Command Palette
Search for a command to run...
Wan2.2-Animate-14B: Open Advanced Large-Scale Video Generation Model
Date
Organization
Tags
Paper URL
License
Apache 2.0
GitHub
1. Tutorial Introduction

Wan2.2-Animate-14B is an action generation model open-sourced by Alibaba's Tongyi Wanxiang team in September 2025. The model supports both action imitation and role-playing modes, accurately replicating facial expressions and movements from performer videos to generate highly realistic character animation videos. The model can seamlessly replace animated characters into the original video, perfectly matching the scene's lighting and color tone. Based on the Wan model, it controls limb movements through spatially aligned skeletal signals and recreates expressions using implicit facial features extracted from the source image, achieving highly controllable and expressive character video generation. Related research papers include... Wan-Animate: Unified Character Animation and Replacement with Holistic Replication .
This tutorial uses a single RTX PRO 6000 graphics card as computing resource.
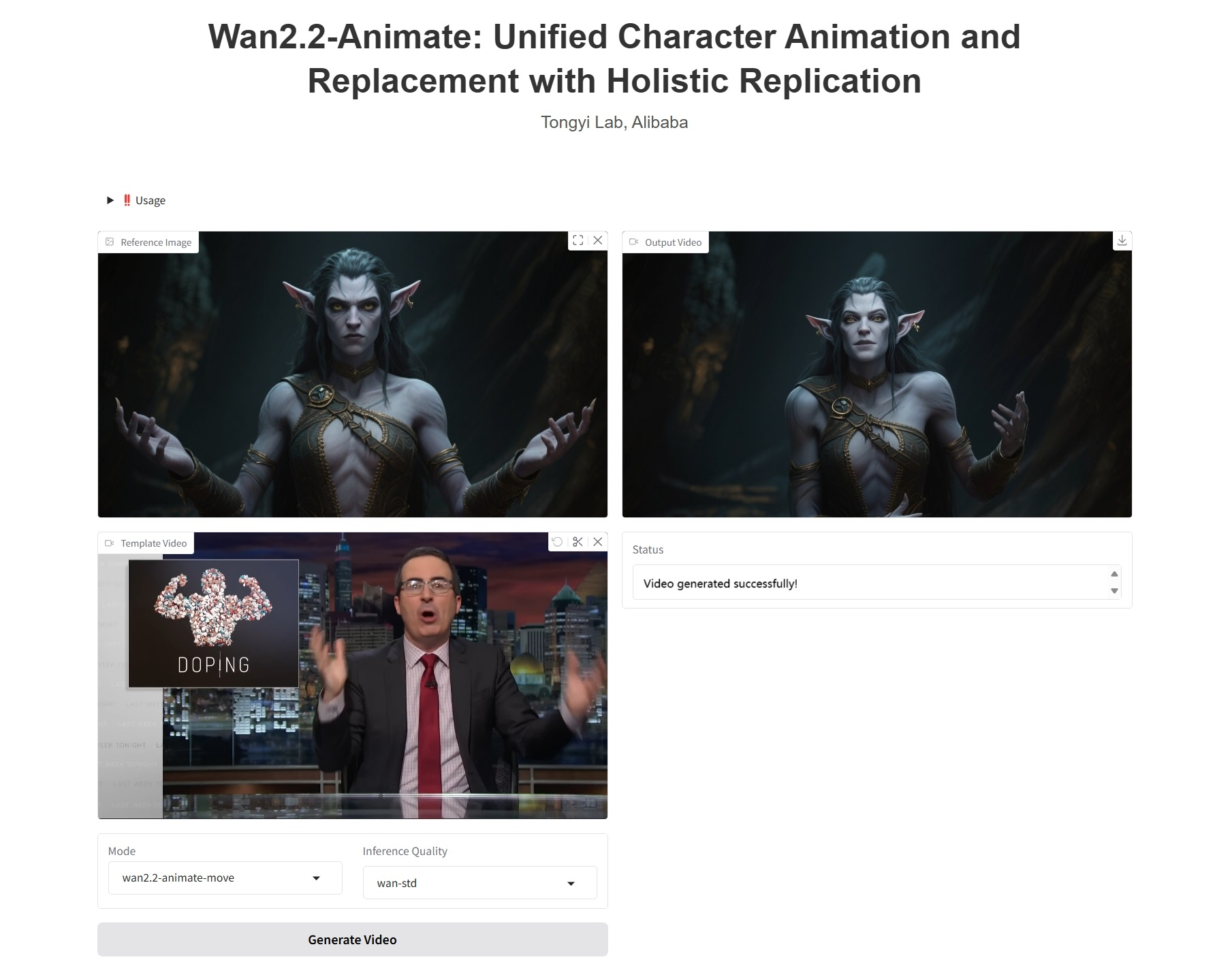
2. Effect display
3. Operation steps
1. Start the container
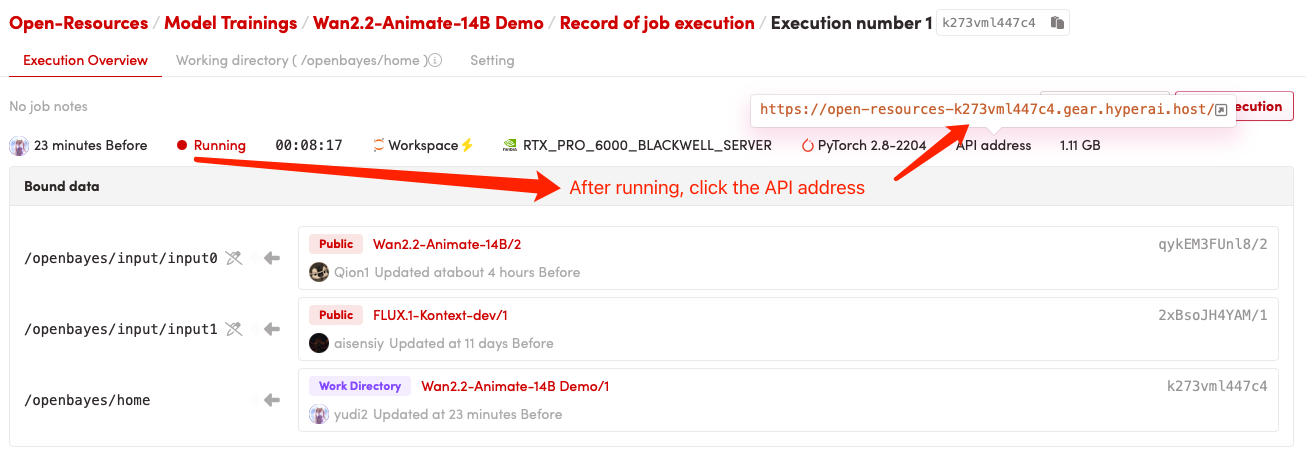
2. Usage steps
If "Bad Gateway" is displayed, it means the model is initializing. Since the model is large, please wait about 1-2 minutes and refresh the page.
Note: When you select Inference Quality, the better the quality of the video generated by wan-pro, the longer it will take to generate. Example 1 takes about 1200 seconds.
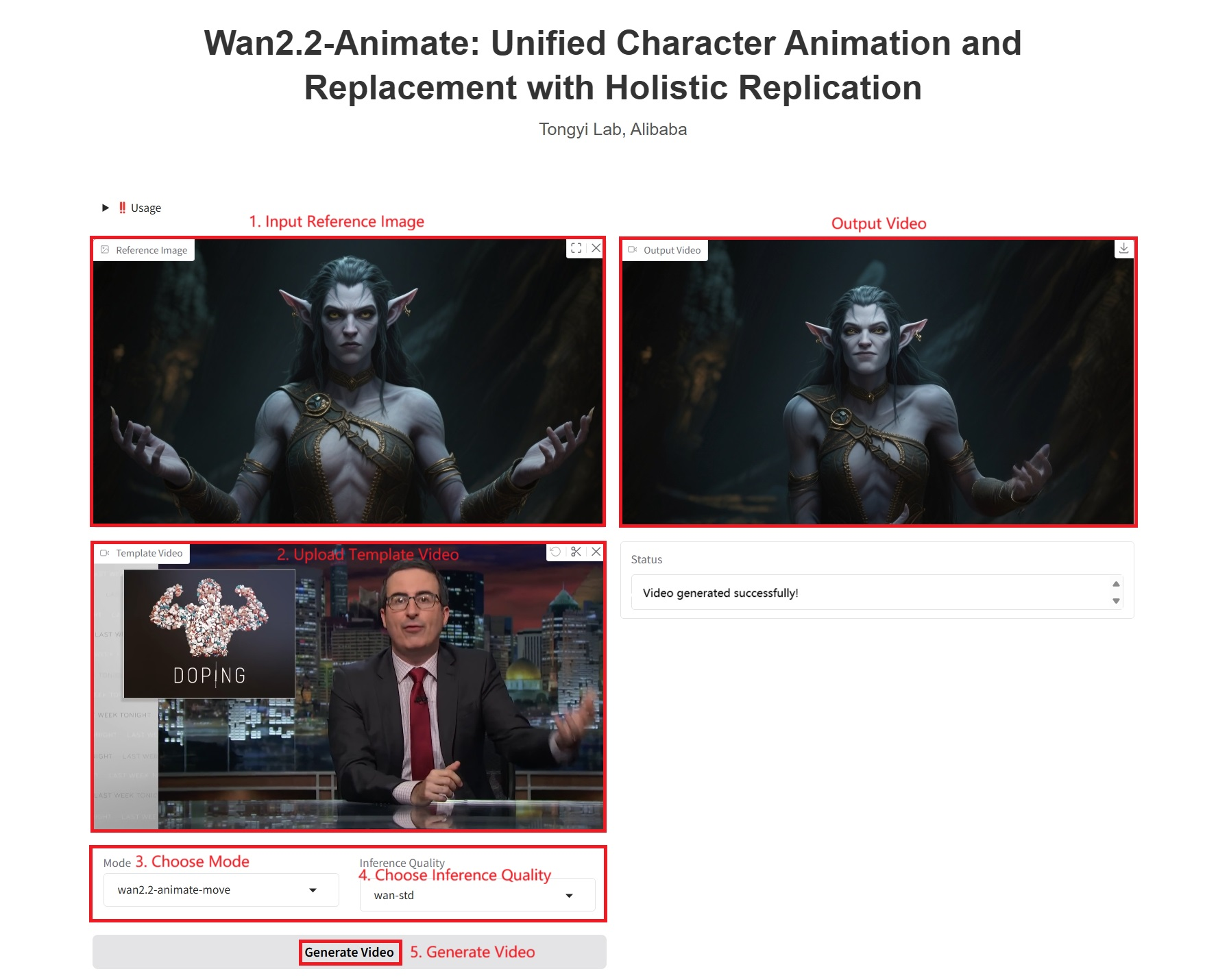
Specific parameters:
- Mode:
- wan2.2-animate-move: Action imitation. Takes a character image and a reference video as input. The model transfers the character's movements and expressions from the reference video to the input character image, making the static character dynamic and expressive.
- wan2.2-animate-mix: Character replacement, which replaces characters in a video with those in an input image while preserving the original video's movements, expressions, and environment, achieving seamless integration.
- Inference Quality:
- wan-pro: high-quality generation.
- wan-std: Standard version, balancing performance and efficiency.
Citation Information
The citation information for this project is as follows:
@article{wan2025,
title={Wan: Open and Advanced Large-Scale Video Generative Models},
author={Team Wan and Ang Wang and Baole Ai and Bin Wen and Chaojie Mao and Chen-Wei Xie and Di Chen and Feiwu Yu and Haiming Zhao and Jianxiao Yang and Jianyuan Zeng and Jiayu Wang and Jingfeng Zhang and Jingren Zhou and Jinkai Wang and Jixuan Chen and Kai Zhu and Kang Zhao and Keyu Yan and Lianghua Huang and Mengyang Feng and Ningyi Zhang and Pandeng Li and Pingyu Wu and Ruihang Chu and Ruili Feng and Shiwei Zhang and Siyang Sun and Tao Fang and Tianxing Wang and Tianyi Gui and Tingyu Weng and Tong Shen and Wei Lin and Wei Wang and Wei Wang and Wenmeng Zhou and Wente Wang and Wenting Shen and Wenyuan Yu and Xianzhong Shi and Xiaoming Huang and Xin Xu and Yan Kou and Yangyu Lv and Yifei Li and Yijing Liu and Yiming Wang and Yingya Zhang and Yitong Huang and Yong Li and You Wu and Yu Liu and Yulin Pan and Yun Zheng and Yuntao Hong and Yupeng Shi and Yutong Feng and Zeyinzi Jiang and Zhen Han and Zhi-Fan Wu and Ziyu Liu},
journal = {arXiv preprint arXiv:2503.20314},
year={2025}
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.