Command Palette
Search for a command to run...
Le Plus Grand Ensemble De Données De Segmentation Vidéo De Meta Est Désormais En Ligne, 50 Fois Plus Grand Que Les Ensembles De Données Similaires ; Il a 9 000 Étoiles ! La Démonstration De Kuaishou Digital Human Démarre En Un Clic !

Comment l’IA donne-t-elle vie à des portraits statiques, en faisant vivre leurs sourires, leurs clignements d’yeux et même leurs expressions faciales subtiles ? Récemment, l'équipe Kuaishou a rendu LivePortrait open-source. Téléchargez simplement une photo statique et elle peut être transformée en un portrait dynamique avec des expressions riches. Il a déjà reçu 9 000 étoiles sur GitHub.Ce tutoriel est désormais disponible sur HyperAI. Venez le découvrir dès maintenant !
Portrait en direct Lien du tutoriel :
Du 29 juillet au 2 août, le site officiel de hyper.ai est mis à jour :
* Ensembles de données publiques de haute qualité : 11
* Sélection de tutoriels de haute qualité : 3
* Sélection d'articles communautaires : 4 articles
* Entrées d'encyclopédie populaire : 5
* Principales conférences avec date limite en août : 4
Visitez le site officiel :hyper.ai
Ensembles de données publiques sélectionnés
1. Ensemble de données de segmentation vidéo SA-V
L'ensemble de données SA-V est un ensemble de données de segmentation vidéo à grande échelle créé par Meta en 2024 pour la formation et l'évaluation de Meta Segment Anything Model 2. Il contient environ 51 000 vidéos du monde réel et 643 000 annotations de masques spatio-temporels, ce qui est environ 50 fois plus important que d'autres ensembles de données similaires.
Utilisation directe :https://go.hyper.ai/X4DGI
Afin de promouvoir le développement efficace des systèmes d'IA dans le domaine de la biologie, les chercheurs de FutureHouse Inc. ont lancé le Language Agent Biology Benchmark Dataset LAB-Bench, qui est utilisé pour évaluer les performances des systèmes d'IA dans la recherche biologique réelle, comme la recherche et le raisonnement de la littérature, l'interprétation des graphiques et la compréhension et le traitement des séquences d'ADN et de protéines. Les résultats ont été soumis à la conférence de haut niveau NeurlPS 2024.
Utilisation directe :https://go.hyper.ai/UznkS
3. Ensemble de données de problèmes de compétition de mathématiques NuminaMath-CoT
L'ensemble de données contient plus de 860 000 paires de questions-solutions de compétitions mathématiques, chacune utilisant le modèle de raisonnement de la chaîne de pensée (CoT). Les sources de l'ensemble de données comprennent des exercices de mathématiques de lycée chinois, des questions de compétition d'Olympiade mathématique américaine et internationale. Les données ont été principalement collectées à partir de documents d’examen PDF en ligne et de forums de discussion sur les mathématiques.
Utilisation directe :https://go.hyper.ai/svElx
4. Ensemble de données d'évaluation du jeu Taptap
Cet ensemble de données contient des critiques étiquetées d'environ 300 jeux sur l'application de jeux mobiles TapTap, avec un total de 4 888 exemples de données, qui peuvent être utilisés pour des tâches d'analyse des sentiments. Parmi eux, les avis utilisateurs avec moins de 3 étoiles (maximum 5 étoiles) ont été considérés comme 0 (insatisfait), et les autres étaient 1 (satisfait). Le rapport entre ces deux catégories est d’environ 1:1.
Utilisation directe :https://go.hyper.ai/ISf7c
5. Ensemble de données CCPD Ensemble de données de détection de plaques d'immatriculation chinoises
L'ensemble de données CCPD est un ensemble de données de reconnaissance de plaques d'immatriculation vaste, diversifié et soigneusement annoté. L'ensemble de données est principalement collecté dans les parkings de Hefei, en Chine, et contient des photos de plaques d'immatriculation dans une variété d'environnements complexes, tels que le flou, l'inclinaison, les jours de pluie et de neige, ce qui rend l'ensemble de données plus difficile dans la tâche de reconnaissance des plaques d'immatriculation.
Utilisation directe :https://go.hyper.ai/gZ37Y
6. Ensemble de données de synthèse de nouvelles TinyStories
Cet ensemble de données est un ensemble de données synthétiques de nouvelles générées par GPT-3.5 et GPT-4, et le vocabulaire contenu est limité à la gamme de compréhension des enfants de 3 à 4 ans. Cet ensemble de données peut être utilisé pour former des modèles afin de générer des histoires courtes qui sont fluides, cohérentes, diversifiées et dotées d'une grammaire presque parfaite.
Utilisation directe :https://go.hyper.ai/m9ouS
7. Fumée des feux de forêt Ensemble de données de détection de fumée des feux de forêt
Cet ensemble de données a été publié conjointement par AI for Mankind et HPWREN en 2019. Il contient un total de 737 images, dont 516 images d'entraînement, 147 images de vérification et 74 images de test, le format d'annotation étant COCO. L’objectif est d’améliorer la capacité du modèle à distinguer les nuages/brouillards de la fumée et d’établir une boucle de rétroaction de bout en bout.
Utilisation directe :https://go.hyper.ai/ofGHZ
8. Ensemble de données LJSpeech
Il s'agit d'un ensemble de données vocales du domaine public composé de 13 100 courts extraits audio dans lesquels un seul locuteur lit des passages de 7 livres de non-fiction. Des transcriptions sont fournies pour chaque fragment. La durée des clips variait de 1 à 10 secondes, pour une durée totale d’environ 24 heures.
Utilisation directe :https://go.hyper.ai/Eo1bK
L'ensemble de données contient 8 508 images des douze catégories du zodiaque chinois. L'ensemble de données a été pré-divisé en formation, validation et test avec un ratio de 85:7,5:7,5.
Utilisation directe :https://go.hyper.ai/ps2es
Cet ensemble de données contient près de 300 000 données de formation et est conçu spécifiquement pour le domaine juridique chinois. Il vise à améliorer les capacités du modèle en matière de traitement de textes juridiques, de raisonnement juridique, de recherche de connaissances et de conformité dans le domaine judiciaire.
Utilisation directe :https://go.hyper.ai/zh9Ij
11. Ensemble de données audio de reconnaissance numérique à chiffres parlés libres (FSDD)
Le Free Spoken Digit Dataset (FSDD) est un ensemble de données audio composé d'enregistrements vocaux numériques dans des fichiers wav avec un taux d'échantillonnage de 8 kHz. Les enregistrements ont été édités pour minimiser le silence au début et à la fin.
Utilisation directe :https://go.hyper.ai/HZ00d
Pour plus d'ensembles de données publics, veuillez visiter :
Tutoriels publics sélectionnés
HiDiffusion est un framework haute résolution open source développé par Megvii Technology. Il prend non seulement en charge les images générées par du texte et les images générées par des images, mais dispose également de capacités de restauration d'images. HyperAI Super Neural a maintenant lancé le tutoriel « HiDiffusion peut générer rapidement une démonstration d'image 8k de haute qualité ». Vous n'avez pas besoin de saisir de commandes, clonez-le simplement en un clic pour démarrer.
Exécutez en ligne :https://go.hyper.ai/yZ5K5
2. Démonstration humaine numérique vidéo générée par image open source LivePortrait Kuaishou
LivePortrait est un framework de génération de vidéos de portrait. Ses principales fonctions incluent la génération d'animations vives à partir d'une seule image, le contrôle précis des mouvements des yeux et des lèvres, le traitement de l'assemblage homogène de plusieurs portraits, la prise en charge de portraits multi-styles, la génération d'animations haute résolution, etc. Ce didacticiel est une démonstration d'exécution en un clic de LivePortrait. L'environnement et les dépendances pertinents ont été installés. Vous pouvez en faire l'expérience en le clonant et en le démarrant en un clic.
Exécutez en ligne :https://go.hyper.ai/oTs66
3. Démonstration d'agrandissement d'image super-résolution basée sur AuraSR GAN
AuraSR est un modèle de restauration d'images haute définition basé sur l'apprentissage en profondeur qui peut identifier intelligemment les informations détaillées dans les images et compléter automatiquement les détails manquants tout en agrandissant les images. Par rapport aux méthodes traditionnelles d'agrandissement d'image, AuraSR produit non seulement de meilleurs résultats, mais est également facile à utiliser et peut être facilement utilisé sans compétences professionnelles. Découvrez le modèle avec le clonage en un clic.
Exécutez en ligne :https://go.hyper.ai/y2wIU
Articles de la communauté
Aitomatic, une entreprise leader dans l'innovation en matière d'IA dans le secteur industriel, a annoncé le lancement de SemiKong, le premier modèle de langage d'IA open source au monde conçu spécifiquement pour l'industrie des semi-conducteurs. La société a déjà lancé un agent d'IA appelé aiKO, qui crée des agents exclusifs pour les utilisateurs professionnels en fonction de leur expertise et de leurs données, et donne aux entreprises la « pleine propriété » de leurs agents.
Voir le rapport complet :https://go.hyper.ai/A7eCi
2. Temps forts : « La conversation du siècle » entre Huang Renxun et Zuckerberg
Au petit matin du 30 juillet, lors de la 51e conférence graphique SIGGRAPH, le fondateur et PDG de Nvidia, Huang Renxun, et le fondateur et PDG de Meta, Mark Zuckerberg, ont eu une « discussion au coin du feu ». HyperAI a compilé les points forts et les sous-titres chinois complets de la vidéo.
Voir le rapport complet :https://go.hyper.ai/rbU2u
L'équipe de recherche du MIT a réutilisé des prédicteurs à état unique très précis tels qu'AlphaFold et ESMFold et les a affinés dans un cadre de correspondance de flux personnalisé pour obtenir des modèles de génération de structure protéique conditionnelle à la séquence, appelés AlphaFLOW et ESMFLOW. Cet article est une interprétation détaillée et un partage des documents pertinents.
Voir le rapport complet :https://go.hyper.ai/qupG9
Le laboratoire de modèles de base de la vie du département d'automatisation de l'université Tsinghua, en collaboration avec l'hôpital Xiangya de l'université du centre-sud, a proposé un modèle de base d'IA de diagnostic pathologique précis ROAM basé sur de grands intérêts régionaux et un transformateur pyramidal, qui est utilisé pour le diagnostic au niveau clinique et la découverte de marqueurs moléculaires des gliomes, et peut être étendu au diagnostic pathologique d'autres types de tumeurs.
Voir le rapport complet :https://go.hyper.ai/w4tsr
Articles populaires de l'encyclopédie
1. Champ de rayonnement neuronal (NeRF)
2. Attention aux requêtes de groupe GQA
3. Augmentation des données
4. Compréhension linguistique multitâche à grande échelle (MMLU)
5. Mémoire à long terme
Voici des centaines de termes liés à l'IA compilés pour vous aider à comprendre « l'intelligence artificielle » ici :
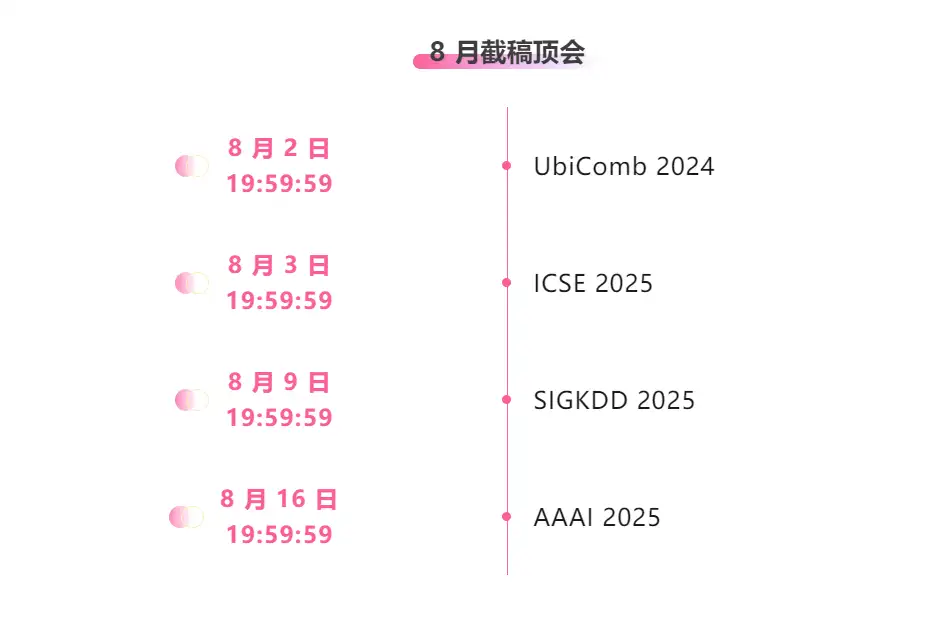
Suivi unique des principales conférences universitaires sur l'IA :https://go.hyper.ai/event
Voici tout le contenu de la sélection de l’éditeur de cette semaine. Si vous avez des ressources que vous souhaitez inclure sur le site officiel hyper.ai, vous êtes également invités à laisser un message ou à soumettre un article pour nous le dire !
À la semaine prochaine !
À propos d'HyperAI
HyperAI (hyper.ai) est une communauté leader en matière d'intelligence artificielle et de calcul haute performance en Chine.Nous nous engageons à devenir l'infrastructure dans le domaine de la science des données en Chine et à fournir des ressources publiques riches et de haute qualité aux développeurs nationaux. Jusqu'à présent, nous avons :
* Fournir des nœuds de téléchargement accélérés nationaux pour plus de 1 300 ensembles de données publiques
* Comprend plus de 400 tutoriels en ligne classiques et populaires
* Interprétation de plus de 100 cas d'articles AI4Science
* Prise en charge de plus de 500 termes de recherche associés
* Hébergement de la première documentation complète d'Apache TVM en Chine
Visitez le site Web officiel pour commencer votre parcours d'apprentissage :








