Command Palette
Search for a command to run...
PaddleOCR-VL: Multimodal Document Parsing
1. Tutorial Introduction

PaddleOCR-VL is a state-of-the-art (SOTA) and resource-efficient model designed specifically for document parsing tasks. Its core component is PaddleOCR-VL-0.9B, a compact and powerful visual language model (VLM) that integrates a NaViT-style dynamic resolution visual encoder with the ERNIE-4.5-0.3B language model, enabling accurate element recognition. This innovative model efficiently supports 109 languages and excels in recognizing complex elements such as text, tables, formulas, and charts while maintaining extremely low resource consumption. Through comprehensive evaluation on widely used public and internal benchmarks, PaddleOCR-VL achieves SOTA performance in both page-level document parsing and element-level recognition tasks. This model significantly outperforms existing solutions, demonstrates strong competitiveness against top-tier visual language models, and offers fast inference speeds. These advantages make it highly suitable for real-world deployment. Related research papers are available. PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model .
This tutorial uses a single RTX 5090 graphics card as computing resource.
2. Effect Examples
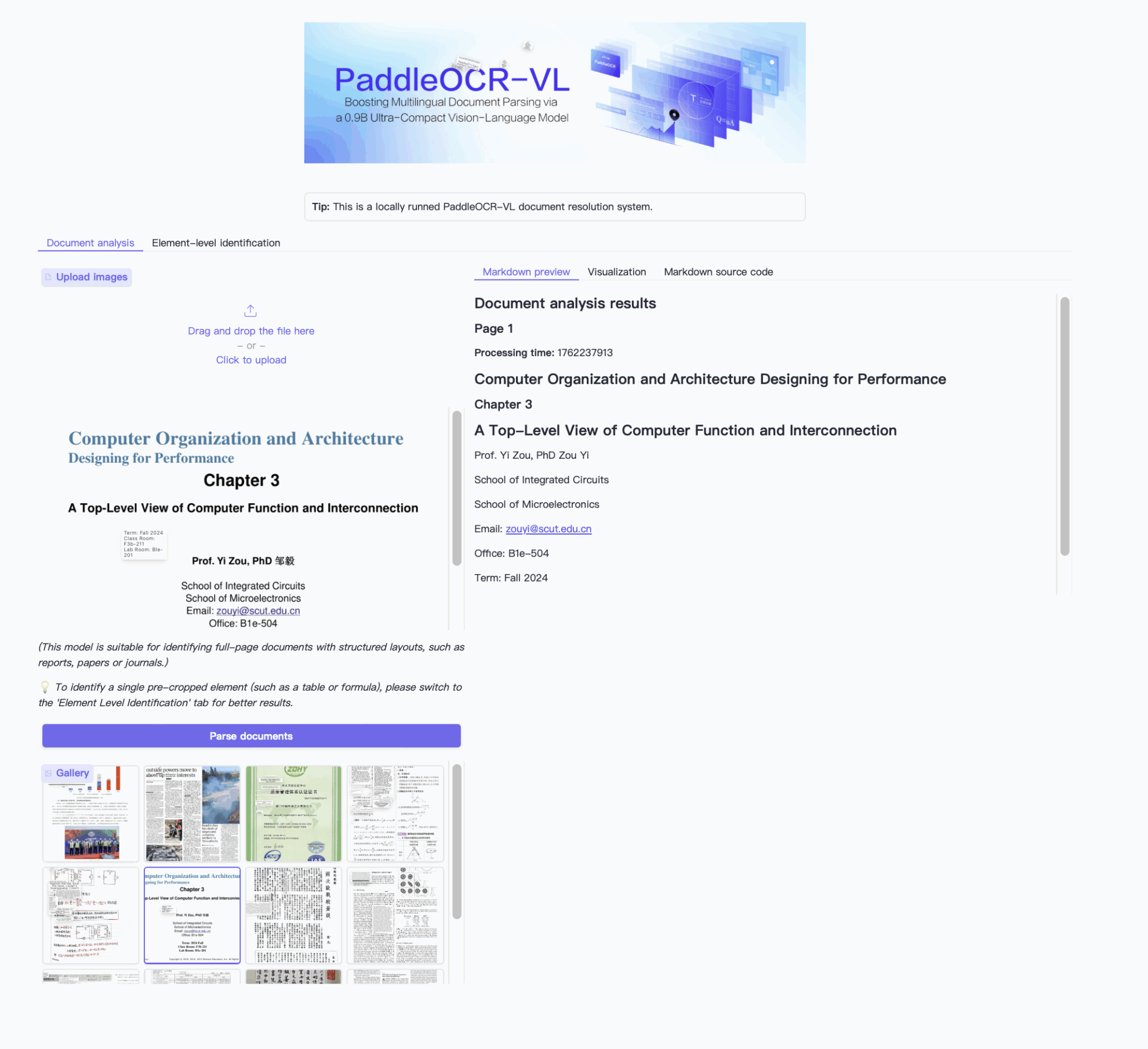
3. Operation steps
1. Start the container
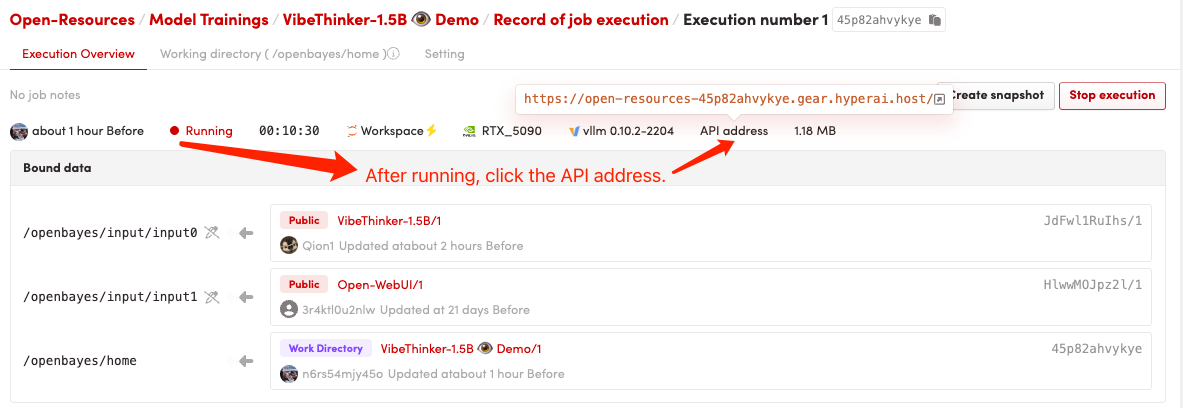
2. After entering the webpage, you can start a conversation with the model
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 2-3 minutes and refresh the page.
How to use
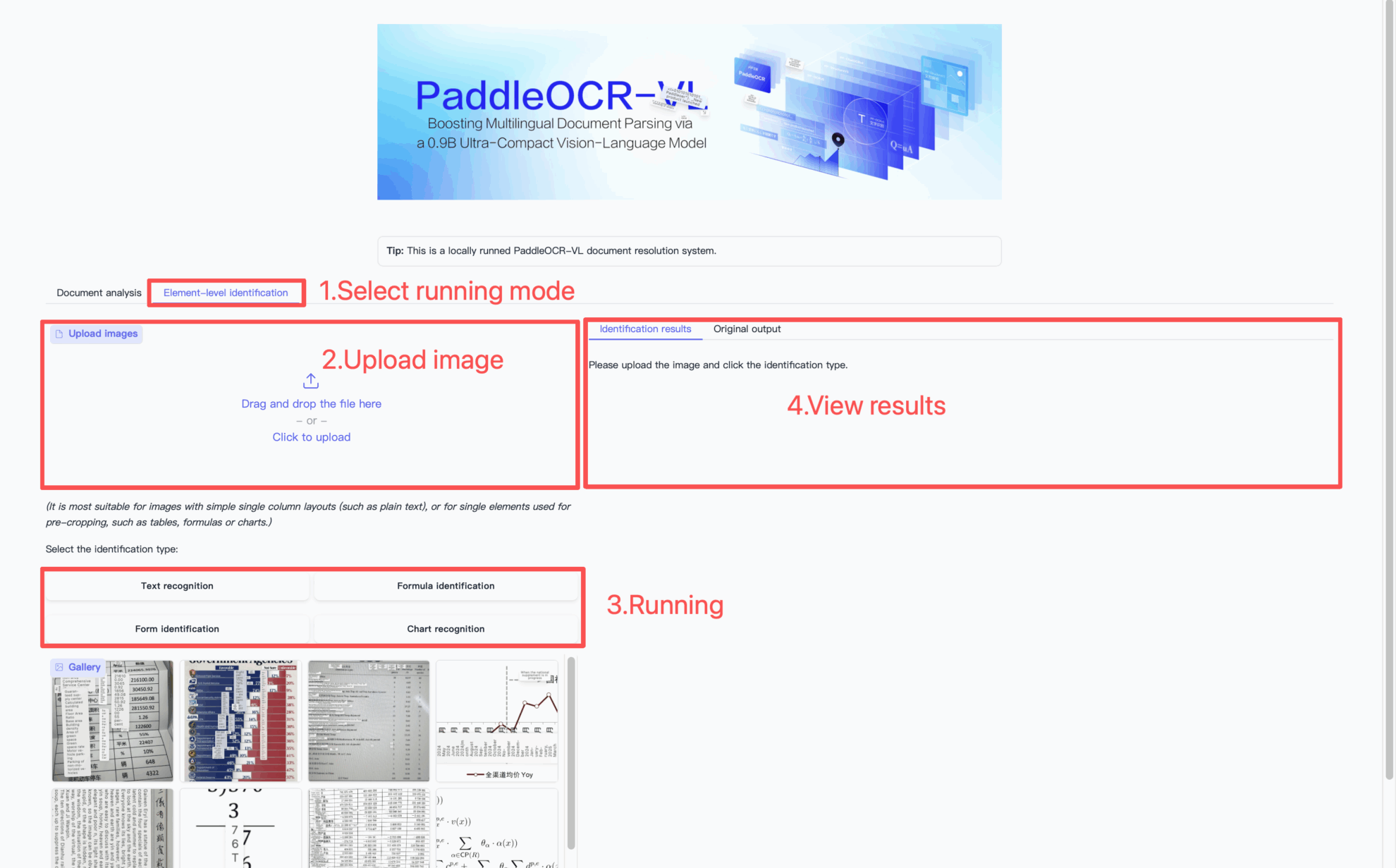
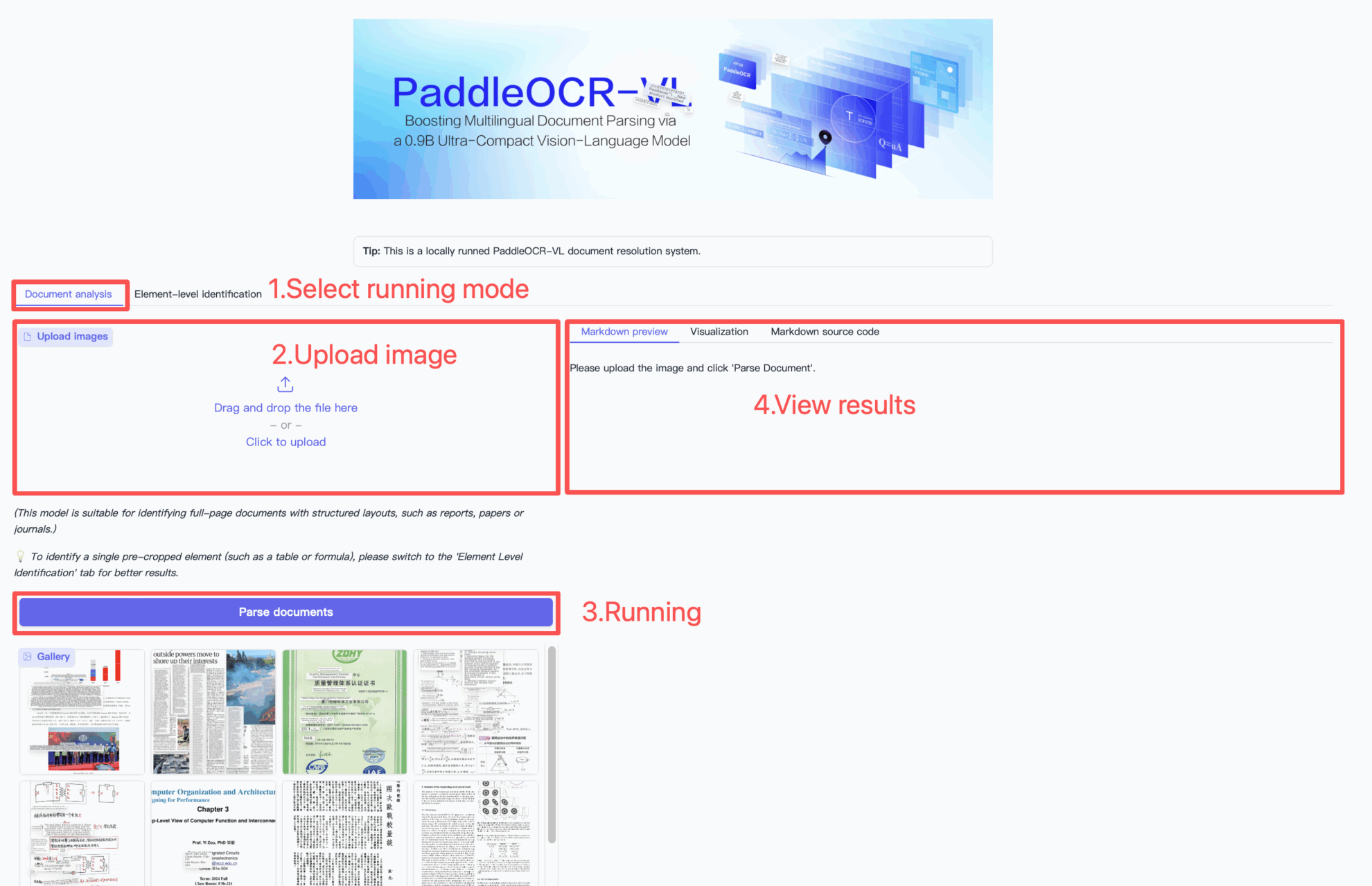
Citation Information
@misc{cui2025paddleocrvlboostingmultilingualdocument,
title={PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model},
author={Cheng Cui and Ting Sun and Suyin Liang and Tingquan Gao and Zelun Zhang and Jiaxuan Liu and Xueqing Wang and Changda Zhou and Hongen Liu and Manhui Lin and Yue Zhang and Yubo Zhang and Handong Zheng and Jing Zhang and Jun Zhang and Yi Liu and Dianhai Yu and Yanjun Ma},
year={2025},
eprint={2510.14528},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.14528},
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.