Command Palette
Search for a command to run...
Higgs Audio V2: Redefining the Expressiveness of Speech Generation
Date
Size
410.43 MB
Tags
License
Apache 2.0
GitHub
Paper URL
1. Tutorial Introduction

This tutorial uses a single RTX 4090 graphics card. It provides six examples for testing: voice-clone, smart-voice, multispeaker-voice-description, single-speaker-voice-description, single-speaker-zh, and single-speaker-bgm. System Prompt supports English only.
2. Project Examples
voice-clone
smart-voice
multispeaker-voice-description
single-speaker-voice-description
single-speaker-zh
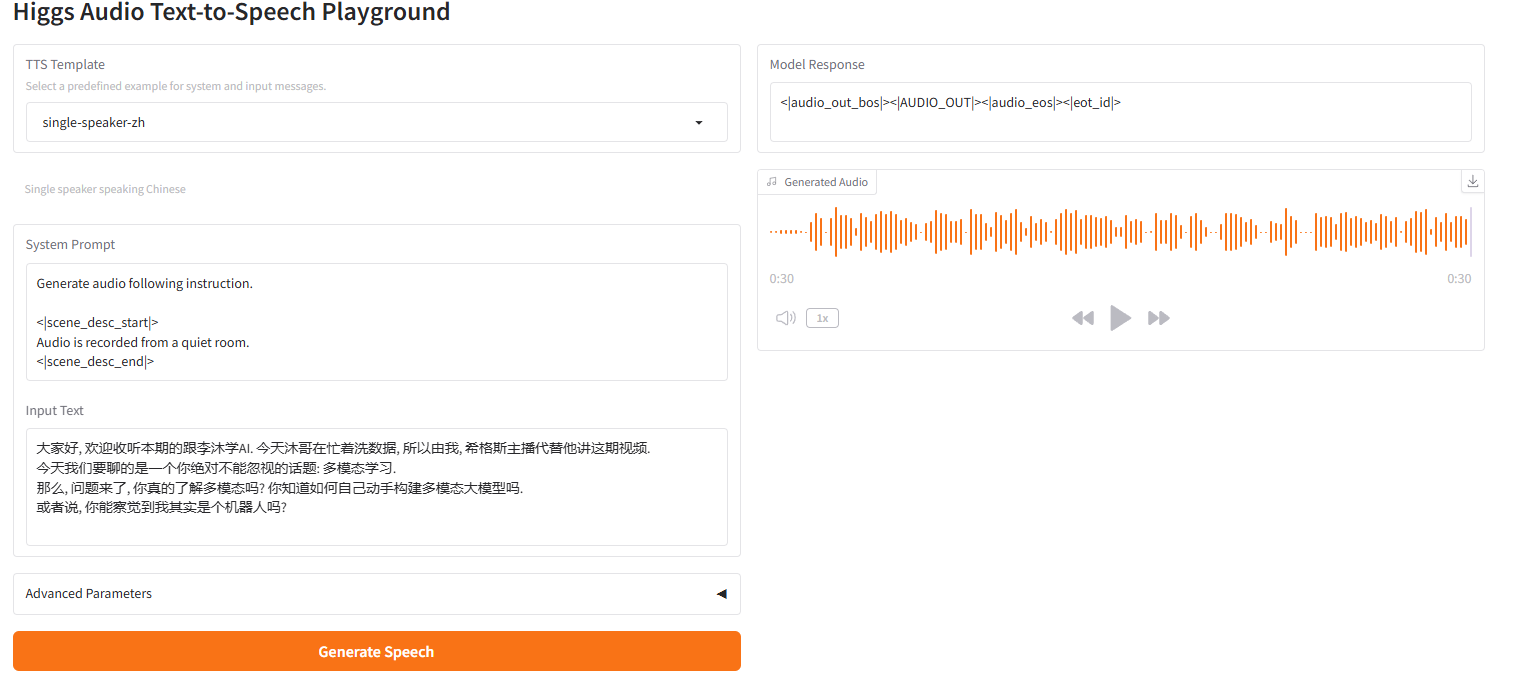
single-speaker-bgm
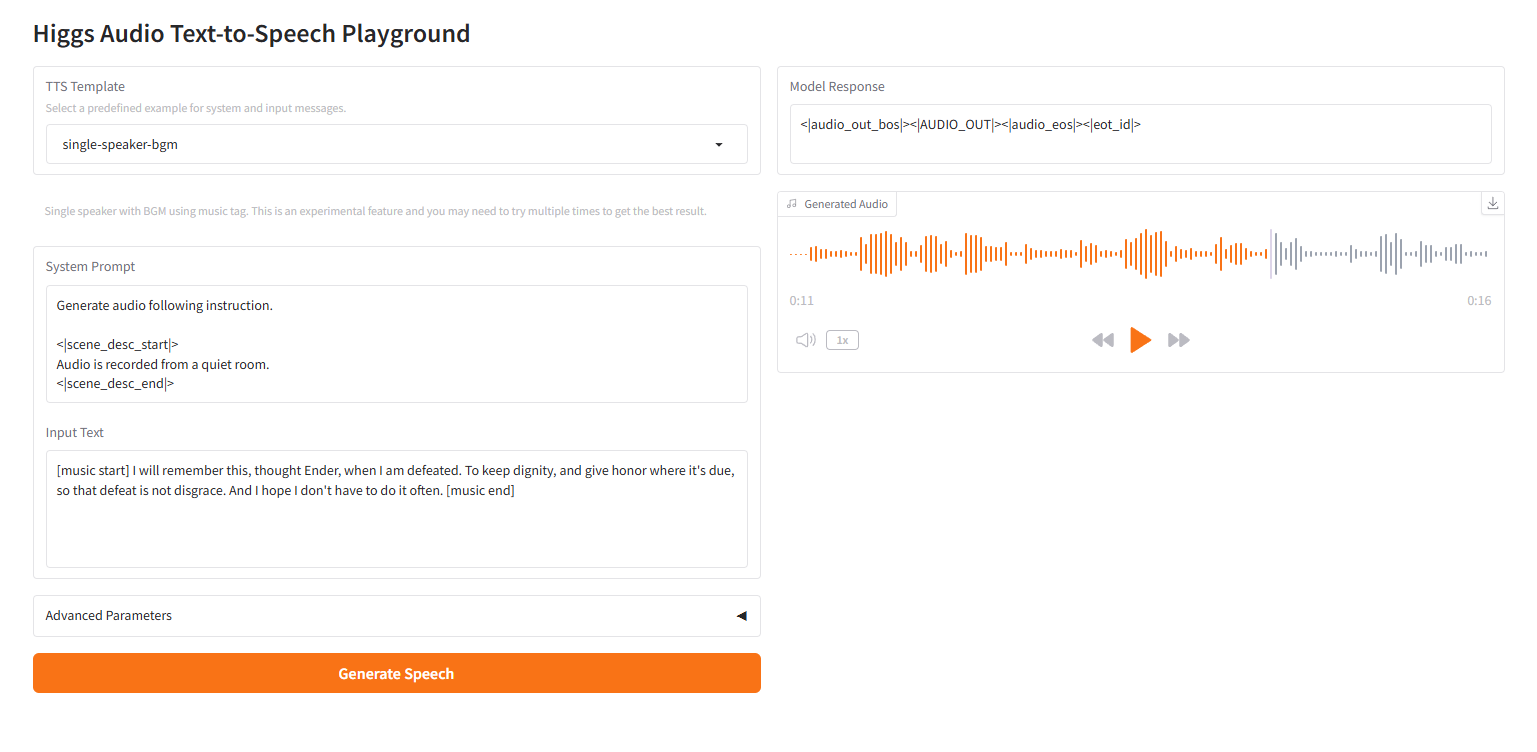
3. Operation steps
1. After starting the container, click the API address to enter the Web interface
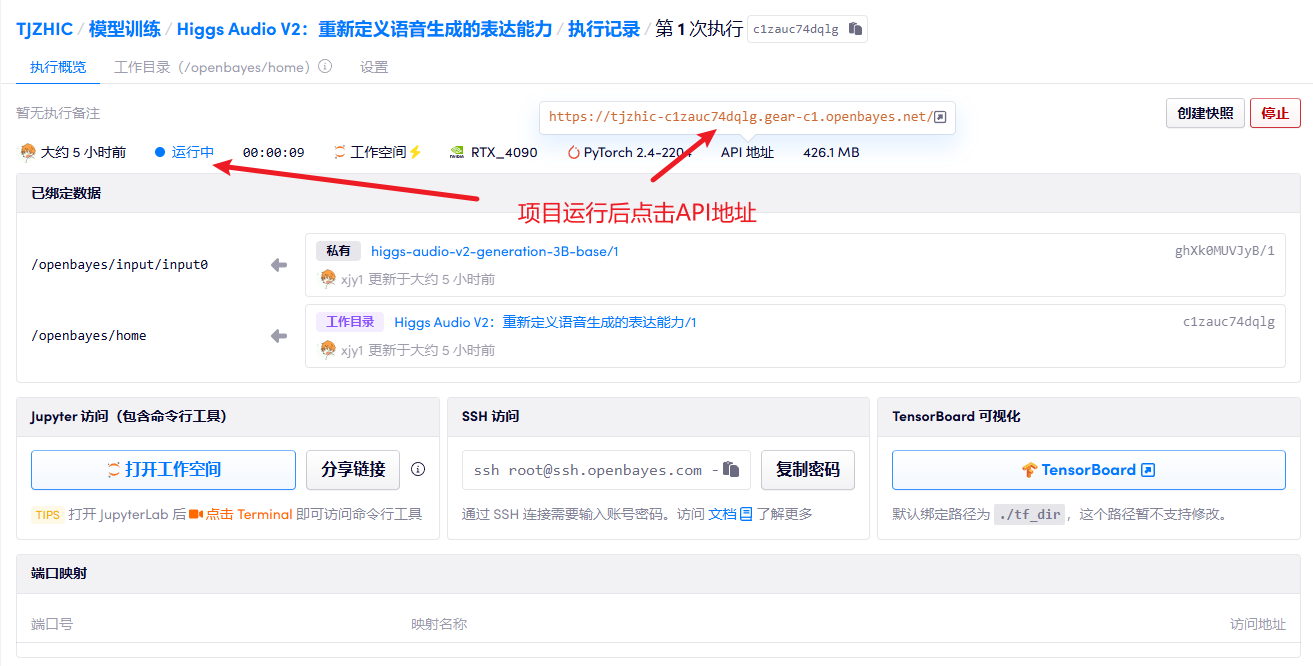
2. Usage steps
If "Bad Gateway" is displayed, it means that the model is initializing. Since the model is large, please wait for about 2-3 minutes and refresh the page. When using the Safari browser, the audio may not be played directly and needs to be downloaded before playing.
2.1 Voice-clone
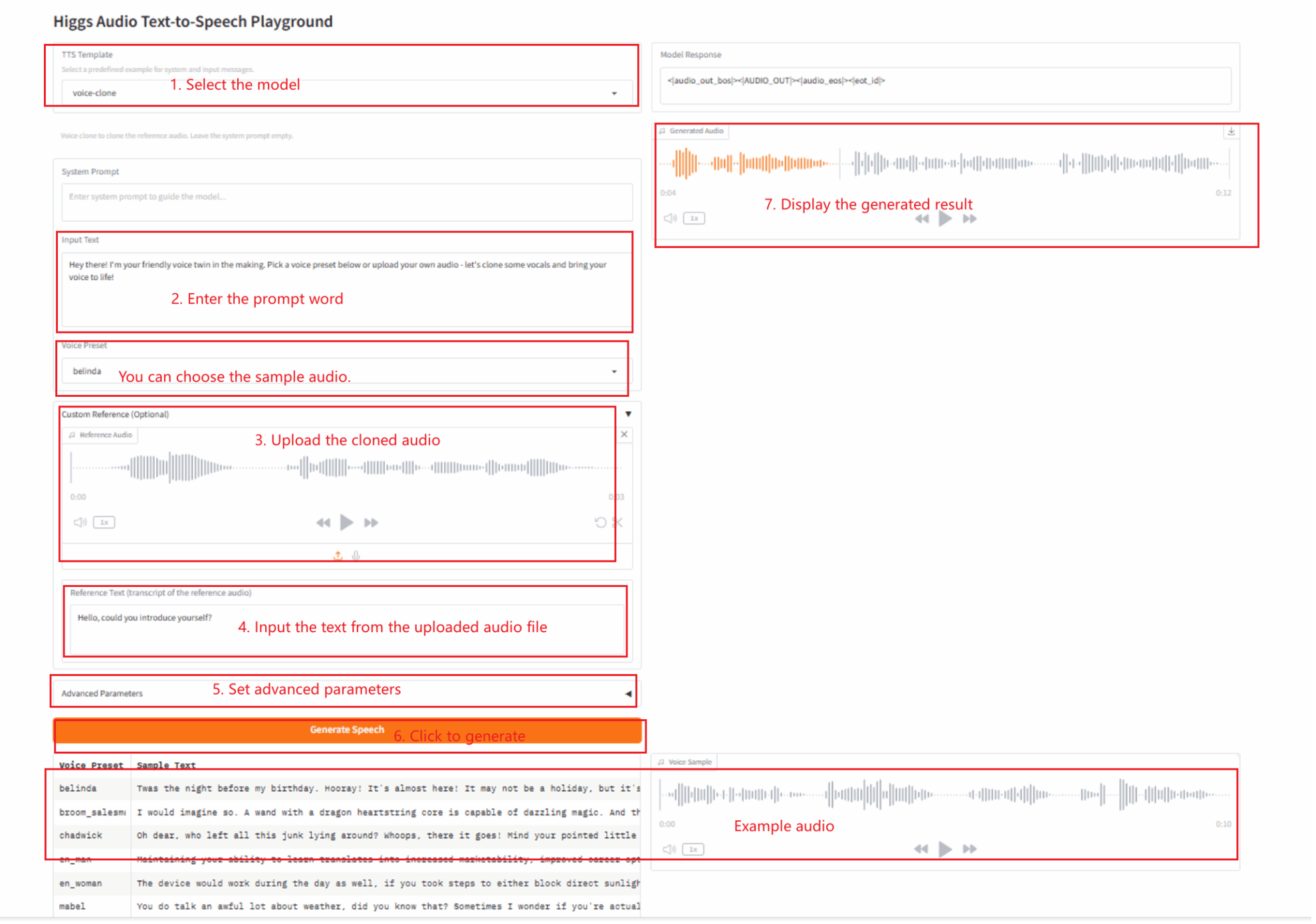
Parameter Description
- Advanced Parameters:
- Max Completion Tokens: Limits the length of the generated audio text (in tokens). The larger the value, the longer the generated audio may be.
- Temperature: Controls the randomness of the generated output. Low values (e.g., 0.1) make the output more deterministic and repeatable; high values (e.g., 1.0) make the output more varied and creative, but potentially incoherent.
- Top P: Limits the range of labels (cumulative probabilities) that the model considers at each step. Low values (such as 0.5) make the output more concentrated; high values (such as 0.95) make the output more diverse.
- Top K: Restricts the model to select only the K most probable markers at each step. Low values make the output more certain; high values (or -1 to disable) make the output more diverse.
- RAS Window Length: Enables the duplicate avoidance feature and defines the size of the text window to check for duplicates. Set to 0 to disable this feature.
- RAS Max Num Repeat: In conjunction with the RAS window, defines the maximum number of times a content can be repeated within the window. A low value reduces repetitions, while a high value allows more natural repetitions.
2.2 smart-voice
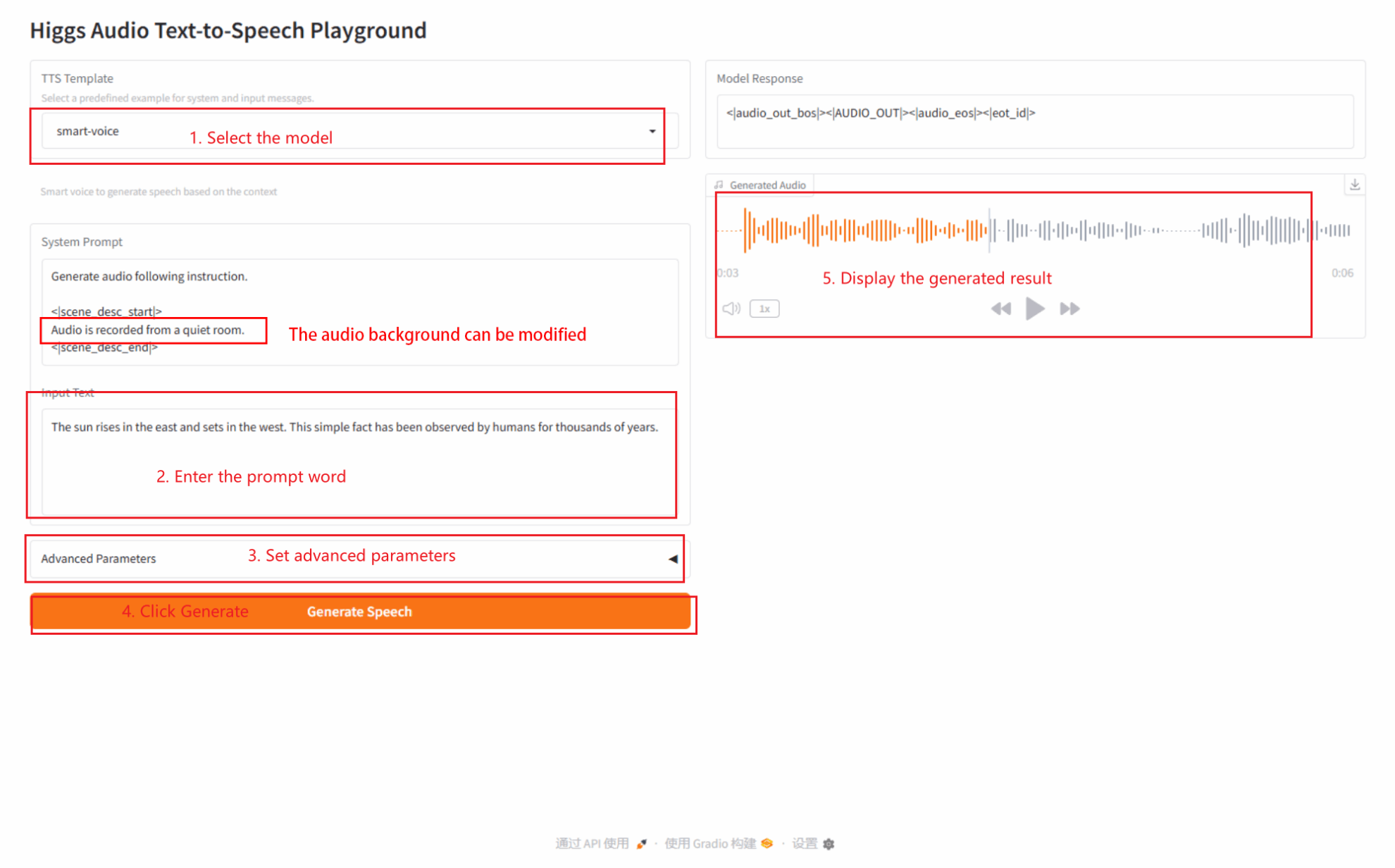
2.3 multispeaker-voice-description
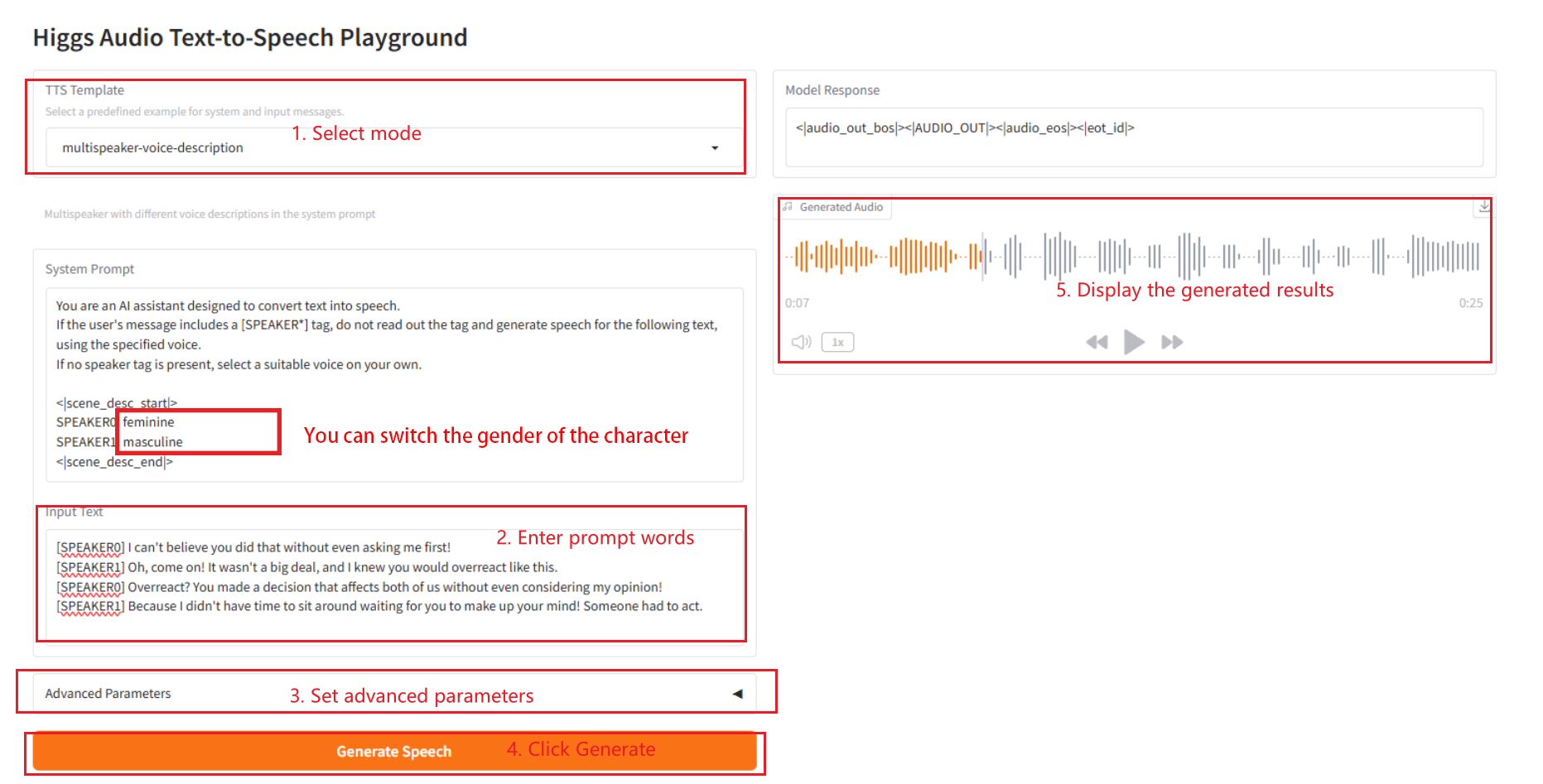
2.4 single-speaker-voice-description
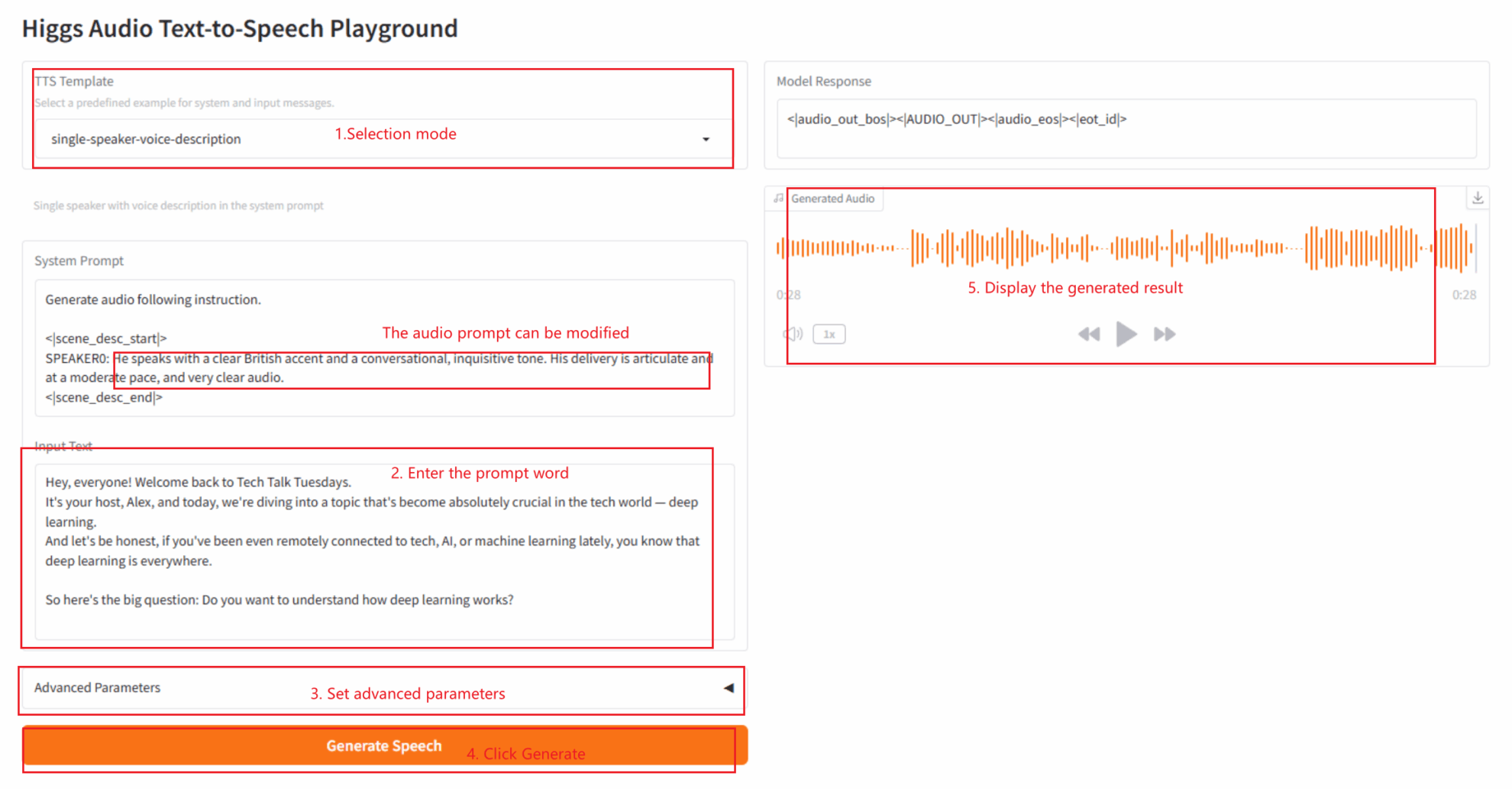
2.5 single-speaker-zh
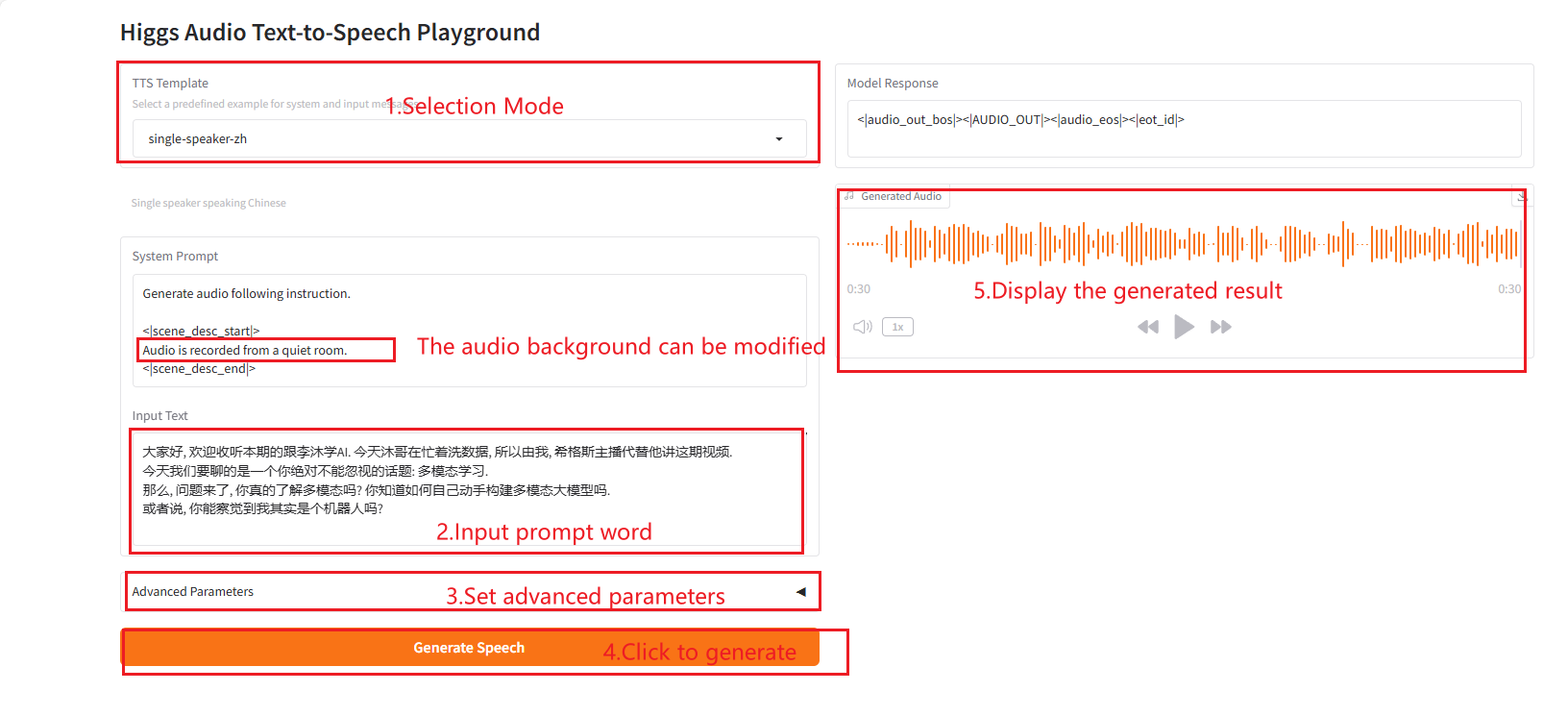
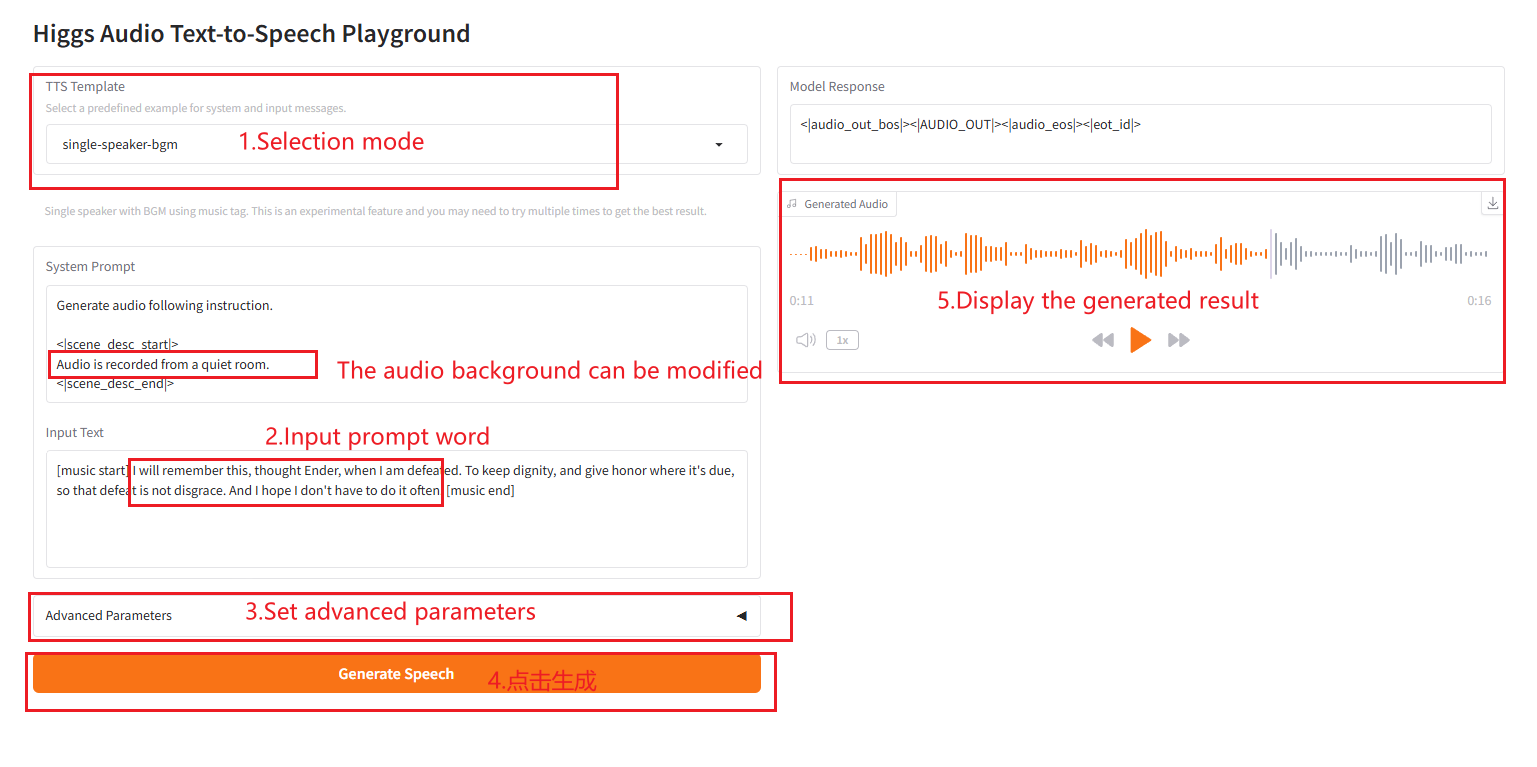
2.6 single-speaker-bgm
4. Discussion
🖌️ If you see a high-quality project, please leave a message in the background to recommend it! In addition, we have also established a tutorial exchange group. Welcome friends to scan the QR code and remark [SD Tutorial] to join the group to discuss various technical issues and share application effects↓

Citation Information
The citation information for this project is as follows:
@misc{higgsaudio2025,
author = {{Boson AI}},
title = {{Higgs Audio V2: Redefining Expressiveness in Audio Generation}},
year = {2025},
howpublished = {\url{https://github.com/boson-ai/higgs-audio}},
note = {GitHub repository. Release blog available at \url{https://www.boson.ai/blog/higgs-audio-v2}},
}Build AI with AI
From idea to launch — accelerate your AI development with free AI co-coding, out-of-the-box environment and best price of GPUs.