Command Palette
Search for a command to run...
L'Université d'Oxford Et d'autres Ont Fouillé En Profondeur Les Données De Santé De 7,46 Millions d'adultes Pour Développer Des Algorithmes De Dépistage Précoce, Permettant Une Prédiction Précoce De 15 Types De Cancer Sur La Base d'indicateurs sanguins.

Au Royaume-Uni, la survie au cancer est depuis longtemps confrontée à de graves défis, les résultats cliniques étant parmi les plus faibles des pays développés. Derrière cette situation se cache la réalité objective selon laquelle un grand nombre de patients atteints de cancer sont déjà à un stade intermédiaire ou avancé au moment du diagnostic et n’ont pas bénéficié du meilleur moment pour suivre un traitement. En 2011, le Service national de santé du Royaume-Uni (NHS) a publié sa stratégie contre le cancer, qui énonce clairement l'objectif de diagnostiquer le cancer du 75% à un stade curable (stade 1 ou 2), dans le but d'améliorer la situation actuelle en optimisant le processus de diagnostic. Cette stratégie considère les soins primaires comme un point de rupture, améliore l’efficacité du diagnostic précoce grâce à des algorithmes prédictifs et indique la direction à suivre pour l’innovation des modèles de diagnostic et de traitement du cancer.
Dans ce contexte, des algorithmes de prédiction du cancer développés à partir de bases de données électroniques de santé primaires à grande échelle ont émergé, tels que le modèle de score QCancer.La probabilité absolue qu’un individu soit atteint d’un cancer non diagnostiqué est évaluée en intégrant plusieurs facteurs tels que l’âge, le sexe, le statut de pauvreté, le tabagisme, la consommation d’alcool, les antécédents familiaux et les symptômes.Les directives cliniques nationales recommandent aux cliniciens d’envisager des tests supplémentaires ou une orientation lorsque la valeur prédictive positive du cancer dépasse un seuil spécifique (comme 3%). Ces algorithmes sont intégrés aux systèmes informatiques cliniques de soins primaires pour évaluer le risque de cancer en temps réel lorsque les patients consultent le médecin, fournissant ainsi un support de données pour la prise de décision clinique.
En 2020, un peu plus de la moitié des cancers en Angleterre sont diagnostiqués au stade 1 ou 2, ce qui représente encore un écart important par rapport à l'objectif de 75% d'ici 2028. Ces dernières années, les progrès de la technologie des tests sanguins ont ouvert une nouvelle voie pour surmonter ce goulot d'étranglement.De nombreuses études ont montré que des changements anormaux dans les indicateurs sanguins tels que l’hémoglobine, le nombre de globules blancs et les plaquettes peuvent apparaître plusieurs années plus tôt que les symptômes cliniques.Cela suggère son potentiel en tant que biomarqueur d'alerte précoce pour le cancer, incitant les chercheurs à explorer l'intégration des données d'analyses sanguines dans des modèles prédictifs pour améliorer la capacité de l'algorithme à identifier les cancers sans symptômes ou avec des symptômes atypiques.
Sur cette base, l’Université Queen Mary de Londres et l’équipe de recherche de l’Université d’Oxford ont collaboré pour développer deux nouveaux algorithmes de prédiction du cancer basés sur les dossiers médicaux électroniques anonymes de 7,46 millions d’adultes en Angleterre :L'algorithme de base intègre les facteurs cliniques traditionnels et les variables de symptômes, et l'algorithme avancé intègre en outre des indicateurs sanguins tels que la numération globulaire complète et les tests de la fonction hépatique.
L'étude a utilisé un modèle de régression logistique multinomiale pour modéliser les groupes d'hommes et de femmes séparément, non seulement pour prédire la probabilité globale de cancer,Il permet également pour la première fois des évaluations individuelles des risques pour 15 types de cancer, dont le cancer du foie et le cancer de la bouche.Au cours de 5 millions de validations indépendantes, le nouvel algorithme a démontré une discrimination, un étalonnage et une sensibilité supérieurs aux modèles existants, fournissant une base scientifique pour optimiser les processus de prise de décision clinique et promouvoir le diagnostic précoce du cancer. De plus, l’équipe propose que cette méthode soit le premier algorithme utilisé en soins primaires pour estimer la probabilité d’un cancer du foie qui n’est pas actuellement diagnostiqué.
Les résultats de recherche pertinents ont été publiés dans la revue de renommée internationale Nature Communications sous le titre « Développement et validation externe d'algorithmes de prédiction pour améliorer le diagnostic précoce du cancer ».

Adresse du document :
Le projet open source « awesome-ai4s » rassemble plus de 100 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Étude à double base de données et à cohortes multiples : la taille de l'échantillon dépasse un million, ce qui renforce le soutien des données dans tous les aspects.
Les données de cette étude ont été obtenues à partir de deux bases de données de dossiers médicaux électroniques : QResearch (version 48) et Clinical Practice Research Datalink (CPRD Gold).Le premier est basé sur le système EMIS et couvre l'Angleterre, tandis que le second est basé sur le système Vision et comprend des données cliniques en Irlande du Nord, en Écosse et au Pays de Galles, formant une cohorte de validation externe géographiquement indépendante pour garantir la diversité et la représentativité des données.
En termes de population étudiée, comme le montre la figure ci-dessous, les données de la clinique QResearch en Angleterre ont été divisées aléatoirement en une cohorte de développement de 7 464 507 personnes, dont 129 715 nouveaux cas de cancer, une cohorte de validation de 2 637 184 personnes, dont 44 984 nouveaux cas de cancer, et une cohorte de validation CPRD de 2 736 726 personnes, dont 32 328 nouveaux cas de cancer.
La taille de l’échantillon des trois cohortes dépassait toutes le million, couvrant les personnes âgées de 18 à 84 ans.Il comprend les hémopathies malignes courantes chez les jeunes, le cancer du sein et les types de cancer courants chez les personnes d’âge moyen et les personnes âgées. La période s’étend du 1er janvier 2015 au 31 mars 2023, avec une période de suivi de 2 ans. Il se concentre sur les patients qui n’ont pas reçu de diagnostic de cancer au moment de l’inscription et garantit l’exactitude des nouvelles données sur le cancer en excluant ceux qui présentaient des « symptômes d’alerte » dans les 12 mois précédant l’inscription. Les données couvrent des dimensions telles que l’âge, le sexe, le statut de pauvreté, le tabagisme, la consommation d’alcool, les antécédents familiaux, les symptômes et les analyses de sang (numération globulaire complète, tests de la fonction hépatique). À l’exception de la cohorte anglaise, dont les données autodéclarées sur la race, le tabagisme, la consommation d’alcool et l’IMC étaient légèrement plus complètes, les caractéristiques de base de chaque cohorte étaient généralement cohérentes, fournissant une base de données équilibrée pour le développement du modèle.
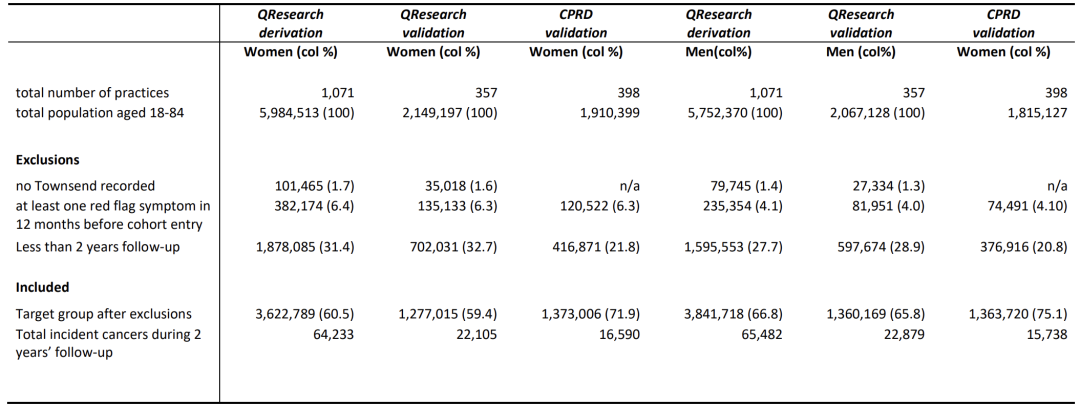
L’étude s’appuie sur quatre sources de données principales : les médecins généralistes, les hôpitaux, les taux de mortalité et les registres du cancer. Il identifie 13 types de cancer déjà inclus dans QCancer (cancer du poumon, cancer colorectal, etc.) et les nouveaux cancers du foie, cancers oro-pharyngés, etc., soit un total de 15 types.La cohorte CPRD était basée uniquement sur les diagnostics enregistrés par les médecins généralistes en raison de limitations de données, ce qui a donné lieu à un système de validation à plusieurs niveaux. Ces données se caractérisent par une taille d’échantillon importante, une vaste zone géographique, une longue période de temps, de multiples facteurs prédictifs et une forte pertinence clinique. En développant une cohorte pour construire un modèle prédictif et en utilisant des cohortes de validation de différentes régions et systèmes (en particulier la cohorte externe CPRD) pour évaluer l'universalité et la fiabilité du modèle, nous pouvons garantir l'efficacité et la stabilité de l'algorithme dans des scénarios cliniques réels et fournir un support de données pour le diagnostic précoce du cancer.
Développement d'un modèle de prédiction du cancer : modélisation par régression logistique multinomiale et validation multidimensionnelle
Lors du développement du modèle, l’étude a examiné les variables prédictives candidates en fonction des algorithmes et de la littérature existants, couvrant les caractéristiques démographiques, les habitudes de tabagisme et de consommation d’alcool, les antécédents familiaux de cancer, les comorbidités, ainsi que les symptômes et les résultats des analyses de sang. Les symptômes ont été subdivisés en « symptômes d'alerte (forte association avec le cancer, base d'une orientation urgente selon les directives cliniques) » et symptômes non spécifiques, et les analyses sanguines incluaient les dossiers de la cohorte des 2 années précédentes pour capturer les signaux potentiels.
Afin de garantir la scientificité et l'exactitude du modèle,Dans la modélisation, les chercheurs ont utilisé la régression logistique multinomiale pour estimer les coefficients des variables prédictives pour chaque type de cancer et ont ajusté les modèles pour les hommes et les femmes.Les valeurs manquantes de consommation d'alcool, de tabagisme et d'indicateurs sanguins ont été remplies par imputation multiple par équation en chaîne (5 imputations pour les hommes et les femmes chacune + fusion de la règle de Rubin), et les variables binaires ont été codées dans des catégories dichotomiques selon les dossiers de diagnostic du médecin généraliste. Lors de l'ajustement du modèle, les variables avec un niveau de signification ≤ 0,01 ont été conservées et les coefficients avec un rapport de risque de 0,80 à 1,20 et aucune signification ont été fixés à zéro. Un modèle concis a été construit en combinant la valeur P et la taille de l’effet pour éviter la sélection automatique des variables basée uniquement sur la signification statistique et garantir la pertinence clinique.
Des polynômes fractionnaires ont été utilisés pour modéliser les relations non linéaires entre les variables continues et pour tester l’interaction entre les variables prédictives et l’âge. Lors de l'évaluation de l'optimisme du modèle, les chercheurs ont utilisé un facteur de rétrécissement heuristique pour évaluer l'optimisme du modèle, et les valeurs de rétrécissement des deux modèles étaient > 0,99, confirmant qu'il n'y avait pas de surajustement. Enfin, le modèle A (facteurs cliniques + symptômes) et le modèle B (modèle A + résultats des analyses sanguines) ont été dérivés. Ce dernier vise à améliorer la précision de la prédiction en ajoutant de nouveaux signaux liés au cancer.
L’évaluation du modèle a été menée dans deux cohortes de validation indépendantes. En plus de calculer l'AUROC pour évaluer la capacité de discrimination,Les chercheurs ont introduit un indice de discrimination multi-catégories (PDI, 12 catégories pour les hommes/14 catégories pour les femmes, dont une catégorie sans cancer) pour mesurer la performance globale de la classification (plus le PDI est proche de 1, plus la discrimination est précise).La cohérence entre la probabilité prédite et la valeur réelle a été testée par la courbe d'étalonnage, la pente et l'interception. L'analyse spéciale du cancer précoce se concentre sur les cas de 2015 à 2020, en utilisant le stade 1/stade 2 comme définition précoce, et stratifie et évalue des sous-groupes tels que les régions géographiques, les races et les groupes d'âge pour vérifier l'universalité du modèle dans différentes populations.
Application du modèle de prédiction du cancer : le cancer du foie et le cancer de la bouche ont été inclus pour la première fois, et la relation entre les indicateurs sanguins et le risque de cancer a été analysée.
Dans la phase d'application du modèle et de vérification expérimentale,Cette étude a mené une vérification multidimensionnelle de l’association des variables, de la capacité de discrimination, de l’effet d’étalonnage et de la valeur clinique du nouveau modèle prédictif.Par rapport à l'algorithme QCancer existant, le nouveau modèle ajoute quatre nouvelles conditions médicales : la cirrhose, l'hépatite B, l'hépatite C (liée au cancer du foie) et le SIDA (lié au cancer du sang et au cancer du rein), complète l'association avec les antécédents familiaux de cancer du poumon/cancer du sang et sept symptômes croisés tels que les démangeaisons, les ecchymoses et les bosses abdominales.
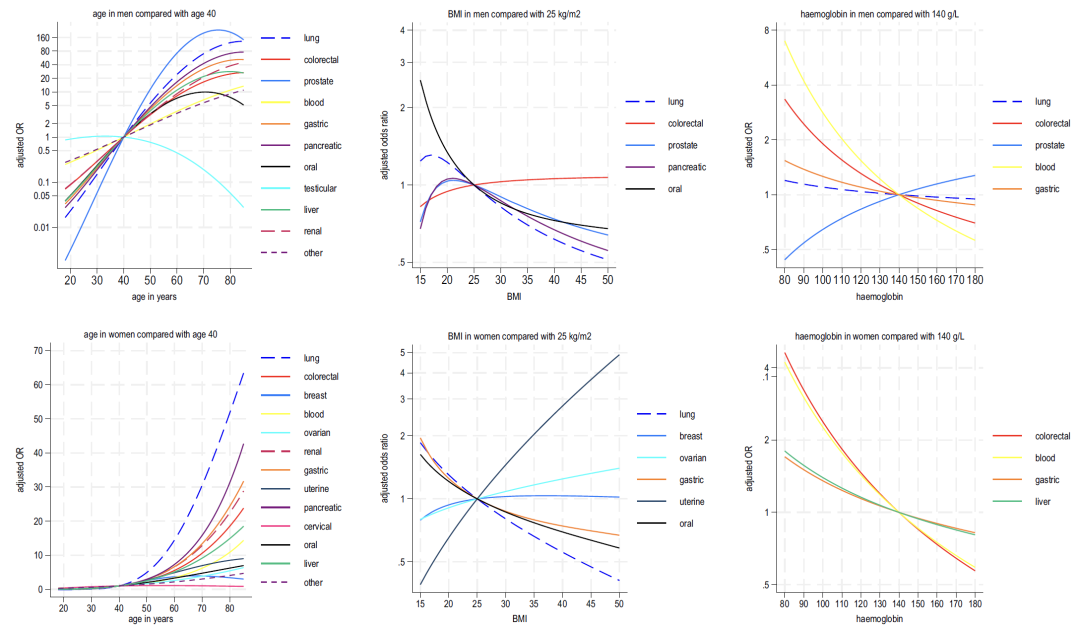
Il y avait des différences entre les sexes dans l’interaction entre l’âge et les symptômes :Le risque de la plupart des cancers est plus élevé à un âge plus jeune chez les hommes, mais l’inverse est vrai chez les femmes.L’analyse de l’âge et de l’IMC a montré qu’à l’exception du cancer des testicules et du cancer du col de l’utérus, le risque de tous les types de cancer augmentait avec l’âge ; un IMC plus faible était positivement corrélé à plusieurs types de cancer, et le risque de cancer de l'utérus et de cancer de l'ovaire chez les femmes augmentait avec un IMC plus élevé.
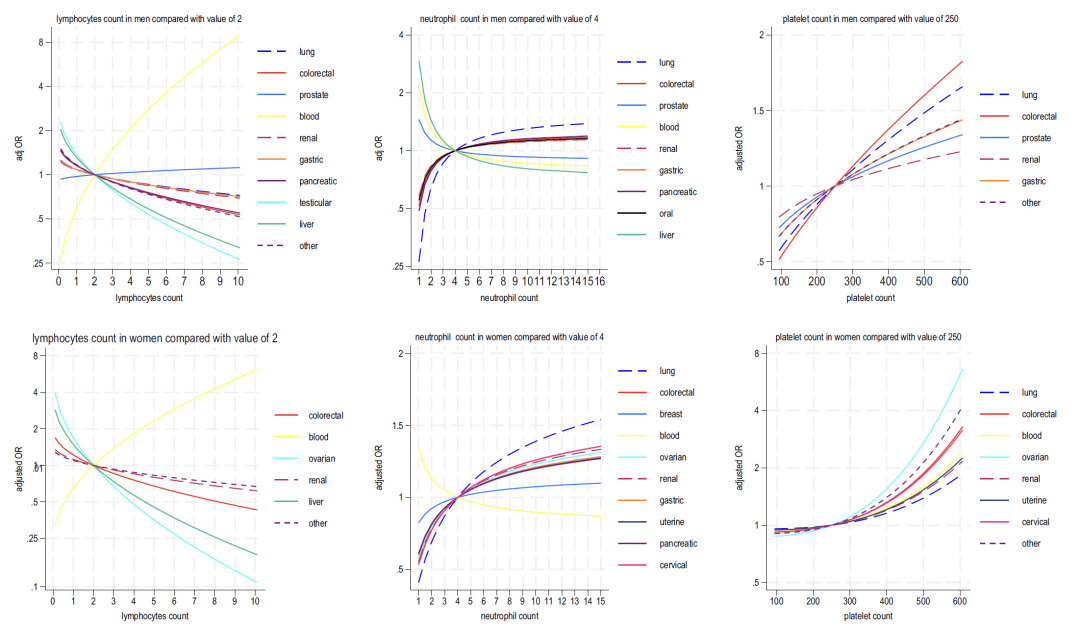
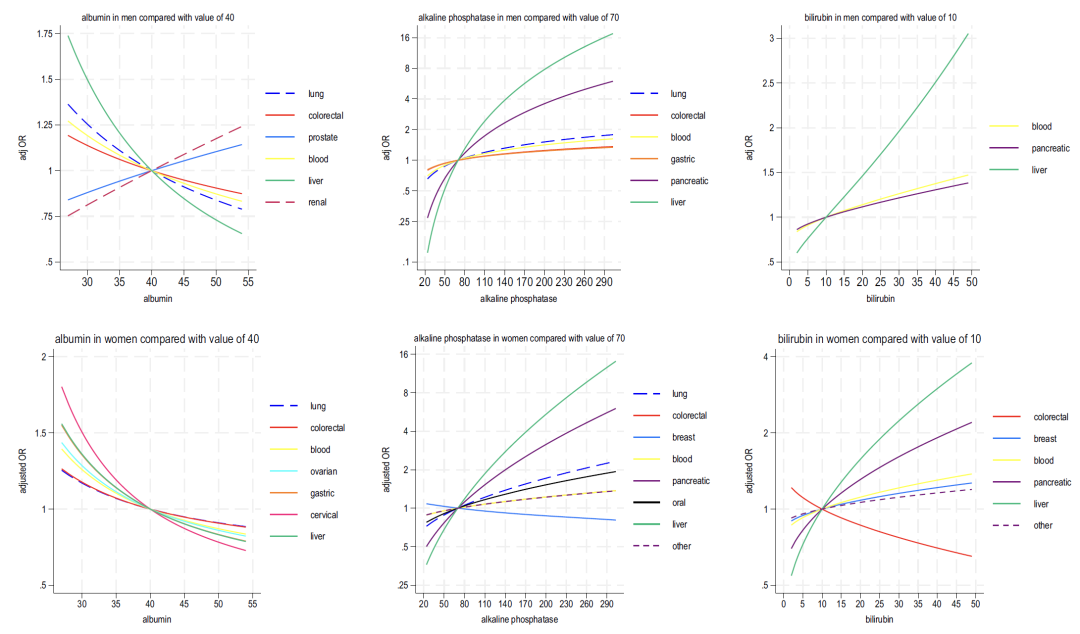
Comme le montrent les figures 2 à 4 ci-dessous, l’analyse des indicateurs sanguins inclus dans le modèle B montre que :
* Hémoglobine : Une diminution de cet indicateur est associée au cancer du poumon et au cancer colorectal chez les hommes, et au cancer colorectal et au cancer du foie chez les femmes ;
* Lymphocyte : corrélé négativement avec la plupart des cancers et fortement corrélé positivement avec les cancers du sang ;
* Neutrophile : Chez les femmes, une augmentation de cet indicateur est largement associée au cancer (le cancer du poumon est le plus significatif), tandis que chez les hommes, elle est « associée de manière bidirectionnelle (des valeurs élevées sont associées à 6 types de cancer, et des valeurs faibles sont associées au cancer du foie et au cancer de la prostate) » ;
* Plaquettes : une numération plaquettaire élevée est positivement corrélée à de multiples cancers chez les hommes et les femmes (le cancer colorectal chez les hommes et le cancer de l'ovaire chez les femmes étant les plus forts), et est associée de manière synergique à une élévation des neutrophiles et à une diminution des lymphocytes ;
* Fonction hépatique : une diminution de l’albumine et une augmentation de la phosphatase alcaline indiquent généralement un risque de cancer, tandis qu’une augmentation de la bilirubine est étroitement liée au cancer du foie et au cancer du sang.
Dans l’évaluation de la capacité de discrimination, comme le montre la figure ci-dessous, la statistique c (AUROC) du modèle B (y compris les tests sanguins) est meilleure que celle du modèle A dans son ensemble. L’efficacité globale de discrimination des hommes (0,876) est supérieure à celle des femmes (0,844). La plupart des valeurs c des 15 cancers sont > 0,8, seuls le cancer de la bouche (0,747) et le cancer du col de l'utérus (0,694) chez les femmes étant légèrement inférieurs. L'indice de discrimination multi-catégories (PDI) a montré que le modèle B était supérieur au modèle A dans sa capacité à distinguer les hommes des femmes (0,323 pour les hommes et 0,266 pour les femmes) et avait des performances de classification exceptionnelles pour le cancer des testicules (PDI 0,641 pour les hommes) et le cancer de l'utérus (PDI 0,439 pour les femmes). L'analyse des sous-groupes a montré queLes performances du modèle étaient stables selon les races, les âges et les régions géographiques, avec de légères fluctuations dans les cancers rares en raison du petit nombre d’événements.
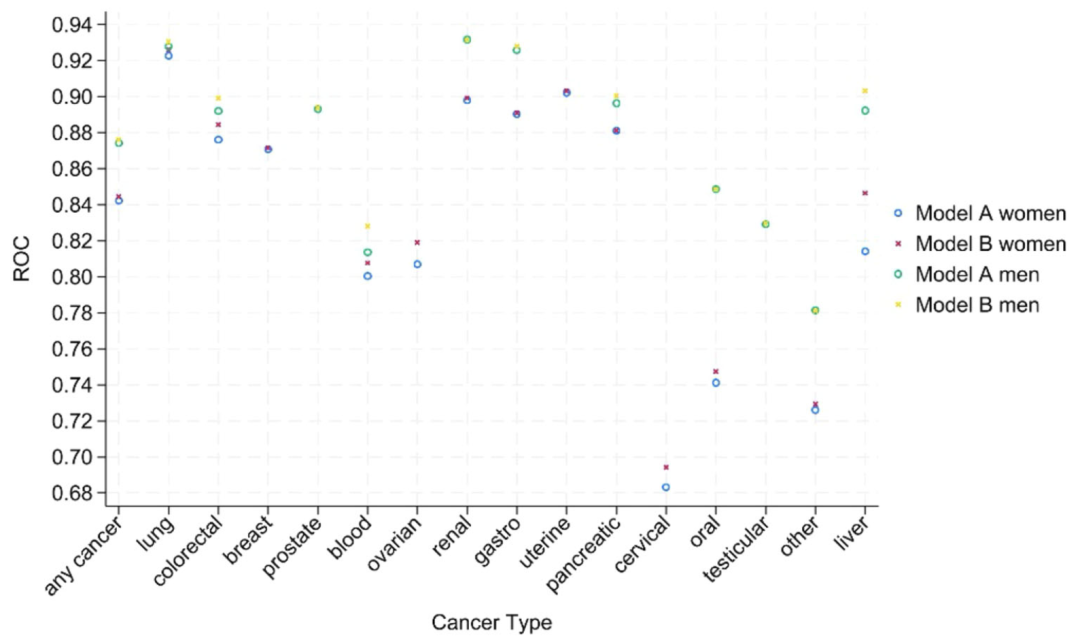
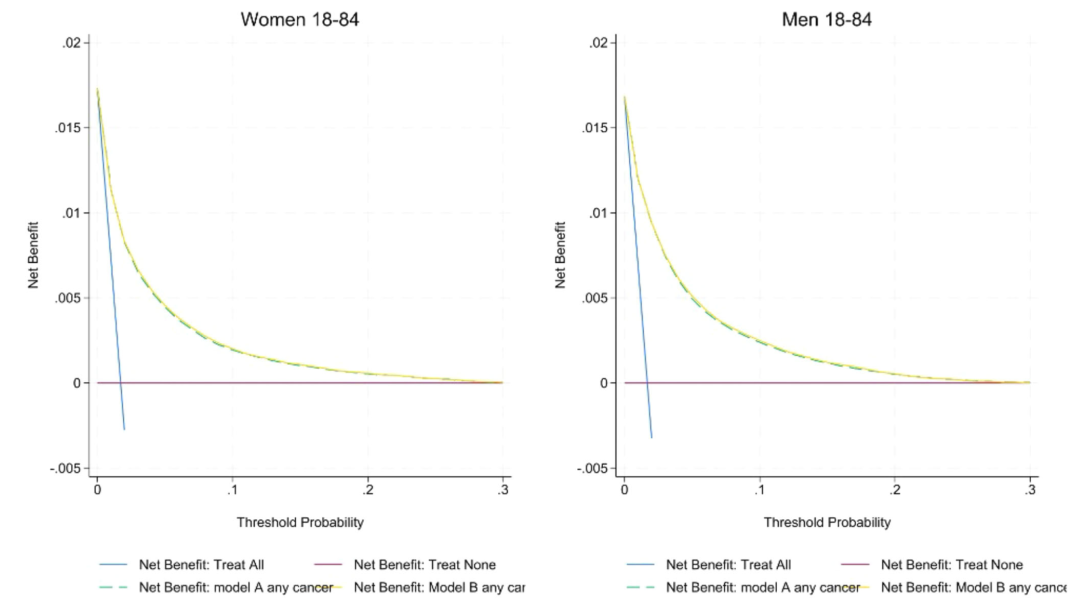
En termes de capacité d’étalonnage, comme le montre la figure ci-dessous, la pente d’étalonnage du modèle A/B dans la cohorte anglaise est proche de 1 (1,00 pour les femmes et 0,99 pour les hommes), et l’interception approche zéro ; Cependant, il existe une certaine surestimation de la probabilité de cancer chez les hommes et les femmes dans la cohorte externe CPRD. La courbe de décision montre que le bénéfice net du modèle B est supérieur à celui du modèle A et de QCancer, en particulier au seuil de référence de 3%, la sensibilité du modèle A/B au cancer masculin (82,6%) est supérieure à celle de QCancer (78,1%), et la sensibilité au cancer féminin augmente de 66,0% à plus de 77%, et la capacité à identifier le cancer précoce de stade 1/2 est comparable à celle de tous les stades (75% pour les femmes et 81% pour les hommes). L’analyse de reclassification a montré queComparé à QCancer, le modèle A classe davantage de personnes âgées comme à haut risque et de personnes plus jeunes comme à faible risque, optimisant ainsi la précision de l’allocation des ressources cliniques.
Algorithmes mondiaux de prédiction du cancer et diagnostic précoce : progrès interdisciplinaires dans la recherche universitaire et l'innovation en entreprise
Dans le domaine des algorithmes de prédiction du cancer et du diagnostic précoce, des équipes de recherche scientifique d’universités du monde entier et d’entreprises technologiques favorisent la transformation accélérée de la recherche théorique en applications cliniques grâce à l’innovation interdisciplinaire.
Par exemple, le modèle MuMo développé par l’équipe de Dong Bin et Shen Lin de l’Université de Pékin,Intégrer l'imagerie, la pathologie et les données cliniques des patients atteints d'un cancer gastrique HER2-positif pour fournir des prédictions précises pour un traitement individualisé ;Le Centre d'information sur les réseaux informatiques de l'Académie chinoise des sciences a construit le modèle SuRe-Transformer basé sur le système de superordinateur « Dongfang » utilisant l'architecture Transformer.Améliorer la précision de prédiction HRD des images de pathologie du cancer du sein par 21% ;Le groupe de recherche de Li Shao à l'Université Tsinghua a utilisé le cadre d'apprentissage faiblement supervisé HistoCell.Réaliser une inférence non supervisée de réseaux d'association spatiale de cellules dans des images pathologiques.Fournir de nouveaux outils pour la recherche sur le microenvironnement tumoral.
Le modèle CHIEF développé par la Harvard Medical School et l'Université de Stanford,Diagnostiquer 19 types de cancer avec une précision de 94%,Il peut également prédire les taux de survie des patients sur la base d’images pathologiques ; Le modèle d'apprentissage en profondeur ResNetRS50 construit par l'Université de Cambridge prédit le cancer du sang en analysant les données sanguines, avec une précision, une vitesse et un taux d'erreur plus élevés que les modèles avancés.
L’innovation dans le secteur des affaires se concentre davantage sur l’intégration de la mise en œuvre de la technologie et de la pratique clinique. La plateforme AI for Health de Microsoft intègre les génomes et les dossiers médicaux électroniques pour construire une carte individuelle des risques de cancer, avec une précision de prédiction de 89% pour les personnes à haut risque de cancer du sein ; Le système AlphaScan de Google DeepMind a une précision de 96% dans la détection précoce du cancer du poumon ; La solution d'imagerie pulmonaire d'IA de la société de technologie médicale InferRead, un système de détection de nodules pulmonaires basé sur l'apprentissage profond, a été appliquée à la tomodensitométrie clinique, améliorant considérablement l'efficacité du diagnostic.
Dans l’ensemble, le domaine des algorithmes de prédiction du cancer et du diagnostic précoce évolue du dépistage d’un seul cancer vers un dépistage précoce de plusieurs cancers : le test Galleri de Grail aux États-Unis permet de dépister 50 types de cancer et de localiser la lésion primaire grâce à une analyse de la méthylation sanguine, et la technologie PanSeer® de la société chinoise Xunyuan Biotechnology permet un dépistage précoce efficace de cinq cancers courants. Avec l'intégration profonde de l'intelligence artificielle et du big data, les algorithmes de prédiction du cancer devraient être popularisés dans les soins médicaux primaires, favorisant la transformation des modèles de diagnostic et de traitement de la « médecine empirique » à la « médecine de données de précision », et jetant les bases pour parvenir à une « détection et une intervention précoces ».
Liens de référence :
1.https://bda.pku.edu.cn/info/1003/2824.htm
2.https://www.cas.cn/syky/202505/t20250522_5069507.shtml
3.https://mp.weixin.qq.com/s/s1JyOTPChdoMipmTzBBqvw
4.https://mp.weixin.qq.com/s/4fhMJ25xVAThAFTdmZyt9w








