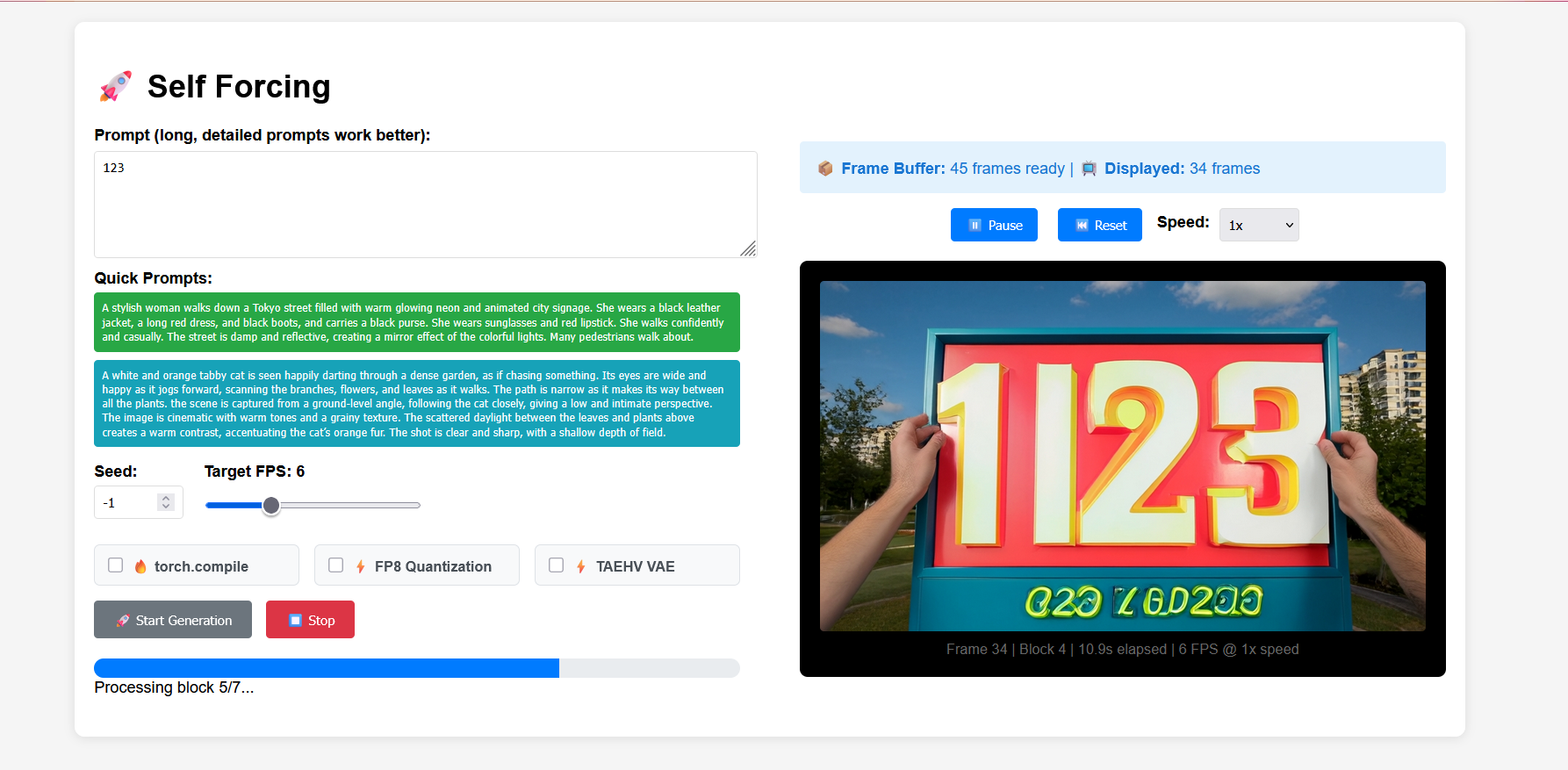
3. Étapes de l'opération
1. Après avoir démarré le conteneur, cliquez sur l'adresse API pour accéder à l'interface Web
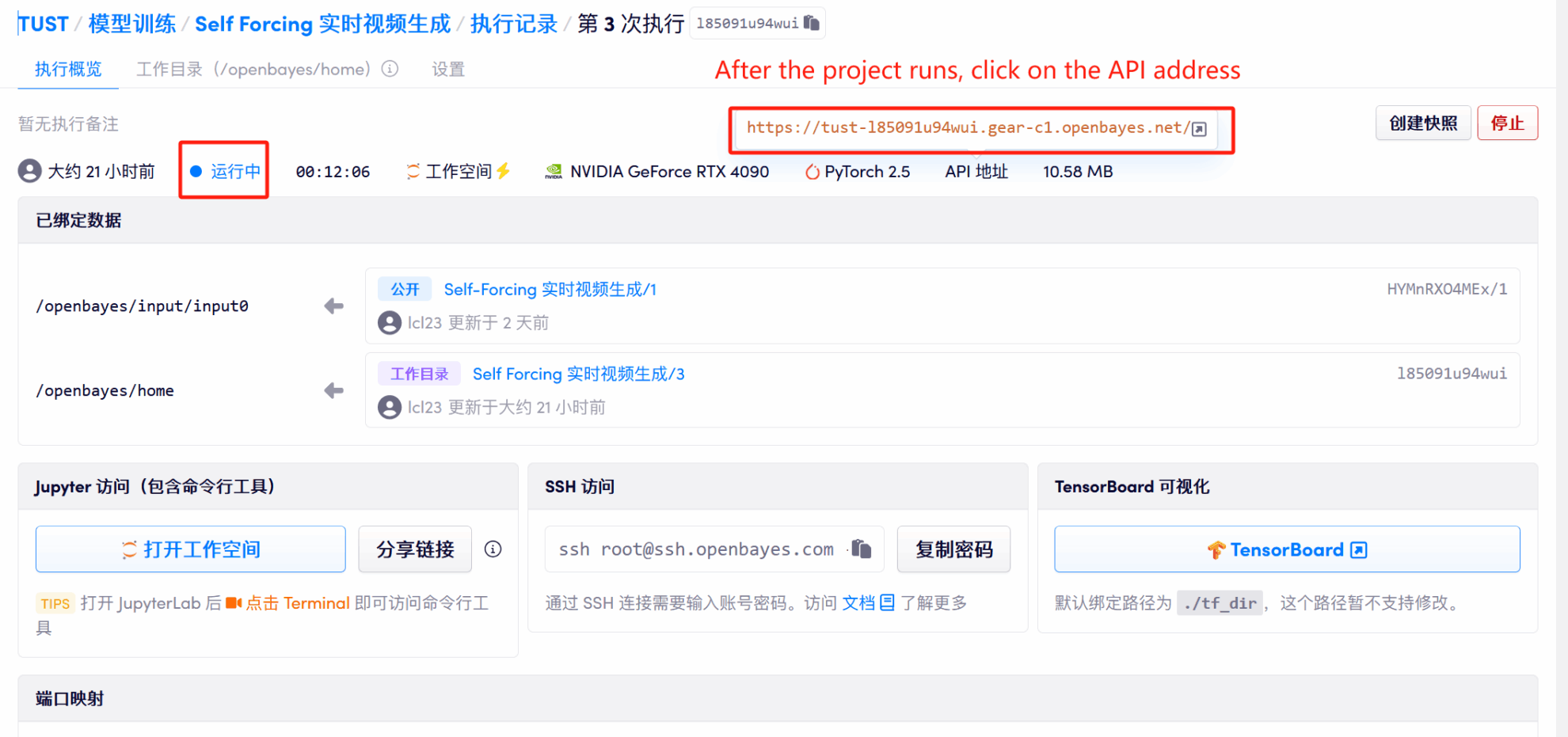
2. Étapes d'utilisation
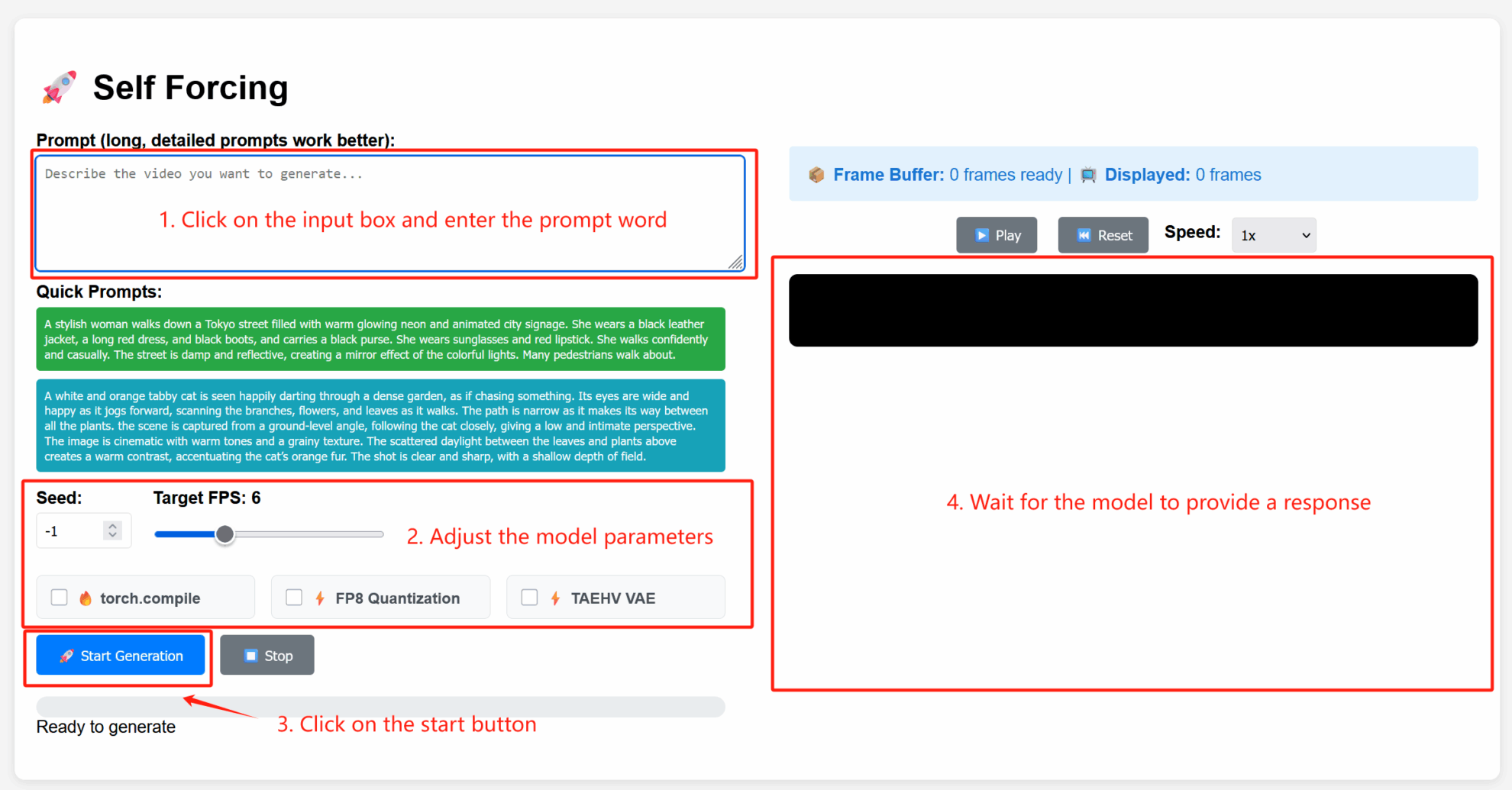
Description des paramètres
- Paramètres avancés :
- Graine : valeur aléatoire qui contrôle le caractère aléatoire du processus de génération. Une graine fixe peut reproduire les mêmes résultats ; -1 indique une graine aléatoire.
- FPS cible : fréquence d'images cible. La valeur par défaut est 6, ce qui signifie que la vidéo générée est à 6 images par seconde.
- torch.compile : activez l'optimisation de la compilation PyTorch pour accélérer l'inférence du modèle (prise en charge de l'environnement requise).
- Quantification FP8 : permet la quantification à virgule flottante 8 bits, réduisant la précision de calcul pour augmenter la vitesse de génération (peut légèrement affecter la qualité).
- TAEHV VAE : spécifie le type de modèle d'autoencodeur variationnel (VAE) utilisé, ce qui peut affecter les détails ou le style générés.
4. Discussion
🖌️ Si vous voyez un projet de haute qualité, veuillez laisser un message en arrière-plan pour le recommander ! De plus, nous avons également créé un groupe d’échange de tutoriels. Bienvenue aux amis pour scanner le code QR et commenter [Tutoriel SD] pour rejoindre le groupe pour discuter de divers problèmes techniques et partager les résultats de l'application↓

Informations sur la citation
Les informations de citation pour ce projet sont les suivantes :
@article{huang2025selfforcing,
title={Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion},
author={Huang, Xun and Li, Zhengqi and He, Guande and Zhou, Mingyuan and Shechtman, Eli},
journal={arXiv preprint arXiv:2506.08009},
year={2025}
}Vue d’ensemble de Notebook
Niveau
Créer de l'IA avec l'IA
De l'idée au lancement — accélérez votre développement IA avec le co-codage IA gratuit, un environnement prêt à l'emploi et le meilleur prix pour les GPU.